Семантическая интеграция данных при помощи RDF хранилища
Автор: Konstantin Pentchev, Vassil Momtchev
Перевод: Дмуховский Р.И.
Источник: Тhe 7th Framework Programme for Research and Technological Development.
Введение
В этой статье представлен анализ различных уровней выполнения интеграции данных. Циглер и Дитрих [1] определяют несколько уровней интеграции в зависимости от его специфики:
1) Руководство интеграции - мнимая интеграция происходит, так как интерпретация осуществляется конечным пользователем;
2) Общий пользовательский интерфейс - данные из соответствующих источников отображаются в одном окне в приложении;
3) Интеграция приложениями или промежуточная интеграция осуществляется на уровне конкретного приложения, в котором разработчики освобождаются только от реализации общей функциональности интеграции;
4) Унифицированный доступ к данным, интеграции информации, осуществляется с помощью виртуальных данных или абстрагированием от его физической структуры во время выполнения;
5) Общее хранение данных - это физическая реорганизация или репликация существующих данных на новое место и, возможно, новой глобальной схемы.
Основное правило – интеграция становится более эффективной, когда она приближается к физической памяти. Таким образом, когда мы должны работать с очень большими объемами информации, как в рамках проекта Khresmoi, наш выбор для эффективной интеграции данных практически ограничивается консолидацией данных (или хранилищем) и федеративным подходом. В следующих пунктах мы найдем компромисс между этими подходами и их влияние на разработку базы знаний.
Хранилище данных представляет собой процесс централизации информации в общую физическую модель хранения. Это требует реорганизации и консолидации всех данных в глобальной схеме, и может либо полностью заменить старые базы данных либо копировать информацию на регулярной основе. В любом случае, консолидация данных требует разработки и осуществления преобразования и загрузки скриптов, которые необходимы для выбора структуры и семантической неоднородности между источником и глобальной схемой во время загрузки данных.
Данные федерации использует другой подход, используя одинаковый уровень доступа к данным, описанным в [1], который в настоящее время часто упоминается как виртуализация данных. Виртуализация представляет собой метод абстрагирования информации от его физического хранения и организации. Это дает возможность установить источник данных между несколькими результатами во время выполнения каждого запроса. Таким образом, все структуры и семантические неоднородности должны быть решены во время выполнения, что повышает эффективность расходов. Кроме того, подход федерации хорошо известен за неспособность эффективно бороться со многими удаленными операциями соединения. Удаленное соединение является вычислительным слиянием информации между двумя распределенными физическими и / или логическими интерфейсами.
В проекте Khresmoi стратегии интеграции хранилищ данных и объединения демонстрируют значительные компромиссы, потому что велико количество семантической поддержки данных, которые должны быть эффективно обработаны. Калабрия [2] расширяет два вышеупомянутых подхода до четырех, представленные в таблице 1:
Таблица 1: Различные архитектурs интеграции данных, используемых в отрасли.
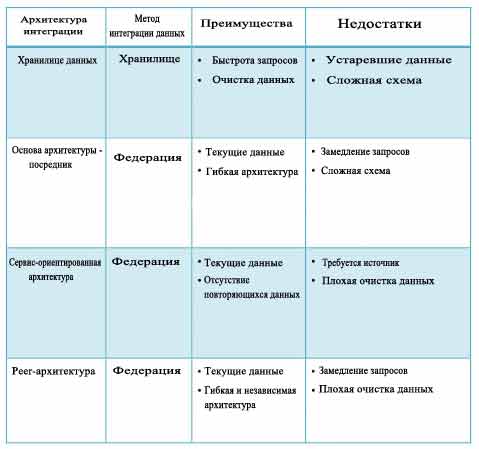
Сравнивая различные подходы в таблице 1, мы видим, что каждый имеет значительные преимущества и недостатки. Это показывает, что наилучшим решением для обработки больших массивов информации яляется хранилище, поскольку оно обеспечивает:
- вывод цепочки и материализации тривиальный неявных связей;
- высокую производительность запросов для всей информации;
- неограниченные возможности для очистки данных;
- интеграция проверки их согласованности, которая зачастую имеет решающее значение для области биомедицины;
Подход федерации и посредника на основе архитектуры для интеграции автономных источников данных, которые не могут быть воспроизведены в хранилище, потому что их содержимое обновляется слишком часто и / или из-за ограничений по безопасности. Peer-архитектура предлагает отличную гибкость, но существуют недостатки, такие как отсутствие глобальной схемы и медленное выполнение запросов.
RDF хранилище
RDF хранилище требует перевод всех источников данных RDF и загрузки заявлений в различные графы (контексты). Хранение различных наборов данных в отдельных графах имени гарантирует минимальную информацию о происхождении. Это требуется для того, чтобы поддерживать дополнительные обновления информации.
Linked Life Data (LLD) службы [3] является примером проекта RDF хранилища, который демонстрирует отличную производительность для широкого круга запросов SPARQL против миллиардов заявлений RDF. Служба опирается на высокоэффективное сохранение RDF, оптимизатор запросов и интегрированной цепочки рассуждений, что позволяет проводить индексированный поиск неявных заявлений. После того как все данные консолидируются в единую физическую структуру, правила определяют ссылки на связанные идентификаторы. На рисунке 1 показаны шесть правил, где пунктирные линии и синий текст подписи (используется либо как часть URI или литералов) обозначают критерии для связывания информации. Поскольку указанные правила отображения не универсально применимые для произвольного набора данных RDF, они с ручным управлением для каждого конкретного подмножества.
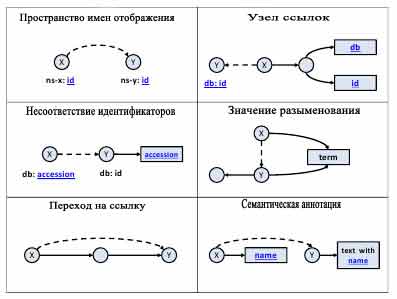
Рисунок 1 Ресурс выравнивание модели в LLD.
На рисунке 2 показаны семантические аспекты экземпляра отображения
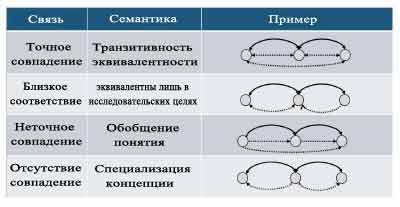
Рисунок 2: Экземпляр отображения в LLD с использованием SKOS лексики.
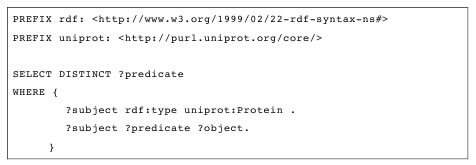
Локальное хранение данных RDF может обеспечить полный контроль над запросом оптимизации и статистику по каждому значению ассоциации, позволяя проводить расчет оптимальных планов выполнения сложных информационных соединений. Запросы с несвязанными предикатами особенно трудно оптимизировать. SPARQL запросы представленные в таблице 2 перечисляют все уникальные предикаты типов белка. Первый образец выполнен на 0,8 LLD результаты 16505340 возможных привязок. Вторая модель будет объединена с первой в результатах 5120886447 возможных привязок. Это дает в общей сложности 8.45E +16 привязок, с использованием оптимизации. Тем не менее, общее время выполнения запроса меньше чем за 60 секунд, несмотря на его чрезвычайную сложность. Но подобные типы запросов не подходят для любого рода.
Таблица 2: SPARQL запрос с несвязанными предикатами
В заключении скажем что хранилище, и LLD проект, гарантируют быструю обработку запросов, поскольку они предлагают единую модель данных, хранения базы при условии запроса стратегии оптимизации и возможности контроля качества данных и их очистки. Тем не менее, централизованный контроль над информацией, стоит денег. Каждое хранилище имеет избыточные и устаревшие данные, которые требуют регулярного обновления. В некоторых случаях, хранилище не совместимо с конкретным источником данных из-за лицензий или ограничения безопасности.