Реализация ресурса знаний в системе извлечения информации
из текста
Авторы: Д.А.Александровский,
Д.А.Кормалев, Е.П.Куршев,
Е.А.Сулейманова, И.В.Трофимов
Источник: http://www.raai.org/cai-08/files/cai-08_paper_230.doc
ИЦИИ ИПС
РАН
Введение
Задача извлечения информации из текста [1] состоит в автоматической
обработке документов с целью распознавания и выделения релевантной информации и
представления ее в структурированной форме. Практически в любой предметной
области для точного извлечения требуются априорные знания о ней — знания о
понятиях, объектах и отношениях, связанных с целями извлечения или являющихся
целями. В свою очередь, извлеченная из текстов информация
может нести в себе новые знания о предметной области и быть полезна для
дальнейшего извлечения. Тесная связь между априорной и извлеченной информацией,
а также между предметными и лингвистическими знаниями сформировала
потребность в унификации средств представления.
В статье рассматривается интегрированный ресурс знаний (РЗ) системы извлечения
информации, объединяющий базу предметных знаний и словарь.
Представление предметных знаний
Общие принципы
Ранее
[2] была предложена классификация знаний для систем извлечения
информации. Знания систематизируются по трем измерениям, которым
поставлены в
соответствие бинарные дифференциальные признаки со значениями:
«предметные» —
«лингвистические», «о классах» —
«об индивидах», «априорные» — «из
текстов». РЗ
опирается на данную классификацию с тем исключением, что грань между
априорными
знаниями и знаниями «из текстов» стирается.
В соответствии с классификацией предметные знания делятся на:
1.
«о классах», «априорные» — общие знания об устройстве мира и предметной области
в терминах концептов и типов отношений — онтология;
2.
«об индивидах», «априорные» — сведения о некоторых экземплярах концептов, их
свойствах и отношениях между ними — база априорных фактов;
3.
«об индивидах», «из текстов» — знания о свойствах конкретных объектов,
извлекаемые из текстов, — база текстовых фактов.
Пара «о классах»+«из
текстов» не представляет интереса с точки зрения задачи извлечения информации и
относится к области автоматического или автоматизированного пополнения
онтологий.
Онтология вместе с базами фактов образуют базу предметных знаний системы.
Предметные знания хранятся в РЗ в структурах, называемых элементами знаний.
Элементы знаний делятся на 4 категории:
1.
концепты;
2.
экземпляры концептов;
3.
типы предметных отношений;
4.
экземпляры отношений.
Концепты и типы отношений служат для представления онтологической
информации о предметной области и задаются априорно. Экземпляры концептов и
отношений составляют базу фактов предметной области и могут быть как
априорными, так и извлеченными из текстов (Рисунок 1).
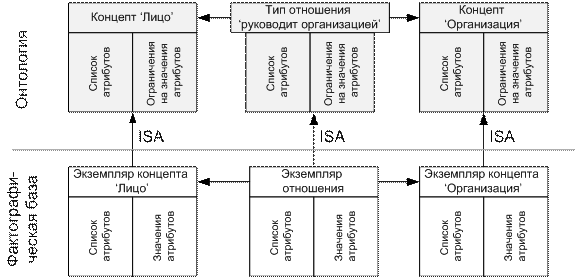
Рисунок 1. Онтология и
база фактов.
Стрелки с подписью ISA обозначают отношение инстанцирования
Элементы онтологии организованы в иерархические структуры. Нижестоящие
элементы наследуют атрибуты и свойства родителей, но могут задавать более
жесткие ограничения на значения атрибутов и свойств. Допускается множественное
(в том числе ромбовидное) наследование. При этом отслеживается
непротиворечивость и отсутствие конфликтов в атрибутах. Например, не
допускается добавление в родительский тип атрибута с именем, уже занятым в
одном из потомков, или наследование от нескольких типов, имеющих одноименные
атрибуты, не унаследованные от общего предка.
Элемент знаний «экземпляр отношения» используется не только для декларации
предметных отношений определенного типа, но и для служебных целей. Иерархия
концептов (или типов отношений) в онтологии (AKO-связи)
и отношение инстанцирования (ISA-связи)
выражаются при помощи служебных экземпляров отношений, которые не имеют
родительского типа отношений.
Типы предметных отношений
Элемент знаний «тип предметного отношения» — это связь между концептами
предметной области, за исключением отношений со специальной интерпретацией
(например, AKO) и служебных отношений, обеспечивающих
функционирование ресурса знаний. Определение типа предметного отношения
включает описание ограничений на его участников (экземпляры каких концептов
могут быть связаны экземпляром отношения данного типа), а также возможные
атрибуты экземпляров отношения данного типа. Например, отношение $должность_во_главе_орг может
связывать концепт @глава_орг с концептом @организация.
Ограничения на связь экземпляров концептов при помощи экземпляра отношения
конкретного типа могут быть и более жесткими. Например, может выполняться
проверка значений атрибутов у экземпляров концептов.
Предметные отношения (здесь и далее термин предметное отношение и тип
предметного отношения будем использовать как синонимы) содержательно можно
разделить на две группы с условными названиями отношения-«состояния»
и отношения-«события». Отношение-«состояние»
характеризуется протяженностью во времени, часто размытостью временных границ.
Предполагается, что отношения-«состояния» по большей
части бинарны. Одноместные отношения-«состояния»,
или признаки ($холост, $имеет_детей), удобнее
представлять посредством атрибутов. Многоместные отношения-«состояния»
представляются в виде композиции нескольких бинарных. Например:
$лицо_занимает_должность_в_орг (X,Y,Z)
эквивалентно
$лицо_занимает_должность (X,Y) & $должность_в_орг (Y,Z)
Отношение-«событие» обычно имеет место при смене
отношений-«состояний», имеющих один или несколько общих членов. Например, если
известно, что $возглавил (X,Y), то можно
предположить, что до события (в течение некоторого времени) не имело
место состояние $возглавляет (X, Y) и
существовал Z такой, что имело место
$возглавляет (Z, Y), а после
события (в течение некоторого времени) имеет место состояние $возглавляет (X, Y) и не
имеет место состояние $возглавляет (Z, Y).
Предметным отношениям принадлежит ключевая роль в механизме вывода новых
фактов. На основе таких свойств отношений, как симметричность, транзитивность и
т.п., и формально-логических описаний отношений можно строить достоверный вывод.
Однако с точки зрения интеллектуального анализа текста большой интерес
представляют также формализация правдоподобных рассуждений и вывод с
использованием нечетких квантификаторов.
Концепты. Свойства.
Емкость свойства
Элемент знаний «концепт» описывается посредством набора атрибутов с
указанием ограничений на значения и набором предметных отношений, в экземпляры
которых может (должен) вступать любой экземпляр концепта. Назовем свойством
концепта X такое бинарное отношение-состояние P, что X может
выступать в качестве первого элемента отношения P (т.е.
входит в область определения отношения P). Будем
говорить при этом, что отношение P проецируется на
свойство P¢, а свойство P¢ реализуется
отношением P.
Свойства концепта наследуются нижестоящими концептами. При этом возможно
введение дополнительных ограничений на область значений. Так, концепт @ректор
наследует от родительского концепта @глава_орг свойство «глава_чего»,
реализующее отношение $должность_во_главе_орг.
Область значений свойства родительского концепта состоит из концепта @организация.
При наследовании область значений свойства «глава_чего»
сужается до концепта @вуз. Аналогично, концепт @мэр наследует от
родительского концепта @глава_ГПЕ[1] свойство, реализующее
отношение $должность_во_главе_ГПЕ, сужая
область значений свойства до концепта @город.
Введем количественную меру свойства концепта — емкость.
Емкость свойства P¢
концепта X — это
число экземпляров концептов из области значений свойства, которые могут или
должны быть связаны экземпляром отношения P с любым
экземпляром концепта X. Если
емкость свойства концепта имеет ненулевое минимальное значение, то это обязательное
свойство концепта. Минимальная емкость k свойства
P¢ концепта X означает,
что существует не менее k экземпляров
концепта Y из области значений отношения P,
связанных экземпляром отношения P с любым
экземпляром концепта X.
Таким образом, полное описание свойства включает в
себя имя; емкость; тип отношения, через которое реализуется свойство; условия
для «левого» и «правого» участника (классы, высказывания об атрибутах).
Отметим, что концептуализация, лежащая в основе РЗ, ориентируется на
текстовое выражение целевой информации и устроена так, чтобы обязательные
свойства концептов «на поверхности» проявлялись как синтаксические валентности
имен — номинаций экземпляров. Где это возможно, отношения между
концептами-типами опосредуются концептами-ролями; так, отношение родства между
двумя лицами представляется в виде композиции отношений:
$родственник (X,Y)
эквивалентно
$играет_роль (X,Z) &
$родственник_чей (Z,Y),
где X и
Y — экземпляры
концепта @лицо, Z — экземпляр
концепта-роли @родственник. Отношения $мать, $отец, $сын,
$сестра и проч., являющиеся подотношениями
отношения @родственник, представляются аналогично, но с дополнительными
ограничениями на X, Y и Z.
Текстовые выражения концепта-роли @родственник и его подконцептов
имеют обязательную валентность «чей», реализующую отношение $родственник_чей.
Экземпляры
концептов
Элемент знаний «экземпляр концепта» служит моделью конкретного индивида
(объекта) предметной области. Каждый экземпляр всегда связан с концептом, от
которого экземпляр был инстанцирован (отношение ISA).
Экземпляр концепта обладает атрибутами и свойствами, определенными в
родительском концепте. Значения атрибутов и свойств экземпляра должны
удовлетворять ограничениям на значения, описанным в родительском концепте. По
определению отношений AKO и ISA,
экземпляр некоторого концепта является также инстанциацией
любого его родительского концепта.
Экземпляры
предметных отношений
Элемент знаний «экземпляр отношения» служит моделью связи определенного
типа между экземплярами концептов. Экземпляры отношений инстанцируются
от типов отношений и связаны с ними. Экземпляры отношений могут иметь атрибуты,
определенные в родительском типе отношения.
Представление лингвистической информации
Лингвистические знания, согласно
классификации [2], делятся на:
1.
«о классах», «априорные» — словарь базовой предметной лексики (сюда же можно
отнести лингвистические модели, а также правила извлечения информации);
2.
«об индивидах», «априорные» — словарь собственных имен;
3.
«об индивидах», «из текстов» — динамический словарь собственных имен (пара «о классах»+«из текстов» в контексте задачи не
рассматривается).
Лингвистическая составляющая ресурса знаний — словарь. Словарь связан с
базой предметных знаний посредством ссылок от дескрипторов к элементам знаний:
дескрипторы словаря базовой лексики ссылаются на концепты, а дескрипторы
словаря собственных имен — на априори известные экземпляры концептов из базы
фактов. Словарь базовой лексики и словарь собственных имен имеют схожее
устройство — это дескрипторные словари (дескриптор представляет множество синонимичных
выражений). В отличие от тезауруса, дескрипторы в словаре базовой предметной
лексики не связаны друг с другом никакими парадигматическими отношениями (роль
последних выполняют отношения между соответствующими элементами базы предметных
знаний). В словаре собственных имен словарным входам приписаны довольно общие
категории типа «имя лица», «название организации» (такие категориальные метки
удобно использовать на этапе извлечения первичных текстовых фактов).
Словарь предоставляет возможность указывать дополнительные ограничения на
все словоформы, входящие в состав дескриптора и синонимов, с тем
чтобы увеличить точность распознавания словарных единиц в тексте и снизить
количество морфологических вариантов, принимаемых к рассмотрению на последующих
этапах. Это могут быть: графематические
ограничения (например, регистр для аббревиатур), морфологические ограничения
(например, число, когда это существенно для различения омонимов). Для
словосочетания можно задать и структурно-синтаксические ограничения: указывается,
какое слово является главным и каков тип синтаксического подчинения зависимых.
Динамический словарь [3] имеет ту же структуру, что и словарь собственных
имен, однако его записи имеют метку «динамическая», так как они приобретаются
из текстов и имеют меньшую достоверность. Категориальная метка и
лингвистические ограничения автоматически не заполняются (их в дальнейшем может
наполнить эксперт и перенести статью в априорный словарь). В каждом дескрипторе
автоматически могут сформироваться только два синонима — форма, упомянутая в
тексте, и ее аббревиатура, сформированная по общим принципам. Кроме того,
автоматически создается ссылка на базу фактов.
Использование ресурса знаний в системе извлечения
информации
Описанный выше ресурс знаний используется на трех этапах процесса
извлечения информации:
o словарный
поиск — распознавание в тексте имен элементов знаний, внесенных в словарь;
o извлечение
информации — правила извлечения информации могут не только использовать
результаты словарного поиска (представляемые в виде специальных аннотаций), но
и обращаться к базе предметных знаний с запросами для проверки наличия
атрибутов, отношений иерархии и др.;
o построение
и добавление фактов, т.е. построение новых элементов знаний
на основе извлеченных из текста данных — на этом этапе обращение к базе
предметных знаний требуется для выполнения дополнительных правил проверки
(например, допустимости установления связи заданного типа между экземплярами),
при установлении отношения тождества между экземплярами.
Кроме этого, ресурс знаний используется клиентскими приложениями системы
извлечения информации для осуществления доступа к выявленным текстовым знаниям.
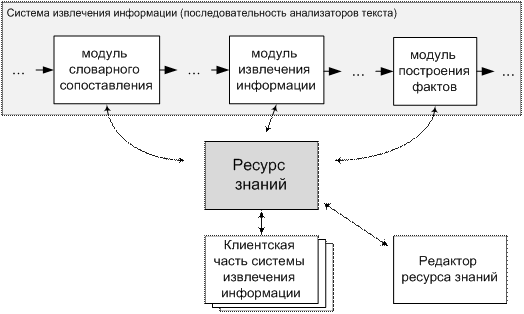
Рисунок 2. Место ресурса
знаний в системе извлечения информации
Для наполнения РЗ априорными знаниями создан специализированный редактор.
Редактор структурно разделен на две части — редактор словаря и редактор базы
предметных знаний. Для удобства работы пользователь редактора базы знаний может
создавать произвольные группы элементов знаний (представления), с
которыми в настоящий момент он работает (работать со всем объемом знаний
одновременно неудобно, и трудно отразить такое количество элементов компактно
на экране). С представлениями можно осуществлять ряд операций для получения
новых представлений (теоретико-множественные операции, операции построения
окрестности по отношениям и др.). Предметные знания удобно отражать в виде
графа, в котором всем элементам знаний соответствуют вершины (по аналогии с
диаграммами ER-типа), а дуги соединяют вершины
экземпляров отношений со связанными элементами.
Заключение
Унификация априорных и извлеченных из текстов знаний удобна тем, что
позволяет использовать одни и те же алгоритмы и инструменты для работы с обоими
типами знаний. Объединение лингвистических и предметных знаний в одном ресурсе,
во-первых, облегчает первичное наполнение и последующую поддержку, а во-вторых,
дает возможность использовать предметные знания уже на этапе первичной
обработки текста правилами извлечения информации. Благодаря специально
разработанному языку запросов к РЗ правила могут не ограничиваться словарной
информацией, а обращаться в онтологию и базу фактов для проверки различных
условий, требующих навигации по отношениям.
Работа выполнена при поддержке программы ОНИТ РАН «Фундаментальные основы
информационных технологий и систем» — проект № 2.2 «Развитие методов обработки
текста на естественном языке на основе использования неоднородных
ресурсов знаний».
Работа выполнена при поддержке научно-технической программы Союзного
государства «Разработка и использование программно-аппаратных средств Грид-технологий перспективных высокопроизводительных (суперкомпьютерных)
вычислительных систем семейства "СКИФ"» — проект «Сервис анализа
текстовой информации на базе грид-инфраструктуры».
Работа выполнена при поддержке научно-технической программы Союзного
государства «Развитие и внедрение в государствах-участниках Союзного
государства наукоёмких компьютерных технологий на базе мультипроцессорных
вычислительных систем» — проект «Исследование и разработка параллельных
алгоритмов анализа больших объемов текстовой информации из глобальной сети и
алгоритмов принятия решений на основе когнитивных методов».
Литература
[1]
Appelt D. E., Israel D. J. Introduction to
Information Extraction. Tutorial // Sixteenth Int. Joint
Conf. on Artificial Intelligence IJCAI’99,
Stockholm, Sweden, 1999.
[2] Сулейманова
Е.А. Классификация ресурсов знаний в системе извлечения информации из текста //
Математические методы распознавания образов: 13-я Всероссиийская
конференция. Ленинградская обл., г. Зеленогорск, 30
сентября - 6 октября 2007 г.: Сборник докладов. — М.: МАКС Пресс, 2007. — С.
625—628.
[3] Куршев Е.П., Кормалев Д.А.,
Сулейманова Е.А., Трофимов И.В. Исследование методов извлечения информации из
текстов с использованием автоматического обучения и реализация
исследовательского прототипа системы извлечения информации // Математические
методы распознавания образов: 13-я Всероссиийская
конференция. Ленинградская обл., г. Зеленогорск, 30
сентября - 6 октября 2007 г.: Сборник докладов. — М.:
МАКС Пресс, 2007. — С. 602—605.