
РЕФЕРАТ ПО ТЕМЕ ВЫПУСКНОЙ РАБОТЫ
Содержание
- Цель и задачи
- Актуальность темы
- Предполагаемая научная новизна
- Планируемые практические результаты
- Обзор исследований и разработок по теме. Глобальный уровень
- Обзор исследований и разработок по теме. Национальный уровень
- Обзор исследований и разработок по теме. Локальный уровень
- Повышение эффективности извлечения знаний из сетевых источников на основе методов Web и Text Mining
- Подходы к извлечению данных и знаний из Web
- Извлечение значимой информации и фильтрация
шума
- Организация системы извлечения объектов из специализированных текстов
- Предлагаемые направления совершенствования алгоритмов извлечения знаний
- Выводы
- Список источников
Цель и задачи
Целью настоящей работы является разработка и исследование алгоритмов интеллектуального анализа содержимого сайтов для извлечения и верификации знаний в заданной предметной области.
Для достижения поставленной цели необходимо решение следующих задач:
- Анализ существующих подходов к извлечению данных и знаний из Web.
- Разработка алгоритмов извлечения значимой информации и фильтрации
шума
. - Разработка алгоритмов извлечения объектов из текстовых документов.
- Разработка алгоритмов формирования шаблонов и верификации извлеченных знаний.
- Анализ эффективности предложенных алгоритмов.
Актуальность темы
Развитие Internet в глобальную информационную инфраструктуру позволило обычным пользователям быть не только потребителями информации, но ее создателями и распространителями. Это привело к лавинообразному росту и постоянному пополнению хаотично организованной информации сети. В Интернете содержится неизмеримое множество знаний и информации, и такое обилие часто создает сложности при поиске необходимой информации. Всё это приводит к необходимости использования каких-то специальных технологий для извлечения полезных знаний из сети Интернет. Особую важность приобретают программные интеллектуальные средства автоматического извлечения релевантной информации, достоверность которой можно формально проверить или верифицировать.
Разработанные до сих пор подходы к верификации знаний используют преимущественно статистические и синтаксические методы проверки целостности и непротиворечивости, размещенных в отдельной базе знаний, что обуславливает неспособность существующих методов верификации справиться с разнородностью, неструктурированностью и противоречивостью информации, представленной в Web.
В Web представлен широкий спектр данных: текст, графика, аудио, видео. Так как в документах традиционно больше содержится данных в текстовом виде, актуально совершенствование методов извлечения знаний из текстовой информации. Текстовая информация в Web может быть неструктурированной в виде свободного текста, полуструктурированной в виде HTML-страниц или структурированной в виде документов из БД.
Новое направление в методологии анализа данных – Web Mining может успешно служить этим целям. Web Mining развивается на пересечении таких дисциплин как обнаружение знаний в базах данных, эффективный поиск информации, искусственный интеллект, машинное обучение и обработка естественных языков. Направление Web Mining, называемое Web Content Mining, охватывает методы, которые способны на основе данных сайта обнаружить новые, ранее неизвестные знания, которые в дальнейшем можно будет использовать на практике. Другими словами, технология Web Content Mining применяет технологию Data Mining для анализа неструктурированной, неоднородной, распределенной и значительной по объему информации, содержащейся на Web-узлах.
В связи с этим актуальной является задача разработки алгоритмов извлечения знаний из распределенных разнородных источников, модели и методов семантической верификации полученных знаний, которые предоставят возможность интеллектуальным программам или агентам автоматически убеждаться в достоверности в определенном контексте предоставленной системой информации.
Предполагаемая научная новизна
Алгоритмы извлечения знаний из локальных и распределенных источников шаблонными методами обучения и их семантической верификации с помощью модифицированной онтологии предметных областей.
Планируемые практические результаты
Алгоритмическое обеспечение может использоваться для построения интеллектуальной системы извлечения и верификации знаний.
Обзор исследований и разработок по теме. Глобальный уровень
На сегодняшний день существует множество систем анализа текстового Web контента и его интеллектуального анализа. Разработкой таких систем занимаются как небольшие частные компании, группы ученых и программистов, так и гиганты компьютерной индустрии.
Так, IBM предлагает свою разработку Intelligent Miner for Text [1], которая, по сути, является набором отдельных утилит. Language Identification Tool – утилита определения языка – для автоматического определения языка, на котором составлен документ. Categorisation Tool – утилита классификации – автоматического отнесения текста к некоторой категории (входной информацией на обучающей фазе работы этого инструмента может служить результат работы следующей утилиты – Clusterisation Tool). Clusterisation Tool – утилита кластеризации – разбиения большого множества документов на группы по близости стиля, формы, различных частотных характеристик выявляемых ключевых слов. Feature Extraction Tool – утилита определения нового – выявление в документе новых ключевых слов (собственные имена, названия, сокращения) на основе анализа заданного заранее словаря. Annotation Tool – утилита «выявления смысла» текстов и составления рефератов – аннотаций к исходным текстам.
Среди разработок на постсоветском пространстве стоит выделить системы GALAKTIKA-ZOOM и «Медиалогия». Программный комплекс GALAKTIKA-ZOOM предназначен для аналитической обработки динамично пополняющихся больших массивов (до десятков миллионов) текстовых документов, находящихся в подключаемых неструктурированных и структурированных электронных базах данных [2].
Система «Медиалогия» не предусматривает передачи программы заказчикам, производя обслуживание клиентов в онлайновом режиме. «Медиалогия» – это web-приложение, представляющее собой мощное решение со сложной архитектурой и обеспечивающее непрерывную обработку поступающей информации, структурированное хранение данных, расчет аналитических параметров, проведение анализа по запросам пользователя и хранение настроек и отчетов.
Обзор исследований и разработок по теме. Национальный уровень
В работе [3] разработан метод верификации онтологических знаний, который заключается в генерации древовидных структур пояснения для автоматического гибридного вывода знаний на основе информации, которая извлекается из распределенных разнородных источников. Доказано, что верификация знаний сводится к верификации множества утверждений, представленных в виде триплетов. Для интерпретации результатов верификации предложен метод определения эквивалентности древовидных структур, который отличается от существующих возможностью учета семантики узлов дерева и характеризуется использованием нескольких независимых оценок подобия онтологических объектов.
Обзор исследований и разработок по теме. Локальный уровень
В [4] рассматриваются основные подходы к извлечению знаний из распределенных информационных ресурсов: интеллектуальный анализ текстов и предварительное структурирование информации. Рассматриваются подходы и описываются тенденции развития информационного пространства и средств его анализа. Предлагается структура системы извлечения знаний из информационных ресурсов с неструктурированной и структурированной информацией.
Предложенный в [5] метод использует 11 характеристик интернет страниц, в том числе Google Page Rank, рейтинг Yandex, Alexa Trafic Rank, рейтинг закладок Delicious и количество ссылок в Twitter за последний месяц. Между показателями производится поиск и анализ взаимозависимостей. При этом определяется влияние отдельных характеристик и их групп на общий рейтинг интернет страницы. Метод реализован на языке R. Приведены результаты анализа характеристик 46 интернет страниц предложенным методом. Обнаружено сильное влияние на рейтинг закладок Delicious группой двух показателей: количеством ссылок в Twitter и рейтингом посещаемости интернет страницы.
Повышение эффективности извлечения знаний из сетевых источников на основе методов Web и Text Mining
Подходы к извлечению данных и знаний из Web
Активные исследования в области работы со слабоструктурированной информацией привели к появлению большого количества альтернативных инструментов, используемых для создания программ-посредников [6]. Предлагаемые подходы в исследовании проблемы извлечения данных из Web используют методы, заимствованные из таких областей как: обработка данных на естественном языке, языки и грамматики, машинное самообучение, информационный поиск, базы данных и онтология. В результате, они предоставляют самые различные возможности, поэтому строгих критериев для их сравнения пока не выработано.
Основной задачей извлечения данных из Web является: получение определенных фрагментов информации (поля) из указанных HTML документов в указанное время. Она близка к задаче автоматической кластеризации и состоит в поиске разложения множества HTML-документов D {d1, … , dn} на классы C1, … , Ck, которые содержат документы со схожей структурой.
Задание отображения прикладных объектов в точки многомерного пространства состоит в определении базиса признаков {ei},
формирующих многомерное пространство, и метода разложения документа по этому базису (т.е. вычисления координат {wi}).
Для определения координат документа {wi} в пространстве базисных признаков {ei} используются различные подходы.
В частности, в работе [7] предлагается использовать подход, популярный при вычислении весов термов в поисковых системах,
использующих векторную модель представления документов. При этом: wi=tfi/(logN/ki), где tfi – это
частота встречаемости i-го признака, ki – количество документов, в которых он встречается, а N – общее количество
рассматриваемых документов. Для оценки качества кластеризации предлагается использовать энтропийную меру.
На основании вычисления общей энтропии и энтропии кластера авторы работы [8] вводят критерий хорошего
кластера,
который может быть обработан автоматически. Затем вводится еще одна мера, отражающая возможность построения многоуровневой иерархии кластеров.
Существует целый ряд других подходов к формализации задачи извлечения слабоструктурированной информации из Интернет-источников. В них используется логика ранжированных или неранжированных деревьев первого или более высокого порядка (как правило, второго порядка) [9], [10], а также логика на графах [11]. Эти методы относятся к перспективному, активно развивающемуся направлению современной математической логики, которое в настоящее время активно формируется. Эффективная реализация таких методов требует разработки новых способов представления и хранения документов в виде древовидных (а в самом общем случае – графовых) структур, а также языков запросов к ним, что требует больших усилий на этапе разработки. С точки зрения простоты реализации было решено использовать стандартные средства представления документов и языки запросов, поэтому далее эта группа методов не рассматривается.
Для систематизации существующих подходов можно использовать классификацию, предложенную в работе [8], которая выделяет следующие группы методов и средств их реализации: декларативные языки; использование HTML структуры; системы, осуществляющие обработку данных на естественном языке; системы на основе индуктивных логических рассуждений; средства моделирования; средства, основанные на онтологии. Эта классификация не строгая и некоторые инструменты могут относиться сразу к нескольким группам.
Исходя из выполненного анализа существующих методов извлечения, можно сделать вывод, что страницы HTML едва ли могут быть обработаны посредством обычного грамматического разбора, ввиду ряда причин. Основные из них заключаются в том, что разработчики HTML-страниц пользуются неограниченной свободой при недостатке средств синтаксического контроля. Следствием этого является разнообразие способов структурирования данных в странице, так что два логически однородных элемента данных могут быть форматированы совершенно различным образом, либо даже содержать ошибки, т.е. части кода могут не вполне соответствовать грамматике HTML (отсутствие закрывающих тэгов является распространенным примером).
Извлечение значимой информации и фильтрация шума
При извлечении знаний из Web-контента, на начальном этапе необходимо получить значимую информацию из определенного источника. Для этого необходимо установить тип документа и выбрать алгоритм работы в зависимости структуры данных его представления.
По способу упорядочивания данных в различных типах документов их можно разделить на три вида: неструктурированные, частично-структурированные и структурированные [12]. Электронные документы составлены в произвольной форме на естественном языке и содержат неструктурированные данные. Примером такого документа может быть статья с произвольной тематикой (txt, doc, pdf). Частично-структурированные данные содержат электронные Web-документы различных расширений (php, aspx, jsp, htm и т.д.), оформленные в текстовом формате HTML, где они описываются с помощью специальных тэгов. Cтруктурированные данные содержат ХML-документы и базы данных [13]. Их относят к данному типу благодаря наличию специфических инструментов. В случае XML – это DTD (преамбула документа, где определяются его компоненты и структура) и XML schema (язык описания структуры XML документа) [13].
К основным критериям значимости информации относят: актуальность, достоверность, полноту и чистоту
представляющих ее данных.
Последний критерий является объективной характеристикой, так как отвечает за содержательную часть информации [14] и
отражает ее качество, сигнализирует о зашумленности (отсутствуют данные, которые не несут смысловой нагрузки в рамках заданной тематики).
На рис 1. представлены основные этапы анализа web-страниц при извлечении значимой текстовой информации и фильтрации шума
.
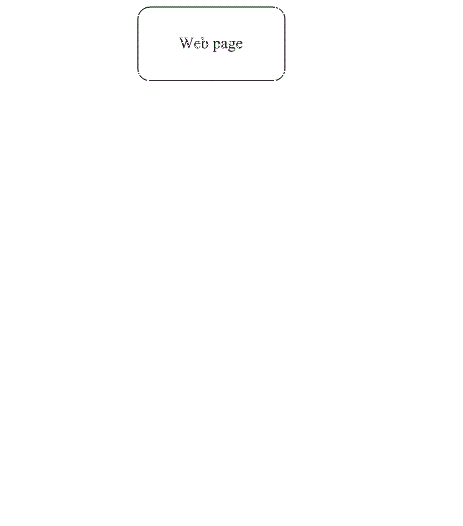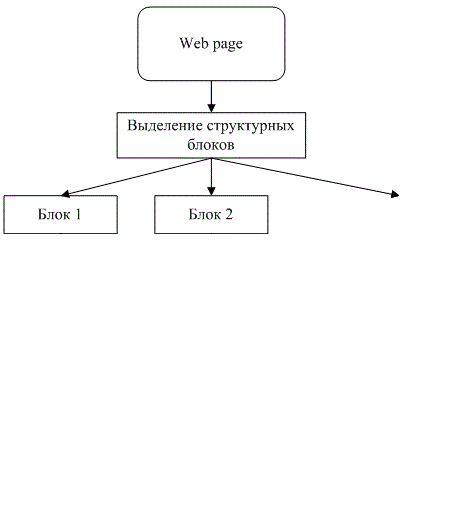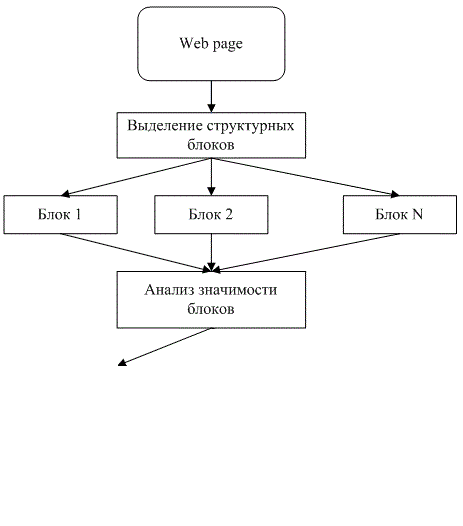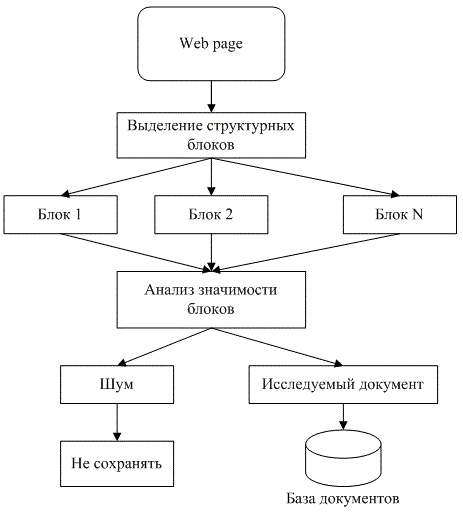
Рисунок 1 – Этапы извлечения значимой информации
(анимация: 21 кадр, 8 циклов повторения, 137,4 килобайт)
Организация системы извлечения объектов из специализированных текстов
В системах электронной торговли, документооборота предприятий имеется большое количество значимых текстовых документов с ограниченной лексикой (характеристики продукции, комплектующих и сырья, отчеты о поломках, результаты опросов и т.д.).
Для таких текстов упрощается создание алгоритмов преобразования их к стандартизованному структурированному виду. Стандартизованную информацию проще обрабатывать и можно использовать в различных производственных целях.
Например, описание манипулятора мышь: компьютерная мышка Genius, модель DX-7010, цвет Black, датчик оптический, радио интерфейс, 2 стандартные клавиши, колесо прокрутки с функцией нажатия, Windows-совместимая.
Данный текст требуется преобразовать к виду:
| Поле | Значение |
| Тип устройства | манипулятор мышь |
| Торговая марка | Genius |
| Модель | DX-7010 |
| Тип датчика | оптический |
| Интерфейс | радио |
| Количество кнопок | 2 стандартные клавиши |
| Цвет | Black |
| Совместимость | Windows |
Такие тексты объединяет упрощенный язык, правила построения проще предложений естественного языка, описания практически всегда схожи друг с другом по структуре, чаще всего используются один и тот же относительно небольшой, если сравнивать с естественной речью, набор слов, очень часто встречаются аббревиатуры и сокращения. Поэтому существенно упрощается система разбора таких текстов.
В предлагаемой системе будем использовать шаблонный метод с обучением. Состав системы показан на рисунке.
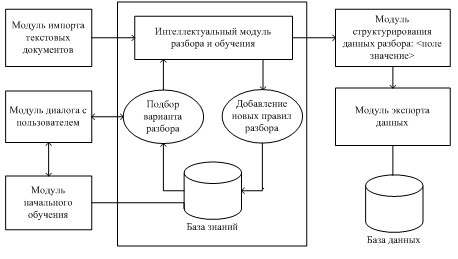
Рисунок 2 – Структура системы извлечения объектов из специализированных текстов
Перед началом работы пользователем и модулем начального обучения формируются шаблоны разбора для предметных областей системы документов и правила разбора текстов с помощью шаблонов. Шаблоны, например, для периферийных устройств ПК представляются фреймом следующего вида:
| Периферийные устройства ПК |
| Тип устройства |
| Торговая марка |
| Изготовитель |
| Совместимость |
| Интерфейс |
| Цвет |
Значения слотов накапливаются при обучении. Составленный вручную шаблон, обладает высокой точностью и низкой полнотой для извлечения именованных сущностей из текста. Применяя этот шаблон, на начальном этапе в режиме диалога с системой, получаем обучающее множество для машинного обучения.
Если рассмотреть кластер, объединяющий несколько тематически близких документов, то в нем часто оказывается достаточное количество близких по смыслу предложений, включающих как предложения, в которых некоторый фрейм распознан вполне успешно, так и предложения, в которых этот же фрейм не распознан совсем или распознан частично. Эту вторую группу предложений можно использовать для наращивания шаблонов для распознавания данного фрейма. Для обеспечения дополнительного обучающего множества, необходимо выделить предложение, в котором найден некоторый фрейм объекта, а затем найти множество предложений кластера, похожих на исходное, но в которых нужный фрейм не обнаружен. Предложения, содержащие шаблоны извлекаемой информации, служат центрами для кластеров схожих предложений, в которых такие шаблоны не обнаружены.
При своей работе система извлечения данных определяет наличие в текстовом фрагменте некоторого объекта (фрейма) и выделяет связанную с этим объектом информацию (слоты фрейма и их значения). В алгоритмах изначально производится обработка текстов кластера при помощи имеющегося шаблона и извлекается информация об объекте из текста. Далее производится поиск извлеченной информации в каждом предложении кластера, в котором не удалось установить наличие извлекаемого объекта и подсчитывается количество найденных слотов.
При работе с предметной областью, отличной от обрабатываемой до этого, но достаточно близкой к ней, система может использовать ранее найденные правила разбора, однако при этом могут извлекаться не все объекты или слоты. Для повышения точности отбора предложений предполагается использовать алгоритмы, основанные на вычислении меры близости предложений по количеству выделенных слотов, по косинусу угла между предложениями и по значению меры TF×IDF слова [15]. Косинус угла между вектором слов данного предложения x и вектором слов предложения y, в котором анализатор обнаружил наличие некоторого объекта, вычисляется по формуле:
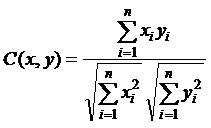
Предлагаемые направления совершенствования алгоритмов извлечения знаний
Для упрощения и автоматизации процедуры формирования шаблонов и верификации извлеченных знаний предлагается использовать онтологию предметной области. По онтологии модуль начального обучения может формировать шаблоны-фреймы для заданной тематики документов. Правильность извлечения значений слотов для объектов контролируется с помощью верифицирующих знаний онтологии. Эти знания хранятся в онтологии и могут пополняться из распределенных источников.
Выводы
Проведен анализ существующих подходов к извлечению данных и знаний из Web, рассмотрены этапы извлечения значимых документов с Web-страниц и
фильтрация шума
. Разработаны алгоритмы извлечения объектов из текстовых документов на основе шаблонного метода. Предлагаемое
алгоритмическое обеспечение может использоваться в системах интеллектуального анализа Web-контента.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2013 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Intelligent Miner for Text (IBM). [Электронный ресурс]. – Режим доступа: http://www-3.ibm.com....
Галактика-Zoom
. [Электронный ресурс]. – Режим доступа: http://zoom3.galaktika.ru.- Головянко М. В. Методи і модель верифікації знань для інтелектуалізації Web-контенту; Автореф. дисс. канд. техн. наук. – Х., 2011. – 129 с.
- Бабин Д.В. Повышение эффективности извлечения знаний на основе интеллектуального анализа и структурирования информации/ Д.В. Бабин, С.М. Вороной, Е.В. Малащук//
Штучний інтелект
. – 3’ 2005. – С. 259-264. - Миргород В.С. Метод интеллектуального анализа интернет страниц/ В.С. Миргород, И.С. Личканенко, Д.М. Мазур, Р.А. Родригес Залепинос// Информатика и компьютерные технологии; VIII. – ДонНТУ. – 2012.
- Laender A.H.F., Ribeiro-Neto B.A., Juliana S.Teixeria. A brief survey of web data extraction tools. ACM SIGMOD Record 31(2), 2002. – pp. 84-93.
- Некрестьянов И. Обнаружение структурного подобия HTML-документов/ И. Некрестьянов, Е. Павлова. [Электронный ресурс]. СПГУ. – 2002. – С. 38-54. – Режим доступа: http://rcdl.ru/doc....
- Crescenzi V., Mecca G. Automatic Information Extraction from Large Websites// Journal of the ACM, Vol. 51, No. 5, September 2004. – pp. 731-779.
- Gottlob G., Koch C. Logic-based Web Information Extraction // SIGMOD Record, Vol. 33, No. 2, June 2004. – pp. 87-94].
- Courcelle B. The monadic second-order logic of graphs xvi: canonical graph decompositions//Logical Methods in Computer Science, Vol. 2, 2006, pp. 1-18.
- Logical methods in computer science[Электронный ресурс]. – Режим доступа: www.lmcs-online.org.
- Беленький А. Текстомайнинг. Извлечение информации из неструктурированных текстов. [Электронный ресурс] / А. Беленький // Журн.
КомпьютерПресс
. – 2008. № 10. Режим доступа: http://www.compress.ru/article.aspx?id=19605&iid=905 – 18.09.2011. - Chia-Hui Ch. A survey of Web Information Extraction [Text] / Ch. Chia-Hui, K. Mohammed, R.G. Moheb, F. S. Khaled. // IEEE Transactions on Knowledge and Data Engineering – 2006. № 18/10. – С. 1411-1428.
- Агеев М. С. Извлечение значимой информации из web-страниц для задач информационного поиска [Текст] / М. С. Агеев, И. В. Вершинников, Б. В. Добров // Интернет-математика 2005. Автоматическая обработка веб-данных. – М.:
Яndex
, 2005. – С. 283-301. - Hatzivassiloglou V., Klavans J., Holcombe L., Barzilay R., Min-Yen Kan, McKeown R. SIMFINDER: A Flexible Clustering Tool for Summarization. Proceedings of the NAACL Workshop on Automatic Summarization, 2001.