
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования
- 3. Обзор исследований и разработок
- 4. Применение нечётких показателей в задаче отбора персонала на вакансию
- Выводы
- Список источников
Введение
В процессе приема сотрудников работодателю приходится принимать важные решения, от которых будет в дальнейшем зависеть эффективность функционирования бизнеса и социально-психологический климат в коллективе. При приеме на работу, помимо профессиональных навыков претендентов на определенную должность, важными являются их личностные качества: исполнительность, ответственность, пунктуальность, умение работать в команде, дружелюбность и общительность. Неправильный выбор специалистов для работодателей влечет за собой негативные последствия в виде неоправданных материальных затрат и потерь рабочего времени.
Подбор персонала – это процесс управления в сложной системе с множеством объектов, которыми являются, с одной стороны, организация и представляющие ее сотрудники, с другой – претенденты на должность, обладающие профессиональными и личностными навыками. Для автоматизации процесса управления подбором персонала невозможно разработать универсальную формализованную модель в силу специфических требований к претендентам со стороны различных организаций и учреждений, выступающих в качестве работодателей на современном рынке труда. В то же время повысить эффективность управления этим процессом можно путем создания системы поддержки принятия решений соответствия уровня подготовки специалиста требованиям рынка труда.
1. Актуальность темы
Современное общество характеризуется интенсивным развитием техники и технологий, а также большими объемами перерабатываемой информации, что обуславливает устойчивый рост требований к уровню подготовки специалистов различного профиля.
Сегодня очень актуальной является проблема поиска работодателями квалифицированных кадров для повышения эффективности работы предприятия. Для решения этой проблемы нужно отобрать ограниченное число «лучших» претендентов на собеседование с работодателем [2]. Необходимо разработать систему отбора кандидатов, которая составит рейтинг претендентов. Исходные данные для расчета рейтинга – данные анкет соискателей.
Сейчас чаще всего для оценивания кандидата используется собеседование. Этот метод имеет ряд недостатков. На восприятие кандидата интервьюером оказывают влияние стереотипы, первое впечатление, физическая привлекательность (непривлекательность), манеры, положение, одежда и прочие факторы, ключевой причиной которых можно назвать субъективность интервьюера. На основе изложенного представляется необходимым разработка компьютеризированной системы отбора персонала, с прохождением этапа тестирования, на котором оценка не зависит от субъективного фактора и дает устойчивый результат.
2. Цель и задачи исследования
Цель исследования – разработка интеллектуальной системы отбора ограниченного числа претендентов на собеседование с работодателем
Задачей исследования является оптимизация процесса отбора кандидатов из ограниченного количества претендентов на вакантную должность для собеседования с работодателем с использованием методов нечёткой логики.
На основе анализа предметной области можно выделить следующие задачи, которые должна решать система подбора кандидатов:
3. Обзор исследований и разработок
Анализ состояния разработки проблемы подбора персонала показал, что имеющиеся на рынке программные продукты (Personnel Manager, «БОСС-Кадровик», «Радость кадровика», «1С: Зарплата и Управление Персоналом 8.0» и др.) не позволяют обеспечить информационно-аналитическую поддержку принятия решения по отбору персонала с учетом приоритетности и противоречивости выдвигаемых требований к персоналу, что обуславливает необходимость разработки нового компьютерного метода отбора персонала фирмы [2]
В качестве программной базы нового метода отбора персонала фирмы предлагается использовать Экспертную систему поддержки принятия решений в кризисных ситуациях (ЭС ПРКС), основанную на автоматической классификации текущей ситуации в условиях неполной и нечёткой входной информации и формировании управленческого решения, соответствующего распознанному классу ситуации [3].
Подобная система поддержки принятия решений уже разрабатывалась многими компаниями, одним из используемых решений для крупных предприятий являются системы SAP [4]:
- решение «Управление человеческим капиталом» SAP ERP Human Capital Management(SAP ERP HCM). Структура этой традиционной системы учёта кадров представлена на рисунке 1.
- модуль SAP ERP HCM для подбора персонала SAP E-Recruiting. Он включает множетво функций необходимых кадровому агентству, возможна регистрация кандидатов через интернет, функциональность расширена.
- компонент «Бизнес-аналитика» SAP Business Intelligence(SAP BI). Это система принятия решений, которая использует методы интеллектуального анализа данных не только для подбора персонала, но и для других сфер функционирования предприятия: планирование, производство, сбыт.

Рисунок 1 – Архитектура решения SAPERPHCM
Так как модуль SAP E-Recruiting является специализированным в части подбора персонала, его использование будет включать наименьшее количество доработок, покрывающих функциональные дефициты системы. Однако его применение будет более эффективным при совместной эксплуатации с компонентом SAP Business Intelligence, использующим методы Data mining.
Известны также и другие способы решения задачи отбора претендентов с использованием нейронных сетей [5] и дерева решений [6]. Недостатком данных методов является то, что они не позволяют в полной мере оценить профессиональные качества соискателей в соответствии с требованиями работодателей. Они дают возможность анализировать только данные из анкет соискателей. Однако дерево решений будет целесообразно использовать для классификации профессиональных навыков, определения степени важности и зависимости между ними.
Известен так же новый подход к оценке претендентов на вакансии в онлайн-системе подбора персонала с использованием таксономии, алгоритмов машинного обучения для решения проблемы расчета рейтинга кандидата и проведения семантических методов сопоставления [7]. Предлагаемая система извлекает набор объективных критериев из профиля LinkedIn кандидата, и сравнивает их семантически с предъявляемыми требованиями. Он также выводит их личностные характеристики на основе лингвистического анализа их блога. Преимуществом данной системы является то, что результаты её работы постоянно сравнивалась с рекрутерами, а также, что её можно использовать для автоматизации расчета рейтинга кандидатов и изучения личностных характеристик. Недостатки: для работы алгоритма необходима обучающая выборка с оценками экспертов и большая трудоёмкость.
В книге А.В. Андрейчиков О.Н. Андрейчикова. «Анализ, синтез, планирование решений в экономике» в разделе 4.8.3 «Метод нечеткого логического вывода в задаче выбора фирмой кандидата на замещение вакантной должности бухгалтер» описан подход, использующий метод нечёткого вывода для решения задачи подбора персонала. Суть которого, состоит в следующем: составляются правила и записываются в базу знаний интеллектуальной системы. В процессе решения задачи пользователем задаются исходные данные, которые представляют собой значения лингвистических переменных, соответствующих требованиям. Обработка этих данных осуществляется посредством процедур нечеткого логического вывода. Результатами работы системы являются нечеткое множество, полученное для заданного кандидата, и мера его сходства с возможными исходами, т. е. нечеткими множествами. В результате сортировки претендентов составляется рейтинг кандидатов, который и позволит выделить лучших кандидатов, которые пойдут на собеседование [8].
Описанный метод принятия решений с использованием правил нечеткого вывода является адаптацией нечеткой логики к процессам принятия решений с исходными данными в виде точечных оценок. В ряде случаев оценивание альтернатив удобнее производить с использованием нечетких чисел, которые являются значениями лингвистических переменных. При этом правила могут применяться не одновременно, а последовательно. Такой подход к компьютерной поддержке процессов принятия решений используется в интеллектуальных системах с нечеткой логикой.
Преимуществом данного подхода является то, что формализация знаний с помощью правил позволяет учитывать различную важность критериев и самих правил для формирования требований к должности. Для учета различной важности правил в книге используются нормированные весовые коэффициенты, которые можно получить либо путем попарных сравнений, либо путем экспертного назначения весов.
В своей работе я буду использовать экспертное назначение весов, так как это позволит учитывать важность каждого критерия и упростит работу пользователя с системой. В рассматриваемой задаче возможны различные подходы к выбору кандидата на должность: мягкий, жесткий, рациональный и т. д. Я буду использовать в своей работе жёсткий подход. Жесткий подход к выбору кандидата на должность возможен в случае избытка квалифицированных кадров и ресурса времени, отводимого для выбора. Целью такого подхода является поиск кандидата, наиболее соответствующего идеалу.
Недостатком данного подхода является то, что он не учитывает при оценивании кандидата их профессиональные данные, не описан алгоритм оценивания степени обладания этими навыками, не описан этап получения входных данных для работы системы, а так же задача подбора персонала рассмотрена в узкой направленности – только для должности бухгалтер.В своей работе я учту эти недостатки и постараюсь устранить.
Таким образом, для решения задачи отбора претендентов на вакантную должность я буду использовать методы нечеткой логики. Применение нечеткой логики для решения данной задачи позволит формализировать знания экспертов при формировании требований работодателем к должности [9].
4. Применение нечётких показателей в задаче отбора персонала на вакансию
Приведем формальную постановку задачи отбора персонала:
1. Задано множество требований Tm, предъявляемых к претенденту на вакансию m:
Tm = {P1m, P2m, …, Pnm};
Pim = {Qi1m, Qi2m, …, Qikm};
Pim – множество значений для каждого требования;
Qijm – значение для требования к претенденту на вакансию m;
i = 1, …, n;
j = 1, …, k;
m = 1, ..., M;
n – число требований к претендентам на вакансию m;
k – число значений для каждого требования;
M – число вакансий;
2. Множество Gm коэффициентов – «критериев важности», определяющих "уровень важности" всех требований.
Gm = {G1m, G2m, …, Gnm};
3. Множество Ls характеристик претендента s.
Ls = { L1s, L2s, …, Lzs };
Lis = { Qi1s, Qi2s, …, Qils };
i = 1, …, z;
s = 1, …, S;
z – количество характеристик претендента s;
l – количество значений каждой характеристики кандидата;
S – количество претендентов на вакансию m;
L – множество всех претендентов.
Требуется:
Выбрать множество P претендентов на вакансию m - требуемое количество претендентов, в соответствии с предъявляемыми к ним требованиям.
P = { P1, P2, …, PS };
Одной из основных задач для построения системы отбора кандидатов, является задача определения множества Gm – «критериев важности».
Выбор претендентов на вакансию m:
1. Формирование списка требований с заданными значениями.
2. Определение «критериев важности» каждого требования путем экспертного назначения весов.
3. Определения степени соответствия претендентов вакансии с помощью дерева решений и алгоритма нечеткого вывода Сугено.
4. Формирование списка «лучших» претендентов.
Предполагается использование следующих данных в качестве лингвистических переменных для формирования рейтинга претендентов с помощью нечеткого вывода[10]:
Вид деятельности (анализируется на этапе выборки кандидатов из базы данных агентства); дата рождения (на основании которой будет рассчитан возраст); общий трудовой стаж работы; стаж работы на вакантной должности; пол; образование; специальность и квалификация; занимаемые должности; причины увольнения; наличие опыта работы на руководящих должностях; опыт работы с компьютером; языковые навыки и т.д.
Возраст (рассчитывается на основании даты рождения)[11]:
- От 18 до 24 лет: юный;
- От 22 до 29 лет: молодой;
- От 27 до 39 лет: средний;
- От 36 до 54 лет: выше среднего;
- От 50 до 65 лет: старческий;
- Больше 60 лет: преклонный.
На рисунке 2 представлен вид функции принадлежности для возраста.
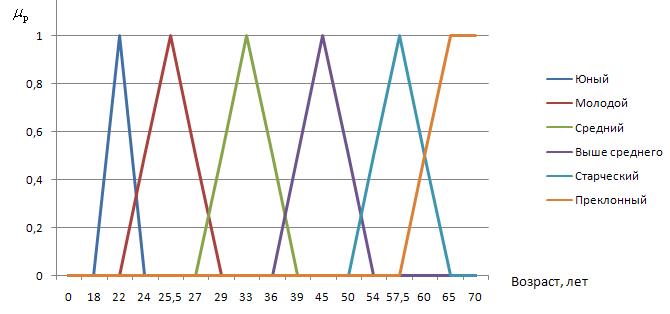
Рисунок 2 – График функции принадлежности для лингвистической переменной «Возраст»
Аналогичным образом можно представить остальные лингвистические переменные.
Общий трудовой стаж работы (в годах):
- [0; 3]: начальный;
- [2; 6]: небольшой;
- [5; 10]: средний;
- [8; 20]: высокий;
- >=15: очень высокий.
Стаж работы на вакантной должности (в годах):
- [0; 3]: начальный;
- [2; 6]: небольшой;
- [5; 10]: средний;
- [8; 20]: высокий;
- >=15: очень высокий.
Наличие опыта работы на руководящих должностях:
- От 0 до 1: отсутствует;
- От 0,5 до 3 лет: небольшой;
- Свыше 2-х лет: большой.
Пол:
- Женский;
- Мужской;
Образование:
- Среднее;
- Среднее специальное;
- Неполное высшее;
- Высшее.
Специальность:
- Соответствует требуемой;
- Не соответствует требуемой.
Квалификация:
- Соответствует требуемой.
- Не соответствует требуемой.
Занимаемые должности:
- Хотя бы одна соответствует требуемой.
- Ни одна не соответствует требуемой.
Причины увольнения:
- По инициативе работника;
- По инициативе собственника (администрации) предприятия;
- По обоюдному согласию работника и администрации;
- Другое.
Опыт работы с компьютером:
- Да;
- Нет.
Языковые и другие навыки:
- Обладает;
- Не обладает.
Были выбраны основные параметры, которые наиболее часто встречаются в требованиях работодателей и имеют наибольшую значимость для них. При составлении списка требований работодателю необходимо задать значение для каждого навыка. При этом должна быть возможность задавать неограниченное количество требований, с возможностью редактирования перечня возможных навыков.
Степень обладания профессиональными навыками можно получить, используя дерево решений. Проанализировав требования из крупнейшего в Украине сайта поиска работы и сотрудников – work.ua, были выбраны наиболее часто встречающиеся навыки для построения дерева решений отдела информационных технологий (ИТ). Для отдела ИТ дерево решений будет иметь следующий вид:

Рисунок 3 – Дерево решения для задачи подбора персонала в ИТ отделе
(анимация: 5 кадров, 5 циклов повторения, 20 килобайт)
Рассмотрим данные, взятые из требования на вакантную должность, а также характеристики кандидатов из их анкет из сайта work.ua.
Вакансия №1
Разработчик .NET / C#
24000 грн., по результатам собеседования
Компания:
Укринвент, ООО
Все вакансии этой компании
Город:
Киев
Вид занятости:
полная занятость
Требования к соискателю
• опыт работы от 1 года
• не имеет значения, готовы взять студента
Описание вакансии
Молодой компании для создания приложений под Windows требуется адекватный умеющий работать в команде разработчик .NET/C#.
Требования.
• Знания и опыт работы с .NET Framework / C#
• Знания принципов ООП
• Навыки разработки пользовательского интерфейса WPF
• Сетевые технологии, WCF
• Понимание архитектуры ОС, и принципов её работы.
Условия.
Мы предоставляем офис в районе метро Шулявская, дружную атмосферу, наличие коллег-программистов в коллективе, нестандартные и интересные задачи, лояльное руководство, гибкий график (возможно совмещение с учебой).
ЗП достойная по результатам собеседования и выполнения небольшого тестового задания.
Составим базу правил для основных требований анкеты. Для этого будем использовать алгоритм нечёткого вывода Sugeno. Достоинством этого алгоритма является то, что при построении правил существует возможность задавать весовые коэффициенты для каждого из подусловий.
Входные переменные:
Пусть х1 – опыт (стаж) работы от 1 года,
х2 – знания и опыт работы с .NET Framework,
х3 – знания и опыт работы с C#,
х4 – знания принципов ООП,
х5 – навыки разработки пользовательского интерфейса WPF
х6 – сетевые технологии, WCF.
База правил для вакансии №1:
Если х1 есть «любой», то степень истинности подзаключения:
W = 0,2 С1. Вес правила: F1 = 0,3.
Если х2 есть «да» и х3 есть «да», то степень истинности подзаключения:
W = 0,8 С2+ 0,8 С3. Вес правила: F1 = 0,6.
Если х4 есть «да», и х3 то степень истинности подзаключения:
W = 0,9С4. Вес правила: F1 = 0,9.
Если х5 есть «да» и х6 есть «да», то степень истинности подзаключения:
W = С5+ С6. Вес правила: F1 = 1.
Рассмотрим данные из 2-х анкет, взятых с сайта work.ua. В целях сохранения конфиденциальности информации о кандидатах, их личные данные, которые не будут анализироваться, были изменены.
Анкета №1
Петров Пётр Петрович
Системный администратор, от 2000 грн./мес., полная занятость
Дата рождения:
3 июня 1989 (23 года)
Город:
Петровск
Контактная информация
Для просмотра контактной информации нужно войти как работодатель илизарегистрироваться.
Опыт работы
администратор
с 01.2007 по 09.2011 (4 года 8 месяцев)
next (локальная компьютерная сеть)
В обязанности входило подключение абонентов, настройка клиентского ПК для работы в сети, консультации (телефонный режим) по общим вопросам касаемых работы ЛКС
Образование
Высшее
с 09.2006 по 06.2011
Херсонский национальный технический университет, кибернетика, программное обеспечение автоматизированных систем, Херсон.
Профессиональные навыки
Навыки работы с компьютером, ПО
знаение ОС Windows, Linux, MS Office, web-программирование
Владение языками
Русский — эксперт
Украинский — эксперт
Английский — средний
Дополнительная информация
целеустремленный, ответственный, пунктуальный, аккуратный, новые знания и навыки даются легко.
Рассчитаем степень истинности подусловия для первого правила, для первого подусловия. Треугольная функция принадлежности рассчитывается по формуле:
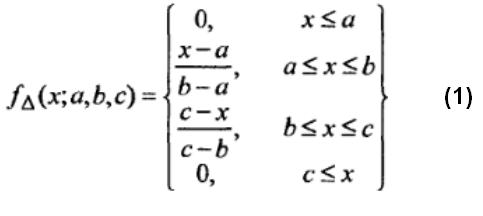
Х1 = 2 года
Для первого терма опыт работы = начальный.
B11 = (с – x)/(с-b), т.к. опыт работы «начальный» [0;3], b<=x <=c
A,b,c – точки для треугольной функции принадлежности,
B11 – степень истинности 1-го подусловия для 1-го терма.
B11 = (3 – 2)/(3 – 1,5) = 0,67,
Для второго терма опыт работы = небольшой.
В12 = 0, т.к. x <=а
Аналогично, для остальных термов: В13 = 0, В14 = 0, В15 = 0.
Bi – степень истинности для всего подусловия.
В1 = max(Вi+j) = 0,67;
M’(y) = average(Bi), для проверки всех требований больше подходит.
M’(y) = 0,2/1 = 0,2;
Ci – степень активации для всего подусловия c учётом веса правила.
C1 = M’(y) * F1, где F1 – вес правила.
C1 = 0, 2*0,3 = 0,06;
Wi – степень истинности подзаключений.
W1 = Е1* B1, где Е1 – весовой коэффициент в базе правил.
W1 = 0,2*0,67 = 0,134 – степень истинности подзаключений по 1-му правилу.
Аналогично, просчитываем степень истинности подзаключений (Wi) и степень активации (Ci), получим:
Для 2-ого правила:
В1 = max(Вij) = 0,5; В2 = max(Вij) = 0;
В1 – степень истинности .NET, которую определяем согласно данным из дерева решений.
В2 – степень истинности C#, равна 0, т.к. не обладает этим навыком, согласно дереву решений.
M’(y) = average(Bi), для проверки всех требований больше подходит.
M’(y) = 0,5/2 = 0,25;
C2 = M’(y) * F2, где F2 – вес правила.
C2 = 0,25*0,6 = 0,15;
W2 = Е1* B1 + Е2* B2, где Еi – весовые коэффициент в базе правил.
W2 = 0,8*0,25 + 0,8*0=0,2– степень истинности подзаключений по 2-му правилу.
C3= 0,W3= 0, C4= 0,W4= 0, так как кандидат не обладает такими навыками.
При помощи формулы центра тяжести для одноточечных множеств получим:
y= sum(Ci *Wi)/ sum(Ci);
y=(0,2 *0,134+ 0,15*0,2+0*0+0*0)/(0,2 +0,15+0+0) =0.162 – степень соответствия Анкеты №1 Вакансии №1.
Анкета №2
Васильев Василий Васильевич
C# developer, полная занятость, неполная занятость
Дата рождения:
24 марта 1993 (20 лет)
Город:
Васильевск
Контактная информация
Для просмотра контактной информации нужно войти как работодатель или зарегистрироваться.
Образование
Неоконченное высшее
с 09.2009 по 09.2014
КПИ, ФИОТ, Киев.
Дополнительная информация
Васильев Василий Васильевич
Место проживания: Васильевск, ул. Василевская, 18/20
Телефон: [просмотреть контакты]
E-mail: [просмотреть контакты]
Цель: Совершенствование и освоение практических навыков в реальных проектах.
Образование:
2009 – наст.вр. – Киевский Политехнический институт, факультет Вычислительной техники и информатики, специальность: «системная инженерия»
Опыт работы и трудовой деятельности:
•Опыта в коммерческой разработке приложений не имею
Знания и навыки:
• знания C#, .NET Framework;
• начальные знания Flex/Flash, ActionScript;
• понимание принципов ООП;
• профессиональный пользователь ПК;
• проектирование информационных систем, реляционных баз данных;
• техническое знания Английского языка;
Личностные качества:
Умение качественно работать. Добросовестность в работе. Трудолюбие.
Заинтересован совершенствоваться и осваивать новые технологии и средства разработки.
Пожелания:
•гибкий график работы.
Рассчитаем степень истинности подусловия для первого правила, для первого подусловия.
Х1 = 0;
Для первого терма опыт работы = начальный.
В11 = 0, т.к. x <=а
Аналогично, для остальных термов: В12 = 0, В13 = 0, В14 = 0, В15 = 0.
Bi – степень истинности для всего подусловия.
В1 = max(Вij) = 0;
M’(y) = average(Bi), для проверки всех требований больше подходит.
M’(y) = 0/1 = 0;
Ci – степень активации для всего подусловия c учётом веса правила.
C1 = M’(y) * F1, где F1 – вес правила.
C1 = 0*0,3 = 0;
Wi – степень истинности подзаключений.
W1 = Е1* B1, где Е1 – весовой коэффициент в базе правил.
W1 = 0,2*0 = 0 – степень истинности подзаключений по 1-му правилу.
Аналогично, просчитываем степень истинности подзаключений (Wi) и степень активации (Ci), получим:
В1 = max(Вij) = 1; В2 = max(Вij) = 1;
M’(y) = average(Bi), для проверки всех требований больше подходит.
M’(y) = 2/2 = 1;
C2 = M’(y) * F2, где F2 – вес правила.
C2 = 1*0,6 = 0,6;
W2 = Е1* B1 + Е2* B2, где Еi – весовые коэффициент в базе правил.
W2 = 0,8*1 + 0,8*1=1,6– степень истинности подзаключений по 2-му правилу.
Для 3-его правила:
Bi – степень истинности для всего подусловия.
В1 = max(Вij) = 1;
M’(y) = average(Bi), для проверки всех требований больше подходит.
M’(y) = 1/1 = 1;
Ci – степень активации для всего подусловия c учётом веса правила.
C3 = M’(y) * F3, где F3 – вес правила.
C3 = 1*0,9 = 0,9;
Wi – степень истинности подзаключений.
W3 = Е1* B1, где Е1 – весовой коэффициент в базе правил.
W3 = 0,9*1 = 0,9 – степень истинности подзаключений по 3-му правилу.
Для 4-ого правила:
Bi – степень истинности для всего подусловия.
В1 – степень истинности WPF, которую определяем согласно данным из дерева решений.
В2 – степень истинности WCF, которую определяем согласно данным из дерева решений.
В1 = max(Вij) = 0,5;
В2 = max(Вij) = 0,5;
M’(y) = average(Bi), для проверки всех требований больше подходит.
M’(y) = (0,5+0,5)/2 = 0,5;
Ci – степень активации для всего подусловия c учётом веса правила.
C4 = M’(y) * F4, где F4 – вес правила.
C4 = 0,5*1 = 0,5;
Wi – степень истинности подзаключений.
W4 = Е1* B1+ Е2* B2, где Е1, Е2 – весовые коэффициенты в базе правил.
W4 = 1*0,5 + 1*0,5 = 1 – степень истинности подзаключений по 4-му правилу.
При помощи формулы центра тяжести для одноточечных множеств получим:
y= sum(Ci *Wi)/ sum(Ci);
y= (0*0+0,6*1,6 + 0,9*0,9+0,5*1)/(0+0,6+0,9+0,5) =1,135 – степень соответствия Анкеты №2 Вакансии №1.
Вывод:1.135>0.162, следовательно, кандидат с анкетой №2 больше соответствует вакансии №1, чем кандидат с анкетой №1.
На основании составленной базы правил можно сформировать рейтинг претендентов, с помощью методов нечёткого вывода. Для улучшения качества работы системы планируется добавление специальных параметров, в соответствии с вакантной должностью.
Выводы
Качественный анализ данных возможен при наличии полной информации в анкетных данных кандидатов. Таким образом, процесс оценки соответствия уровня подготовки претендентов требованиям работодателя целесообразно проводить с использованием интеллектуальной системы, работа которой позволит получить объективную оценку соответствия уровня подготовки претендентов требованиям работодателя.
В данной работе описана задача формирования списка кандидатов для предварительного отбора кандидатов с использованием нечеткой логики. Использование нечетких показателей позволит учесть все требования, предъявляемые работодателями, и отобрать лучших кандидатов на собеседование.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2013 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Гиль М.В., Фонотов А.М., Разработка системы предварительного отбора кандидатов на собеседование на основе методов интеллектуального анализа данных, научно-технический журнал ВАК Украины «Искусственный интеллект» № 2 – 2013, с. 24-34.
- Кретов В.С., Коробицын И.М., Компьютерный метод отбора персонала фирмы // Науковедение интернет-журнал [Электронный ресурс]. – Режим доступа:http://naukovedenie.ru/index.php?id=160.
- Кретов В.С., Лебедев И.С., Новый метод автоматической классификации террористических актов // Научно-техническая информация. 2006. №5. с. 14-16.
- SAP Business Management Software Solutions, Applications and Services [Електронный ресурс]. – Режим доступа: http://www.sap.com/.
- Азарнова Т.В., Терновых И.Н., Применение нейросетей в процессе подбора персонала, Вестник ВГУ, серия: системный анализ и информационные технологии. 2009. № 2. с. 76-80.
- Qasem A. Al-Radaideh, Eman Al Nagi, Using Data Mining Techniques to Build a Classification Model for Predicting Employees Performance, (IJACSA) International Journal of Advanced Computer Science and Applications, № 3, № 2, 2012, с. 144-151.
- Faliagka E. et. al., Taxonomy Development and Its Impact on a Self-learning e-Recruitment System, International Federation for Information Processing, 2012 pp. 164-174.
- Андрейчиков А.В. Анализ, синтез, планирование решений в экономике. / А.В. Андрейчиков, О.Н. Андрейчикова. — М.: Финансы и статистика, 2000. — 203 с.
- F. Herrera, E. Lopez, C. Mendana and M.A., Rodriguez, A linguistic decision model for personnel management solved with a linguistic biobjective genetic algorithm, Fuzzy Sets and Systems, 2001, № 118, Issue 1, pp. 47-64.
- Gil M. V., Fonotov A. M, Data mining as part of the information technologies market of the human resources, Information control systems and computer monitoring (ICS and CM) // Materials III National Conference of Students and Young Scientists. - Donetsk, Donetsk National Technical University – 2012, рр. 157-160.
- Гиль М.В., Фонотов А.М., Методика отбора персонала на вакансию на основе нечетких показателей, Информационные управляющие системы и компьютерный мониторинг (ИУС-2013) / Материалы IV международной научно-технической конференции студентов, аспирантов и молодых ученых. — Донецк, ДонНТУ — 2013, Том 2, с. 67-71.