ОЦЕНКА СИСТЕМ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ
ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ:
КТО ВИНОВАТ, ЧТО ДЕЛАТЬ
Авторы: В. Ф. Хорошевский[1]
Источник: http://www.raai.org/resurs/papers/kii-2006/doklad/Khoroshevsky.rar
В
работе обсуждаются метрики для оценки качества функционирования систем
извлечения информации из текстов на естественном языке, приводится краткая
история вопроса, перечисляются основные требования к таким метрикам и на основе
сформулированных требований предлагается новая система метрик, которая должна
дать более точное представление о возможностях систем и инструмент для
корректного их сравнения. Приводятся основные результаты использования
предложенных метрик для оценки качества функционирования систем семейства OntosMiner.
Введение
Последние несколько лет автоматическая обработка текстов на естественном
языке (ЕЯ) стала одной из приоритетных задач в области новых информационных
технологий. При этом на современном этапе основное внимание исследователей и
разработчиков практически значимых ЕЯ-систем все больше сосредоточивается на
системах типа Multilingual Information Extraction (MIE), Summarization (Sum) и
Question-Answering (QA) [TIDES, 2006]. Во всех этих случаях одной из важнейших
задач является оценка качества функционирования таких систем, без чего
невозможны ни понимание достигнутых результатов, ни корректное сравнение разных
систем.
Учитывая вышесказанное, целью настоящей работы является обсуждение метрик
для оценки качества функционирования систем извлечения информации из текстов на
естественном языке, предложения по новой системе метрик, а также анализ опыта
их использования для оценки качества систем семейства OntosMiner [Хорошевский,
2006], ориентированных на извлечение информации из мультиязычных коллекций
документов. Разработка систем семейства OntosMiner осуществляется швейцарской
фирмой Ontos AG[2]
в содружестве с российской IT-фирмой АвиКомп[3].
Организовано изложение следующим образом. В следующем разделе приводится
краткая история вопроса и обсуждаются основные требования к метрикам оценки
качества систем типа IE. Затем, на основе сформулированных требований,
предлагается новая система метрик, которая должна, по нашему мнению, дать более
точное представление о возможностях разных систем и корректного их сравнения. В
разделе 3 приводятся основные результаты использования предложенных метрик для
оценки качества функционирования систем семейства OntosMiner. В заключении
намечаются пути дальнейших исследований и разработок.
1. Методы оценки систем
типа IE
1.1. Краткая история вопроса
Начало работам по метрикам оценки систем извлечения информации из текстов,
по-видимому, было положено исследованиями, которые проводились в 1991-1998 г.г.
в рамках проекта TIPSTER [TIPSTER, 2006]. Хотя, справедливости ради, следует
отметить, что первые результаты в этом направлении были получены еще в
классических работах Солтона по оценке систем информационного поиска [Salton,
et al., 1988]. И, тем не менее, применительно к задаче оценки систем типа IE,
одним из важных результатов проекта TIPSTER было создание соответствующего
стандарта de Facto. Развитие работ по данному направлению в США происходило и
происходит в рамках программы TIDES, которая стала продолжением проекта
TIPSTER. В Великобритании акцент аналогичных работ на метриках, учитывающих
использование онтологий [Maynard, 2005].
В настоящее время исследования и разработки по метрикам для оценки систем
типа IE ведутся не только в США, Великобритании, но и в континентальной Европе
[LREC, 2004], Японии [Kageura et. al., 2000] и России [Кураленок и др., 2002].
Следует однако отметить, что эти работы в значительной мере сосредоточены на
задачах оценки систем информационного поиска, кластеризации и вопрос-ответных
систем, хотя, на наш взгляд, базисом всех таких оценок должна быть
сбалансированная система метрик для оценки систем типа IE.
1.2. Метрики проекта TIPSTER и программы TIDES
Метрики, разработанные в
проекте TIPSTER и уточненные в рамках программы TIDES, неоднократно проверялись в ходе испытания различных
систем на международных конференциях TREC (Text and REtrieval Conference), MUC (Message Understanding Conference) и DUC (Document Understanding Conference) [TREC, 2003; MUC, 1993; Hovy, et al., 2005]. При этом для оценки качества функционирования систем типа
IE используются такие метрики, как точность (P), полнота (R) и
качество (F-measure). Точность оценивает количество правильно
идентифицированных объектов как процент от общего количества идентифицированных
объектов, полнота – количество правильно идентифицированных объектов как
процент от общего количества правильных объектов, а интегральной оценкой
является качество – метрика, которая является взвешенной оценкой параметров
точности и полноты.
Соответствующие перечисленным выше характеристикам расчетные формулы
определяются следующим образом [Chinchor, 1992]:
![]()
![]()
![]()
где Correct – число полностью правильно идентифицированных объектов,
Partial – число частично правильно идентифицированных объектов
(взвешиваются коэффициентом ½ от полностью правильных ответов), Spurious
– число неправильно идентифицированных объектов, Miss – число
пропущенных объектов, β – коэффициент важности R относительно P.
Не менее важны и способы усреднения результатов. В настоящее время для
этого используются два основных подхода – макроусреднение (macroaverage) и
микроусреднение (microaverage). Первый предполагает предварительное вычисление
значений метрик качества по каждому обработанному документу и последующее их
усреднение для получения оценок на корпусе документов. Во втором сначала
определяются соответствующие параметры (Correct, Partial и др.) на всем
корпусе документов, а затем производятся вычисления значений метрик качества.
Как указывается в работе [Кураленок и др., 2002], макроусреднение чаще используется
при оценке результатов поиска, а микроусреднение – для оценки результатов
кластеризации.
В дополнение к перечисленным выше метрикам для оценки качества
информационного поиска часто используется 11-точечный график полноты/точности,
измеренный по методике TREC, который отражает изменение точности в зависимости
от требований к полноте.
1.3. Существующие метрики – достоинства и недостатки
Основное требование ко всем метрикам оценки качества состоит в том, что их
значения должны быть максимальными для «хороших» систем и минимальными для
«плохих», а их изменение должно быть монотонно. Дополнительно к этому метрики
должны быть понятными и интуитивно прозрачными, эффективно вычисляться,
коррелировать с оценками эксперта-человека, но не должны допускать разные
варианты интерпретации результатов.
Достоинства существующих метрик оценки качества систем типа IE определяются
тем, что они отвечают основному критерию, указанному выше и эффективно
вычислимы, а также понятны эксперту.
Вместе с тем эти метрики не всегда коррелируют с мнением экспертов и
допускают различные интерпретации результатов. Кроме того, существенным
ограничением существующих метрик является их ограниченность и неполнота. Так,
они оценивают качество выделения из текстов «элементарных» сущностей (например,
объектов типа Person, Organization, Location и др.), но при этом не учитывают
точность и полноту выделения артефактов, относящихся к выделенным сущностям
(например, атрибутов типа JobTitle, Time и др.). Практически нет хороших метрик
для оценки качества выделения отношений между выделенными объектами, а если
такие метрики используются, то они, по существу, «штрафуют» систему несколько
раз за одну и ту же ошибку [LREC, 2004]. И, наконец, последнее по счету, но не
по важности ограничение существующих метрик состоит в том, что они практически
не учитывают значимость компонент выделенных объектов и отношений в тех
случаях, когда те имеют внутреннюю структуру (например, если при выделении
объекта типа Person правильно обработаны имя и отчество, а фамилия, в случае
сложных фамилий, выделена лишь частично, то, независимо от важности
составляющих, в расчетные формулы этот объект войдет как Partial с
коэффициентом ½).
Таким образом, в настоящее время уже имеется явная потребность в
разработке более адекватных метрик для оценки качества систем извлечения
информации из текстов.
2. Система метрик для
оценки качества извлечения информации из текстов
2.1. Основные требования к
системе метрик
Учитывая вышесказанное основные требования к предлагаемой ниже системе
метрик – следующие:
·
Монотонность всех метрик и системы метрик в целом.
·
Сбалансированность всех метрик системы.
·
Понятность и интуитивная прозрачность отдельных метрик и системы метрик в целом
для эксперта-человека.
·
Однозначность интерпретации результатов оценки.
·
Возможность интегральной оценки качества.
·
Эффективная вычислимость всех метрик и системы метрик в целом.
·
Адекватность текущему уровню теории и практики создания систем извлечения
информации из текстов и возможность их обобщения в будущем.
При этом предлагается сохранить в качестве базиса для новой системы метрик
сохранить существующие оценки – точность, полноту и F-меру.
Требование монотонности имеет тот же смысл, что и у существующих метрик, но
предполагается, что в области их определения не должно быть «провалов».
Сбалансированность метрик системы означает, что все предпочтения должны
специфицироваться явно. Что касается требования понятности и интуитивной
прозрачности, а также связанного с ним требования однозначности интерпретации
результатов оценки, то здесь прежде всего имеется ввиду четкость определения и
измерения параметров, входящих в расчетные формулы. Требование возможности
интегральной оценки качества важно с точки зрения сравнения разных систем
независимо от тех алгоритмов обработки, которые в них реализованы. При этом
предполагается наличие и скалярной, и векторной итегральной оценки. Требование
эффективной вычислимости всех метрик и системы метрик в целом очевидно и в
специальном обсуждении не нуждается. Иначе обстоит дело с последним
требованием, соответствие которому преполагает, что с увеличением мощности
существующих систем извлечения информации из текстов новая система метрик будет
естественным образом расширяться и пополняться с возможностью сохранения
оправдавших себя на практике метрик существующей системы.
По нашему мнению, реализация этих требований должна дать более точное
представление о возможностях разных систем и корректного их сравнения.
2.2. Предложения по новой системе метрик
Как указывалось выше, новая система метрик должна опираться на четкие и
однозначные определения параметров, входящих в расчетные формулы, что влечет за
собой однозначность в их измерении. Поэтому прежде, чем перейти к обсуждению
собственно системы метрик, остановимся на спецификации их параметров.
2.2.1. Спецификация параметров новой системы метрик
Известно, что для существующих метрик оценки качества систем типа IE параметры
их опираются на аннотации объектов (NEs). В качестве модели аннотаций в
настоящее время, как правило, используется подход, принятый в проекте TIPSTER
[TIPSTER, 2006]. Представляется, что такой подход может с успехом
использоваться и в новой системе метрик.
Будем полагать, что аннотация представляется в формате, где явно
специфицированы тип выделенного объекта (отношения) и его атрибуты, а также
расположение аннотации в тексте относительно его начала (OffSets). Тогда общая стуктура аннотации – следующая:
<AnnName is_a AnnType; StartOffSet =
Number; EndOffSet = Number;
Attr1 = Value1; … Attrn = Valuen >
Для простоты будем считать, что значениями атрибутов могут быть
элементарные типы данных (например, string, integer и т.п.) или их одномерные
массивы.
2.2.2. Оценка точности выделения объектов
С учетом требований, перечисленных выше, расширим определение точности для
объектов следующим образом:
Правильно идентифицированным будем называть такой объект, который, по
мнению эксперта, зафиксирован в тексте правильно (правильны значения типа
объекта и его OffSets) и все существенные атрибуты объекта тоже правильны
(значения OffSets правильны, а имена атрибутов заполнены правильными
значениями).
Таким образом,
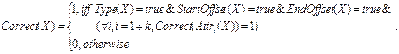
Тогда, по аналогии, полностью неправильно идентифицированный объект
фиксируется следующей формулой:
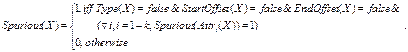
Иначе обстоит дело с частично правильно идентифицированными объектами,
так как в этом случае необходимо не только фиксировать данный феномен, но и
правильно оценить «тяжесть» допущенных ошибок.
Понятно, что объект X можно рассматривать как Partial лишь в том
случае, если Type(X) = true. Тогда для фиксации феномена целесообразно использовать формулу вида:
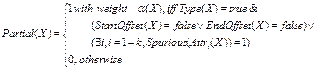 , где
, где ![]() и
и
![]()
![]()
![]()
![]()
В приведенных выше формулах α(X) , ε(X) и δ(X) – коэффициенты качества
обработки всего объекта, атрибутов объекта и качества фиксации позиций объекта
в тексте соответственно, а γ и ω – веса атрибутов
и Offsets, причем 0 ≤
γi ≤1 и Σ γi = 1; 0 ≤ ωStartOffset ≤1; 0 ≤
ωEndOffset ≤1 и (ωStartOffset + ωEndOffset ) = 1.
С учетом введенных выше понятий
![]()
2.2.3. Оценка точности выделения отношений
Оценки точности выделения отношений, в отличие от объектов, в настоящее
время практически не имеют устойчивых метрик. На наш взгляд такая ситуация
связана с тем, что, во-первых, сами отношения лишь недавно стали обрабатываться
в системах типа IE, а
во-вторых, сложность их оценки значительно выше, чем сложность оценки объектов.
Поэтому, прежде чем вводить метрики для оценки качества выделения отношений,
сформулируем ограничения, которым такие метрики должны удовлетворять:
·
В силу того, что эксперты устойчиво фиксируют наличие отношений, но расходятся
во мнении об экспликации их позиций в тексте, исключим из соответствующих
метрик параметры OffSets (заметим, что часто отношение «размыто» в рамках
предложения и даже всего текста уже по самой природе ЕЯ).
·
При оценке качества выделения отношений необходимо учесть эффекты наведенных
ошибок, связанных с неверной обработкой объектов и\или атрибутов, которые
специфицируют его актанты (нельзя «наказывать» за одну и ту же ошибку несколько
раз).
·
Так как качество выделения отношения зависит не только от качества выделения
актантов, но и от качества его собственной обработки, необходимо в
соответствующих метриках явно оценивать и ту, и другую составляющие.
С учетом вышесказанного, введем определение точности для отношений
следующим образом:
Правильно идентифицированным будем называть такое отношение, которое, по
мнению эксперта, присутствует в тексте и выделено системой, причем тип
отношения между правильно выделенными обязательными актантами определен
правильно и все существенные атрибуты отношения тоже правильны. Т.е.,
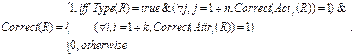
Тогда полностью неправильно идентифицированное отношение можно фиксировать
следующей формулой:
![]()
Для частично правильно идентифицированных отношений, как и в случае
объектов, необходимо правильно оценить «тяжесть» допущенных ошибок. Отношение R естественно оценивать
как Partial, только если Type(R) = true. Тогда для фиксации
феномена на верхнем уровне можно использовать формулу вида:
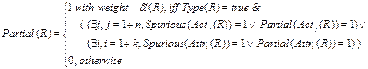 , где
, где ![]() и
и
![]() , причем
, причем
![]()
![]()
![]()
![]()
В приведенных выше формулах ![]() – коэффициенты качества
обработки всего отношения, его атрибутов и качества выделения актантов
отношения соответственно, γ – веса атрибутов, причем 0 ≤
γi ≤1 и Σ γi = 1.
– коэффициенты качества
обработки всего отношения, его атрибутов и качества выделения актантов
отношения соответственно, γ – веса атрибутов, причем 0 ≤
γi ≤1 и Σ γi = 1.
Тогда
![]()
2.2.4. Оценка полноты выделения объектов и отношений
В оценках полноты в классическом варианте участвуют, по сути дела, те же
параметры, что и в оценках точности, за исключением параметра Miss, характеризующего
количество пропущенных системой объектов и\или отношений. Поэтому, определив
этот параметр, как
![]()
![]()
можно, по аналогии с оценками точности, предложить следующие оценки для
полноты:
![]()
![]()
2.2.5. Интегральные оценки качества
В предлагаемой системе метрик для точности и полноты введены по две оценки
– для объектов и отношений.
Для получения интегральной оценки точности целесообразно взвесить PNE и PR коэффициентом их
относительной важности βp по аналогии с F-мерой:
![]()
Аналогично точности для интегральной оценки полноты взвесим и их
коэффициентом относительной важности βr:
![]()
Тогда интегральная оценка качества функционирования систем типа IE останется той же, что и
в классическом случае:
![]()
Однако теперь здесь учтены все составляющие, рассмотренные выше.
2.2.5. Усреднение результатов
В соответствии с двумя основными способами усреднения результатов
(макроусреднение – macroaverage и микроусреднение – microaverage) введем в
рассмотрение соответствующие метрики качества.
Для случая макроусреднения
![]()
![]()
![]()
Для микроусреднения коллекция документов рассматривается, по существу, как
единый большой документ. Поэтому
![]()
![]()
![]()
Понятно, что «цена» ошибки в первом случае выше, чем во втором.
3. Эксперименты с
системами метрик
3.1. Общие замечания
Очевидно, что для проверки предложенных метрик необходимо иметь реальную
систему типа IE, которая бы поддержала соответствующие эксперименты. В данной
работе для этого использовался процессор OntosMiner/Russian, разработанный и
реализованный в проекте OntosMiner, ориентированном на создание семейства
систем типа MIE (Multilingual Information Extraction) [Хорошевский, 2004]. В
этом проекте создана и запатентована технология создания прикладных систем
обработки ЕЯ-текстов, опирающаяся на мощную многоплатформенную инструментальную
среду GATE (General Architecture for Text Engineering) из Шеффилдского
университета Великобритании [Cunningham et. al., 2002]. В рамках этой
технологии модифицирована часть компонент среды GATE, а также разработаны и
реализованы специализированные компоненты обработки ЕЯ-текстов, в том числе
·
лексическое форматирование текстов, что обеспечивает выделение элементарных
единиц (слова, знаки препинания, числа и т.п.), необходимых для дальнейшей
обработки;
·
фрагментирование текстов на предложения;
·
морфологический анализ отдельных лексических единиц;
·
выделение в тексте предикатных конструкций (глаголов и аналитических глагольных
форм);
·
выделение в тексте отдельных поименованных сущностей, фиксирующих семантически
значимые с точки зрения предметной онтологии понятия;
·
семантический анализ и семантическая интерпретация полученных предыдущими
компонентами результатов, выполняемые под управлением предметной онтологии с
целью построения когнитивных карт, описывающих смысл обрабатываемых текстов.
Процессор OntosMiner/Russian ориентирован на обработку корпоративных
документов и статей с новостных сайтов Интернет, в основном, по тематике
«Бизнес: Люди и Компании». В текущей версии он обрабатывает семантически
значимые объекты и отношения, перечисленные в Табл.1.
Табл. 1. Типы объектов и
отношений,
обрабатываемых OntosMiner/Russian
|
Объекты (Поименованные
сущности) |
||
|
1. |
Person |
Физические лица (ФИО) |
|
2. |
JobTitle/Title |
Должности и титулы |
|
3. |
Organization |
Юридические лица (компании, университеты и т.п.) |
|
4. |
Location |
Геоимена (страны, города и т.п.) |
|
5. |
Date/Period |
Время |
|
6. |
Money/Percent |
Деньги/Проценты |
|
Семантические отношения |
||
|
1. |
BeEmployeeOf |
Работать-Служить (в организации) |
|
2. |
LocatedIn |
РасполагатьсяВ (для организаций) |
|
3. |
TheSame? |
Отношение орфо-синонимии между объектами |
|
4. |
ConnectedWith |
Возможна семантическая связь между объектами |
|
5. |
PresentedIn |
Объекты представлены в одном документе |
Предполагается развитие этого процессора в части номенклатуры типов
объектов и отношений, значимых для полномасштабной обработки документов
указанных выше типов.
3.2. Корпус документов
Для оценки качества процессора OntosMiner/Russian был сформирован корпус
документов, которые могут быть отнесены к предметной области, поддерживаемой
этим процессором. Документы брались с русскоязычных новостных сайтов Интернет.
Типичные примеры фрагментов текстов из данного корпуса представлены ниже.
Doc-1:
REGNUM, 09.02.2006 09:54
Комитет по экологии Госдумы будет настаивать на приостановке деятельности
ПО "Маяк"
8 февраля в Государственной Думе состоялось заседание комитета по экологии.
Основной темой повестки дня стало обсуждение экологических проблем, связанных с
деятельностью ПО "Маяк", по результатам поездки в Озёрск, сообщили
корреспонденту ИА REGNUM в пресс-центре Уральского Межрегионального
координационного совета партии "Единая Россия"…
Справка: Федеральное государственное унитарное предприятие (ФПГУ)
"Производственное объединение "Маяк" - предприятие ядерного
оружейного комплекса России. Оно входит в состав Федерального агентства по
атомной энергии Российской Федерации.
ПО "Маяк" - единственное в России предприятия по переработке
отработанного ядерного топлива. На предприятии перерабатывают ядерные отходы с
1977 года. Комбинат обслуживает Кольскую, Нововоронежскую и Белоярскую атомные
станции, а также перерабатывает ядерное топливо с атомных подводных лодок и
из-за рубежа.
Doc-2:
РИА "Новости", 15.05.2006
00:47
Мосгорсуд рассмотрит вопрос об освобождении из-под стражи Адамова
Мосгорсуд в понедельник рассмотрит вопрос об
освобождении из-под стражи бывшего главы Минатома Евгения Адамова, обвиняемого
в мошенничестве и превышении должностных полномочий…
Басманный суд Москвы 14 мая прошлого года заочно выдал санкцию на арест
Адамова. Россия и США добивались от Швейцарии выдачи Адамова. США прислали
официальный запрос об экстрадиции российского экс-министра 24 июня, а Россия -
17 мая прошлого года. Федеральный суд Швейцарии 22 декабря 2005 года отменил
решение швейцарских властей об экстрадиции Адамова в США и признал приоритет
российского запроса о выдаче бывшего министра.
Doc-3:
...Основой империи семьи Лужкова считается ЗАО «Интеко», 99% акций которого
принадлежит Елене Батуриной и 1% - ее брату, Виктору Батурину. О масштабах
семейного бизнеса стало известно после того, как в 2003 году компания решила
разместить облигации на российском фондовом рынке, и ради этого была вынуждена
раскрыть свои карты. Как оказалось, «Интеко» в разной мере контролирует более
десятка крупных компаний, включая «ДСК-3», «Осколцемент», «Интеко-Пласт»,
«Бистро-Пласт», «МНПЗ-Нефтехим». Также, по данным газеты «Ведомости», в группу
«Интеко» входит АКБ «Русский земельный банк»…
В апреле 2004 года Юрий Лужков почти два дня провел в Батуми на переговорах
с Асланом Абашидзе, тогда еще главой Аджарии. В СМИ этот визит назвали
политическим. Между тем, если о целях того визита поинтересоваться у рядового
жителя Батуми, то он бы, скорее всего, назвал визит деловым…
Doc-4:
Глава иранского МИДа прибыл в Берлин
Министр иностранных дел Ирана Манучер Моттаки прибыл в Берлин на встречу со
своим немецким коллегой, передает MIGnews.com. Пресс-служба немецкого МИДа
сообщает, что в ходе встречи официальный представитель Тегерана назовет точную
дату, до которой иранские власти дадут свой ответ на международный ультиматум.
Перед поездкой Моттаки заявил, что «мировое сообщество не должно
ограничивать время Ирана на обдумывание пакета предложений до встречи членов
большой восьмерки».
Напомним, что как американские, так и европейские политики призвали Иран
ускорить процедуру принятия решения. «Мы рассчитывали получить ответ на наши
предложения в течение недели, максимум двух. Мы не намерены ждать месяцы пока
иранские власти соизволят огласить свое решение», — заявил 22 июня президент
Буш. С подобным заявлением к иранским властям обратился и президент Франции Жак
Ширак.
Версия для печати
//KM.RU (главная)
СУББОТА, 24.06.2006, 18:57
KMnews
Doc-5:
Глава МИД Армении выступил в ООН
Министр иностранных дел Армении В.Осканян выступил 21 июня в Женеве на
открытии сессии новосозданного Совета по правам человека ООН, пишет REGNUM.
Как сообщили в пресс-службе МИД Армении, в церемонии открытия приняли
участие Генеральный секретарь ООН К.Аннан и Верховный комиссар ООН по правам
человека Л.Арбур…
Д.Буш встретится с М.Саакашвили
Вопросы урегулирования абхазского и югоосетинского конфликтов будут
главными темами встречи президентов Грузии и США Михаила Саакашвили и Джорджа
Буша, передает ИА REGNUM.
Об этом журналистам в Тбилиси заявил заместитель помощника государственного
секретаря США Мэтью Брайза.
Как подчеркнул Брайза, «одной из главных тем встречи президентов будет
вопрос политического мирного урегулирования конфликтов на территории Грузии —
конфликты должны быть урегулированы мирным политическим путем и, что самое
главное, в рамках территории, признанной международным сообществом». …
Doc-6:
Осипов Юрий Сергеевич
академик (210 упоминаний в СМИ)
...Главное требование к кандидатам, по словам академика Ю. С. Осипова,-
высокий профессиональный уровень, большой вклад в науку и активность в научных
исследованиях.... 26.05.06 Cnews…
Что он/она говорит
Законы о науке все еще не действуют
...Как заявил президент РАН Юрий Осипов, с 1 января зарплата ученым
увеличена на 20%.... 11.02.05 Известия Науки
С осени 2006 года средняя зарплата сотрудников РАН составит более 8 тыс
рублей- Юрий Осипов
..."К 2008 году, как и планировалось, мы выйдем на средний показатель
в 30 тыс рублей",- добавил Осипов.... 24.05.06 АМИ-ТАСС …
...А если мы еще вспомним, что Тобольск- это родина нынешнего президента
Российской академии наук Юрия Осипова, и вспомним слова Ломоносова о том, что
Россия будет прирастать Сибирью, то все увязывается в логическую цепочку, такой
мостик между прошлым и настоящим",- сказал МироновИ когда я узнал, что в
Тюменской области педагогам поднимают зарплату, я подумал, что губернатор
Собянин, знает он об этом или нет, следует заветной мысли великого Менделеева.Менделеев,
например, был уверен, что в России в первую очередь необходимо повышать
жалованье учителям."Загляните в эту книгу и вы увидите, насколько она
современна сегодня..... 30.07.05 Вслух.Ру …
..."Я думаю, значительная доля ответственности за дремучее состояние
российской власти в отношении науки лежит на президенте Российской академии
наук Юрии ОсиповеВпрочем, врагов, как считает Сергей Глазьев, у научной обители
хватает внутри."В Академии наук сосредоточена огромная
материально-интеллектуальная собственность, к которой уже не раз подбирались
олигархи,- считает Глазьев, намекая на незавидное будущее институтов, которые
превратятся в случае реформы РАН в коммерческие палатки.!"... 02.03.06
http://www.vz.ru/politics/2006/3/2/24463.html
Общий объем корпуса – 1882 документа.
3.3. Оценки результатов обработки
Для
оценки результатов обработки текстов из указанного корпуса было решено
использовать объекты типа Person, JobTitle/Title, Organization
и Location, а также отношения типа BeEmployeeOf и ConnectedWith. С
одной стороны, такой набор является практически стандартным для оценок на
конференциях TREC/MUC/DUC [TREC,
2003; MUC, 1993; Hovy, et al.,
2005], а с другой – дает интересную информацию по сравнению классической и
предложенной системы метрик.
Процедура
оценки была организована следующим образом:
· 6 текстов,
случайно выбранных из контрольного корпуса, тэгировали эксперты-лингвисты.
· Результаты
ручного тегирования сравнивались с результатами обработки этих же текстов
системой OntosMiner/Russian.
· Вычисления
оценок производились по классическим формулам и формулам, предложенным в данной
работе.
При этом, для простоты, предполагалось, что точность и полнота имеют
одинаковые веса (β=1), а веса атрибутов и Offsets, если они используются
при вычислениях, тоже одинаковы (γ=1/k, где k – кол-во атрибутов, и ωStartOffset
= ωEndOffset = 1/2).
Оценки результатов обработки представлены в Табл. 2, 3, 4. В силу
значительного объема «ручных» вычислений, результаты по новым метрикам получены
только для первых трех текстов.
Табл. 2. Классические оценки
|
Объект/ Параметр |
Док |
Именованные сущности |
|||
|
Person |
JobTitle |
Organization |
Location |
||
|
Correct / Partial
/ Spurious / Miss |
1. |
4 / 1 / 0 / 0 |
10 / 0 / 0 / 0 |
15 / 3 / 1 / 2 |
9 / 0 / 0 / 0 |
|
2. |
13 / 0 / 0 / 1 |
9 / 0 / 1 / 5 |
12 / 1 / 0 / 1 |
30 / 0 / 0 / 0 |
|
|
3. |
21 / 0 / 0 / 0 |
11 / 1 / 0 / 4 |
16 / 1 / 0 / 6 |
15 / 0 / 0 / 0 |
|
|
4. |
56 / 0 / 2 / 0 |
34 / 0 / 1 / 3 |
103 / 4 / 1 / 23 |
35 / 0 / 2 / 5 |
|
|
5. |
12 / 0 / 0 / 4 |
10 / 1 / 1 / 1 |
11 / 2 / 2 / 5 |
22 / 0 / 1 / 1 |
|
|
6. |
25 / 2 / 1 / 1 |
26 / 0 / 0 / 0 |
22 / 2 / 1 / 7 |
13 / 0 / 2 / 0 |
|
Точность /
Полнота / F-мера |
1. |
0,90 / 0,90 / 0,90 |
1,00 / 1,00 / 1,00 |
0,89 / 0,82 / 0,85 |
1,00 / 1,00 / 1,00 |
|
2. |
1,00 / 0,93 / 0,96 |
0,90 / 0,64 / 0,75 |
0,96 / 0,89 / 0,92 |
1,00 / 1,00 / 1,00 |
|
|
3. |
1,00 / 1,00 / 1,00 |
0,94 / 0,72 / 0,82 |
0,97 / 0,76 / 0,85 |
1,00 / 1,00 / 1,00 |
|
|
4. |
0,97 / 1,00 / 0,98 |
0,97 / 0,92 / 0,94 |
0,97 / 0,81 / 0,88 |
0,95 / 0,88 / 0,91 |
|
|
5. |
1,00 / 0,75 / 0,86 |
0,87 / 0,87 / 0,87 |
0,80 / 0,67 / 0,73 |
0,96 / 0,96 / 0,96 |
|
|
6. |
0,93 / 0,93 / 0,93 |
1,00 / 1,00 / 1,00 |
0,92 / 0,74 / 0,82 |
0,87 / 1,00 / 0,93 |
|
Табл. 3. Предлагаемые оценки (объекты)
|
Объект/ Параметр |
Док |
Именованные сущности |
|||
|
Person |
JobTitle |
Organization |
Location |
||
|
Correct / Partial
/ Spurious / Miss |
1. |
4 / 1 / 0 / 0 |
10 / 0 / 0 / 0 |
15 / 3 / 1 / 2 |
9 / 0 / 0 / 0 |
|
2. |
13 / 0 / 0 / 1 |
9 / 0 / 1 / 5 |
11 / 1 / 1 / 1 |
30 / 0 / 0 / 0 |
|
|
3. |
21 / 0 / 0 / 0 |
11 / 1 / 0 / 4 |
16 / 1 / 0 / 6 |
15 / 0 / 0 / 0 |
|
Точность /
Полнота / F-мера |
1. |
0,90 / 0,90 / 0,90 |
1,00 / 1,00 / 1,00 |
0,83 / 0,79 / 0,81 |
1,00 / 1,00 / 1,00 |
|
2. |
1,00 / 0,93 / 0,96 |
0,90 / 0,64 / 0,75 |
0,94 / 0,88 / 0,91 |
1,00 / 1,00 / 1,00 |
|
|
3. |
0,98 / 0,99 / 0,99 |
0,99 / 0,72 / 0,82 |
0,96 / 0,71 / 0,82 |
1,00 / 1,00 / 1,00 |
|
Табл. 4. Предлагаемые оценки
(отношения)
|
Объект/ Параметр |
Док |
Отношения |
|
|
BeEmployeeOf |
ConnectedWith |
||
|
Correct / Partial / Spurious / Miss |
1. |
2 / 0 / 0 / 2 |
24 / 0 / 0 / 0 |
|
2. |
4 / 0 / 0 / 1 |
21 / 0 / 0 / 0 |
|
|
3. |
2 / 0 / 0 / 3 |
35 / 0 / 0 / 0 |
|
|
Точность / Полнота / F-мера |
1. |
1,00 / 0,50 /
0,67 |
1,00 / 1,00 / 1,00 |
|
2. |
1,00 / 0,80 /
0,89 |
1,00 / 1,00 / 1,00 |
|
|
3. |
1,00 / 0,40
/ 0,57 |
1,00 / 1,00 /
1,00 |
|
2.4. Сравнение оценок
Как показывает анализ полученных результатов, новые метрики более
«чувствительны» к ошибкам в определении Offsets, но,
вместе с тем, учитывают важность атрибутов и правильность их выделения. Так,
например, если среди атрибутов объекта типа Person (Gender, FirstName, PatrName, FamName) один
выделился неверно, точность и полнота будут выше, чем в тех случаях, когда ни
один из атрибутов не обработался правильно. Аналогичная ситуация имеет место и
для оценок отношений.
Заключение
В работе проанализированы метрики для оценки качества систем типа IE и
предложена новая система метрик, которая, по нашему мнению, дает адекватный
механизм для оценки качества таких систем и более аккуратного сравнения разных
систем данного класса. Эксперименты по использованию новой системы метрик,
проведенные на корпусе русских текстов, полученных с новостных сайтов в
Интернет, подтвердили полезность предложенной системы оценок. Вместе с тем,
эсперименты показали необходимость дальнейшего совершенствования системы
метрик. В частности, уже сейчас видна необходимость учета правильной и\или
неправильной обработки совпадающих текстуально объектов. Возможны и другие
расширения и уточнения предложенной системы метрик.
Список литературы
[Chinchor, 1992] N. Chinchor, MUC-4
evaluation metrics, In Proceedings of the Fourth Message Understanding
Conference (MUC-4), Morgan Kaufman Publishers, 1992.
[Cunningham, et.
al., 2002] H. Cunningham, D. Maynard, K. Bontcheva, V.Tablan, GATE: an
Architecture for Development of Robust HLT Applications, Proceedings of the
40th Annual Meeting of the Association for Computational Linguistics
(ACL), Philadelphia, July 2002.
[Hovy, et al.,
2005] E. Hovy, C.-Y. Lin, L. Zhou, Evaluating
DUC 2005 Using Basic Elements,
http://www-nlpir.nist.gov/projects/duc/pubs/2005papers/usc-isi-zhou2.pdf
[Kageura et. al.,
2000] K. Kageura et. al., IR/IE/Summarization Evaluation Projects in Japan,
In: Proc. 2nd International Conference On Language Resources And
Evaluation (LREC 2000), Japan, 2000.
[LREC, 2004] Proc.
4th International Conference On Language Resources And
Evaluation (LREC 2004), Lisbon, Portugal, 26-28 May 2004.
[Maynard, 2005] D. Maynard,
Benchmarking ontology-based annotation tools for the Semantic Web, UK e-Science
Programme All Hands Meeting (AHM2005) Workshop "Text Mining, e-Research
and Grid-enabled Language Technology", Nottingham, UK, 2005.
[MUC, 1993] Proceedings of the
Fifth Message
Understanding Conference (MUC- 5), Morgan Kaufman Publishers, 1993.
[Salton, et al.,
1988] G. Salton, C. Buckley, Term-Weighting Approaches, Automatic Text
Retrieval. Information Processing and Management, 24(5), 1988.
[TIDES, 2006]
J. Olive, Translingual Information Detection, Extraction and Summarization
(TIDES), http://www.darpa.mil/ipto/programs/tides/
[TIPSTER, 2006] TIPSTER Text Program,
http://www-nlpir.nist.gov/related_projects/tipster
[TREC, 2003] Proceedings of the Twelfth Text Retrieval Conference
(TREC 2003). Appendix 1, Common Evaluation Measures,
http://trec.nist.gov/pubs/trec12/appendices/measures.ps
[Кураленок и др., 2002] И. Кураленок, И.
Некрестьянов, Оценка систем текстового поиска, Программирование, 28(4), 2002.
[Хорошевский, 2004] В.Ф. Хорошевский, OntosMiner: семейство систем
извлечения информации из мультиязычных коллекций документов, Труды конференции
КИИ-2004, Тверь, Россия, 2004.