
Abstract
Содержание
- Introduction
- 1. Theme urgency
- 2. Goal and tasks of the research
- 3. Implementing ray tracing on a different architecture
- Conclusion
- References
Introduction
Three-dimensional graphics – the area of knowledge, which has received endless possibilities due to the continuous development of information technology, improving the hardware of electronic computing systems, productivity growth of computer technology.
1. Theme urgency
The actual problem of computer graphics is realistic images that are active in demand in the industry, game industry and film. Photorealistic image is characterized by effects like soft shadows, penumbra, caustic, motion blur, depth of field, blurred reflections, shine, translucency. Among the existing approaches photorealistic rendering ray tracing methods are the most accurate because they are based on a physical model of light propagation.
There is a rich variety of different methods of ray tracing, so it becomes necessary to sample the most effective methods of exact ray tracing, which will mean raising work correctly for a wide range of displayable dynamic and static scenes.
2. Goal and tasks of the research
The aim of of research is to analyze the existing methods of photorealistic rendering, improving their efficiency, as well as methods for mapping techniques at the architecture parallel computer systems.
Main tasks of the research:
- An analysis of existing methods of ray tracing, thus pick out the methods that make it possible to obtain high-quality realistic image.
- The development of modified methods for ray tracing.
- Display methods for parallel architecture computer systems, in particular using GPGPU resources – CUDA.
Research object: photorealistic rendering.
Research subject: modification of the exact-unbiased methods to reduce the time taken to render a single frame, and display them on the architecture of the GPU.
3. Implementing ray tracing on a different architecture
Over the years, ray tracing in real time is the main goal of computer graphics. Ray tracing in real time showed some small scenes on the basis of the principle of CPU computing SIMD, as well as large scenes on a shared-memory multiprocessor, and cluster. At the moment, already available with special chips to accelerate ray tracing in real time. In this study the implementation of ray tracing on a different architecture is expensive.
An alternative approach to the implementation of ray tracing in a real-time use of GPU. Graphics hardware has evolved from the Graphics Rendering Pipeline (pipeline, the steps of which passes card for building the final image) is optimized for the rendering of triangles with texture maps to the GRP with programmable vertex and fragmented stages.
Pipeline for GPU consists of the following stages: application, vertex program, rasterization, fragmented program, display. Since graphics processors began to include a complete set of commands and more types of data, it can be classified as a macro processor. In order, to transfer all of the calculations on the GPU, it was proposed to consider the architecture of the GPU as a stream processor. Streaming calculation differ from traditional that the system reads the data required for calculating the flow elements. Each element of the stream – a record of data, which requires similar computations. The flow model is effective in implementation, because it allows you to use parallelism to improve throughput, hide memory latency.
Displaying ray tracing on the threading model (Fig. 1) [1]. Initially, it is assumed that the geometry of the scene represented by triangles are stored in the database of the accelerating structures. Streaming ray tracer is divided into four core: produces a stream of visible light. Every visible beam – generating rays from the camera grid intersections, crossing the beam and the triangle shading. Ray generator from the chamber is a separate beam corresponding to the image pixel. The kernel reads the stream crossings ray beams produced by the generator. This core sequence directs the rays through the screen, while the beam does not face a voxel containing triangles. The following core intersection is responsible for testing the intersection of the beam with all the triangles inside the voxel. The kernel calculates the shading color, generates secondary rays or shadow rays.
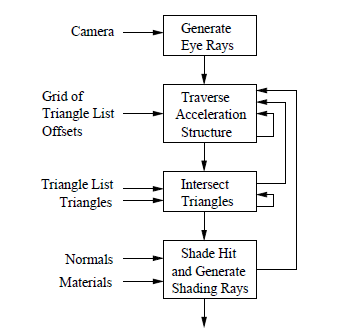
Figure 1: Raytracer Streaming model
Application: Quick approximating method to find the point of intersection of the reflected or refracted ray. Calculations are based on distance values, stored in the environment map texels. The approximation is used to locate the reflection and refraction, presented maps of the environment to make them independent of where they come across. On the other hand, placing a virtual light source to the eye, this method works well for generating the caustic in real time. This method is suitable for scenes consisting of large flat faces. The method described in [2] for GPU architecture, and is used in the gaming industry.
In the paper [3] consider a system Razor, which supports dynamic scenes with high-quality effects (soft shadows, unfocused blur). This system is executed on a programmable multi-core architecture and is intended to trace rays in real time. The system tracing Razor, uses multi-threading with one main thread and the worker threads per core CPU. Primary rays are organized in 2D-blocks, which are placed in the work queue and are displayed on the workflows. As shown in Fig. 2 Razor supports visibility with a special structure of the kd-tree constructed for each frame, and uses the so-called "coarse-grain" parallelism, using domain decomposition of frames into cells. Furthermore, it uses parallelism with simultaneous packet tracing emission of a plurality of rays as shown in Figure 6. Calculations of material separated from the shading calculations intersections, since they are essentially different. Figure 3 shows the organization of multi-core hardware.
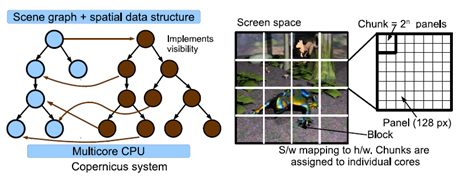
Figure 2: Multocore system review
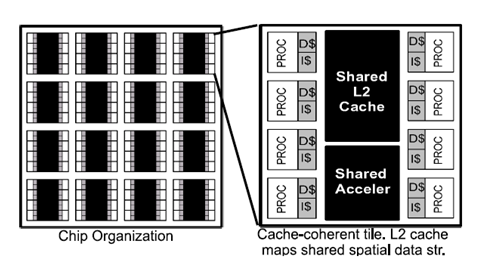
Figure 3: Hardware multicore system
Hardware architecture – is a large-scaled multi-core processor with a private second-level cache, multithreading to hide the latency of memory access, and limited cache coherency. Such organization enables easy scalability to thousands of cores. Studies have shown 8-core tile can be fully utilized by 100% and support 10 million rays/s. Such tiles 16 can fit on a chip (240mm2, Technology 22 nm), and thus no problems to realize tracing rays in real time.
With the advent of technology CUDA NVIDIA and AMD Stream has started the revision of the concept of ray tracing on the GPU. In the paper [4] describes the implementation of ray tracing on the GPU with support for shadows, reflections, refractions, transparency and texture of objects. Graphics platform – OpenGL, Shading Language – GLSL (providing cross-platform). The features of this implementation are: the representation of all the scenes in the form of triangles, the use of a regular grid with the "cloud proximity" as the accelerating structure, improved algorithms for crossing the "ray-primitive." Necessary to calculate the data is transferred textures and special global variables. Each texel in the texture of an offset texture vertices of the triangles and by other special global variables stored data of the camera and light sources.
The paper [5] discusses options for implementing a recursive ray tracing on CUDA. When the rays strike the scene, their ultimate goal is – Returns the pixel color and the color value of a pixel is not determined by the value of the neighboring pixel color. Because the smallest independent element in ray tracing is – pixel, then built on it the whole concurrency calculations. On CUDA attached to each pixel a separate thread GPU. This flow produces all calculations lighting, shading, object intersection test/beam for all objects. In essence, this means that each thread has access to the complete characterization of the scene.
Since ray tracing is a resource-intensive process that constantly arises the problem of its acceleration on the GPU. To solve this problem, a structure such accelerators as recursive partitioning spatial structure (kd, BVH trees). As the experience of the implementation of ray tracing on the GPU, this technology has some drawbacks. These include the lack of stack, insufficient number of registers GPU, immeasurable speed of an algorithm. The article [6] these shortcomings offset by the high degree of parallelism, the division algorithm for multiple cores and multiple switch. Given the shortcomings in the work of the CUDA technology [6], the task of tracing decomposed into three sub-tasks: the search for a kd-tree, counting intersections shading. With this approach it was possible to measure the velocity of parts of the algorithm, all of the programs are independent of each other, the core may be any shading complexity that do not affect the system performance. Some algorithmic aspects of the photon maps make it difficult to implement on the GPU, which affects the system performance. The solution was to – grouping of photons, each of which photons slightly diverge from each other. For the next phase, collecting light is used a fixed radius sample collection and evaluation of light photons, which fall within a predetermined range, which saves resources GPU. For more details about the problem storing photons on GPU (CUDA) in the multi-pass algorithm and its resolution in the [6, p.6].
Alternative approach to accelerate ray tracing on the GPU is described in [7], where the proposed grading of the photon map (in order to get caustic effect) so as to reduce the access time to the nearest photons in the collision point. It uses a spatial hash function and bitonicheskaya sorting.
In [26] NVIDIA OptiX engine is presented for ray tracing, designed for graphics processors NVIDIA. This engine was developed on the basis of one important observation that the majority of the ray tracing algorithms may be implemented using a small set of programmable operations. The core of OptiX engine is a dynamic object-oriented compiler that generates custom ray tracing kernels by combining user-defined program to generate rays, shading, intersections with objects, etc. This engine offers high performance at the expense of accurate object model, as well as its flexibility, which allows you to customize and adapt the engine to specific tasks, support for recursion. Data that is collected and fully customizable beam, which simplifies the calculations for a single beam per unit time. A programmable graphics pipeline OptiX is shown in Figure 4 [8, p.3, figure 2].
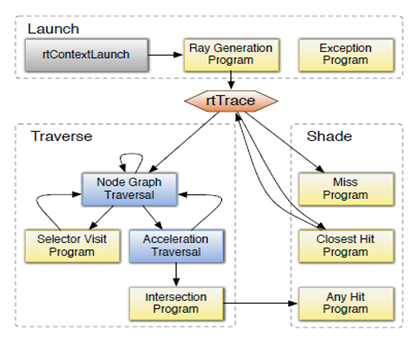
Figure 4: OptiX pipeline
The scene is stored and processed as a graph in [26, p.3, figure 2] is an example of a graph partitioning certain areas (Fig. 5).
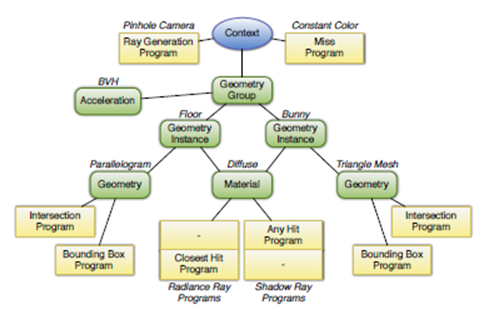
Figure 5: Scene graph
Flow control is the main application OptiX [26, p.6, figure 5] (Fig. 6).
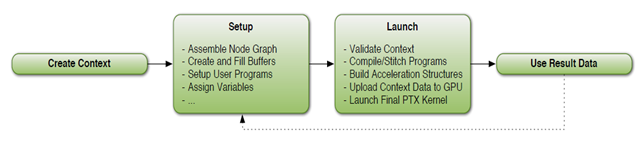
Figure 6: Control thread application
OptiX also supports graphics API (OpenGL). OptiX functions: parallelism within a GPU, between the GPU and the CPU, the use of kd, BVH trees and other work-arounds algorithms use control power GPU with the integrated load balancing.
As a result, consideration of a variety of ray tracing techniques for further comparative analysis will be featured only accurate methods of ray tracing, which gives the output quality photorealistic image. These methods include bi-directional path tracing, photon mapping method, the distributed ray tracing, MLT.
In [9] proposed the implementation methods of tracing paths, bidirectional path tracing and MLT on GPU (CUDA), in order to show that GPU computing is much better than CPU. The experimental data were obtained on the instrument Intel CoreTMi7 CPU 920 and NVIDIA GeForce GTX 480 (Fig. 7).
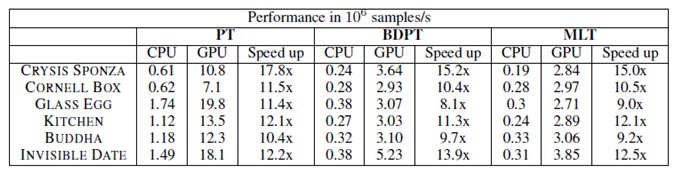
Figure 7: Perfomance comparison between CPU and GPU
Conclusion
After analyzing the methods of ray tracing, select group of methods by high quality and accuracy of the output image. Contact Ray Tracing balance between quality and speed, and since this method is the basis for many others, it will not be classified in the category of photo-realistic techniques. Distributed ray tracing has a wide number of advantages in terms of photo-realistic effects, so we select it in the group of exact methods. Ray tracing is based on the Monte-Carlo ray tracing and direct form the basis of multi-pass techniques. Bi-directional path tracing, Metropolis Light Transport and the method of photon mapping is maintained by the filter accuracy and high quality. Volumetric ray-tracing method is not suitable for the selected criteria. Thus, by using photorealistic rendering techniques include: distributed ray tracing, photon mapping method, bi-directional path tracing and Metropolis Light Transport.
Master's work is devoted to the actual scientific problem of synthesis of photo-realistic images. As part of the research carried out:
- The analysis of existing methods of ray tracing.
- Selected accurate photorealistic rendering techniques.
- The features of the display of selected methods for architecture GPU.
Further studies focused on the following aspects:
- Implementation of software implementation methods for CUDA.
- Getting experimental characteristics of speed and quality.
- Optimization techniques to reduce the time scene rendering.
This master's work is not completed yet. Final completion: December 2013. The full text of the work and materials on the topic can be obtained from the author or his head after this date.
References
- Purcell T. J. et al. Ray tracing on programmable graphics hardware //ACM Transactions on Graphics (TOG). – 2002. – Т. 21. – №. 3. – С. 703-712.
- Szirmay Kalos L. et al. Approximate Ray Tracing on the GPU with Distance Impostors //Computer Graphics Forum. – Blackwell Publishing, Inc, 2005. – Т. 24. – №. 3. – С. 695-704.
- Govindaraju V. et al. Toward a multicore architecture for real-time ray-tracing //Proceedings of the 41st annual IEEE/ACM International Symposium on Microarchitecture. – IEEE Computer Society, 2008. – С. 176-187.
- Боголепов Д.К., Турлапов В.Е. –
Интерактивная трассировка лучей на графическом процессоре
. Труды международной научной конференции по Компьютерной Графике и ЗрениюГрафиКон 2009
- 2009. - С. 263–266. - Britton A. D. Full CUDA Implementation Of GPGPU Recursive Ray-Tracing. – 2010.
- Фролов В., Игнатенко А. Интерактивная трассировка лучей на графическом процессоре с применением технологии CUDA //
GraphiCon 2008
. – 2008. – С. 311-312. - Ульянов Д.Я. Об одной реализации метода фотонных карт для визуализации каустик // Труды международной научной конференции
Графикон 2010
. -2010. - С. 328-359. - Parker S. G. et al. Optix: a general purpose ray tracing engine //ACM Transactions on Graphics (TOG). – 2010. – Т. 29. – №. 4. – С. 66.
- van Antwerpen D. Improving SIMD efficiency for parallel Monte Carlo light transport on the GPU //Proceedings of the ACM SIGGRAPH Symposium on High Performance Graphics. – ACM, 2011. – С. 41-50.