
Abstract
Contens
- Introduction
- 1. The purposes and research problems
- 2. Urgency of a theme for research
- 3. Prospective scientific novelty
- 4. Schedulable practical results
- 5. Summary of own results
- Conclusion
- References
Introduction
The basic difficulty which interferes with introduction of speech technologies in numerous fields of activity and a life of the person, is insufficient stability of process of recognition and understanding of speech. (External noise, pronunciation variations, syntactic deviations, etc.) work of a considerable quantity of experts worldwide is devoted creation of methods of understanding of the speech, distortions steady against various kinds. A considerable quantity of algorithms has been developed for recognition of separately said words. However the separate pronunciation unlike conjoint speech essentially slows down and complicates speech dialogue between the announcer and the computer.
The problem essence consists that among existing speech technologies there are no methods of recognition the conjoint speech, steady in relation to any deviations that cannot lead робастному to understanding of speech. Almost all known approaches to recognition of conjoint speech are based on semantic-syntactical or stochastic restrictions in models of generation the hypothetical phrases (as compound standards or models) [1,2,3,4]. Such models can distinguish only phrases ideally constructed and accurately said in a complete silence. Differently phrases with partial discrepancies are rejected already at level of recognition of chains of words. To remove these restrictions within the limits of existing approaches (for example, by full search) it is impossible, as it would lead to catastrophic complication of model of recognition. At the big sizes of the dictionary the number of phrases constructed by a search method would reach huge volume that would lead to scale computing operations, and such system simply became practically not applicable.
1. The purposes and research problems
The main purpose of this paper is to develop an algorithm for continuous speech recognition and its implementation in a software product.
For object in view performance following problems are allocated:
- Studying of algorithms of record and preliminary processing of a speech signal;
- Studying of algorithms of segmentation of a speech signal;
- The analysis of existing methods of recognition of continuous speech;
- Working out of own algorithm of recognition of continuous speech or upgrade of the existing;
- Software product working out on continuous speech recognition;
- Carrying out of check and comparison of results of work on with existing applications.
2. Urgency of a theme for research
In questions of automatic recognition of speech scientific steels to be engaged from the moment of occurrence of the first computers as the text command interface of interaction from the COMPUTER did not provide comprehensible speed and naturalness of work. For many years of researches the wide spectrum of methods and the computer programs directed on the decision of problems of recognition of speech has been developed.
Today promising results are received and operating commercial systems, basically, for English language, and also Spanish, French, Japanese, Chinese and the Arabian languages are created. It is in many respects connected with economic and political aspects of development of speech technologies. For example, English language is the most widespread and consequently investments into development of technologies for the automated processing of English speech have paid off quickly enough. At the same time not enough attention owing to what their development restrains a little is given to speech technologies of other languages.
Meanwhile, Russian is one of the most popular languages of the world, on it speaks over twenty percent of the population of Europe. Despite it, operating systems of automatic recognition of Russian conjoint speech actually do not exist. Except economic problems, development of speech technologies is influenced, first of all, by features of Russian and the speeches causing complexities in the course of processing. The cores from them: absence of strict grammatical designs of construction of offers, and also numerous rules of word-formation, phonetic representation of words and arrangement of accents with a considerable quantity of exceptions.
To an estimation of efficiency of developed systems of automatic recognition of speech apply many indicators, as integrated criteria of an estimation of productivity of such systems serve accuracy of recognition of speech (sounds, words or phrases) and speed of processing of a speech signal. Ideally the system should provide practically 100 % accuracy of recognition of speech at an instant conclusion of result. Nevertheless, considering the limited possibilities of existing computing resources at the decision of such difficult intellectual problems as automatic recognition of speech of the person, it is necessary to find the compromise between accuracy and speed of processing. In picture 1 is resulted basic elements of system of recognition of conjoint speech on an example of workings out "ЦРТ" [5] (Russia).
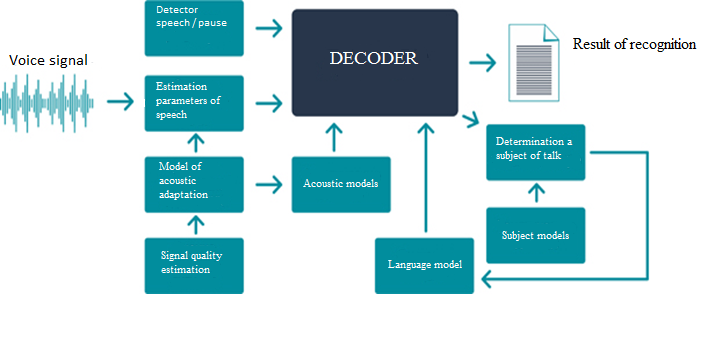
3. Prospective scientific novelty
It is supposed that in the given operation the new method of recognition of continuous speech will be offered and also for acceleration of system operation of recognition computing resources of the graphics adapter that allows to increase speed of recognition considerably will be involved.
4. Schedulable practical results
As the main schedulable results object in view achievement is supposed: development the algorithm of recognition the continuous speech and its implementation in the form of a software solution.
5. Summary of own results
As a result of the led analysis of existing methods of recognition of continuous speech it has been decided to use in the further researches on continuous speech recognition phonemic the methods of the recognition based on segmentation of a signal on separate phonemes and the subsequent analysis of the segmented signal. Some results in the given direction already have been received by me, on an example of recognition of many-valued numbers.
Conclusion
For today the continuous speech solution of a problem is possible only a method of generation of hypotheses of phrases by the full search of composite standards/models of words, but it leads to unacceptable complication of model of recognition, therefore such method is used only at very restricted size of the dictionary. In the given final operation it is supposed to refuse the full search of hypotheses of phrases, in favor phonemic discernments.
During the led review of existing systems of voice recognition it is possible to draw outputs that the task of recognition of continuous speech is interdisciplinary, therefore experts of a various profile should be attracted in development of speech technologies (engineers, mathematicians, philologists, physicians, teachers, etc.). In this connection ripened necessity for join of potential of researchers at once in several areas of a science, such as signal handling, pattern recognition, phonetics, computer linguistics that is connected to usage of the big financial and temporal resources.
References
- Jelinek F. The Development of an experimental Discrete Dictation Recognizer - In Proceedings of the IEEE, 1985.-vol. 73,no. 11, 1616-1624 стр.
- Sakoe H, Chiba S. Recognition of Continuously Spoken Words based on Time-Normalization by Dynamic Programming. - J. Acoust. Soc. Japan, 1971 - 7, 9, 483-49О стр.
- Myers C. S., RabinerL. R. A Level Building Dynamic Time Warping Algorithm for Connected Word Recognition. - IEEE Trans. ASSP-29, 1981. - No. 2, 284-297 стр.
- Винцюк Т.К. Распознавание слов устной речи методами динамического программирования. Кибернетика, 1968, № 1,с. 81-88.
- Центр Речевых Технологий ЦРТ [Электронный ресурс]. – Режим доступа: htpp:// www.speechpro.ru.
- Косарев Ю.А. Естественная форма диалога с ЭВМ. Л.: Машиностроение, 1989.
- Холоденко А.Б. Использование лексических и синтаксических анализаторов в задачах распознавания для естественных языков // Интеллектуальные системы. Т. 4. Вып. 1-2. 1999.
- Соколова Е.Н. Алгоритмы лемматизации для русского языка // Рабочий проект многоязычного автоматического словаря на 60 тыс. словарных статей. Т. 1. Лингвистическое обеспечение. М., 1984.
- Карпов А.А., Ронжин АЛ, Ли ИВ. SIRIUS - cистема дикторонезависимого распознавания слитной русской речи // Известия ТРТУ. 2005. № 10.
- Oparin I, Talanov A. Stem-Based Approach to Pronunciation Vocabulary Construction and Language Modeling for Russian // Proc. of 10-th International Conference "Speech and Computer" SPEC0M'2005, Patras, Greece.
- Институт системного анализа РАН [Электронный ресурс]. – Режим доступа: http://www.isa.ru
- Чучупал В.Я, Маковкин К.А., Чичагов А.В. К вопросу об оптимальном выборе алфавита моделей звуков русской речи для распознавания речи // Искусственный интеллект. 2002. № 2.
- Института проблем управления им. В. А. Трапезникова РАН [Электронный ресурс]. – Режим доступа: http://www.ipu.ru
- Scansoft, Inc. [Электронный ресурс]. – Режим доступа: http://scansoft.com
- Scansoft, Inc. [Электронный ресурс]. – Режим доступа: http://nuance.com
- Zhozhikashvili V.A., Farkhadov M.P., Petukhova N.V., Zhozhikashvili A.V. The first voice recognition applications in Russian language for use in the interactive information systems // 9th International Conference SPEC0M'2004/St.-Petersburg: "Anatoliya", 2004.
- Karpov A.A., Ronzhin A.L. Speech Interface for Internet Service Yellow Pages // Intelligent Information Processing and Web Mining: Advances in Soft Computing, Proc. of the International IIS: IIPWM'05 Conference, Gdansk, Poland, Springer-Verlag, 2005.
- Шелепов ВЮ, Ниценко ВЮ. К проблеме по фонемного распознавания // Искусственный интеллект. 2005. № 4.
- Дорохина ГВ, Павлюкова А.П. Модуль морфологического анализа слов русского языка // Искусственный интеллект. 2004. № 3.