
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования
- 3. Обзор исследований и разработки
- 4. Выводы
- Список источников
Введение
Эволюционные алгоритмы (ЭА)[2] – это стохастический метод поиска, который применялся для решения множества проблем поиска, оптимизации и машинного обучения. В отличие от большинства других технологий оптимизации, ЭА содержат популяцию пробных решений, которые конкурентно управляются по средствам применения некоторых различных операторов для поиска достоверного, если не глобального, оптимального решения. Среди распространенных подклассов ЭА широко изучаются генетические алгоритмы (ГА). Генетические алгоритмы[1] итеративно обучают популяцию индивидов, применяя оператор рекомбинации (объединяя двух или более родителей для получения одного или более потомков) и мутации их содержимого (случайное изменение проблемных переменных). Однако если придерживаться законов естественной эволюции, нельзя управлять одной популяцией, в которой взятая особь претендует на скрещивание с какими-либо другими партнерами в той же популяции (беспорядочное скрещивание). Напротив, вид развивается в рамках общин (подгрупп), где существует структурная близость, и склонен к воспроизведению внутри подгруппы. Среди расширений типов ГА особенно популярны. распределенные ГА (РГА), Распределенные эволюционные алгоритмы – это подкласс параллельных генетических алгоритмов, предназначенных для снижения преждевременной сходимости к локальному оптимуму, стимуляции разнообразия и поиска альтернативных решений той же проблемы. Они основаны на разбиении популяции на несколько отдельных подпопуляций, каждая из которых будет обрабатываться ГА, независимо от других. Кроме того, разнообразные миграции индивидов порождают обмен генетическим материалом среди популяций, которые обычно улучшают точность и эффективность алгоритма Мощность эволюционных алгоритмов усиливается с применением распределенных вычислений. Здесь пытаются промоделировать естественную модель взаимодействия отдельных популяций, для решения следующих задач:
- уменьшение вероятности преждевременной сходимости
- увеличение разнообразия популяции
- увеличение скорости сходимости к глобальному оптимуму или максимально оптимальному решению задачи.
Для решения двух этих главных задач существует большое количество работ, представленных в литературе.
1. Актуальность темы
В последнее время активно развиваются многоядерные вычислительные машины[4], обладающие возможностью многопоточных вычислений. При использовании многоядерных систем необходимо эффективно использовать механизмы распараллеливания процессов[5] для наиболее продуктивного использования вычислительных мощностей, в связи с этим использование параллельного генетического алгоритма видится более продуктивным, чем использование классического генетического алгоритма[3].
2. Цель и задачи исследования
Цель работы состоит в том, чтобы практически реализовать концепцию параллельного генетического алгоритма[6] с помощью фреймверка Java concurrent на многоядерных системах.
Основные задачи :
- Исследовать методы реализации параллельного генетического алгоритма.
- Выбрать метод реализации параллельного генетического алгоритма.
- Изучить литературу по параллельным генетическим алгоритмам.
- Реализовать изученные методы в программном проекте.
3. Обзор исследований и разработки
В настоящие время выделяют три основных типа параллельных генетических алгоритмов (ПГА)[8] :
- глобальные однопопуляционные ПГА, модель «хозяин-раб» (Master-Slave GAs);
- однопопуляционные ПГА (Fine-Grained GAs);
- многопопуляционные ПГА (Coarse-Grained GAs).
3.1 Модель «Хозяин – раб»
Модель «хозяин – раб» характеризуется тем, что в алгоритмах такого типа селекция принимает во внимание целую популяцию,в отличии от двух других моделей. Также стоит отметить то, что возможно случайное скрещивание ,то есть любые два индивида могут скрещиваться , в других моделях скрещивание ограничивается строго определенным набором индивидуумов . В алгоритмах второго класса существует главная популяция, но оценка целевой функции распределена среди нескольких процессоров. Хозяин хранит популяцию, выполняет операции ГА и распределяет индивидуумы между подчиненными. Они же лишь оценивают ЦФ индивидуумов. Однопопуляционные ГА пригодны для массовых параллельных компьютеров и состоят из одной популяции. Селекция и скрещивание ограничены отношениями близкого родства. Данный класс ПГА может быть эффективно реализован на параллельных компьютерах. Третий класс – многопопуляционные ГА более сложная модель, так как она состоит из нескольких подпопуляций, которые периодически, по установленным правилам, обмениваются индивидуумами. Такой обмен индивидуумами называется миграцией и управляется несколькими параметрами.
Многообщинные ГА очень популярны, но достаточны сложны как для понимания так и для реализации, потому что последствия от эффекта миграции, на данный момент, не полностью исследованы. В то же время многообщинные ГА имеют сходство с «островной моделью» в популяционной генетике, которая рассматривает относительно изолированные общины; поэтому параллельные ГА в некоторых случаях называют «островными» параллельными ГА.
3.2 Островная модель
Использование небольшого числа относительно больших подпопуляций и миграция между ними – является одной из главных характеристик многообщинных ПГА. Можно предположить , что первым систематическим изучением параллельных ГА с множеством популяций была диссертация Р.Б.Гроссо (Grosso). Его целью было имитировать взаимодействие параллельных субкомпонентов эволюционирующей популяции. При этом Гроссо имитировал диплоидных особей (использовались две субкомпоненты для каждого «гена»), и популяция была разделена на 5 общин. Каждая община обменивалась индивидуумами со всеми другими общинами при установлении фиксированных коэффициентов миграции. Экспериментальным путем Гроссо определил, что улучшение средней ЦФ популяции происходило быстрее при маленьких общинах, чем при одиночной популяции. Это подтверждает устоявшийся в генетике популяций принцип: благоприятные признаки распространяются быстрее, когда общины маленькие, чем когда они большие. Однако он также заметил, что когда общины были изолированы, стремительный рост ЦФ остановился на меньшем значении, чем при большой популяции. Другими словами, качество найденного решения до сходимости было хуже в изолированном случае, чем в одиночной популяции. При низком коэффициенте миграции общины все еще вели себя (работали) независимо друг от друга и исследовали различные регионы пространства поиска. Мигранты не оказывали значительного эффекта на поведение общин, и качество решений было сопоставимым со случаем, когда общины были изолированы. Однако при средних коэффициентах миграции разделенная популяция нашла решения, схожие с теми, что найдены для одиночной популяции. Эти наблюдения показывают, что имеется критическое значение коэффициента миграции, ниже которого производительность алгоритма затрудняется ввиду изоляции общин. Для вышележащих значений этого коэффициента разделенная популяция находит решения того же качества, что и обычная одиночная популяция. Обычно данная модель разрабатываются для кластерных архитектур, которые состоят из нескольких независимых рабочих станций со своей локальной памятью. На каждой из таких систем выполняется своя копия ГА (построение новых поколений популяций). При этом генетические параметры работы этих алгоритмов должны несколько отличаться друг от друга. Это позволит направить поиск на каждом таком «острове» в отличном от других направлении. Через заданное количество итераций острова производят обмен лучшими особями, что позволяет корректировать направление поиска для менее удачных островов. Эффективность параллельных ГА, построенных по такой схеме, определяет именно по взаимодействию компонент. Можно выделить основные характеристики такого обмена:
- топология, которая определяет, какие подпопуляции будут считаться соседними и, соответственно, между какими островами будет возможен обмен особями ;
- время изоляции, которое определяет, сколько эпох ГА не будет производиться миграция;
- степень миграции, которая определяет количество особей, участвующих в миграции;
- стратегия отбора особей для миграции;
- стратегия удаления особей из подпопуляции при проведении миграции;
- стратегия репликации мигрирующих особей.
Заметим также, что хотя популяции развиваются независимо и равноправно, в реали-зациях такого вида алгоритмов выделяется сервер, который инициализирует работу и реализует топологию обмена данными. Более того, синхронизация работы копий ГА на островах требует способа их взаимодействия. Точная и корректная реализация такого взаимодействия различных копий ГА в модели островов является сложной задачей . Популярность многообщинных параллельных ГА объясняется тем что :
- Многообщинные ГА выглядят как простое расширение последовательного ГА. Схема очевидна: взять несколько простых последовательных ГА, запустить их на узле параллельного компьютера и в предварительно определенное время обмениваться несколькими особями.
- Требуется относительно мало дополнительных усилий для конвертирования последовательного ГА в многообщинный ГА. Большая часть программы последовательного ГА хранит стндартную информацию и следует добавить небольшое количество дополнительных подпрограмм, чтобы реализовать миграцию.
Обобщенную схему миграционной модели ГА вы можете увидель на рисунке 1.
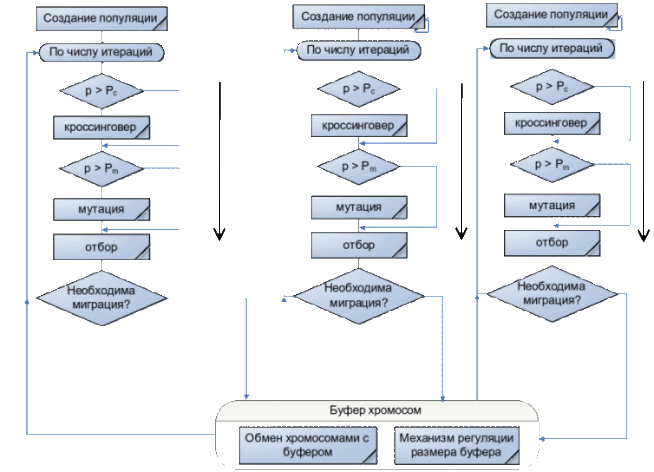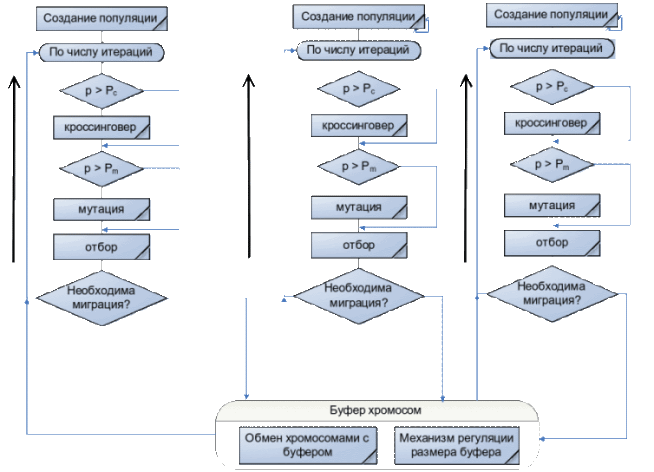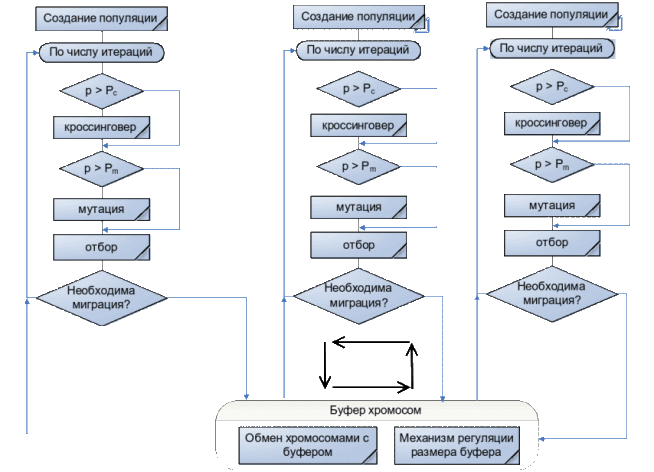
Рисунок 1 – Миграционная модель ГА
(анимация: 3 кадра, постоянное повторение, 150 килобайта)
Построение ПГА с помощью Java Concurrent[7]. Фреймверк Java Concurrent[9] содержит широкий набор средств для распараллеливания и дальнейшей синхронизации параллельных процессов. Одним из таких наборов являются параллельные коллекции. Параллельные коллекции облегчают разработку многопоточных программ, предоставляя потокобезопасные, удачно сделанные структуры данных. Однако в некоторых случаях разработчику нужно сделать еще один шаг вперед и подумать о регулировании и/или ограничении выполнения потоков. Так как пакет java.util.concurrent призван упростить многопоточное программирование, именно поэтому в него включены утилиты для синхронизации. Модель миграции представляет популяцию как множество подпопуляций. Каждая подпопуляция обрабатывается отдельным потоком (Thread_N). Эти подпопуляции развиваются независимо друг от друга в течение одинакового количества поколений ,по истечению времени изоляции (время изоляции будет зависит от параметра – Sleep,который будет вызывается на текущем Thread,то есть на текущей подпопуляции – Thread_N.sleep(время изоляции)) происходит обмен особями между подпопуляциями. Количество особей ,подвергшихся обмену ,метод отбора особей для миграции и схема миграции определяет частоту так называемого генетического многообразия в подпопуляциях и обмен информацией между подпопуляциями. Отбор особей для миграции происходит с помощью пропорционального отбора. Для миграции берутся наиболее пригодные особи. Так при использовании пропорционального отбора в неограниченной миграции сначала формируется коллекция из наиболее пригодных особей ,отобранных по всем подпопуляциям. Так как в каждом потоке Thread_N обрабатывается своя подпопуляция, то и особи каждой подпопуляции содержаться в коллекции своего потока выполнения. Используются коллекции типа HashSet[10], в которых содержаться искомые подпопуляции. Ниже приведен фрагмент кода на Java ,который показывает представление подпопуляции в виде коллекции типа HashSet :
-
Set
subpopulations_1=new HashSet (); - Set
subpopulations_2=new HashSet (); - Set
subpopulations_3=new HashSet (); - Set
subpopulations_N=new HashSet ();
Генеральная, либо «общая» популяция представлена в том же виде :
- Set
unionpopulations=new HashSet ();
На основе такого подхода формируется «общая» коллекция ,которая содержит особи из каждой коллекции подпопуляций. Случайным образом из этой «общей» коллекции выбирается особь , и ею заменяют наименее пригодную в подпопуляции N. Аналогичные действия проделываем с остальными подпопуляциями. При таком подходе так же возможно ,что какая-то подпопуляция получит дубликат своей «хорошей» особи. Весь этот механизм обмена особями подпопуляций реализован через так называемый пул потоков. Пул потоков предлагает решение и проблемы издержек жизненного цикла потока, и проблемы пробуксовки ресурсов. При многократном использовании потоков для реализации новой подпопуляции, издержки создания потока распространяются на многие задачи. В качестве бонуса, поскольку поток уже существует, когда прибывает запрос, задержка, произошедшая из-за создания потока, устраняется. Таким образом, запрос может быть обработан немедленно, что делает наше приложение более быстрореагирующим. Ниже представлена схема работы с пулом потоков :
- public class WorkQueue
- {
- private final int nThreads;
- private final PoolWorker[] threads;
- private final HashSet queue;
- public WorkQueue(int nThreads)
- {
- this.nThreads = nThreads;
- queue = new HashSet();
- threads = new PoolWorker[nThreads];
- for (int i=0; i
- threads[i] = new PoolWorker();
- threads[i].start();
- }
- }
В данном фрагменте кода представлена очередь потоков. Каждый поток содержит свои подпопуляции особей ; пул потоков обеспечивает и безопасный обмен особями ,исключая взаимные блокировки потоков, что в свою очередь обеспечивает лучшую производительность и меньшее время на выполнение операции миграции между подпопуляциями.
Выводы
Для выполнения поставленной задачи – реализации параллельного генетического алгоритма была выбрана стратегия миграции особей между подпопуляциями, так же называемая «миграционной моделью». Для практической реализации был выбран объектно-ориентированный язык Java и фреймверк для распараллеливания Java Concurrent. Для синхронизации параллельных потов используется пул потоков, который обеспечивает безопасный обмен особями, исключая взаимные блокировки потоков, что в свою очередь обеспечивает лучшую производительность и меньшее время на выполнение операции миграции между подпопуляциями. Было установлено, что мощность эволюционных алгоритмов усиливается с применением параллельных вычислений. Использование параллельных алгоритмов дает большую выгоду в производительности системы и времени выполнения поставленной задачи.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2013 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Курейчик В.М., Кныш Д.С. Параллельный генетический алгоритм. Модели и проблемы построения // – С.1 – 3.
- Интернет-ресурс. - Режим доступа:www/ URL: http://www.gotai.net/ – сайт по ИИ.
- Гладков Л.А., Курейчик В.М., Курейчик В.В. Генетические алгоритмы [Текст]/под ред. В.М. Курейчика . – 2-е издн., испр. и доп. – М.:ФИЗМАТЛИТ ,2006 .-320 с.
- Иванов Д.Е., Чебанов П.А. Взаимодействие компонент в распределённых генетических алгоритмах генерации тестов / Д.Е. Иванов, П.А. Чебанов // Наукові праці Донецького національного технічного університету. Серія: “Обчислювальна техніка та автоматизація”. Випуск 16(147).- Донецьк: ДонНТУ.- 2009.- С.121-127.
- Grosso P.B. Computer Simulations of Genetic Adaptation: Parallel Subcomponent Interaction in a Multilocus Model// Unpublished doctoral dissertation, The University of Michigan. (University Microfilms №8520908), 1985.
- Курейчик В.М., Родзин С.И. Эволюционные алгоритмы: генетическое программирование. Обзор // Известия РАН. Теория и системы управления.-2002.-№1.-С.127-137.
- SDN for Java Concurrent / Интернет-ресурс. - Режим доступа: http://docs.oracle.com/javase...
- Mitchell M. An Introduction to Genetic Algorithms [Текст]/M.Mitchell. — Cambridge: MIT Press, 1999 —158 c. — ISBN 0-262-13316-4 (HB), 0-262-63185-7 (PB).
- Java Concurrency in Practice Brian - Goetz, Tim Peierls, Joshua Bloch — Москва: Sun Press, 2012 —983 c. — ISBN 0-262-13316-4 (HB), 63185(P).
- Java 2. Библиотека профессионала. Том 1. Основы - Кей С. Хорстманн, Гари Корнелл. - Москва: Sun Press, 2012 —989 c. — ISBN 0-262-13316-4 (HB), 0-262-63185-7 (PB).