
Abstract
Сontent
- Introduction
- 1.1 Work actuality
- 1.2 The goal and the problems of the research
- 1.3 Expected scientific innovation
- 1.4 The practical importance
- 2. Review and analysis of methods for removing outliers in data
- 2.1 Kinds of data preprocessing
- 2.2 Definition of outliers and problems of their determination
- 2.3 Classification and analysis of methods for removing outliers in data
- 3. Construction of weighted training samples
- 4. Conclusion
- 5. References
Introduction
Today the problem of data quality is one of the most important problems that are solving in construction of intelligent systems. Especially critical this problem is shown at the construction of training recognition systems. Possibility of their training and functional reliability depends on quality of basic data [1].
The main difference of training recognition systems is to build a classifier as a result of training. Process of training consists in serial presentation to system the initial set of objects [2]. This is why pre-processing of data is a critical step in building recognition systems. The process of research, filtering, transformation, and data modeling to extract useful information and decision-making is called data mining [3].
1.1 Work actuality
Actuality of this work is confirmed by the number of different data preprocessing methods developed in recent years. Many modern systems should process tens and hundreds thousands objects for the minimum time therefore efficiency of systems depends on preprocessing of these objects as a whole. This is why the task of data filtering is actual scientific and technical challenge, requiring the development of modern approaches to its solution.
1.2 The goal and the problems of the research
The object of research is the problem of data filtering in training recognition systems.
The subject of the researchis the methods of defining and removing outliers in the training samples.
The purpose of the graduation Master’s work is the researching of the existing methods of determination of noise in the data and to develop a method for removing outliers from training samples.
In the course of work it is necessary to solve the following problems:
1) The research of steps of training recognition systems construction and ways of training samples preprocessing;
2) The research of methods for removing outliers in training samples and criteria of stopping the data filtering;
3) Тhe development of the method of removing outliers from data based on the analysis of weighted training samples;
4) A software development for analyzing the effectiveness of the proposed filtering data method.
1.3 Expected scientific innovation
The scientific innovation of this work is the development of the method of removing outliers in data based on the analysis of weighted training samples, what is a new direction in preprocessing of training samples of the large volume which is effectively solving problems of compression and integration of training data.
1.4 The practical importance
The practical significance of this work is the development of themethodof the data filtering, which allows improvingthe quality of the basic set of data and the efficiency of the system as a whole.
The use of weighed training samples for solving problems of compression and integration of training samples of the large volumewill offer a single method, including the performance of all three methods of data preprocessing.
2. Review and analysis of methods for removing outliers in data
2.1 Kinds of data preprocessing
Preprocessing of data is the first step in construction of recognition systems (Figure 1).
Data preprocessing in recognition systems is an iterative process that include:
1) data cleaning, which consists in removing of noise, missing data and data of poor quality;
2) data compression, which is the determination of minimal features space and representative set of data based on the methods of reduction and transformation;
3) data integration, which allows to reduce amount of datawith saving of initial information by means of heuristic algorithms.
As a result of preprocessing is formed training set used to construct classification decision rules.
In most systems, pre-processing data consist in their cleaning, when the greatest attention is given to removing noise (outliers) and data of poor quality.

Figure 1 – The construction of recognition systems
2.2 Review and analysis of methods for removing outliers in data
Outlier is an object of some class, which values of featuresare significantly different from the values of objects features of the same class [7]. Such objects in the feature space are surrounded by objects of another class and, consequently, reduce the quality of decision rules of classification.Outliers search is carried out by means of filters, that are the procedures, allowing to allocate relevant information in available initial data.
2.3 Classification and analysis of methods for removing outliers in data
Correspondence of data to a hypothesis of compactness is the basic principle of the outliers’ allocation in training samples.It consists in the fact that the objects of the same class appear in the feature space in geometrically close points, forming a "compact" clusters [9].
Methods of searching and processing of the found outliers can be divided into two groups [7]. Methods of the first group directed to outliers correction by changing the values of their attributes.Methods of the second group remove outliers by the data filtering.
The problem of the outlier detection can be solved in two ways.The first way is to select some set of objects in the original training set.The best known algorithms that implement this method areSTOLP [6] (figure 2), FRiS-STOLP [10], NNDE (NearestNeighborDensityEstimate) andMDCA (MultiscaleDataCondensationAlgorithm) [4].

Figure 2 – Result of algorithm STOLP working
The second way consists in the construction of new objects on selected objects from initial sample.Algorithm of the crushing etalons [6] (figure 3), LVQ (learningvectorquantization) [11] andw-GridDC [12].

Figure 3 – Reducing the size of training set using the algorithmof the crushing etalons
3. Construction of weighted training samples
In addition to cleaning the data pre-processingincludes problems of data compression and integration to reduce the outliers’ effect on the effectiveness of the system and to reduce the amount of stored data.
One of the most efficient methods of data compression and integration is the w-GridDC [12]. The result of this method is the construction of weighted reduced training set of w-objects.
The idea of w-GridDC method is to impose a grid on the feature space to form many cells, the definition of a sample of objects that belong to each of the cells and their replacement by w-objects.The formation of a new sample of objects is executed only if all the objects belonging to one class of cells. W-objects weight is determined by the number of objects in the original sample, belonging to the cell.
Analysis of the characteristics of the w-objects weights distribution, made in [13], shows that the weight of most w-objects increases exponentially with the increasing distance from the interclassboundaries. The majority of w-objects have less weight near the interclass boundaries. However in the weighted sample there are a number of objects with single or close to single weight.Analysis of w-objects is a way to determine outliers from samples of w-objects.
Next, we present a step by step description of the method (Figure 4). As a result, the algorithm will be obtained weighted training sample w-objects.
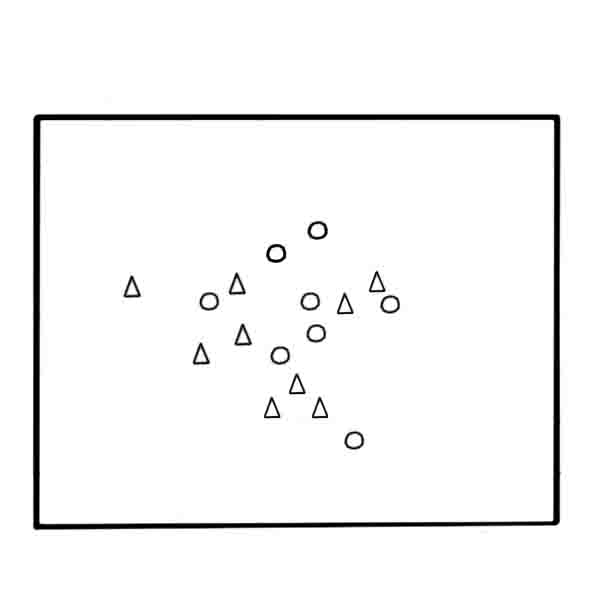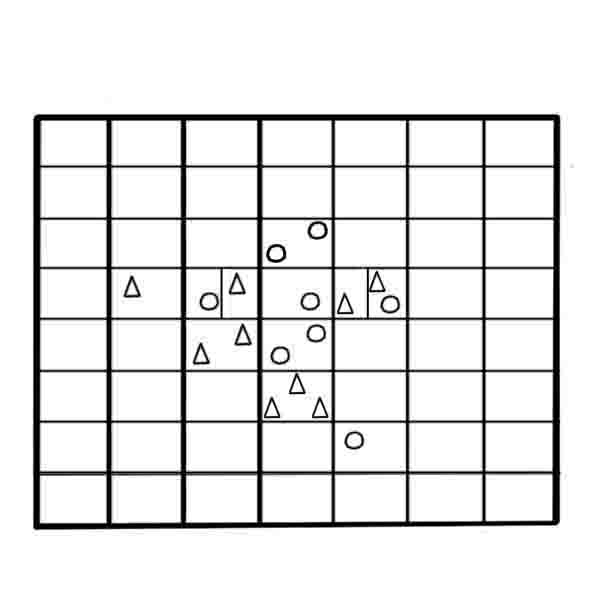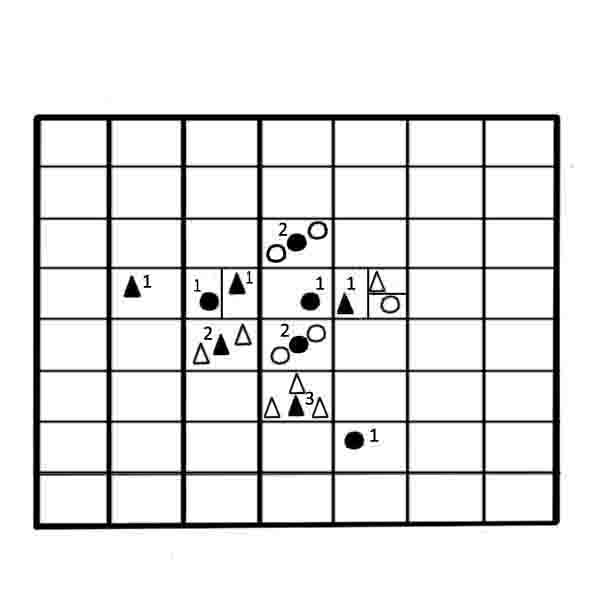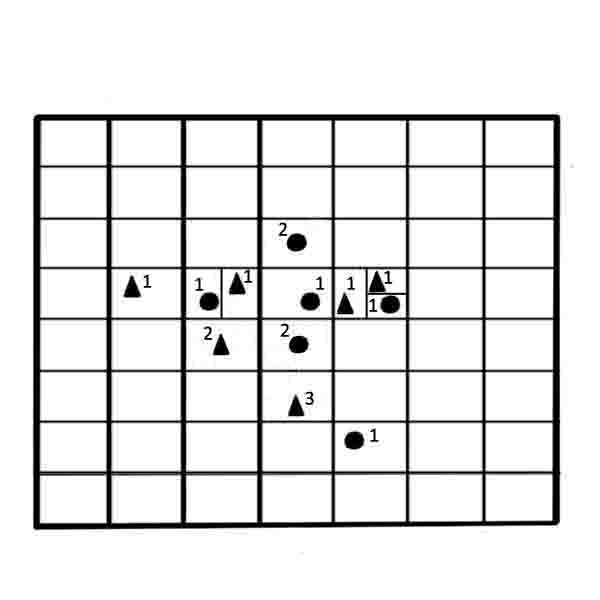
Figure 4 – Construction of the sample w-objects based on the algorithm w-GridDC
(Animation: 4 frames, 5 cycles of repetition, 130 kilobytes)
4. Conclusion
The steps of recognitions systems construction and kinds of data preprocessing were analyzed during the researches. It was shown that the solution of data preprocessing problems is a paramount importancedue to the large volume and diversity of input information. A research object is the problem of data filtering like one of the most actual problems in Data mining.
Analysis of existing methods for determining outliers in the training set was done. It showed that the training set of objects topological distribution in the feature space has the greatest impact on the selection of noise objects.
One of the most effective algorithms for data preprocessing algorithm is w-GridDC, therefore, the development of a new method for removing data outliers will be done on the basis of weighted training samples.
References
- Крисилов В.А., Юдин С.А., Олешко Д.Н. Использование гипотезы -компактности при построении обучающей выборки для прогнозирующих нейросетевых моделей // System Research & Information Technologies. – 2006. – № 3. – С. 26 – 37.
- Дуда Р., Харт П. Распознавание образов и анализ сцен. – М.: Мир, 1976. – 512 с.
- Профессиональный информационно-аналитический ресурс, посвященный машинному обучению, распознаванию образов и интеллектуальному анализу данных - Интеллектуальный анализ данных [Электронный ресурс].–Режим доступа: http://www.machinelearning.ru
- Larose D.T. Discovering knowledge in Data: An Introduction to Data Mining / D.T. Larose – New Jersey, Wiley & Sons, 2005. – 224 p.
- Pal S.K. Pattern Recognition Algorithms for Data Mining: Scalability, Knowledge Discovery and Soft Granular Computing / S.K. Pal, P. Mitra – Chapman and Hall/CRC, 2004. – 280 p.
- Загоруйко Н.Г. Методы распознавания и их применение. – М.: Сов. радио, 1972. – 208 с.
- Волченко Е.В., Кузьменко И.Ю. Анализ методов нахождения выбросов в обучающих выборках // Проблеми інформатики і моделювання. Тезиси одинадцятої міжнародної науково-технічної конференції. Секція "Молоді вчені". – Х.: НТУ "ХПІ", 2011. – С. 12 – 13.
- Дюличева Ю.Ю. О задачах фильтрации обучающих данных // Искусственный интеллект. – 2006. – № 2. – 65 – 71.
- Загоруйко Н.Г. Гипотезы компактности и -компактности в методах анализа данных // Сибирский журнал индустриальной математики. – 1998. – №1. – Том 1. – С. 114 – 126.
- Zagoruiko N.G., Borisova I.A., Dyubanov V.V., Kutnenko O.A. Methods of Recognition Based on the Function of Rival Similarity // Pattern Recognition and Image Analysis. – 2008. – Vol. 18. – №.1. – P. 1–6.
- Kohonen T. Self-Organizing Maps. – Springer-Verlag, 1995. – 501 р.
- Волченко Е.В. Сеточный подход к построению взвешенных обучающих выборок w-объектов в адаптивных системах распознавания // Вісник Національного технічного університету "Харківський політехнічний інститут". Збірник наукових праць. Тематичний випуск: Інформатика i моделювання. – Харків: НТУ "ХПІ", 2011. – № 36. – С. 12 – 22.
- Volchenko E.V. Research of features in association of training sample objects to meta-objects // 9th International Conference on “Pattern recognition and image analysis: new information technologies”: Conference Proceeding. Nizhny Novgorod, Russian Federation, 2008. – Vol. 2. – P. 291-294.