Шелюк Артем Евгеньевич



Проблема інтелектуального управління даними є однією з найактуальніших тем у сучасній індустрії зберігання даних. Збільшення накопичуэмого об'єму даних промислових систем в процесі їх експлуатації приводить до ускладнення управління і подальшого аналізу на основі традиційних моделей.
За прогнозами, в 2012 р. обсяг цифрової інформації наблизиться до 1800 екзабайт, в 10 разів перевищивши обсяг цифрової інформації в 2006 р. Не менше 95% цих даних - це важко піддаються управлінню неструктуровані дані, наприклад електронна пошта, документи Word, відео і т.п., причому 90% цієї інформації ніколи не буде прочитано.
Практично вся інформація в мережі Інтернет не містить семантики і тому її пошук, релевантний запитам користувача, в рамках конкретної предметної області є досить серйозною проблемою. Для забезпечення ефективного пошуку і управління, веб-додаток повинен чітко розуміти семантику документів, представлених в мережі.
В сучасному світі чільну роль займає інформація. Іноді це виглядає цілком обгрунтовано, іноді спекулятивно, іноді абсолютно безпідставно, але вона завжди має величезний вплив на прийняті рішення. Загальний обсяг інформації постійно зростає, весь час з'являються нові її джерела. Засвоювати і виділяти потрібну інформацію стає все складніше.
Тому основною проблемою у розвитку є його інтелектуалізація, і пов'язана з цим інтеграція даних, якісний пошук, інтеграція Веб служб і багато іншого. Ефективні засоби для зазначених завдань пропонуються в рамках підходу Semantic Web.
Метою роботи є розробка засобів і методів, які дозволяють створювати сховища структурованих і частково-структурованих даних на основі семантичного уявлення, а також керувати цими даними на високому рівні абстракції.
Для виконання поставленої мети необхідно вирішити існуючі завдання:
Графічний інсрументарій семантичного браузера планується реалізовувати на мові Java з використанням об'єктно-орієнтованих бібліотек розширюваного каркаса IDE Eclipse:
В результаті роботи повинен бути розроблений інструментарій, який дозволить переглядати внутрішню структуру баз даних і частково-структурованих файлів, виконувати переходи за об'єктами на основі відносин між ними, підтримує різні рівні кратності (один до одного, один до багатьох) і типи відносин.
Існтрументарій буде включати в себе: 1) інструментарій моделювання, який дозволяє спроектувати предметну область (в якості основного методу опису предметної області використовуються діаграми UML), 2) інструментарій прив'язки даних до елементів концептуальної моделі (відображення для управління даними через відповідні їм концепти); 3 ) безпосередньо, браузер для перегляду концептів, їх асоційованих зв'язків, обсягів і вибірок даних і пр.
Реалізовані кошти дозволять працювати з інформацією на якісно іншому рівні, а сам семантичний браузер може являеться основою для побудови інформаційних і аналітичних систем.
Онтологія - детальна формалізація деякої області знань за допомогою концептуальної схеми. Зазвичай така схема складається зі структури даних, що містить всі релевантні класи об'єктів, їх зв'язку і правила (теореми, обмеження), прийняті в цій галузі.
Класифікація онтологій:
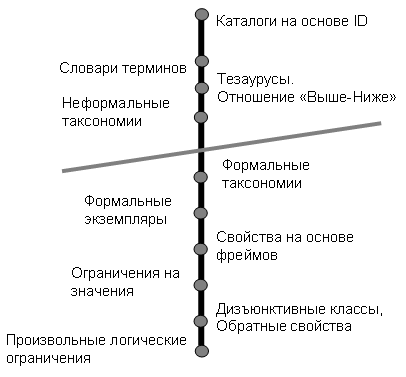
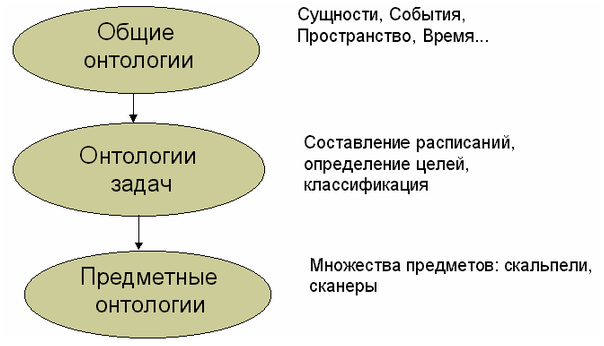

Загальні онтології описують найбільш загальні концепти (простір, час, матерія, об'єкт, подія, дія і т.д.), які незалежні від конкретної проблеми чи області. У цю категорію потрапляють і онтології уявлення, і онтології верхнього рівня.
Онтологія, орієнтована на завдання - це онтологія, використовувана конкретною прикладною програмою і містить терміни, які використовуються при розробці ПЗ, що виконує конкретну задачу. Вона відображає специфіку застосування, але може також містити деякі загальні терміни (наприклад, в графічному редакторі будуть і специфічні терміни - палітра, тип заливки, накладення шарів і т.д., і загальні - зберегти і завантажити файл). Завдання, яким може бути присвячена онтологія, можуть бути найрізноманітнішими: складання розкладу, визначення цілей, діагностика, продаж, розробка ПО, побудова класифікації. При цьому онтологія завдання використовує спеціалізацію термінів, представлених в онтологіях верхнього рівня (загальних онтологіях).
Предметна онтологія (або онтологія предметів) описує реальні предмети, що беруть участь в будь-якої діяльності (виробництві). Наприклад, це може бути онтологія всіх частин і компонентів літаків певної марки (Boeing) і відомості про їх постачальників, характеристиках, способі з'єднання один з одним і т.п.
Основна ідея Semantic Web полягає у тому, щоб зробити інформацію, передану в Web, більш формалізованою і зручною для машинного сприйняття, зокрема, для того щоб її можна було ідентифікувати і класифікувати. На думку авторів технології Semantic Web, це може досягатися за допомогою введення метаданих, які повинні супроводжувати будь-яку інформацію і розповідати про її походження, форматі та багато іншого, що має радикальним способом полегшити пошук інформації в Web та її обробку.
Грунтуючись на відкритих стандартах, технології Semantic Web дозволяють описувати і виділяти смислову інформацію (семантику) з довільних даних, зокрема змісту документів або коду додатків. Говорячи, що машина розуміє семантику документа, мається на увазі не тільки інтерпретація набору символів, що містяться в документі, але і те, що машина розуміє сенс документа, тобто значення документа в цілому. Наступні технології є основними в складі Semantic Web:
Ключовим елементом технологій Semantic Web є унікальна система ідентифікації об'єктів. URI (Uniform Resource Identifier) - це ідентифікатор якого об'єкта (ресурсу) в глобальній мережі. Будь-який елемент, схема чи модель даних семантичної мережі повинні мати власний унікальний адресу (URI). Зараз використовуються два типи ідентифікаторів.
1. Універсальний покажчик ресурсів (Uniform Resource Locator, скор. URL) - це URI, який, крім ідентифікації ресурсу, вказує на спосіб поводження з ресурсом шляхом опису способу доступу до нього або його положення в мережі.
2. Універсальне ім'я ресурсу (Uniform Resource Name, скор. URN) - це URI, який ідентифікує ресурс за допомогою імені в певному просторі імен. Це дозволяє посилатися на ресурсі без використання інформації про його розташуванні.
Другий базовий компонент Semantic Web - це модель даних Resource Description Framework (RDF), яка дозволяє об'єднати інформацію з довільних джерел. Формат RDF найбільш корисний у забезпеченні спільного використання інформації, зміст якої може однаково інтерпретуватися різними програмними агентами. Специфіка моделі даних RDF складається тому, що ресурси і властивості ідентифікуються за допомогою глобальних ідентифікаторів (URI). RDF описує предметну область в термінах ресурсів, властивостей ресурсів і значень властивостей. RDF-дані можна розцінювати як сукупність тверджень - суб'єкт, предикат і об'єкт твердження, і представляти у вигляді спрямованого графа, утвореного такими твердженнями.
Наступний рівень у піраміді технологій Semantic Web займає RDF Schema - мова опису словників RDF-термінів. RDFS служить фундаментом для багатших мов опису онтологій предметної області, які дозволяють адаптувати до Web системи логіки й забезпечити семантичну обробку даних. Схема RDF являє собою систему типів для Semantic Web і дозволяє визначити класи ресурсів і властивості як елементи словника, зокрема задати, які властивості з якими класами можуть бути використані.
Базовий будівельний блок моделі даних RDF - твердження, що представляє собою трійку: ресурс, іменоване властивість і його значення. У термінології RDF ці три частині затвердження називаються відповідно: суб'єкт (subject), предикат (predicate) і об'єкт (object). Ресурсом в даному випадку називають все, що описується засобами RDF. Це може бути звичайна Web-сторінка або якась її частина, наприклад, окремий елемент HTML розмітки. Також ресурсом може бути ціла колекція сторінок, наприклад, Web-сайт. І, нарешті, в якості ресурсу може виступати щось, що не є доступним безпосередньо через Інтернет, наприклад, довільний предмет зі світу речей.
На малюнку 2.1 в термінах відповідних сутностей і зв'язків зображена загальна схема моделі RDF. Тут під властивістю (Property) слід розуміти певний аспект, характеристику, атрибут або відношення, що використовується для опису ресурсу. Кожна властивість має свій специфічний сенс, допустимі значення, тип ресурсів, до яких воно може бути застосовано, а також відносини з іншими властивостями. Для забезпечення унікальності імен властивості дотримуються концепції URI, тобто властивість стає потенційним об'єктом для опису за допомогою RDF окремо від характеризується ресурсу та наявного значення.
Таким чином, кожне властивість в RDF саме є ресурсом і може мати свої власні атрибути. Цей факт перетворює модель даних з дерева, яким є XML-розмітка, в орієнтований граф. Вершинами цього графа є суб'єкти та об'єкти, а дугами - іменовані властивості. Оскільки властивість в свою чергу може бути суб'єктом деякого твердження, графи можуть бути як лінійними, так і вкладеними, наприклад, ми можемо висловлювати сумнів або згода з яким-небудь твердженням або вказувати джерело отримання відомостей [3].
Одним з загальнозначущих властивостей є «type», що відноситься до простору імен, що задається безпосередньо специфікацією RDF. Воно дозволяє вказати клас описуваного ресурсу. Це може бути автомобіль, людина, книга і т.п., а може бути деяка послідовність об'єктів (для вираження даного факту існує спеціальне значення «Seq», також належить до простору імен RDF). Згідно специфікації [4], значення властивості може мати один з двох типів.
Перший - це ресурс, що задається деяким URI. Другий тип - літерал, є деякий текстове значення характеристики. Втім, літерал може виражати собою значення будь-якого примітивного типу даних, присутнього в XML. Його текст також може містити в собі якусь розмітку, наприклад, XML, але відмітною особливістю такої розмітки є те, що вона не обробляється RDF-процесором і сприймається як звичайна рядок.
Модель даних сама по собі всього лише скелет. Для того щоб опис знайшло якийсь сенс, необхідно скористатися словниками, які задаються за допомогою додаткової технології - RDF Schema, що грає для RDF таку ж роль, що і схема для XML. Під словником розуміється сукупність ресурсів, що використовуються для опису властивостей інших ресурсів; класів ресурсів, які можуть бути описані за допомогою заданих властивостей; та обмеження, що накладаються на їх значення або набори допустимих значень. При цьому класи можуть складатися щодо «підклас» і аналогічно властивості можуть бути пов'язані відношенням «подсвойство» [6].
Модель даних, побудована при використанні належних словників, пропонує осмислене опис ресурсів, але цього ще не достатньо для розуміння Web машинами. Подібно до того, як одна людина не має можливості передати знання іншому, якщо вони обидва вміють говорити на одній мові, але використовують для цього різну лексику, мета не буде досягнута, поки не будуть розроблені єдині словники для опису якихось фактів, і програми не зможуть користуватися ними.
Реальне значення RDF неможливо оцінити, поки він використовується для внутрішніх цілей окремо взятого додатка. Користь від впровадження RDF буде тоді, коли він стане засобом міжпрограмного взаємодії, обміну даними, коли машини отримають здатність комбінувати інформацію, отриману з різних джерел, тим самим, отримуючи якусь нову інформацію.
Чим більше додатків в Інтернеті зможуть працювати з даними, тим вище стане їх цінність. У той же час RDF прекрасно підходить і для представлення самих даних, їх структури та зв'язків. Таким чином, при застосуванні спеціально розроблених RDF-схем (як засіб опису онтології предметної області) технологія Semantic Web може бути використана для вираження інформації, що відноситься до деяких розділів знань, зрозумілим для різних додатків Інтернету чином.
Вибираючи базову IDE для написання плагіна візуалізації, було вирішено розглядати тільки Eclipse, т.к якщо писати плагін для цієї IDE, то він розробляється як зовнішній модуль, і практично ніколи не вимагає зміни самої IDE, оскільки вся необхідна функціональність надається базової середовищем розробки. Так само Eclipse спочатку замислювався не як єдиний продукт, а як безліч модулів, що взаємодіють один з одним. Тому відразу ж питання написання різноманітних плагінів був широко висвітлений і по даній темі на офіційному сайті присутня велика кількість навчальних матеріалів, статей і прикладів.
Основні переваги Eclipse:
Для реалізації графічних елементів плагіна була обрана бібліотека GEF (Graphical Editing Framework). GEF - фреймворк, спеціально розроблений для платформи Eclipse. Вважається, що GEF досить складний фреймворк для вивчення, але при цьому він має ряд переваг в порівнянні з іншими фреймворками. GEF складається з наступних компонент:
Структура Eclipse плагина (графічне представлення структури плагіна представлено на рисунку 1.4). Він складається з наступних частин.
JAR-файл, що містить плагін, повинен мати певне ім'я і знаходиться всередині певної директорії Eclipse, де IDE зможе знайти і завантажити його. Назва файлу повинна містити ідентифікатор плагіна, потім підкреслення, і версію: com.qualityeclipse.favorites_1.0.0.jar [9].
Плагін Eclipse, як будь-який компонент має ряд особливостей і функцій.
Плагін може оголошувати точки розширення так, щоб інший плагін міг змінювати (зазвичай збільшувати) функціональність оригінального плагіна відповідно до потреб розробника. Такий механізм дозволяє робити доповнення незалежними, оскільки початковий плагін в цьому випадку може нічого не знати про цей додаток, яке його розширить. Для кожної точки розширення повинна бути вказана її категорія та список атрибутів, необхідних, щоб цією точкою скористатися [10].

В MANIFEST.MF оголошені властивості збірок OSGi і (не завжди) пакетів Java, які повинні бути доступні іншим збірок. Bundle-SymbolicName дозволяє задати унікальне ім'я збірки.
Маніфест є першим XML-дескриптором компонента. Робота з дескрипторами компонентів починається при старті платформи Eclipse. Завантажувач плагінів переглядає каталоги plugins (і / або links) в пошуках встановлених компонентів, і для кожного компонента аналізує файли MANIFEST.MF і plugin.xml. При цьому в пам'яті будується структура зв'язків збірок та їх описів (реєстр плагінів), але завантаження коду компонентів не відбувається (структура управління плагінами займає в пам'яті незрівнянно менше місця, ніж «звичайний» набір плагінів) [9,11].
Другий основний дескриптор компонента (поряд з маніфестом) - xml-дескриптор, який повинен знаходитися у файлі plugin.xml. Цей дескриптор також аналізується завантажувачем плагінів Eclipse до того, як буде завантажуватися і виконуватися код плагіна. Основне завдання цього дескриптора - описати зв'язку, настройки компонентів, його взаємодію з іншими компонентами і аспектами візуального представлення плагінів, які створюються за допомогою механізму «точок розширення». Основне призначення точки розширення - оголосити унікальний ідентифікатор, який буде використаний конкретними розширеннями для посилання на точку розширення.
У даній роботі була розглянута основна класифікація онтологій, а також їхніх мов опису. Виконано огляд технологій Semantic Web, принципів побудови моделі RDF та використання словників RDF: Schema. Також були вивчені методи розробки програми для розширюваного каркаса IDE Ecipse, і бібліотека GEF (Graphical Editing Framework) для реалізації графічної частини інтсрументарія.
На момент написання даного реферату магістерська робота ще є не завершеною. Передбачувана дата завершення: грудень 2012 р., через що повний текст роботи, а також матеріали по темі можуть бути отримані у автора або його керівника тільки після зазначеної дати.