Інтелектуальні методи отримання інформації з текстів, написаних природньою мовою
Автори: Кулаков В.В., Мельник О.В., Коломойцева І.О.Джерело: Інформаційні управляючі системи та комп'ютерний моніторинг(ІУС та КМ- 2012) / Матерiали III мiжнародної науково - технiчної конференцiї студентiв, аспiрантiв та молодих вчених. - Донецьк, ДонНТУ - 2012, електронна збірка.
Загальна постановка проблеми
Завдання аналізу текстових документів орієнтоване на отримання знань і є нині актуальною проблемою, що зачіпає різні сфери людської діяльності, оскільки її рішення дозволить повністю автоматизувати процес обробки, класифікації і систематизації інформаційного ресурсу. Бурхливе зростання об'єму текстів, в яких ведеться пошук, призвело до того, що ті статистичні методи, які зробили можливим швидкий і ефективний пошук по великих масивах неструктурованих даних, стали "заважати" ефективності цього пошуку. Переваги цих методів - відсутність необхідності детального семантичного опису предметної області і змістовного аналізу текстів, породило і його обмеженість. Останнім часом на перший план виходить завдання попередньої "когнітивної обробки" текстів. З одного боку, боротьба з "надлишком" видаваної користувачеві інформації вилилася в те, що сучасні системи аналізу текстів від завдання інформаційного пошуку : знайти документ із заданої тематики, переходять до завдання отримання інформації з текстів (informationextraction) і глибшого аналізу отриманої інформації - отримання знань (datamining). В результаті користувач по своєму запиту отримує не "мішок" текстів, а деякі "підсумкові" дані, що є певним чином структуровані. Якщо приписати тексту деякі "семантичні" мітки, це дозволить частково зменшити кількість "шуму" - текстів не з тієї галузі знань, яка цікавить користувача, і допоможе розв'язати проблему омонімії. Таким чином, на перший план висувається завдання розробки спеціальних мов і систем, що описують понятійну структуру тієї чи іншої галузі знань, - тезаурусів і онтологий. Призначення цієї роботи : отримання фактів (в даному випадку - характеристик об'єктів пошуку); збирання думок (opinionmining/extraction, аналіз коментарів і відгуків користувачів про досліджувані продукти з метою виявлення їх основних переваг та недоліків). Метою дослідницької роботи є дослідження методів автоматичного аналізу текстових документів на природній мові і розробка системи для отримання основних характеристик і формування наближених висновків що до аналізованих об'єктів.Аналіз існуючих рішень
На даний момент проблема отримання фактів з природних текстів залишається відкритою, тому існує мала кількість готових продуктів, що вирішують цю проблему. Багато хто з них є комерційними проектами, але є і вільно розповсюджувані продукти. Мабуть, найвідомішим рішенням є продукт фірми Айтеко "Аналітичний кур'єр". "Аналітичний Кур'єр" є інструментом аналітичної розвідки, який дозволяє швидко занурюватися в нові предметні області. Унікальною особливістю системи є спільне застосування різних методів отримання знань в одному сценарії, наприклад, спочатку робиться кластерний аналіз групи повідомлень, потім будується семантична мережа тематик для вибраного кластера, після чого здійснюється частотний аналіз тимчасового ряду повідомлень по взаємопов'язаних проблемах та ін. У системі реалізовані унікальні за якістю методи аналізу думок і визначення тональності публікацій. До переваг системи належать висока міра автоматизації і адаптивності методів отримання знань, а також мінімальна вартість її експлуатації в порівнянні з аналогами. Ця система має широкі можливості, але є комерційним проектом і досить таки складна для роботи з конкретними предметними галузями. Також існує комерційний продукт RCO FactExtractorDesktop - це програмне рішення для Windows, яке призначене для аналітичної обробки тексту російською мовою і виявлення фактів різного типу, пов'язаних із заданими об'єктами - персонами і організаціями. Основна сфера застосування програми - це завдання з області комп'ютерної розвідки, що вимагають високоточного пошуку інформації, наприклад, автоматичний підбір матеріалу до досьє на цільовий об'єкт або ж моніторинг певних сторін його активності, що освітлюються в ЗМІ.[3] Окрім додатка FactExtractorDesktop компанія також пропонує бібліотеку FactExtractorSDK, яка повинна надавати можливість вбудовувати функціонал з аналізу текстів в інші додатки. Звісно, бібліотека також розповсюджується на комерційній основі. Наступною відомою системою для аналізу тексту є проект АОТ(www.aot.ru). Цей проект є безкоштовним(розповсюджується під ліцензією LGPL). Кожен з бажаючих може безкоштовно використати бібліотеки у своїх програмах у тому числі і в комерційних застосуваннях. Їх технології базуються на багаторівневому представленні природної мови яке, у свою чергу, було запозичено у системи ФРАП. Компоненти, що становлять мовну модель, - лінгвістичні процесори, які один за одним обробляють вхідний текст. Вхід одного процесора є виходом іншого.Виділяють наступні компоненти:
- Графематический аналіз. Виділення слів, цифрових комплексів, формул та ін.
- Морфологічний аналіз. Побудова морфологічної інтерпретації слів вхідного тексту.
- Синтаксичний аналіз. Побудова дерева залежностей усього речення.
- Семантичний аналіз. Побудова семантичного графа тексту.
Спочатку, розглядалася можливість використання бібліотеки АОТ (словники, а також управління словниками) у системі, що розробляється проте з деяких об'єктивних причин (головна з яких - зайва стратифікація, ізоляція текстів від даних, які ними передаються) це рішення було злічене недоцільним вирішуваній задачі.
Особливості системи
Була спроектована система автоматизованого витягання фактів з природних текстів на основі інтелектуальних методів аналізу. Розроблена, в ході цієї роботи, система складається з наступних основних частин(мал. 1) :- менеджер потоку
- html-парсер;
- інтелектуальний аналізатор;
- база об'єктів;
- база словників;
- модуль управління словниками;
- модуль управління базою об'єктів;
- модуль навчання;
- клієнтський модуль.
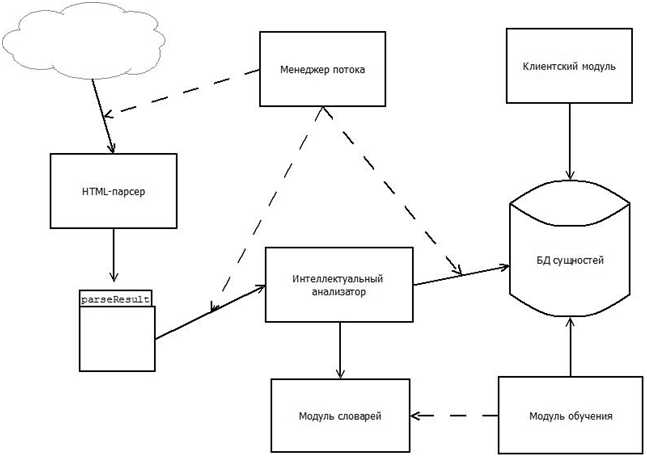
Мал. 1. Схема системи автоматичного витягання інформації
Менеджер потоку займається вибором web- сторінок з мережі інтернет, перенаправленням витягнутих даних html- парсеру, а також передачею результатів роботи html- парсера інтелектуальному аналізатору.
Html- парсер приводить текст до необхідного для аналізу виду, а також витягає базові характеристики об'єкту пошуку.
Інтелектуальний аналізатор обробляє відгуки про об'єкт пошуку, а також додає дані до бази об'єктів.
База об'єктів зберігає інформацію про об'єкти і зв'язки між ними також у базі містяться шаблони представлення об'єктів.
Модуль словників (мал. 2) передбачає роботу з базою словників.

Мал. 2 - Модуль словників
База словників є базою слів, об'єднаних тезаурусами (морфологічні, синонімічні, антонімічні зв'язки та омонімія).
Модуль управління словниками являє собою інтерфейс управління базою даних словників, що дозволяє взаємодіяти з інтелектуальним аналізатором і базою об'єктів.
Модуль навчання має інтерфейс для ручного редагування інформації а також припускає можливість автоматичного навчання. Проміжним варіантом роботи модуля навчання є такий процес при якому за даними, які не зміг обробити аналізатор, складається "список питань" для адміністратора системи.
Клієнтський модуль призначений для того, щоб забезпечити користувачеві можливість максимально ефективно використати інформацію, накопичену під час роботи системи (мал. 3), містить елементи управління, за допомогою яких користувач системи може вказати необхідні параметри пошука.
Також передбачені модулі GUI для роботи адміністратора системи, які надають інтерфейси для управління процесом збору даних, управління словниками системи, управління процесом навчання, як в ручному так і в автоматичному режимах.
Предметною галузею нашого дослідження є комп'ютерне устаткування.
Користувач цієї системи вводить назву об'єкту, що його цікавить, і система
надає йому основні характеристики цього продукту, а також інформацію
грунтовану на аналізі відгуків про цей продукт. Початкові дані беруться з
сторінок мережі Internet, що містять як інформацію про продукт, надану
виробником, так і відгуки користувачів. Аналіз відгуків може дати досить
реальну оцінку для продукту, а можливість використати велику кількість
відгуків для кожного об'єкту може допомогти компенсувати зашумленность
результатів.

Мал. 3 - Інтерфейс клієнтського модуля
Висновки
Проблема автоматичного аналізу текстів на даний момент є дуже перспективною. Система, що розробляється нами, покликана допомогти кінцевому користувачеві отримати найбільш достовірні знання про об'єкт пошуку.На даний момент (2012р.) реалізовано:
- базовий функціонал для модуля словників і модуля навчання;
- розроблена масштабована система первинного розбору даних з html-розміткою;
- створена базова версія інтелектуального аналізатора.
- вдосконалити алгоритми роботи аналізатора із метою підвищення універсальності системи, що розробляється;
- розширити можливості модуля словників;
- вдосконалити модуль навчання для поліпшення його роботи в автоматичному режимі.
- розширювати набір html-парсеров для взаємодії з різними ресурсами.
Література
- Автоматическая Обработка Текста [Electronicresourse] / Интернет-ресурс. - Режимдоступа :www/ URL: http://www.i-teco.ru/ac.html. - Загл. сэкрана.
- Айтекотехнологиибезпробелов [Electronicresourse] / Интернет-ресурс. - Режимдоступа :www/ URL: http://aot.ru/technology.html. - Загл. сэкрана.
- RCO FactExtractorDesktop [Electronicresourse] / Интернет-ресурс. - Режимдоступа :www/ URL: http://www.rco.ru/product.asp?ob_no=1131. - Загл. сэкрана.