
Abstract
Сontent
- Introduction
- 1. The goal and the problems of the research
- 2. Goal and tasks of the research
- 3. The practical importance
- 4. Analysis of data imputation algorithms
- 5. The construction of weighted training samples on the basis of w-baseWTS method
- 6. Research and development of the data gap-filling method in the works of DonNTU
- Conclusion
- References
- Important note
Introduction
The problem of the gaps reconstruction (imputation) in the empirical tables is an actual problem of data processing [1]. The causes of gaps are the inability to obtain or process data, information distortion or information concealment [2].As a result, the input of program that analyzes the collected data receives incomplete information
The presence of gaps in the data may produce the biased resultsand the incorrect strategic decisions [5]. Therefore, the priority of the data analysis for building effective intelligent systems is the problem of recovering gaps in the data.
1.The goal and the problems of the research
The object of the research is a problem of gaps recovery in empirical data tables. The subject of research is the datagaps filling methods.
The purpose of the graduation Master’s work is the development of the gaps filling method in empirical databased on the weighted training samples.
In the course of work it is necessary to solve the following problems:
1) the researching of the existing gaps filling algorithms in empirical data, criteria for quality assessment of the recovered data;
2) the researching of the methods of the weighted samples construction;
3) the development of the datagaps filling method based on the weighted training samples;
4) the software development for testing the data gaps filling algorithms;
5) theanalysis of the proposed algorithm.
2.Expected scientific innovation
The scientific innovation of this work isthe development of thegaps filling method in empirical databased on the weighted training samples.
3. The practical importance
Facing with the problem of data gaps processingis necessaryduring the sociological and economic research. The gaps recovery use to normalize the time series with missing observations [6] and forclose objects search. The recovery algorithm absence in the system will lead to the significant decrease in the efficiency of the system as a whole.
4. Analysis of data imputation algorithms
There are two approaches to solving the problem of incomplete data.
The first approach is to delete rows that contain missing data.The main lack of such approach is caused by information loss at an exception of incomplete data.
The second approach consists in filling the gaps by analyzing the available empirical data. Imputation methods classification is shown in figure 1.

Figure 1 – Imputation methods classification
1. Filling the gaps with the values of datasheet variables.The value of the variable calculates across a table or via a dedicated local group.the following algorithms of this type most often use [2,7]:
– arithmetic mean filling – calculation by the present values of the variable across the table;
– filling with biased selection – gaps filled with the values obtained for another similar object of sample (the substitution is selected for each missed value according to distribution);
– substitution with selection inside groups – a group formed and then gaps in each group are filling with present values from it;
– selection of the closest neighbor (the Hot Desk method) – the closest to filling object is determined by all present values of the variables on the given metric, and gap is filling by the variable value of the closest object;
– regression filling – the linear multiple regression equation construct on the complete sets of data and missing values of variable are calculating.
2. Filling the gaps based on the modeling.Construction of the model of gaps generation is done. The conclusions are obtained by the likelihood function provided correctness of this model, with estimation of parameters such as maximum likelihood methods. The most effective method of modeling is the EM-algorithm [2, 9].
3. Resampling method [4, 7]. Resampling method is based onbootstrap approach. It is the repeated processing of data subsets and their comparison.
4. Local recovery gaps algorithms (algorithms Zet and ZetBraid) [5, 10]. Algorithms Zet (Wanga) and ZetBraid are the technology of the experimental dataverification. They are similar to the method of the local filling.
Also there are neural networks and evolutionary algorithms for filling gaps in the data [4, 11].
Imputation has several disadvantages [9]:
1) the available full data using distorts the structure of the resulting data;
2) the imitation of gaps substitution add to array a certain amount of artificial data.
One of the most effective ways to fill gaps in the data is the local filling (filling with selection inside groups). Algorithms of the weighted training samples of w-objects constructing based on the idea of group selection.
5. The construction of weighted training samples on the basis of w-baseWTS method
In [12] w-baseWTS method of constructing a weighted training set of w-objects to reduce the large volume of samples is offered.The basis of this method is the selection of closest objects sets from the original sample and replacing them by a weighted object of the new sample.The values of each object attributes of the new sampleare the centers of mass of the objects attributes values from the original sample, which it replaces.Weight is defined as the number of objects in the original sample, which were replaced by an object of the new sample.
The construction of w-object consists of three successive stages:
1) creation of a forming set Wt, containing a number of objects in the original sample belonging to the same class;
2) formation of the vector XiW={xi1, xi2, …, xin} of the w-object feature values XiWand calculation of its weight pi;
3) correction of the initial training sample by the removing of objects that are included in the forming set X=X\Wf.
The selecting of objects {Xf1, Xf2, …, Xd} from the forming set Wf is carried by the following rule: an object Xi include in Wf if:
1) it belongs to the same class as the starting point Xf1;
2) the distance from considered object to the initial point is less, than to a competing point Xf2.
Thus, the forming set Wf is formed by the rule:
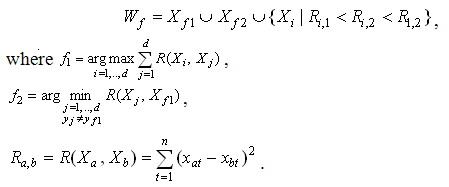
The principle of the forming set formation is given in figure 2.

Figure 2 – The w-object construction
(animation: 9 frames, 5 cycles of repeating, 22,1 kilobytes)
The features values {xi1, xi2, …, xin} of the new w-object XiWare forming on the forming set Wf and they are calculated like the coordinates of the mass center of the pf=|Wf| material points, where |Wf| is a the cardinality of a set Wf ,
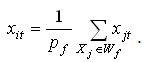
After the formation of the next w-object, all objects forming its set are removed from the original training set, X=X\Wf. The algorithm finishes its work when X=ø.
The principle of forming sets formation is an effective way of dividing the sample into groups. The introduction of the weights can not only store information about the number of exchangeable objects, but also to characterize the region in which these objects are located. The use of weighted training samples of w-objects and the method of w-baseWTS to solve the gaps filling problem in the data samples is an effective.
6. Research and development of the data gap-filling method in the works of DonNTU
The gaps filling problem which is solving in the pre-processing source data, considered in the works:
– finite mathematical model of meteoparameters evolution: development and prediction;
– software development for analyzing and optimizing subscription agency activity;
– software development for analyzing and prediction of natural gas consumption in "DonetskGorGas".
The known methods or software packages to fill the data gaps were used in these studies. Works aimed to develop new methods to fill the gaps in the data was not found.
Conclusion
The
problem of thegaps filling
in the empirical data has been considered in this paper. The causes of
the
missing data and problems arising due the gaps presence are found
out.The gaps
classification and characteristics of filling the data table, depending
on the
type of gaps is considered.
The
analysis of existing
methods of empirical data imputation iscompleted.It is shown that the
formation
of groups of objects in the local coverage is equal with the formation
of forming
sets in the construction of weighted training samples of w-objects.
That is why
the development of a new gaps filling method in the empirical data will
be
performed on the basis of weighted training samples.
References
1. Васильев В.И., Шевченко
А.И. Восстановление
пропущенных данных в эмпирических таблицах // Искусственный интеллект.
– 2003.
– № 3. – С. 317 – 324.
2. Литтл Р.Дж.А., Рубин Д.Б.
Статистический
анализ данных с пропусками.
– М.: Финансы и статистика,
1991. – 430 с.
3. Ефимов А.С. Решение
задачи кластеризации методом
конкурентного обучения при неполных статистических данных // Вестник
Нижегородского университета им. Н.И. Лобачевского. – 2010.
– №1. – С. 220 –
225.
4. Снитюк В.Е. Эволюционный
метод восстановления
пропусков в данных // Сборник трудов VI-й Международной
конференции «Интеллектуальный
анализ
информации», Киев, 2006.
– С. 262 – 271.
5. Загоруйко Н.Г. Методы
распознавания и их
применение. – М.: Сов. радио, 1972. – 208 с.
6. Голядина Н.Э., Осипов Е.
Метод «Гусеница»-SSA для анализа временных
рядов с пропусками [Электронный
ресурс]. – Режим доступа: http://www.gistatgroup.com/gus/mvssa1ru.pdf
7. Злоба Е., Яцкив И.
Статистические методы
восстановления пропущенных данных // Computer Modelling & New
Technologies.
–
2002. – Vol. 6. – № 1. – P.
51–61.
8. Круглов В.В., Абраменкова
И.В. Методы восстановления
пропусков в массивах данных // Программные продукты и системы.
– 2005. – № 2. [Электронный
ресурс]. – Режим доступа: http://www.swsys.ru/index.php?page=article&id=528
9. Зангиева И. Решение
проблемы неполноты данных
массовых опросов [Электронный ресурс]. – Режим доступа: http://soc.hse.ru/data/2010/05/03/1216376341/7_1.PDF
10.
Загоруйко
Н.Г., Елкина В.Н., Тимеркаев В.С. Алгоритм
заполнения пропусков в эмпирических таблицах (алгоритм Zet) //
Эмпирическое
предсказание и распознавание образов.
– Новосибирск,
1975. – Вып.
61: Вычислительные системы.
– С.
3 – 27.
11. Игнатьев Н.А. О синтезе факторов в искусственных нейронных сетях // Вычислительные технологии. – 2005. – № 3. – Том 10. – С. 32 – 38.
12. Волченко Е.В. Метод построения взвешенных обучающих выборок в открытых системах распознавания // Доклады 14-й Всероссийской конференции «Математические методы распознавания образов (ММРО-14)», Суздаль, 2009. – М.: Макс-Пресс, 2009. – С. 100 – 104.
Important note
The master's work is not
completed yet. Final completion is on December 10, 2012. Full work text
and
subject materials can be obtained from the author or her adviser after
this
date.