
Abstract
Content
- Introduction
- 1. Theme urgency
- 2. Goal and tasks of the research
- 3. The discrete Markov model of a cluster without shared storage
- Conclusion
- References
Introduction
Nowadays powerful computing systems are required to solve a large number of tasks.
Cluster is an example of computing systems with distributed data processing [1–4]. Cluster computing systems by criterion of shared storage are divided into clusters with shared storage and clusters without shared storage [2].
The task of rational computer environment’s resources usage is undertaken while designing and operating distributed computer systems. Continuous [5–7] or discrete analytical models [8] are used to perform this task effectively and main parameters of computing environment are defined for each class of undertaken tasks.
Continuous models are less laborious and they are used to perform difficult class of researched structures. In comparison with continuous, Markov discrete model reflects operation of computing environment more precisely and it allows to distribute computing structures effectively [9].
Great temporal expenses are required to analyze cluster systems with large number of undertaken tasks on computing system with discrete model because the number of states of the Markov discrete model rises combinatorial with number of tasks increasing.
1. Theme urgency
Nowadays designing and applying modern supercomputers is the one of the main directions in leading countries. Development of parallel computing systems is caused by necessity to perform big dimension tasks effectively. Efficiency of computing systems usage depends not only on processors performance, but on throughput of its communication channels. This is why a performance analysis of multiprocessor systems functioning is the one of the most important tasks.
Such tasks as load balancing, computing system bottlenecks definition, certain response time providing with a large number of users, etc are come to been owing much to development of computing systems.
Works in sphere of parallel computing structures are urgent and they require further development because of large amount of designed supercomputers.
The developed method of analytical computation structures simulation allows to design parallel structures for performing big dimension tasks which can't be effectively implemented on single-processor computers.
The undertaken researches into analysis and increasing efficiency of cluster systems and cluster systems optimization are described in this work.
2. Goal and tasks of the research
The main goal of this work is development of methods to increase efficiency of cluster systems functioning using analytical models considering selected cluster topology matches the class of undertaken tasks.
Research tasks:
- Markov model of cluster systems functioning development and existing methods of computing the main characteristics of cluster systems functioning improvement;
- Parallel algorithm of Markov model of cluster systems functioning development considering their structural features and a class of undertaken tasks.
Object of the research is the cluster system without shared storage.
Subjects of the research are analytical models of the analysis of high-performance computing systems.
Research methods. Performing tasks formulated in this work is based on methods of the theory of causal processes, calculus mathematics, the graph theory usage. Checking the results of research is going to realize with carrying out computing experiments on computation structures in systems of simulation modeling.
3. The discrete Markov model of a cluster without shared storage
In this model each node of cluster has the own memory, all nodes use a disk subsystem. Nodes of cluster can access a disk subsystem with the front-side bus. Computing tasks are uniformly distributed on several computers integrated in a network.
In simplified structure of a cluster without shared storage (see fig. 1), data transfer (see fig. 2) time on the bus is included in a holding time on servers and disks, correspondingly. The structure consists of the M user workstations, N1 servers executing different applications, N2 disks storing the database.
Let's represent servers and disks as devices which holding time has geometrical distribution with in the average qi parameter (i=1,…,N1+N2+1) – probability of completion of the servicing request (correspondingly, ri=1-qi – probability of continuation of the servicing request.
The controlling server distributes the requests from each of M users and with probability
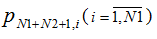 sends request to one of N1 of servers which, in turn, processing this request
accesses to one of N2 disks with probability
sends request to one of N1 of servers which, in turn, processing this request
accesses to one of N2 disks with probability
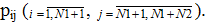
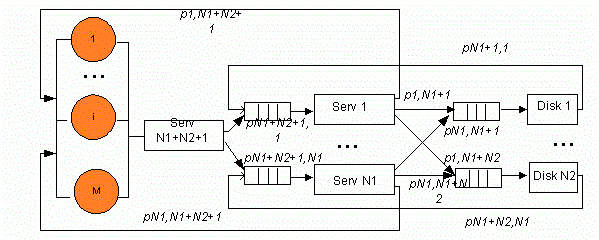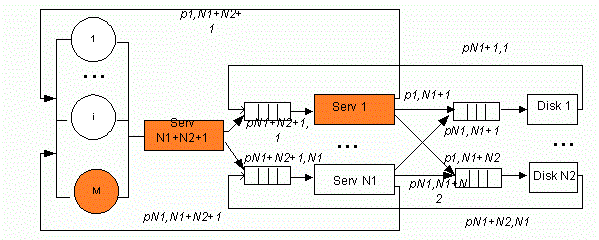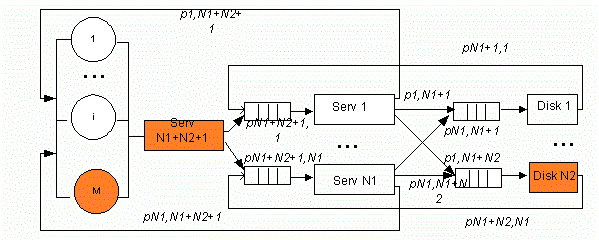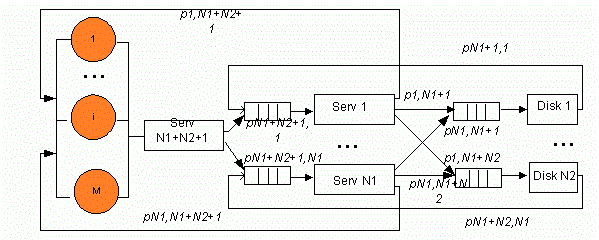
Figure 1 – The skeleton diagram of a cluster without shared storage (Animation: number of frames: 9, repeat count: 6, size: 137 Kbyte)
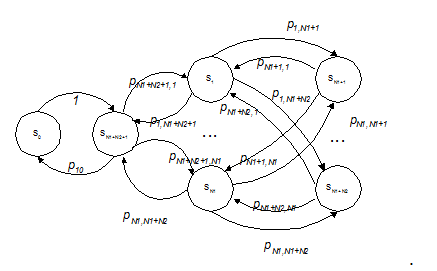
Figure 2 – The transmissions graph of a cluster without shared storage model
To create the discrete model of such computing system let's define all possible statuses. Let's take placement of M requests on N1+N2+1 nodes as a status
of system, where
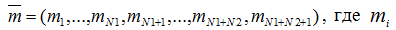 – number of tasks in node i (total number of nodes is N=N1+N2+1).
Let's represent a set of statuses as
– number of tasks in node i (total number of nodes is N=N1+N2+1).
Let's represent a set of statuses as
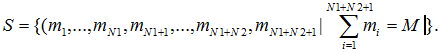 L is a number of various statuses of system and it is equal to number of placements of M tasks on N
nodes and it is determined with a formula:
L is a number of various statuses of system and it is equal to number of placements of M tasks on N
nodes and it is determined with a formula:
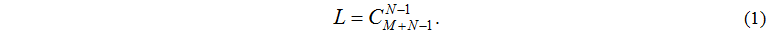
The number of devices in each node is set by a vector 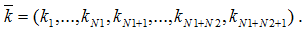
Let's define the transition probabilities for each pair of statuses 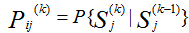 ,
i.e. transition probabilities from Si, status in which it was in step (k-1) to Sj status in step k.
,
i.e. transition probabilities from Si, status in which it was in step (k-1) to Sj status in step k.
Let's input vector 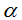 for optional status
for optional status 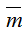 component s of which
component s of which
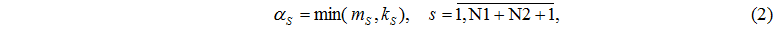
defines number of the loaded devices in the node s. To define possibility of transition from optional status
optional status
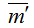 let's find the vector
let's find the vector
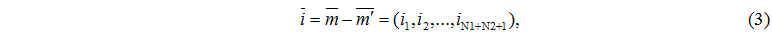
each component 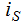 represents change of task number in node s.
If >0 minimum
tasks should leave node s while considering transition. If
< 0,
|| task should come to the node s. While considering any transition from
number of tasks servicing in node s by, can't be more than
represents change of task number in node s.
If >0 minimum
tasks should leave node s while considering transition. If
< 0,
|| task should come to the node s. While considering any transition from
number of tasks servicing in node s by, can't be more than 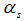 , i.e.
, i.e.
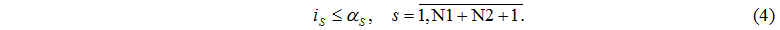
Let's define a set of node numbers J where < 0, i.e.
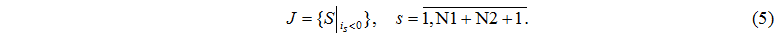
If 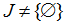 values
values 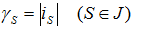 define minimum
possible number of programs which arrives to those nodes which numbers s belong to a set J. Number of programs which have arrived in
one of such nodes s is equal to ||.
Number of tasks which arrived to a master server from servers can't exceed number of operating servers
define minimum
possible number of programs which arrives to those nodes which numbers s belong to a set J. Number of programs which have arrived in
one of such nodes s is equal to ||.
Number of tasks which arrived to a master server from servers can't exceed number of operating servers
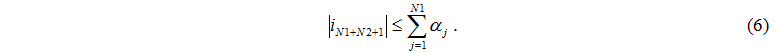
Similarly, the number of tasks which arrived to disks from servers can't exceed number of operating servers
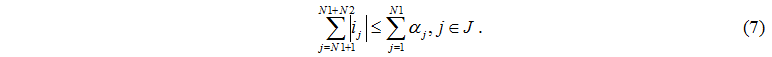
Task from a server node arrive both to the controlling server and to disks therefore the total quantity tasks which has left server node can't exceed number of operating servers
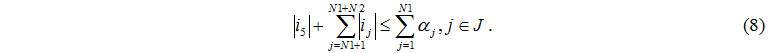
The number of tasks which arrived to servers can't exceed quantity of operating disks and the task which has arrived from the controlling server
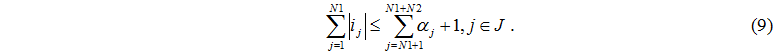
If 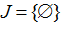 that
that 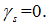
Let's consider particular case:
N = 5 – number of devices,
N1 = 2 – number of computing servers
N2 = 2 – number of disks
M = 5 – number of tasks.
Let's define number of all possible statuses of system as L:
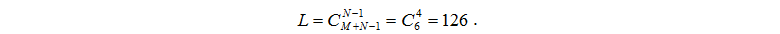
Transition  is possible if conditions (6-9) are true.
is possible if conditions (6-9) are true.
Let's consider case i5=1 – the controlling server has finished processing of one task, therefore processing is required on one of computing servers.
Let's say other devices continue processing tasks, and exchange isn't required, then transition probability between two statuses:
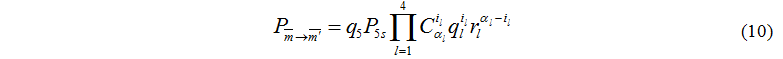
Let's consider other case when i5=1 – the controlling server has finished processing one task, other devices also has finished processing tasks, therefore, it is necessary to consider possibility of tasks exchange between computing servers and disk devices.
Let's formulate conditions of set formation for an exchange of tasks:
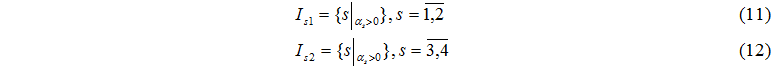
The set Is1 contains numbers of computing servers, and a set Is2 contains numbers of disks which in this clock period can finish task processing.
The exchange can be realized under condition (13):
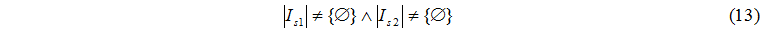
Let's construct a set of events for an exchange of tasks:
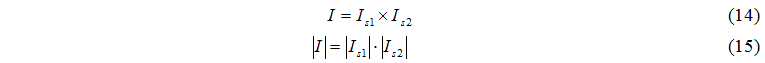
The member of set I looks like:
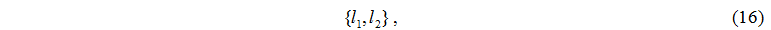
where l1 - number of server node,
l2 - number of disk node.
Then transition probability between two statuses is:
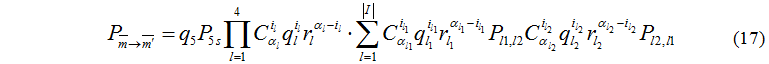
Let's consider case i5=0 three options of exchanging tasks are possible:
1) between controlling server and computing servers;
2) between computing servers and disk devices;
3) between controlling server and computing servers, and computing servers and disk devices.
Let's formulate conditions of set formation for exchanging tasks:
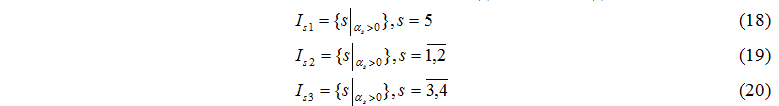
The set Is1 contains number of the controlling server, Is2 contains numbers of computing servers and set Is3 contains numbers of disks which in this clock period can finish task processing.
The exchange can be realized under condition (21):
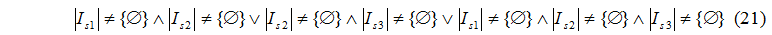
Let's construct a set of events for exchanging tasks:
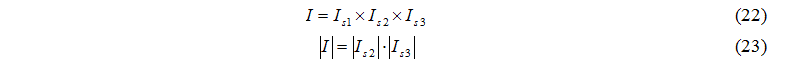
The member of set I looks like:
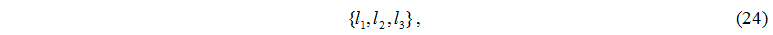
where l1 – number of the controlling server,
l2 – number of server node,
l3 – number of disk node.
To determine vector of stationary statuses it is necessary to solve system of linear algebraic equations
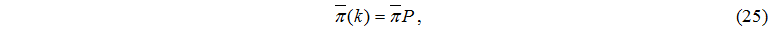
which is appropriate to the considered Markov model.
Stationary probabilities usage is possible to calculate the main characteristics of a computing environment [10]:
The average number of busy devices in node s is determined by a formula:
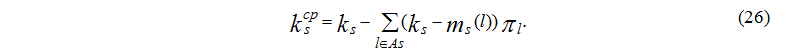
Loading of devices is determined by the following formula:
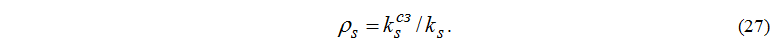
Average number of tasks in node s:
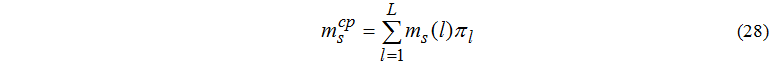
Average number of tasks in queue to node s:
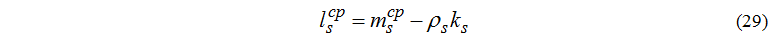
If the specific type of a cluster for performing certain class of tasks is analyzed, it is possible to define computing environment efficiency with these characteristics (depending on criterion: uniform loading of all nodes, minimum time of response, etc.).
For a cluster without shared storage model (see fig. 1) parallel algorithm of discrete Markov model (see fig. 3) is constructed.
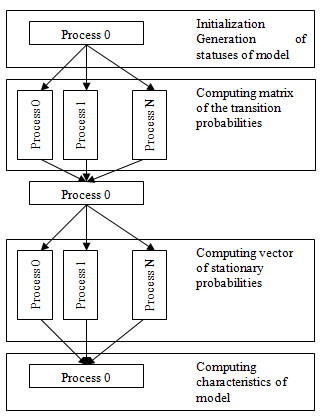
Figure 3 – The diagram of Markov model parallel algorithm
Parallel algorithm efficiency aims one (see fig. 4) in case of growth of task dimension that shows optimality of these algorithms distributing.
To select optimum coefficient of multiprogramming it is possible to use a technique [11] where the criterion of the balance, which components are the price of equipment downtime and a penalty for a time delay of request executing
Considered in [11] methods of optimization of composition and structures of high-performance computing structures are possible to use for computing structures design and in case of big multiprogramming coefficient – only numerical (graded-index) or using method of averages.
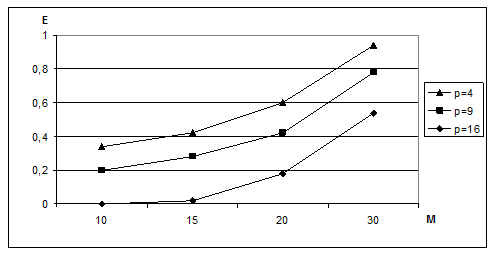
Figure 4 – Dependence of parallel algorithm efficiency on the calculated task dimensionality
Thus, probability models usage while designing, operating and optimizationing computing systems allows to work out recommendations about rational resources usage of this computing environment.
Conclusion
The discrete Markov model of the cluster computing system without shared storage model with limited number of tasks which can be used for an assessment of parallel computing structures efficiency is developed. Including, to compute the main characteristics of a computing environment: loading of devices; average number of busy devices in node s; an average number of tasks in queue to node s; average time of staying and waiting in node s; average time of staying and waiting in system.
Parallel implementation of Markov model of the cluster computing system which efficiency aims to one in case of big dimension of the task is offered.
References
- Шнитман В. Современные высокопроизводительные компьютеры. Информационно-аналитические материалы центра информационных технологий / В. Шнитман [Электронный ресурс]. Режим доступа: http://www.citforum.ru/hardware/svk/contents.shtml.
- Спортак М., Франк Ч., Паппас Ч. и др. Высокопроизводительные сети. Энциклопедия пользователя. – К.:«ДиаСофт», 1998.-432с.
- Corbalan J., Martorell X., Labarta J. Performance-Driven Processor Allocation //IEEE Transactions on Parallel and Distributed Systems, vol. 16, No. 7, July 2005, PP.599-611
- Oleszkiewicz J., Xiao L., Liu Y. Effectively Utilizing Global Cluster Memory for Large Data-Intensive Parallel Programs //IEEE Transactions on Parallel and Distributed Systems, vol. 17, No. 1, Jan. 2006, PP.66-77
- Авен О. И. и др. Оценка качества и оптимизация вычислительных систем. – М.: Наука, 1982,-464с.
- Cremonesi P., Gennaro C. Integrated Performance Models for SPMD Applications and MIMD Architectures //IEEE Transactions on Parallel and Distributed Systems, vol. 13, No. 7, Jul. 2002, PP.745-757
- Varki Е. Response Time Analysis of Parallel Computer and Storage Systems //IEEE Transactions on Parallel and Distributed Systems, vol. 12, No. 11, Nov. 2001, PP.1146-1161
- Клейнрок Л. Вычислительные системы с очередями. – М.:Мир, 1979, 600с. Последовательно - параллельные вычисления: Пер. с англ. - М.: Мир, 1985.-456 с.
- Фельдман Л.П., Михайлова Т.В. Параллельный алгоритм построения дискретной марковской модели /Высокопроизводительные параллельные вычисления на кластерных системах. Материалы четвертого Международного научно-практического семинара и Всероссийской молодежной школы. /Под редакцией член-корреспондента РАН В.А. Сойфера. – Самара, 2004. – С. 249-255.
- Фельдман Л.П., Михайлова Т.В. Оценка эффективности кластерных систем с использованием моделей Маркова. //Известия ТРТУ. Тематический выпуск: Материалы Всероссийской научно-технической конференции с международным участием «Компьютерные технологии в инженерной и управленческой деятельности». – Таганрог: ТРТУ, 2002. – №2 (25). – С. 50-53.
- Фельдман Л.П., Михайлова Т.В. Способы оптимизации состава и структуры высокопроизводительных вычислительных систем //Научные труды Донецкого государственного технического университета. Серия «Информатика, кибернетика и вычислительная техника»(ИКВТ-2001).- Донецк: ДонГТУ.- 2000. C. 80-85.