Модель трафика на основе FARIMA-модели
Авторы: Fei Xue, Jiakun Liu, Yantai Shu, Lianfang Zhang, Oliver W.W. Yang
Перевод с английского: Бойко А.А.
Источник: Traffic Modeling Based on FARIMA Models
Аннотация: В этой статье предложены процедуры для применения FARIMA(p,d,q) (дробно-интегрированной модели авторегрессии скользящего среднего) модели к потоку трафика, а также оценено качество данного метода для заданных параметров. Показано, как моделировать трафик для применения FARIMA-модели в четырех вариантах измерений. Эксперименты продемонстрировали, что FARIMA-модель является хорошей моделью трафика и способна учитывать свойства реального трафика с долгосрочной и краткосрочной зависимостями. В отличие от предыдущих работ по FARIMA-модели, введено несколько рекомендаций, для уменьшения сложности применения FARIMA-модели, которая позволила бы сократить время вычислительного процесса.
Ключевые слова: FARIMA, долгосрочная зависимость, моделирование трафика, самоподобие.
1. ВВЕДЕНИЕ
Моделирование временных рядов имеет большие перспективы в качестве инструмента для изучения сетевого трафика. Тем не менее, традиционные модели, такие как Пуассоновский процесс, Марковские процессы, AR, MA, ARMA и ARIMA процессы [1], могут применяться только для краткосрочных зависимостей.
Исследования высокоприоритетного трафика показали, что трафик в высокоскоростных сетях имеет свойства самоподобия, т.е. долгосрочную зависимость [2], что не учитывается моделями, приведенными выше. Были разработаны самоподобные процессы, такие как модель ФГШ (фрактальный Гауссов шум) [3] и модель ФДШ (фрактальный дифференциироанный шум) [4]. К сожалению, эти модели не могут быть использованы для описания краткосрочных зависимостей. Последние измерения реального трафика обнаружили сосуществование краткосрочной и долгосрочной зависимостей. Т.о., требуются модели для описания и тех, и других зависимостей одновременно,. FARIMA(p,d,q) считается подходящей моделью для таких целей.
В этой статье изучени FARIMA-модель в детальной реализации. Здесь предлагается процедура для применения FARIMA-модели к реальному потоку трафика, а также метод для создания FARIMA-процесса с заданными параметрами. Используются методы обратного предсказания, фрактального де-фильтра (фрактального дифференциирования ), а также сочетание грубой оценки и точной оценки для введения директив по упрощению применения модели FARIMA, что сократит время моделирования.
Эта статья организована следующим образом. Раздел 2 обобщает основное математическое описание FARIMA-моделей. Раздел 3 раскрывает метод создания FARIMA(p,d,q)-процесса. Раздел 4 показывает, как построить FARIMA (p,d,q)-модель для описания потока нагрузки. В разделе 5 оценивается техническая осуществимость FARIMA (p,d,q) моделей.
2.МОДЕЛЬ
FARIMA процессы являются естественным обобщением стандартных ARIMA (p,d,q) процессов, определенных в [1], когда порядок интегрированности d может принимать дробные значения [4]. FARIMA (p,d,q) процессом {Xt: t = ..., -1, 0, 1, ...} называется
![]()
где {at} - белый шум и d ϵ (-0.5, 0.5),
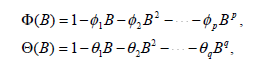
Θ(B), Φ(B) - ненулевые и не имеют общих нулей при |B|≤1, а p и q - неотрицательные целые числа. В представляет собой обратный оператор сдвига, т.е. BXt = Xt-1. ∆ =(1-B) - оператор дифференцирования и ∆d – оператор дробного дифференцирования,

Г - гамма-функция.
Очевидно, что если d = 0, FARIMA (p,d,q), преобразовывается в обычный ARMA (p,q) процесс. Если d ϵ (0, 0.5), то наблюдается долгосрочная зависимость в FARIMA-процессе. FARIMA (0, d, 0) процесса, т.е. ФДШ, является простейшей и наиболее фундаментальной формой FARIMA-процессов. Свойства FARIMA (0, d, 0) процесса схожи с ФГШ-процессом, который может описывать только долгосрочную зависимость. Параметр d в FARIMA (0, d, 0)-процессе - это показатель степени долгосрочной зависимости, как и параметр Херста H в ФГШ. В самом деле, H = d + 0,5. Оба процесса имеют автокорреляционные функции, которые ведут себя, асимптотически как k2d-1 с разными коэффициентами пропорциональности [2].
Для d ϵ (0, 0.5), р ≠ 0 и q ≠ 0, FARIMA (p,d,q)-процесс можно рассматривать как ARMA(p,q), управляемый ФДШ. Из (2-1), получаем:
![]() ,
где
,
где
![]()
Здесь Yt является ФДШ. Следовательно, по сравнению с ARMA и ФГШ процессами, FARIMA (p,d,q)-процесс гибкий и экономный [6] в отношении одновременного моделирования временных рядов с долгосрочной и краткосрочной зависимостями.
3. МЕТОД СОЗДАНИЯ FARIMA (p,d,q)-ПРОЦЕССА
Из (2-3) и (2-4), можно видеть, что FARIMA (p,d,q) процесс Xt можно считать ARMA (p,q)-процессом, управляемым Yt ФДШ. Итак, двухэтапная процедура создания FARIMA (р, д, д)-процесс следующим состоит в следующем:
Шаг 1: Создание Yt ФДШ, используя (2-4).
Шаг 2: Создание FARIMA (p,d,q)-процессa Xt, используя (2-3).
На шаге 1, отметим, что в соответствии с определением оператора дробного дифференцирования (2-2) и уравнения (2-4), и эти процессы ФДШ могут быть получены по заданному параметру d. Здесь делается важное предположение, что все Xt значения равны нулю для отрицательных значений времени. Тогда можем получить конечный временной ряд, определяемый:
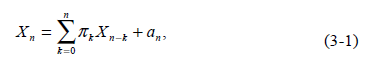 ,
где
,
где
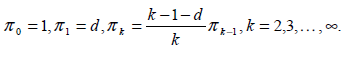
Этот метод называется методом прямого определения.
Другой способ создания FARIMA (0, d, 0)-процесса был введен Хоскингом [4]. Основные уравнения алгоритма Хоскинга состоят в следующем. Процесс Xt имеет нулевое математическое ожидание, дисперсию v0 и параметр d = H - 1/2. Автокорреляционная функция имеет асимптотическую гиперболическую форму, и определяется через d как:

X0 выбирается из нормального распределения N (0, v0). Устанавливается N0 = 0 и D0 = 1. Затем генерируется n точек путем итерации следующих шагов для k = 1, ..., n:

Выбирается каждое значение Xk из N (mk, vk).
В разделе 2 используются известные методы создания ARMA-процесса для создания FARIMA (p,d,q) процесс Xt путем замены at (белый шум) Yt (ФДШ).
3.1 Проверочные эксперименты
Проделаны следующие эксперименты для проверки FARIMA (0, d, 0)-процесса. Использованы два вышеизложенных способа (метод прямого определения и алгоритм Хоскинга) для генерации FARIMA (0, d, 0) процессов для пяти параметров (d = 0.1, 0.2, 0.3, 0.4, 0.45). Для каждого формируемого процесса, получено 20 000 сэмплов. Затем оценили параметр Херста H (d = H - 0,5), используя анализ на основе периодограмм для каждого формируемого процесса.
Таблица 1 показывает, что результаты двух вариантов генерации очень близки. Точность расчетного параметра д генерируемого процесса по отношению к заданному от +5 до +15%. Таким образом, оба из указанных выше двух способов подходят для генерации FARIMA (0, d, 0)-процессов.
4. ПОСТРОЕНИЕ FARIMA (p,d,q)-МОДЕЛИ ДЛЯ ПРИМЕНЕНИЯ К РЕАЛЬНОМУ ТРАФИКУ
Чтобы построить соответствующую модель для заданного трафика, итерационно проделываются следующие шаги до успешного получения необходимой модели:
1) Идентификация модели:
На этом этапе необходимо определить вероятные значения параметров модели р, d, q. Как правило, рассматривается несколько возможных моделей. Необходимо определить вероятные значения параметров:
- d, порядок интегрированности,
- p, порядок авторегрессии,
- q, скользящую среднюю.
2) Оценка параметров:
После того, как произведен выбор возможных моделей, для каждой модели определяются ее параметры.
3). Диагностика:
Включает в себя проверку того, насколько модель соответствует данному трафику, и как следует ее изменять, если не достигнут желаемый результат.
Проблема подбора адекватной FARIMA-модели остается открытым, кроме того, это сделать труднее, чем с ARMA-моделью. Можем проблемы FARIMA-модели переложить на модель ARMA и исследовать ее. Для заданных временных итервалов Xt можно получить из (2-1):
 ,
где
,
где
![]()
4.1 Шаги адаптирования трафика
Предлагается способ решения (4-1) и получения Wt. То есть, используются известные методы оценки параметра Херста H [7], тогда порядок интегрированности d = H - 0,5. Используя известные способы для создания ARMA-модели [1], мы можем решить (4-2) и получить параметры модели ϕ1, ϕ2, ..., ϕp, θ1, θ2, ..., θq.
Здесь предлагается следующая процедура для получения адекватной FARIMA- модели трафика.
Шаг 1: предварительная обработка трафика для получения нулевых значений временных серий Xt: t = 1, 2, ...
Шаг 2: Получение приближенного значения d
в соответствии с соотношением d = H - 0,5. Параметр Херста Н может быть получен с использованием известных методов оценки параметра Херста, таких как R / S анализ и метод периодограмм [7]. Это дает приблизительную оценку D.
Шаг 3: Фрактальное дифференциирование Xt. Из (2 -1) можно получить точное выражение
 ,
где
,
где
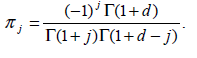
На практике из (4-3) требуются значений интервалов X0,
X-1, ..., Xm при достаточно большом m. Использование EXt вместо них может привести к большой погрешности. Произведена аппроксимация с помощью AR модели, основанной на "обратном прогнозе». После фрактального дифференциирования Х, получаем Wt [7].
шаг 4: определение р и д с использованием известных способов адаптирования моделей ARMA. Начнем с нескольких наборов р и q модели, и значение р и д должно быть равно 0, 1 или 2 (p и q не должны быть равными 0 одновременно в одном наборе), т.к. обнаружено, что p и q должны быть , как правило, небольшими для модели FARIMA. Затем определяется лучшая (р, q) комбинация в зависимости от идентификации модели и диагностической проверки. Если подходящая комбинация не будет найдена, мы увеличим р и q, а затем повторим шаги.
Шаг 5: Оценка параметров. После определения порядка р и д адекватной модели, можно получить все параметры ϕ1, ϕ2, ..., ϕp p, , θ1, θ2, ..., θq, и σ2 с помощью оценка параметров [8]. Этот шаг называется точной оценкой параметров.
Наконец, получаем адекватную FARIMA (p,q,d)-модель как необходимо по (2-1).
4.2 Проверочные эксперименты
Ключевой стадией описанной выше процедуры для создания FARIMA модели является фрактальное дифференцирование. Итак, осуществлены эксперименты по проверке, может ли фрактальное дифференцирование исключить долгосрочные зависимости, т.е. приблизить d к 0. В первом эксперименте получена FARIMA (0, d, 0) модель для пяти параметров (d = 0.1, 0.2, 0.3, 0.4, 0.45) с использованием прямого метода определения, описанного в разделе 3. После фрактального дифференцирования оценили параметр Херста с помощью анализа на основе периодограмм. Результаты приведены в таблице 1. Обнаружили, что после фрактального дифференцирования параметры Херста находятся около 0,5 (0,51 - 0,54), а также параметры d близки к нулю (0,01 - 0,04). После применения фрактального дифференцирования долгосрочные зависимости (самоподобие) практически исключаются.
Также изучены Bellcore trace pAug.TL для проверки того, что фрактальное дифференцирование может исключить долгосрочную зависимость. Получен набор данных который с 2000 выборок, и каждая выборка представляет собой число пришедших пакетов в течение 0,01 секунды. Измерен параметр Херста: H = 0,8, d = 0,3. На рисунке 1 и 2 показаны автокорреляционные функции и спектральная плотность pAug.TL до и после дифференцирования. После дифференцирования параметр D уменьшился до 0,03 (около 0). Обнаружено, что автокорреляционная функция затухает быстрее после фрактального дифференцирования. В самоподобных процессах низкочастотная часть обладает степенным поведением спектральной плотности в области нуля, но после фрактального дифференцирования такое поведение прекращается. Эксперименты подтвердили, фрактальное дифференцирование значительно уменьшает долгосрочную зависимость, как и ожидалось [9].
5. ТЕХНИКО-ЭКОНОМИЧЕСКОЕ ОБОСНОВАНИЕ
Для того, чтобы изучить возможность модели FARIMA, строится FARIMA модель для четырех реальных потоков трафика, используются опыты по проверке адекватности FARIMA-модели и сравнивается с другими моделями. Также рассматривается возможность упрощения FARIMA-модели.
5.1 Построение моделей FARIMA для реального трафика
С целью изучения FARIMA-трафика для моделирования, проведены некоторые исследования поизмеренного трафика Китая (внутреннего и внешнего). Есть два потока (C1003 и C1008) с CERNET центра (китайская образовательная и научно-исследовательская сеть). Два пути проводились на кабеле Ethernet в CERNET центр, который пропускает весь трафик в/из Интернета Китая. Также есть два потока (PAug.TL и pOct.TL) из лаборатории Bellcore [2].
В эксперименте проведена предварительная обработка измеренного трафика, для получения четырех наборов данных. Каждый набор данных имеет 2000 сэмплов, и каждый в сэмпл приходит определенное количество пакетов за 0,01 секунд. Использована процедура, предложенная в разделе 4, для адаптирования модели FARIMA под четыре набора данных. Четыре FARIMA-модели приведены в таблице 2. FARIMA модели показали, что эти потоки трафика обладают краткосрочной и долгосрочной зависимостью, т.к. d ≠ 0, и p,q ≠ 0 одновременно.
5.2 Опыты по проверке производных FARIMA-модели
Здесь используется трафик для того, чтобы убедиться, что полученная FARIMA-модель может описать структуры реального потока трафика. Например, на рисунке 3 показана автокорреляционная функция потока pAug.TL и его FARIMA-модель. Две кривые очень похожи в большом и малом диапазоне. Эксперимент подтвердил, что модели FARIMA могут обладать одновременно краткосрочной и долгосрочной зависимостями трафика.
5.3 эксперименты по сравнению с другими моделями
Сравнение произведено с моделями: ARIMA, AR и ФГШ. Подобраны FARIMA, ARIMA и AR FGN модели для потока pAug.TL. Четыре модели для pAug.TL приведены в таблице 3. Рисунки 3 до 6 показывают АКФ процессов FARIMA, ARIMA, AR и ФГШ. Как можем видеть, ФГШ не подходит из-за АКФ потока в малом диапазоне, АR не подходит для большого диапазона. Для обоих диапазонов одновременно хорошо подходят FARIMA и ARIMA модели однако, модель ARIMA требует больше параметров.
Таблица 4 показывает СКО (среднеквадратическую ошибку [7] потока pAug.TL. На основании результатов таблицы 4, видно, что модель FARIMA имеет наименьшее (лучшее) значение СКО, а за ней идут Арима, AR и ФГШ модели.
5.4 Методы упрощения
Хотя FARIMA модели имеют ряд преимуществ, их недостаток - высокая вычислительная сложность и длительную процедуру запуска. Обнаружено, что параметры (p, q) обычно остаются неизменным в течение некоторого времени. Из этого наблюдения исходит процедура упрощения моделирования, что сделает ее более легкой для реализации
Например, мы изучался поток pAug.TL. Время прохождения составляет 100 секунд, и каждый из 10 000 сэмплов, прибывает в течение 0,01 секунды. Затем эти 100 секунд делятся на пять наборов данных, Aug1 к Aug5, каждый с 2000 сэмплов. Подбирается FARIMA-модель для каждого набора данных (таблица 5). Заметим, что для всех пяти моделей FARIMA постоянны р = 1 и q = 1. Этот феномен предполагает, что это нет необходимости производить идентификацию и проверку модели для потока pAug.TL в 100 секунд. Есть аналогичные наблюдения из других экспериментов, показывающие, что значения (p,q), не могут изменяться в течение длительного периодов времени. Так что можно упростить процедуру создания модели FARIMA и сократить время на моделирования.
6. ВЫВОДЫ
В данной работе изложено, как применять FARIMA модели для потока трафика. Эксперименты показывают, что модель FARIMA является подходящей моделью и способна учитывать свойства реального трафика; это происходит потому, FARIMA процессы гораздо более гибкие и способны одновременно моделировать краткосрочную и долгосрочную зависимости временных рядов.
По сравнению с процессами, обладающими краткосрочной зависимостью такими как АРМА-модели, для Фарима требуется меньшее количество параметров. В сравнении с другими процессами с долгосрочной зависимостью, как ФГШ-модели и FARIMA (0, d, 0)-модели, FARIMA (p,d,q) превосходят по своим возможностям. Также показана, возможность упрощения процедуры, а следовательно и сократить время создания модели и произвести моделирование в режиме реального времени. Будущая работа включает в себя применение моделей FARIMA в проектировании сети, управлении, и прогнозировании трафика; контроль сети на основе измерений.
ПРИЗНАТЕЛЬНОСТЬ
Это исследование частично было поддержано Национальным Фондом Естественных Наук Китая (НФЕНК) в рамках гранта № 69672031, и Исследовательским Советом Естественных Наук и Инженерии Канады (ИСЕНИК) в рамках гранта № OGP0042878.