Введение
С научными вычислениями связаны многие технологические прорывы нашего поколения. Они используются в различных областях: лекарственных средства, айрокосмонавтика, прогнозирование погоды, сейсмический анализ и многое другое. Часто вычисления связаны с очень большими объёмами данных и их алгоритмы должны вычислять результаты математических моделей. Из-за того, что вычисления и данные имеют интенсивный характер, такие приложения выполняются параллельно, то есть выполняются вычисления на многих компьютерах.
ТОР500 – это список топ суперкомпьютеров в мире. В последнее время системы пересекли Petafop(10 в 15-той степени операций с плавающей запятой) барьер. Ожидается пересечение Exafop (10 в 18-той степени) барьера на рубеже десятилетия. Этот рост в области высокопроизводительных вычислений поддерживается сейчас низкими затратами на компоненты. Компоненты включают в себя: процессоры Intel, AMD, и IBM; GPGPUs от NVIDIA и т.д.; шины ввода / вывода, такие как PCI Express и коммутационные сети , такие как InfiniBand.
Так как машины становятся все больше и мощнее весь сетевой стек и сетевые приложения нуждаются в развитии. Основной способ конструирования в НРС это открытость системных характеристик, которые приводят к повышению производительности. Но, так как сложность системы растет , это должно выполнятся в манере, которая не подавляет разработку приложений с деталями.
Для сохранения масштабирования приложений на все более и более мощных системах крайне важно исследовать новые архитектуры с системной точки зрения и новые парадигмы приложений с прикладной точки зрения.
В статье исследуется соразработку связи сети, такой как InfiniBand, и современной библиотеки MPI и, наконец, изменение приложения используя эти новые возможности.
Состояние вопроса
InfiniBand сетевая архитектура
InfiniBand [1] является очень популярным стандартом, используются более чем на 40% от Top500 суперкомпьютерных систем [2]. Текущее поколение InfiniBand сетевые карты и коммутаторы со скоростью QDR может достегать 32 Gbps точка-точка полосы пропускания и около 1-1,5 сек латентность.
Одна из основных особенностей InfiniBand - Remote Direct Memory Access (RDMA). Использование RDMA один процессор может читать и писать содержимое памяти другого процессоа без участия удаленного процессора. Эта функция очень полезная и при разумном использовании в разработки коммутационной библиотеки может обеспечить снижение требований к синхронизации в дополнение к чистой латентности.
Сетевой интерфейс ConnectX-2 последний адаптер InfniBand от Mellanox. Наряду со всеми стандартными особенностями InfniBand, предлагает новые разгружающею сеть функцию называемую CORE-Direct. Используя эту функцию могут быть созданы произвольные списки отправленных принятых и ожидающих операций. Эти списки могут быть размещены в очереди запросов сетевого адаптера. Затем сетевой интерфейс выполняет задачи без участия центрального процессора. Используя такие списки задач, не блокирующие коллективные операции могут быть разработаны библиотеки верхнего уровня .
Интерфейс передачи сообщений
MVAPICH2 высокопроизводительный дизайн для InfniBand. MPI был доминирующей параллельной программной моделью для нескольких прошлых десятилетий. Достиг очень хорошей производительности и масштабируемости. В результате все современные суперкомпьютеры поддерживают этот интерфейс.
InfniBand предлагает низкого уровня интерфейс с несколькими типами пар очередей, с переменными уровнями сервисов. Это позволяет более высокоуровневому программному обеспечению , таким как МРI реализации, использовать гибкое и высокопроизводительное управление подключениями, управление буферами, соединение стратегий и другое.
MVAPICH2 [8] является высокоэффективным внедрением стандарта MPI-2 на InfniBand , Internet Wide Area RDMA Protocol (iWARP) и RoCE (RDMA over Converged Ethernet) .
Внутренний дизайн MVAPICH2систематически разрабатывался, чтобы достигнуть очень хорошей масштабируемости, эксплуатируя различные особенности InfniBand, такое как Unreliable Datagrams, Shared Receive Queues (SRQ), и eXtended Reliable Connections (XRC) на ряду с стратегиями управления связями, такие как связи по требованию, и буферными стратегиями сообщений для эффективности использования памяти. Все эти оптимизации были объединены в unifed runtime. Как нам известно это наиболее масштабируемый runtime в InfniBand, кторы предлагает высокую производительность и является opensource. За прошлые десять лет MVAPICH2 использовался в качестве внедрений MPI для исследования в коммутационных runtime . MVAPICH2 также используется на большом числе InfniBand кластеров во всем мире.
Параллельные научные приложения
Научные приложения используют широкий диапазон численных методов. В нашей работе мы использовали два приложения что использование двух различных методов: метода конечных разностей и преобразования Фурье. Они описаны ниже.
AWP-ODC: The Anelastic Wave Propagation code by Olsen, Dey and Cui. AWP-ODC является общей моделью [7], которая используется в Калифорнийском центре землятрясений Southern California Earthquake Center (SCEC).
AWP-ODC решает3D уравнение волны скоростного напряжения явным методом ступенчатой сетки конечных разностей (Finite Difference - FD). Объем представления земельного участка, который будет смоделирован, анализируется в 3D прямоугольные подсетки. Каждый процесс отвечает за определенную подсетки, и применения граничных условий в случаии если подсетка находится на границе.
P3DFFT: The Parallel Three-Dimensional Fast Fourier Transforms (P3DFFT) библиотека от San Diego Supercomputer Center (SDSC) является портативным, высокоэффективным, общедоступным внедрением, основанным на MPI программной модели. Этот метод использовался в приложении Direct Numerical Simulation (DNS) турбулентности. P3DFFT использован для имплиментации быстрого FFT в IBM’s ESSL. FFT расчеты требуют, чтобы две MPI Alltoall коммуникационные операции были выполнены как транспонирующие матрицы операции матрица перемещает операции. Как показано в [6], возможно реструктурировать библиотеку P3DFFT, чтобы улучшить наше предложение внедрения MPI Ialltoall операций.
Сорозработка научных приложений с MPI библиотекой
Описывается сорозроботки приложений с MPI библиотекой. Полный подход приведен на рисунке 1.
В этой секции описывается улучшение в библиотеку MPI, чтобы включить новые сетевые особенности. Сетевой уровень обеспечивает новые функции, такие как RDMA, разгрузки, обратной петли, которые можно использовать в MPI слоя, как показано на рисунке 1. Кроме того, современные многоядерные вычислительные платформы также предоставляют несколько дополнительных функции для оптимальной передачи данных между ядрами внутри узла. Эти функции также должны быть использованы для лучшую производительности.
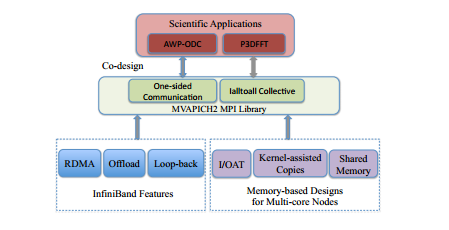
Рисунок 1 - Подход соразработки для библиотеки MPI, сети и научных приложений
Далее описано два важные усовершенствования MPI, которые используют эти функции.
Улучшение Односторонней Связи с RDMA: Односторонняя модель в MPI стремится уменьшать накладные расходы синхронизации. Каждый процесс выставляет область память (окно) ко всем другим процессам в его коммуникационной группе. Каждый процесс может в таком случаи непосредственно читать , обновить память окна любого другого процессора Все параметры требуемые для коммуникации обеспечены процессом выставляющим.
Коммуникационные операции имеют неблокирующую природу. Семантика односторонней коммуникации формирует идеальную пару с RDMA операциями предложеными сетью InfniBand. Проектирование неблокирующего обмена Alltoall с коллективным Offoad: Персонифицированный обмен Alltoall является наиболее коммуникационно интенсивной коллективной операцией в Стандарте MPI-2.2. С N процессорами латентность операции Alltoall пропорциональна 2N, что существенно влияет на производительность и масштабируемость различных научных приложений.
Плодотворной стратегией для повышения производительности приложений может быть, разработка высоко производительной, неблокирующей реализации для Alltoall, которая может быть использована для приложений чтобы перекрывать Alltoall связи.
Возможно использовать основанные на host-based подходы проектирования (libNBC) [12] . Однако, такие методы непосредственно ограничивают наложение и также не очень портативны.
Библиотеки MPI могут усилить offoad особенности особенности сети в адаптере ConnectX-2 InfniBand, чтобы проектировать коллективные неблокирующие операции. Однако, с текущим интерфейсом ConnectX-2, размер списка задач ограничен, и это непосредственно затрагивает масштабируемость коллективных операций, таких как MPI Alltoall.
...
Список использованной литературы
- InfniBand Trade Association.http://www.innibandta.com
- TOP 500 Supercomputer Sites.http://www.top500.org
- Y. Cui, K.B. Olsen, T.H. Jordan, K. Lee, J. Zhou, P. Small, D. Roten, G. Ely, D.K. Panda, A. Chourasia, J. Levesque, S.M. Day, and P. Maechling. Scalable Earthquake Simulation on Petascale Supercomputers. In Proceedings of the 2010 ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis (SC10), Gordon Bell Prize Finalist, November 2010.
- D.A. Donis, P.K. Yeung and D. Pekurovsky. Turbulence Simulations on O(104 ) Processors. In TeraGrid 2008.
- W. Jiang, J. Liu, H. Jin, D. K. Panda, W. Gropp, and R. Thakur. High Performance MPI-2 One-Sided Communication over In?niBand. In IEEE/ACM International Symposium on Cluster Computing and the Grid (CCGrid 04), Chicago, IL, April 2004.
- K. Kandalla, H. Subramoni, K. Tomko, D. Pekurovsky, S. Sur and D. K. Panda. High-Performance and Scalable Non-Blocking All-to-All with Collective Offoad on In?niBand Clusters: A Study with Parallel 3D FFT . In International Supercomputing Conference, Hamburg, Germany, June,2011.
- Olsen KB. Simulation of three-dimensional wave propagation in the Salt Lake Basin. PhD thesis, University of Utah, Salt Lake City, 1994.
- MVAPICH2: High Performance MPI over InfniBand, iWARP and RoCE. http://www.innibandta.com
- P. Lai, S. Sur and D. K. Panda. Designing Truly One-Sided MPI-2 RMA Intra-node Communication on Multi-core Systems. In International Supercomputing Conference (ISC 2010), June 2010.
- Parallel Three-Dimensional Fast Fourier Transforms (P3DFFT) library, San Diego Supercomputer Center (SDSC). http://code.google.com/p/p3dfft
- S. Potluri, P. Lai, K. Tomko, S. Sur, Y. Cui, M. Tatineni, K. Schulz, W. Barth, A. Majumdar, and D. K. Panda. Quantifying Performance Benefts of Overlap using MPI-2 in a Seismic Modeling Application. In International Conference on Supercomputing (ICS’10), 2010.
- T. Hoe?er and J. Squyres and G. Bosilca and G. Fagg and A. Lumsdaine and W. Rehm. Non-Blocking Collective Operations for MPI-2. Technical report, Open Systems Lab, Indiana University, Aug. 2006.