Распознавания слитной речи с фонетической транскрипции
Перевел с английского: Акопян А.Г.
Источник: http://acl.ldc.upenn.edu/H/H90/H90-1040.pdf
Перевел с английского: Акопян А.Г.
Источник: http://acl.ldc.upenn.edu/H/H90/H90-1040.pdf
Давно и широко расспространенная лингвистическая теория по распознаванию речи считает, что прира речевых сообщений понимается на основе промежуточного представления акустического сигнала в условиях небольшого количества фонетических знаков. Традиционная лингвистическая теория очень привлекательна по нескольким причинам. Во-первых, он обеспечивает естественный способ раздела процесса общения на разговорном языке в различных акустических, фонетических, лексических и синтаксических суб-процессах. Во-вторых, он предусматривает снижение пропускной способности на каждой последующей стадии процесса. И, наконец, кажется, должны быть отражены в развитии письменности. Поэтому не удивительно, что эта перспективная идея легла в основу нескольких ранних машин распознавания речи [1,2, 3, 4].
В этом докладе мы предлагаем то, что мы считаем самым простым и непосредственным выражением лингвистической теории в рабочей системе распознавания речи. Данная система является кульминацией череды экспериментов, проведенных на протяжении последних трех лет. Фонетический метод акустического отображения описан в [5], и результаты его применения к диктор-зависимому определению цифр и строк, приведены в [6]. Далее, новый метод лексического доступа был разработан и применен к проблеме выбора диктора, зависит от определения отдельных слов из большого словаря [7] и из которых состоят предложения [8]. Затем, внимание было обращено на дикторо-независимые фонетические транскрипции [9, 10], которые затем были использованы в распознавании слитной речи из 991 слова DARPA [11] задачи управления ресурсами [12].
В своем нынешнем виде, наши системы распознавания речи используют особый вид скрытой Марковской модели в сочетании с соответствующим алгоритмом динамического программирования для выполнения акустико-фонетического отображения. Эта часть не ограничена лексическими и синтаксическими соображениями и таким образом, словарный запас задачи не зависим. Распознавание слов, то легко рассматривается как классическая подстрока в строке редактирования проблемы, которая решается с помощью двухуровневого динамического программирования алгоритма, более низкий уровень, который выполняет лексический доступ в то время как верхний уровень выполняет функции разбора.
Наш расчет современной системы распознавания речи подается в следующем порядке. сначала мы даем обзор системы на уровне блок-схемы. Это сопровождается подробным описанием каждого из компонентов блока, акустической фонетической модели, фонетического декодера и наконец, лексического доступа и анализа методов, которые так тесно связаны между собой, что рассматриваются как единое целое. Далее следует отчет о наших экспериментальных результатах и их интерпретации.
В итоге наши результаты на DARPA задаче управления ресурсами с недоумением 9 грамматики, мы достигли 88% правильного распознавания слов с 3% вставками уступая в точности слов 85%. Фонетическая точность транскрипции была оценена непосредственно из фонетической транскрипции. В нескольких неформальных прослушивательных испытаниях, мы оценили норму вразумительности слова, что составило 75%.
Точность нашей системы по распознаванию слов не так хороша, как результаты полученные на тех же данных в некоторых других традиционных системах [13,14,15,16]. Тем не менее, мы считаем, что несколько корректируемых недостатков существующей системы несут ответственность за несоответствие. Мы надеемся внести необходимые изменения в ближайшем будущем.
Акустическая обработка сигнала на основе линейной автокорреляции интеллектуального анализа. LPC превращаются в кепстральные коэффициенты при частоте кадров сотой доли секунды. Фонетический модуль декодирования алгоритма динамического программирования применяется к 47-статичной эргодической полу-Марковской модели. Есть два очень важных пункта, которые будут сделаны в отношении данного этапа обработки. Во-первых, не лексическая или синтаксическая информация любого рода доступна фонетическому декодеру. Во-вторых, после окончания расшифровки, звуковой сигнал сбрасывается. Все что остается, его фонетическая транскрипция и продолжительности, в сотых долях секунды, в каждой фонетической единице транскрипции.
Лексический доступ и анализ отдельных функций концептуально объединены здесь в двухуровневый алгоритм динамического программирования. На нижнем уровне находится лексическая часть, а верхний уровень выполняет грамматический анализ. Оба эти аспекта тесно связаны между собой. DP Алгоритм просто выполняет редактирование подстроки в строке, в котором ошибка охваченных фонетический транскрипций отображается в предложениях обычной орфографии. Лексика используется просто, давая фонетическую транскрипцию каждого слова словаря, произнесенных в форме цитаты. Грамматика является строгой правильной линейной грамматикой без нулевых производств.
Вся система реализована на языке Фортран-77 и работает на Alliant FX-80. Поскольку фонетическое и лексическое декодирование этапа доступа с высокой степенью внутреннего параллелизма, мы можем использовать архитектуру FX-80 в полной мере, в результате время выполнения 15 раз в режиме реального времени для типичного предложения.
Мы применили эту систему к задаче [11] Управления Ресурсами перспективных исследовательских программ Naval, позволяет запрашивать и отображать различными способами, статус 180 кораблей флота. Словарь составляет 992 слова, в том числе молчание и грамматика налагает чрезвычайно стилизованные слова, приводящие к энтропии около 4.4 бит/слово.
Теперь обратим наше внимание на отдельные компоненты этой системы.
Сигнал обрабатывался с дискретизацией 8 кГц и анализировался с помощью скользящего окна 30 мс. с частотой кадров 100 Гц. Спектр  , был представлен с использованием 12 кепстральных коэффициентов, где приближенное соотношение между спектральной величиной и в результате кепстральные коэффициенты определяются как
, был представлен с использованием 12 кепстральных коэффициентов, где приближенное соотношение между спектральной величиной и в результате кепстральные коэффициенты определяются как
 (1)
(1)
Кепстральные коэффициенты были вычислены от автокорреляционных коэффициентов через LPC [17] и они были использованы в [18]
 (2)
(2)
Двенадцать дополнительных параметров были получены путем вычисления дифференциальных кепстральных коэффициентов,
 , которые содержат важную информацию о временной скорости изменения кепстральных коэффициентов, и приведены в [19]
, которые содержат важную информацию о временной скорости изменения кепстральных коэффициентов, и приведены в [19]
 (3)
(3)
Комбинируемые кепстральные и дельта кепстральные векторы образуют набор из 24-параметров наблюдения векторов  , которые были использованы во всех экспериментах, описанных ниже.
, которые были использованы во всех экспериментах, описанных ниже.
Принято считать, что речевые акустические проявления основных фонетических кодов имеют сравнительно мало символов. Код, однако, чисто психическое представление разговорного языка и таким образом, непосредственно не наблюдается. С тех пор, как скрытая Марковская модель охватывает неразличимую Марковскую цепь и набор случайных процессов, которые могут быть непосредственно взвешены, она кажется самой естественной, чтобы представить доклад как скрытую Марковскую цепь, в котором скрытые состояния соответствуют предполагаемым неразличимым фонетическим символам и зависимые случайные процессы дают отчет об изменчивости заметной акустической манифестации фонетической символьной передачи.
Модель, которую мы используем, чтобы представить акустический фонетический строй английского языка является бесступенчатой продолжительностью скрытой Марковской модели (CVDHMM) [5]. Состояния модели,  , представляют собой скрытую фонетическую единицу. Структура языка моделируется к первой порядковой аппроксимации, матрицей изменения состояний,
, представляют собой скрытую фонетическую единицу. Структура языка моделируется к первой порядковой аппроксимации, матрицей изменения состояний, 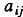 , который определяет вероятность случая статической (фонемы)
, который определяет вероятность случая статической (фонемы)  в момент
в момент  обусловлено состоянием (фонемы)
обусловлено состоянием (фонемы)  в момент времени t, где
в момент времени t, где  длительность фонемы i. Информация о временной структуре из скрытых элементов содержится в множестве плотностей
длительность фонемы i. Информация о временной структуре из скрытых элементов содержится в множестве плотностей  . Акустической корреляцией фонем являются наблюдения, обозначается , и их распределения, которые определяется набором наблюдений плотности
. Акустической корреляцией фонем являются наблюдения, обозначается , и их распределения, которые определяется набором наблюдений плотности  .
.
Плотности распространения гаммы 3-параметрами
 (4)
(4)
где Г(х) есть обычная функция гаммы. Плотности наблюдения - многомерные Гауссовы распространения. Обратите внимание, что оба переходных состояния проиндексированы, а не начальное состояние. Это дает элементарную возможность объяснить коартикулярные явления.
Полная модель таким образом, состоит из множества n состояний (фонемы), переходное состояние
вероятностей, ,  ; наблюдения означает,
; наблюдения означает,  , ; наблюдения
ковариации,
, ; наблюдения
ковариации,  , ; и durational параметры,
, ; и durational параметры,  и
и  , ; где
средняя продолжительность связана с переходным состоянием i в j
, ; где
средняя продолжительность связана с переходным состоянием i в j  и дисперсию продолжительности
и дисперсию продолжительности
 .
.
При n = 47 фонетических единиц, модель имеет 191 000 параметров во всех.
Так как мы определяем каждую фонетическую единицу с уникальным состоянием CVDHMM, как описано
выше, фонетическая транскрипция, сводится к задаче нахождения наиболее вероятного состояния последовательности модели, соответствующую последовательности акустических векторов,  .
.
Мы делаем это путем нахождения статических и последовательности длительностей с вероятностью совместного максимального O. Необходимая оптимизация осуществляется с использованием модифицированного Витерби [20] алгоритма.
Пусть  обозначает максимальную вероятность
обозначает максимальную вероятность  более всех статических и продолжительности
последовательностей прекращения статического i. Эта величина может быть оценена рекурсивно по утверждению
более всех статических и продолжительности
последовательностей прекращения статического i. Эта величина может быть оценена рекурсивно по утверждению
 (5)
(5)
 где
где  является минимальныv значением величины
является минимальныv значением величины 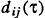 определяется и
определяется и  является максимальной допустимой продолжительностью любой фонетической единицы.
является максимальной допустимой продолжительностью любой фонетической единицы.
Если на каждом этапе рекурсии на t и j значения i и , которые максимизируют (5)
сохраняется, то можно проследить через  массив для получения наилучшего состояния и продолжительности последовательности
массив для получения наилучшего состояния и продолжительности последовательности
 (6)
(6)
1. Lesser, V. R., FenneU, R. D., Erman, L. D. and Reddy, D. R., "Organization of the HEARSAY-II Speech Understanding System," IEEE Trans. Acoust. Speech and Signal Processing, ASSP-23, pp. 11-24, 1975.
2. Woods, W. A., "Motivation and Overview of SPEECHLIS: An Experimental Prototype for Speech Understanding Research," IEEE Trans. Acoust. Speech and Signal Processing, ASSP-23, pp. 2-10, 1975.
3. Jelinek, F., "Continuous Speech Recognition by Statistical Methods," Proc. IEEE, Vol. 64, pp. 532-556, 1976.
4. Mercier, G., Nouhen, A., Quinton, P. and Siroux, J., "The KEAL Speech Understanding System," in Spoken Language Generation and Understanding, J. C. Simon, Ed., D. Reidel, Dordrecht, The Netherlands, pp. 525-544, 1979.
5. Levinson, S. E., "Continuously Variable Duration Hidden Markov Models for Speech Analysis," Computer Speech and Language, Vol. 1, No. 1, pp. 29-46, March, 1986.
6. Levinson, S. E., "Continuous Speech Recognition by Means of Acoustic/Phonetic Classification Obtained from a Hidden Markov Model," Proc. ICASSP-87, Dallas, TX, pp. 93-96, Apr., 1987.
7. Levinson, S. E., Ljolje, A. and Miller, L. G., "Large Vocabulary Speech Recognition Using a Hidden Markov Model for Acoustic/Phonetic Classification," Proc. ICASSP-88, New York, NY, pp. 505-508, Apr., 1988.
8. Miller, L. G. and Levinson, S. E., "Syntactic Analysis for Large Vocabulary Speech Recognition Using a Context-Free Covering Grammar," Proc. ICASSP-88, New York, NY, pp. 271-274, Apr., 1988.
9. Levinson, S. E., Liberman, M. Y., Ljolje, A. and Miller, L. G., "Speaker Independent Phonetic Transcription of Fluent Speech for Large Vocabulary Speech Recognition," Proc. ICASSP-89, Glasgow, Scotland, UK, pp. 441-444, May, 1989.
10. Levinson, S. E., Libennan, M. Y., Ljolje, A. and Miller, L. G., "Speaker Independent Phonetic Transcription of Fluent Speech for Large Vocabulary Speech Recognition," Proc. DARPA Workshop on Speech and Natural Language, Philadelphia, PA, pp. 75-80, Feb., 1989.
11. Price, P., Fisher, W., Bemstein, J. and Pallett, D., "The DARPA 1000-Word Resource Management Database for Continuous Speech Recognition," Proc. ICASSP-88, New York, NY, pp. 651-654, April, 1988.
12. Levinson, S. E. and Ljolje, A., "Continuous Speech Recognition from Phonetic Transcription," Proc. DARPA Workshop on Speech and Natural Language, Harwichport, MA, Oct., 1989.
13. Schwartz, R., Barry, C., Chow, Y.-L., Derr, A., Feng, M.-W., Kimball, O., Kubala, F., Makhoul, J. and Vandegrift, J., "The BBN BYBLOS Continuous Speech Recognition System," Proc. DARPA Speech and Natural Language Workshop, Philadelphia, PA, pp. 94-99, Feb., 1989.
14. Paul, D. B., "The Lincoln Continuous Speech Recognition System: Recent Development and Results," Proc. DARPA Speech and Natural Language Workshop, Philadelphia, PA, pp. 160-166, Feb., 1989.
15. Murveit, H., Cohen, M., Price, P., Baldwin, G., Weintraub, M. and Bemstein, J., "SRI's DECIPHER System," Proc. DARPA Workshop on Speech and Natural Language Workshop, Harwichport, MA, Oct., 1989.
16. Lee, C. H., Rabiner, L. R., Pieraccini, R. and Wilpon, J. G., "Acoustic Modeling for Large Vocabulary Speech Recognition," Proc. DARPA Speech and Natural Language Workshop, Harwichport, MA, Oct. 1989.
17. Tohkura, Y., "A Weighted Cepstral Distance Measure for Speech Recognition," Proc. ICASSP-86, Tokyo, Japan, pp. 761-764, Apr., 1986.
18. Juang, B.-H., Rabiner, L. R. and Wilpon, J. G., "On the Use of Bandpass Liftering in Speech Recognition," IEEE Trans. Acoust. Speech and Signal Processing, ASSP-35, No. 7, pp. 947-954, July, 1987.
19. Soong, F. K. and Rosenberg, A. E., "On the Use of Instantaneous and Transitional Spectral Information in Speaker Recognition," Proc. ICASSP-86, Tokyo, Japan, pp. 877-880, April, 1986.
20. Viterbi, A. J., "Error Bounds for Convolutional Codes and an Asymptotically Optimal Decoding Algorithm," IEEE Trans. Information Theory, Vol. IT-13, pp. 260-269, 1967.
21. Sakoe, H. and Chiba, S., "Dynamic Programming Algorithm Optimization for Spoken Word Recognition," IEEE Trans. Acoust. Speech and Signal Processing, ASSP-26, pp. 43-49, Feb., 1978.
22. Levenshtein, V. I., "Binary Codes Capable of Correcting Deletions, Insertions, and Reversals," Sov. Phys.-Dokl., Vol. 10, pp. 707-710, 1966.
23. Gray, R. M., Probability, Random Processes and Ergodic Properties, Springer-Verlag, New York, 1988, pp. 254 ff.
24. Brown, M. K. and Wilpon, J. G., "A Grammar Compiler for Connected Speech Recognition," submitted to IEEE Trans. Acoust. Speech and Signal Processing.
25. Rabiner, L. R., Wilpon, J. G. and Juang, B.-H., "A Segmental K-means Training Procedure for Connected Word Recognition," AT&T Tech. J., Vol. 65, No. 3, pp. 21-31, May-June, 1986.
26. Olive, J. P. and Liberman, M. Y., "Text to Speech: An Overview," J. Acoust. Soc. Am., Vol. 78, Supp. 1, p. 56, Fall, 1985.
27. Duifhuis, H., Willems, L. F. and Sluyter, R. J., "Measurement of Pitch in Speech: An Implementation of Goldstein's Theory of Pitch Perception," J. Acoust. Soc. Am., 71, pp. 1568-1580, 1982.
28. Levinson, S. E., "A Method for the Incorporation of a Tri-gram Model of English Phonotactics in a System for Phonetic Transcription of Unrestricted Speech," Unpublished Bell Laboratories Technical Memorandum, 1988.
29. Wagner, R. and Fischer, M., "The String-to-String Correction Problem," JACM, Vol. 21, No. 1, pp. 168-173, 1974.