Применение онтологий
Голиков Н.В.
Институт вычислительных технологий СО РАН, Новосибирск
1. Введение
В современном мире за последние два десятилетия появился бездонный и все разрастающийся объем информации. И все чаще люди, в поисках интересующих их данных обращаются не к книгам и другим людям, а начинают обыскивать страницы Интернета. Правда, со временем найти необходимую информацию стало не так просто.
Для повышения эффективности решения задач накопления, обработки, поиска и представления результатов измерений привлекаются современные достижения в области информационных технологий. Особый интерес представляют такие технологии, как XML, RDF и OWL, активно развивающиеся в рамках направления Semantic Web. Они позволяют накапливать, хранить, передавать большие объемы значений структурированных данных и связанных с ними метаданных унифицированным способом, не зависящим от особенностей реализации отдельных систем. Использование технологий Semantic Web при разработке программных систем измерения и сбора данных позволяет существенно упростить проблему совместимости систем из смежных областей и является первым шагом к построению высокоинтеллектуальных компонентов и агентов [1].
Концепция Semantic Web действительно произвела революцию, только "последствия" этой революции еще не наступили. Центральным компонентом концепции является применение онтологий. Онтологии разрабатываются и могут быть использованы при решении различных задач, в том числе для совместного применения людьми или программными агентами, для возможности накопления и повторного использования знаний в предметной области, для создания моделей и программ, оперирующих онтологиями, а не жестко заданными структурами данных, для анализа знаний в предметной области.
Авторы большинства статей по этой тематике описывают применение онтологии, определение которой трактуется неоднозначно в самых различных областях. Начиная от "умного" поиска, логических выводов, и заканчивая семантическими сетями. Последнее из перечисленного, на взгляд автора, является наиболее полезным.
Важнейшую роль в семантической сети должны играть специальные программы - интеллектуальные агенты, в задачу которых входит работа с информацией, представленной в семантической сети. Агенты по заданиям пользователей будут находить источники информации, запрашивать данные, сопоставлять и проверять их на соответствие критериям поиска, а затем выдавать ответ в удобной для пользователей форме. Онтологии же будут очень полезны для того, чтобы взаимодействие агентов было наиболее "эффективно". Скорее это и подразумевал консорциум W3, когда 10 февраля 2004 года рекомендовал к использованию стандарт Ontology Web Language (OWL) [2].
Об этом немного позже, сначала приведем несколько наиболее популярных определений онтологии.
2. Термин онтология
Онтология, являясь философской дисциплиной, изучает объекты, свойства которых являются общими для всего сущего. Когда же природа объектов различна, то в зависимости от контекста и целей использования онтологии, существуют несколько интерпретаций этого понятия [3]. Одни исследователи рассматривают онтологию как концептуальную "семантическую" сущность. Тогда онтология является концептуальной системой, которая предлагается в качестве базиса определенной базы знаний. Другие исследователи трактуют онтологию как специальный семантический объект, трактуют ее как представление концептуальной схемы логической теории, ее словарь или спецификация [4].
Онтологии во многом похожи на тезаурусы и таксономии, но на самом деле шире их, поскольку предоставляют дополнительные средства для описания структуры описываемых данных. Поскольку по своей сути онтологии - это информация об информации, то они являются метаданными.
Для систем искусственного интеллекта, которые, как правило, являются замкнутыми системами, существует только то, что уже в них представлено или может быть представлено, поэтому в области искусственного интеллекта самым распространенным определением онтологии является определение, данное в работе [5]. Согласно этому определению, онтология является точной спецификацией концептуализации. Точный смысл этой интерпретации зависит от понимания терминов "спецификация" и "концептуализация". Под концептуализацией может пониматься некоторая абстракция, т.е. упрощенное представление мира, построенное для определенной цели [4].
Концептуализация включает объекты, понятия и другие сущности, которые предполагаются существующими в рассматриваемой области, а также отношения между ними. С этой точки зрения каждая база знаний, система искусственного интеллекта или интеллектуальный агент явно или неявно фиксируются некоторой концептуализацией.
Надо отметить, что формальное определение предметной области является отдельной, достаточно сложной, задачей. Так, например, в [6] предметная область D определяется как множество объектов, отношений между объектами, а так же процессов изменения объектов и отношений, которые входят в сферу интересов конкретного субъекта или группы. D= (O and R and P), где O - универсальное множество объектов, R - универсальное множество отношений, P - универсальное множество процессов изменения объектов и отношений. Причем терминология предметной области T строится на основе нотационного бинарного отношения r = ((d;t): d in D, t in T). Здесь t - термин, обозначающий элемент d предметной области.
В центре большинства онтологий находятся классы, каждый из которых может иметь подклассы, представляющие собой более точные понятия, чем исходный класс. Все классы онтологии выстраиваются в одну или несколько иерархий и описывают понятия предметной области. При этом классы могут содержать атрибуты, которые описывают свойства и внутреннюю структуру понятий, лежащих в основе классов. Все подклассы наследуют атрибуты родительских классов. Каждый атрибут класса помимо названия имеет тип значения, разрешенные значения, число значений. Тип значения атрибута описывает, какие типы значений может содержать атрибут, например, строку или целое число. Существует также ограничение значения атрибута, состоящее в том, что он может принимать только определенные классы или экземпляры определенных классов.
Онтология может включать и экземпляры классов, то есть такие классы, в которых установлены значения всех их атрибутов. Считается, что онтология вместе с набором индивидуальных экземпляров классов образует базу знаний, хотя на самом деле трудно определить, где кончается онтология, и где уже начинается база знаний. Логические правила вывода при работе с онтологиями дают возможность манипулировать понятиями и данными гораздо эффективнее, позволяя извлекать новые знания.
3. Построение онтологии
Процесс разработки онтологии обычно начинается с того, что составляется глоссарий терминов (понятий), который в дальнейшем используется для исследования свойств и характеристик представленных в нем терминов. Далее на естественном языке создается список точных определений терминов, представленных в глоссарии. Затем на основе таксономических отношений строятся деревья классификации понятий (иерархии классов), которых в онтологии может быть несколько. Из понятий, не задействованных при составлении деревьев классификации, выделяются атрибуты классов и их возможные значения. Именно эти понятия и устанавливают основные связи между классами. После этого в зависимости от целей, для которых разрабатывается онтология, в нее могут добавляться экземпляры классов. И на последнем этапе эксперты по той предметной области, в которой разрабатывается онтология, создают правила логических выводов, позволяющие оперировать данными, представленными в онтологии, и извлекать из созданной онтологии новые знания.
Для описания онтологий использовались различные формальные языки, которые можно разделить на две группы. В первую входят традиционные языки описания онтологий: Interlinguas, CycL; языки, основанные на дескриптивных логиках (такие, как LOOM), и языки, основанные на фреймах (OKBC, OCML, Flogic). Вторая группа - языки, основанные на Web-стандартах: XOL, UPML, SHOE, RDF с RDFS, DAML, OIL, OWL, созданные специально для использования онтологий в WWW. Различия между языками заключаются в их возможностях по описанию предметной области и в некоторых возможностях механизма логического вывода для этих языков.
На базе языков DAML и OIL возникло совместное решение - DAML+OIL, вобравшее в себя всё лучше, что было в обоих языках, и по этой причине выбранное специалистами консорциума W3C в качестве базы для построения нового языка онтологий, когда средств XML и RDF оказалось недостаточно для представления информации и метаданных для построения полноценной семантически связанной сети. Новый язык получил название OWL (Web Ontology Language), и именно ему, по мнению консорциума, была уготована главенствующая роль в семантической сети. 10 февраля 2004 года консорциум W3C присвоил OWL статус рекомендованной к реализации технологии [2]. Эта дата и была названа некоторыми специалистами официальным днем рождения семантической сети.
Основными понятиями, с которыми оперирует язык OWL, являются классы, экземпляры, атрибуты и отношения. Классам отвечают основные понятия предметной области, образующие словарь ее терминов. С помощью атрибутов можно описать свойства, присущие тем или иным классам. Отношения задают взаимосвязи между классами.
Существуют два типа отношений: отношение "is-a" и "kind-of". Иерархия классов представляет отношение "is-a": класс А - это подкласс В, если каждый экземпляр В также является экземпляром А. Другой способ подхода к таксономическому отношению - это отношение "kind-of": Реактивный лайнер - вид самолета. Мясо - вид еды. Причем отношение подкласса транзитивно: если В - это подкласс А, а С - подкласс В, то С - подкласс А. Подкласс класса представляет понятие, которое является "разновидностью" понятия, представляемого надклассом. Следует избегать циклов в иерархии классов. Мы говорим, что в иерархии есть цикл, когда у некоторого класса А есть подкласс В и в то же время В - это надкласс А. Создание такого цикла в иерархии равнозначен объявлению того, что классы А и В эквивалентны. Язык OWL предусматривает возможность совместного использования онтологий: термины из одной онтологии могут содержать ссылки или определяться через термины из другой онтологии. Это позволяет избежать дублирования информации и дает возможность многократно использовать уже разработанные онтологии при создании новых. Надо отметить и появление языков запросов к онтологиям, таких, например, как RDQL. Механизм RDQL предоставляется набором библиотек Jena. Язык, используемый в RDQL, ярко напоминает широко распространенный SQL, только за основу в нем взяты не столбцы таблиц, а N-Triples. Одной из непосредственных возможностей данного механизма является способность дополнения неполных RDF троек.
Надо не забывать, что онтология не должна содержать всю возможную информацию о предметной области: вам не нужно конкретизировать или обобщать больше, чем вам нужно для вашего приложения. Также онтология не должна содержать все возможные свойства классов и различия между классами в иерархии. Однако в последнее время появилось множество попыток создать универсальную онтологию в той или иной области. При этом в скором времени более остро встанет задача не построения, а интеграции онтологий.
4. Применение онтологий
Онтологии разрабатываются и могут быть использованы при решении различных задач, в том числе для совместного применения людьми или программными агентами, для возможности накопления и повторного использования знаний в предметной области, для создания моделей и программ, оперирующих онтологиями.
Онтологии могут быть использованы везде, где требуется обработка данных, учитывающая их семантику. В силу изначальной ориентированности языка OWL на машинную обработку, правильное применение онтологий может, с одной стороны, существенно упростить и, с другой стороны, открыть новые возможности в разработке приложений, решающих задачи автоматизированной обработки и доступа к данным [4]. Приведем несколько вариантов использования онтологий.
Например, в работе [7] авторы используют онтологии для "извлечения значимой информации из web-страниц при индексировании". Предполагается повышение качества информационного поиска за счет удаления навигационной части из web-страниц, разделения web-страниц на содержательную и навигационную части. Данные методы основаны на выделении одинаковых частей страниц с одного сайта. В некоторой степени данная технология частично закрывает потребность в семантическом поиске.
В работе [8] для решения задачи повышения эффективности поиска в сети Интернет предлагается строить порталы знаний, каждый из которых предоставляет доступ к ресурсам сети Интернет определенной тематики. Основу таких порталов знаний составляют онтологии, содержащие описание структуры и типологии соответствующих сетевых ресурсов.
Интересное применение онтологий реализовано в ДО РАН [13]. Специалистами была построена "медицинская" онтология, позволяющая делать выводы. Задав симптомы, с помощью онтологий можно вывести диагноз. Еще одно применение описано в статье [9], "использование онтологии для построения инновационных цепочек в системе поддержки инновационной деятельности в регионе". Система реализуется в виде Интернет-портала и включает в себя, с одной стороны, информационную систему со средствами создания и интеграции связанных с инновациями разнородных информационных ресурсов, а с другой, - развитые средства персонального участия в инновационной деятельности специалистов различного профиля. Важным компонентом, обеспечивающим интеллектуализацию таких рабочих мест, является механизм, поддерживающий интерактивное построение инновационных цепочек. Создание цепочек выполняется по автоматически генерируемому сценарию, структура которого определяется структурой инновационной цепочки, заданной в онтологии инновационной деятельности и видом инновационного запроса.
Часто онтологии используют в качестве:
- "Словаря предметной области". Онтология содержит общую терминологическую базу предметной области, поэтому разработчики программного обеспечения могут использовать термины из онтологии для документирования своего продукта и для формирования пользовательского интерфейса, в том числе и многоязычного.
- "Отображения на базу данных". Онтология предоставляет набор базовых терминов предметной области, с которыми приходится иметь дело в любом процессе измерения. Поэтому онтология является удобным базисом для разработки схемы данных измерительной системы. Она не является полной, поскольку любой конкретный процесс измерения имеет частные особенности, не задаваемые на уровне онтологии. Тем не менее, она определяет базовые понятия, которые в той или иной форме присутствуют или должны присутствовать в любой схеме данных.
- "Формата хранения метаданных". Свойства онтологических терминов определяют состав и формат представления метаданных, содержащихся в системе. Эффективная поддержка метаданных является одной из ключевых задач инженерии информационных систем [15]. Привлечение онтологии позволяет повысить эффективность реализации различных средств обработки данных благодаря формированию богатых массивов метаинформации в машинно-читаемой форме.
- "Формата обмена данными". Открытые форматы обмена данными с внешними системами, основанные на онтологии, существенно упрощают задачу интеграции систем, относящихся к различным областям либо созданных различными разработчиками.
В [9] рассматривается подход к интеллектуализации систем документооборота, основанный на использовании знаний о предметной области, лингвистическом анализе текста документов и его содержательном индексировании.
Интересный подход описан в [11], где строится общая онтология тезаурусов (Generic Thesaural Ontology) GTO. В статье представляется подход к описанию различных тезаурусов на одном "общем" языке. Описан способ унификации шести основных тезаурусов их моделей, классов и отношений в абстракции более высокого уровня. Эти тезаурусы были выбраны, т.к. они хорошо известны, используются различными сообществами в различных областях, представленные как функциональной, так и субъектной схемой и основываются на стандарте ISO 2788.
- Australian Government Thesaurus [Keyword AAA]
- Getty Art and Architecture Thesaurus [AAT]
- Getty Thesaurus of Geographic Names [TGN]
- Library of Congress Subject Headings [LCSH]
- OCLC Dewey Decimal Classification [OCLC]
- Medical Subject Headings [MeSH]
Одна из наиболее важных задач, которую можно решить, используя онтологии - это семантический поиск. В настоящее время проблема поиска информации в больших массивах сравнивается с проблемой Вавилонской башни. Эта проблема усугубляется еще и тем, что существующие поисковые механизмы осуществляют поиск информации без учета семантики слов, входящих в запрос, а также контекста, в котором они используются.
Основополагающими характеристиками информационно-поисковых систем является полнота и релевантность результатов поиска. Полнота поиска тесно связана с оперативностью охвата информации системой. Созданная однажды база данных Интернет-ресурсов является "слепком" состояния Сети в конкретный момент. Если эта база не будет обновляться постоянно и оперативно, присутствующие в ней ссылки на документы станут мертвыми. Кроме того, отсутствие оперативности, обновления баз данных не позволит пользователю отслеживать последние изменения в его предметной области [12]. Полнота охвата ресурсов Сети - это один из двух главных аспектов характеристики полноты сетевой информационно-поисковой системы. Второй аспект связан с полнотой информации, предъявляемой пользователю по его запросу. Если предположить, что по запросу пользователя Q в базе данных находятся Р документов, соответствующих этому запросу, а предъявлено для просмотра всего N документов, то полнота системы определяется по формуле: П=(N/P)*100%. В случае, если П оказывается больше 100%, очевидно, что пользователю выдано минимум N-P документов, не соответствующих его запросу, т.е. нерелевантных. Под релевантностью понимается формальное соответствие информации, выдаваемой системой, запросу. Если по запросу пользователя получено N документов, представляющих собой объединение двух множеств документов: соответствующих запросу (пусть их количество - N1), и не соответствующих (их количество - N2), т.е. N = N1+N2. Тогда релевантность, как степень соответствия, определяется по формуле: Р = (N1/N)*100%, а шум - по формуле: S = (N2/N)*100% = 100% - P. Это определение характерно для формальной релевантности, однако, на практике используется другое, неформальное понятие - пертинентность (Рис 1).

Рис 1. Релевантность и пертинентность.
Для пользователя пертинетность, соотношение объема полезной для него информации к общему объему полученной информации, имеет решающее значение. При этом следует учитывать, что формальный запрос к системе является предметом творческого осмысления информационной потребности и не всегда точно отражает последнюю. Неумение большинства пользователей правильно формулировать запросы и получать приемлемые объемы отклика породило в конце 20 века мнение об Интернете, как об огромной информационной свалке. Именно для максимального удовлетворения информационных потребностей пользователей получили широкое практическое применение теории и методы семантических сетей, контент-анализа и глубинного анализа текстов (Text Mining). При этом возник новый класс систем, который все же позволяет справляться с "проблемой размерности" сети. Сегодня можно рассматривать в качестве одного из удивительных феноменов тот факт, что содержательные, семантически наполненные результаты формируются без непосредственного привлечения методов искусственного интеллекта, объемных баз знаний и даже экспертов как таковых, а путем использования частотно-лингвистических и эвристических методов. И сегодня эффективно работают в основном системы, базирующиеся именно на таких методах.
Благодаря онтологиям, появилась возможность создания семантических сетей.
В основе семантической сети лежат три принципа: агрегация, безопасность и
логика. Агрегация означает совместное использование данных. Подобно тому, как
гипертекст является неотъемлемой частью WWW и благодаря ему "всё можно
связать со всем", в Semantic Web при решении поставленной задачи могут
быть использованы любые данные. Для этих данных будет создана соответствующая
семантическая информация (онтологии), позволяющая использовать их надлежащим
образом. В основу безопасности, обеспечивающей доверие к семантической сети,
положены цифровые подписи, которые могут использоваться агентами и компьютерами
для проверки того, что информация получена из достоверного источника, например,
от какого-то публичного сервиса или персонального агента другого доверенного
пользователя. Логика - это набор правил описания информационной структуры
данных, протоколы и язык описания страниц. Именно логика дает семантической
сети правила вывода для проведения рассуждений и методики выбора тактик
выполнения операций с данными, чтобы получить ответы на вопросы.
Важнейшую роль в семантической сети должны играть специальные программы - интеллектуальные агенты, в задачу которых входит работа с информацией, представленной в семантической сети. Агенты по заданиям пользователей будут находить источники информации, запрашивать данные, сопоставлять и проверять их на соответствие критериям поиска, а затем выдавать ответ в удобной для пользователей форме. При необходимости агенты смогут осуществлять не только поиск информации, но и другие действия, в частности заказывать билеты или вносить записи о планируемых мероприятиях в персональный еженедельник.
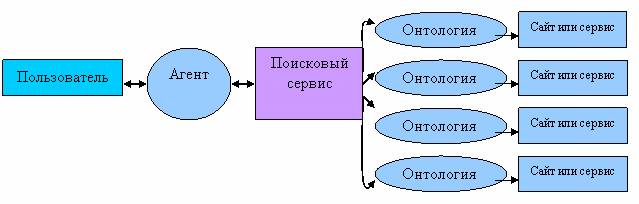
Рис. 2. Поиск нужной информации через поисковый сервис, работающий с
семантической сетью.
Агенты будут способны обмениваться между собой не только информацией и правилами логических выводов, используемых в онтологиях, но и цепочками построенных ими рассуждений, чтобы пользователь мог при необходимости проверить результат, либо на основании уже собранной информации другой агент попробовал найти более оптимальное решение или уточнить какие-то условия первоначального запроса. В определенных ситуациях для решения поставленной задачи может потребоваться и передача одним персональным агентом другому агенту некоторой личной информации пользователя (рис. 3).

Рис 3. Взаимодействие агентов.
5. Выводы
Семантическая сеть должна стать надстройкой над WWW. С ее помощью станет возможным создание новых сервисов, которые технически невозможны при нынешних принципах организации и работы Сети. Цепочки логических рассуждений, осуществляемые агентами, позволят получать информацию, представленную в Сети, в разрозненном виде, то есть из разных информационных источников. В дополнение к поисковым движкам (search engine) поисковые системы обзаведутся специальными логическими движками (logical engine), предназначенными для поиска и обработки информации в семантической сети. Комбинация этих двух поисковых механизмов позволит поднять качество и точность поиска в Сети на совершено иной уровень (рис. 4).

Рис. 4. Принцип работы поисковой системы, использующей поисковый и логический
модули.
По всем расчетам, переход к семантической сети не будет ни простым, ни быстрым. Работы начались еще в 1998 году, а официальная рекомендация OWL консорциумом W3C в качестве основного языка для описания онтологий была представлена только в феврале 2004 года. Немало специалистов считают, что семантический Web - это утопия, и с ними можно частично согласиться, поскольку его внедрение требует немалых усилий от различных категорий разработчиков и пользователей, включая разработчиков крупных информационных порталов, поисковых систем, каталогов и небольших сайтов, а также от разработчиков интеллектуальных программ-агентов.
Чтобы разработчики сайтов начали повсеместно внедрять поддержку онтологий в свои ресурсы, у них должен быть стимул, то есть использование онтологий должно давать их сайту некоторые преимущества, например, увеличение числа переходов с поисковиков или увеличение числа пользователей за счет предоставления дополнительных сервисов и т.п. Необходимы мощные и гибкие программы-агенты, которые смогут полноценно использовать возможности семантического Web'а. Но их активная разработка начнется только тогда, когда у пользователей появится реальная необходимость в них. Пока же большую часть статей по данной тематике можно отнести в раздел "наука ради науки".
Список литературы:
- Bacher R., Leal D., Schroder A. ScadaOnWeb - Modelling and Web-Exchange of Process and Engineering Information // Proc. International Semantic Web Conference. Cagliari, Italy, 2002.
- OWL Web Ontology Language guide. W3C working draft. W3 Consortium, 2003. http://www.w3.org/TR/2003/WD-owl-guide-20030331/.
- Guariano N., Giaretta P.Ontologies and Knowledge Bases. Towards a Terminalogical Clarification //Towards Very Large Knowledge Bases.1995-N.J.I.Mars (ed.) IOS Press, Amsterdam.
- Ковалёв С.П, Прокопов Н.А. "Автоматизация процессов измерения физико-химических величин на базе онтологий" Вычислительные технологии (в печати).
- Thomas R. Gruber. Towards Principles for the Design of Ontologies Used for Knowledge Sharing // International Workshop on Formal Ontology. 1993. March, Padova, Italy.
- Пименова Н.В. "Терминология предметной области, особенности ее формирования и использования для семантической классификации документов".
- М.С. Агеев И.В. Вершинников Б.В. Добров "Извлечение значимой информации из web-страниц для индексирования".
- О.И. Боровикова Ю.А. Загорулько "Организация порталов знаний на основе онтологий".
- С.В. Булгаков Ю.А. Загорулько "Использование онтологий для построения инновационных цепочек в системе поддержки инновационной деятельности в регионе".
- Ю.А. Загорулько, И.С. Кононенко, Е.А. Сидорова "Концепция интеллектуализации документооборота".
- Maria Lee Stewart Baillie Jon Dell'Oro "TML: A Thesaural Markup Language".
- Даниил Кальченко "Интеллектуальные агенты семантического Web'а" http://www.compress.ru/Archive/CP/2004/10/48/
- http://www.iacp.dvo.ru/RUS/
- Shankaranarayanan G., Even A. "The metadata enigma" // Comm. ACM, 49(2), 2006. P. 88-94.
- http://www.ontoprise.de/com/co_produ_tool2.htm
- http://kmi.open.ac.uk/projects/akt/about.html
- http://annotation.semanticweb.org/ontomat.html