Семантична інтеграція неповних та неточних даних
Автор: Берко А.Ю., Висоцька В.А.
Источник: Журнал «Системи обробки інформації», 2009, випуск 7
Вступ
Сьогодні інтеграція є одним з перспективних напрямів формування інформаційних ресурсів загального користування, зокрема, на основі сервісно-орієнтованої архітектури. Сьогодні на ринку інформаційних технологій багато провідних виробників пропонують власні інструментарії вирішення проблем інтеграції на різних рівнях, таких як інтеграція бізнес-процесів (Business Ptrocess Integration – BPI), інтеграція корпоративних застосувань (Entetrprise Application Integration- EAI), інтеграція корпоративних платформ (Platform Integration - EPI) інтеграція даних або, як часто її називають, інтеграція корпоративної інформації (Enterprise Information Integration – EII). Інтеграція даних – це завдання об'єднання даних, отриманих з різних джерел з метою подання користувачеві їх об'єднаного подання [2, 5].
Одним з важливих напрямів інтеграції в багатьох сферах застосування інформаційних технологій є інтеграція даних. Проблеми інтеграції даних є актуальними з огляду на активний розвиток корпоративних та суспільних інформаційних ресурсів, зростання їх обсягів та різноманіття способів подання. При цьому часто виникають проблеми, пов'язані з неповнотою, неточністю чи відсутністю даних у вхідних наборах. Проблеми цього роду мають декілька аспектів – способи позначення неповних чи відсутніх даних, структурування даних за умови їх неповноти, інтерпретація невизначеностей чи відсутності даних.
У запропонованій роботі розглянуто один з аспектів інтеграції інформаційних ресурсів – інтеграцію семантики даних за умов їх неточності, невизначеності чи неповноти.
Семантична інтеграція даних
Головними завданнями інтеграції даних є формування повного і несуперечного набору на основі множини різнорідних вхідних даних, отриманих з різноманітних джерел. Основні теоретичні положення та принципи інтеграції сформульовано у [2]. Для досягнення кінцевої мети інтеграції необхідно забезпечити узгодження їх синтаксису, структури і семантики [5]. У ході вирішення такого роду задач виникає низка проблем, від розв'язання яких залежать властивості кінцевого результату. На рівні інтеграції синтаксису даних:
- це неоднозначність чи суперечність алфавітів;
- невідповідність типів даних та форматів;
- невідповідність синтаксичних обмежень.
На рівні інтеграції структур даних:
- невідповідність способів визначення одиниць даних;
- суперечності видів та способів побудови зв'язків;
- різноманітність способів впорядкування даних [5].
Семантична складова процесу інтеграції є однією з найважливіших та найскладніших, оскільки проблеми синтаксису та структури, загалом, вирішують на технічному та технологічному рівні. Формування узгодженої інтерпретації інтегрованих даних є неможливим без участі людини, а також застосування методів та засобів інтелектуального опрацювання даних
На рівні інтеграції семантики виникають такі проблеми [4]:
- суперечності у визначенні концептів;
- неоднозначність чи різночитання імен;
- застосування несумісних метрик;
- суперечності у визначенні відношень між даними;
- неоднозначність інтерпретації значень
Ці проблеми вирішують різними засобами, такими як тезауруси чи словники даних, семантичний аналіз даних, онтології [5], які вважають найперспективнішим з відомих сьогодні засобом семантичної інтеграції. Основні принципи та методику інтеграції даних на основі онтологій викладено у [4].
Проблематика формування та застосування онтологій як засобу опису семантики даних у процесах інтеграції гетерогенних інформаційних ресурсів має декілька підходів [4], для кожного з яких характерними є власні моделі, способи та засоби вирішення.
Інтеграція даних на основі єдиної онтології. У цьому випадку для явної специфікації семантики різних наборів даних формують єдину глобальну онтологію зі спільними узгодженими розподіленими ресурсами [4].
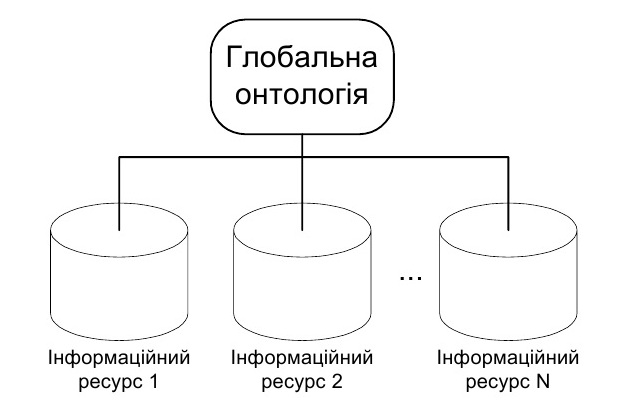
Рис. 1. Схема семантичної інтеграції даних на основі єдиної онтології
Єдину онтологію може бути сформовано двома методами :
- шляхом розподілу – при цьому утворюється глобальний опис концептів, відношень та функцій інтерпретації з розподіленими словниками, який застосовують для специфікації семантики кожного з наборів даних, які підлягають інтеграції;
- шляхом інтеграції – такий спосіб передбачає формування та поповнення глобальної онтології як результатів узгодженого об'єднання словникових ресурсів локальних онтологій, сформованих для наборів даних, які підлягають інтеграції (рис.1).
Особливістю семантичної інтеграції даних на основі єдиної онтології є спільне використання її ресурсів для опису семантики кожного вхідного набору даних.
Інтеграція даних на основі множини онтологій. У такому випадку кожен вхідний набір даних для семантичної інтеграції описують власною онтологією, яка не пов'язана з іншими і оперує власними нерозподіленими словниковими ресурсами [4]. Процес семантичної інтеграції у цьому випадку ґрунтується на узгодженні, взаємодії та обміні ресурсами локальних онтологій (рис. 2)
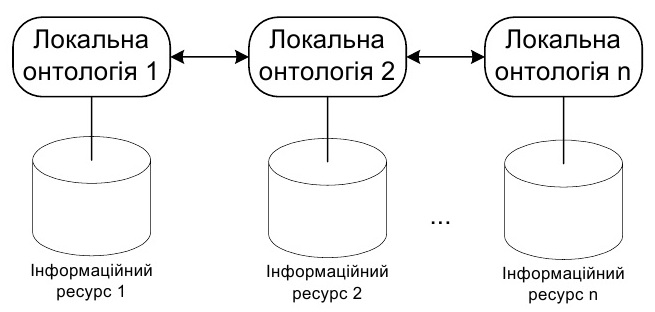
Рис. 2. Схема семантичної інтеграції даних на основі множини онтологій
Проблема інтеграції даних при цьому вимагає застосування таких методів та засобів побудови і опрацювання онтологій, які забезпечують їх спільне застосування у формуванні єдиного семантичного простору інтегрованих даних.
Гібридний підхід до інтеграції даних на основі онтологій. Такий спосіб семантичної інтеграції поєднує особливості двох попередньо описаних методів. За аналогією з єдиною онтологією, в даному випадку створюють спільний, узгоджений розподілений ресурс.
Використання цього ресурсу для специфікації семантики вхідних наборів даних відбувається через їх власні локальні онтології [5] (рис. 3)
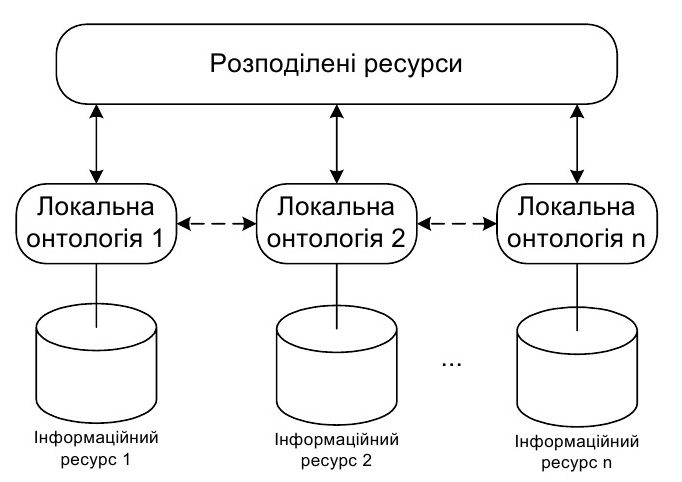
Рис. 3. Схема гібридної семантичної інтеграції даних
Аналогічно до попереднього випадку семантику інформаційного ресурсу, що підлягає інтеграції, описує окрема онтологія. Але для сумісності локальних онтологій створюють глобальні розподілені словникові ресурси, в яких зосереджено базові терміни і поняття, спільні для предметної області інтегрованих даних.
Особливо важливим у процесах інтеграції, які ґрунтуються на онтологіях є коректне опрацювання невідомих, неповних чи відсутніх даних. Неоднозначність їх походження, суті, природи, та порядку опрацювання є потенційним джерелом суперечностей у змісті інтегрованих даних та виконанні запитів до них.
Висновки
Запропонована класифікація та інтерпретація невизначеностей дозволяє не лише їх охарактеризувати і підвищити рівень детермінованості даних. Такий спосіб дозволяє уникнути можливих суперечностей при інтеграції інформаційних ресурсів, що можуть виникати за рахунок різної природи невизначеностей, а також визначити шляхи і процедури опрацювання інтегрованих даних, що містять в своєму складі невизначеності.
Описаний в цій роботі онтологічний підхід до інтеграції неповних та неточних є універсальним для різних інтеграційних методів, моделей та технологій, а також проблемно- та об'єкто-незалежним. Це, в свою чергу, забезпечує семантичну інтероперабельність даних за умови наявності в них невизначеностей, які мають різну природу, зміст та порядок опрацювання.
Список літератури
1. Date C.J. Database in Depth: Relational Theory for Practitioners / Cristopher Date. – CA.: O'Reilly, 2005. – 240 p
2. Lenzerini М. Data Integration: A Theoretical Perspective / Marco Lenzerini // Proc. of the ACM Symp. on Principles of Database. Systems, 2002. – P. 233-246.
3. Rubinson С. Nulls, Three-Valued Logic, and Ambiguity in SQL : Critiquing Date's Critique. / Claude Rubinson // SIGMOD Record Vol. 36, No. 4, December 2007, 2007. – P. 137-143.
4. Wache H. Ontology-Based Integration of Information – A Survey of Existing Approaches / H. Wache, T. Vogele, U. Visser, H. Stuckenschmidt, G. Schuster, H. Neumann and S. Hubner // Proceedings of the IJCAI-01 Workshop on Ontologies and Information Sharing, Seattle. – USA, August 4-5, 2001. – P. 108-118.
5. Берко А.Ю. Методи інтеграції синтаксису різнорідних даних у системах електронного контент-бізнесу / Андрій Берко // Інформаційні системи та мережі: Вісник Націон. ун-ту «Львівська політехніка». – Львів, 2008. – № 621. – C. 19-28