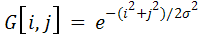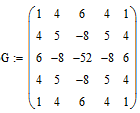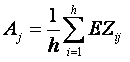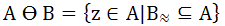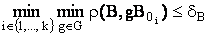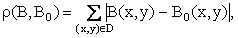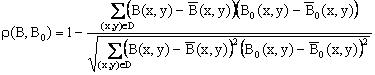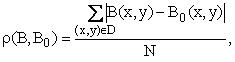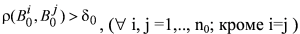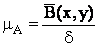Аннотация
Личканенко И.С., Пчелкин В.Н. Методы обработки изображений и распознавания образов для задачи обнаружения номерных знаков транспортных средств. Рассмотрены задачи, возникающие в процессе распознавания номерных знаков транспортных средств. Определены методы обработки изображений и распознавания для выявления номерных знаков.
Ключевые слова: методы обработки изображений, распознавание номерных знаков.
Постановка проблемы
Сегодня важным аспектом безопасности дорожного движения и контроля является идентификация автомобилей по их регистрационному номерному знаку. Системы распознавания номерных знаков имеют различные сферы применения, такие как автотранспортные предприятия, контроль въезда на территорию предприятия, заправочные станции, контроль скорости движения, автомобильные стоянки.
В настоящее время существует достаточно большое количество систем определения номерных знаков, но не все из них являются качественной и надежной продукцией. Системы с высоким быстродействием и точностью распознавания являются коммерческими, засекреченными и дорогими, что не позволяет осуществить их массовое внедрение.
Для реализации задачи распознавания номерных знаков нужно выполнить три этапа: предварительная обработка изображения, сегментация, распознавание символов.
Предварительная обработка изображения заключается в локализации номерной пластины и обработке данного изображения различными фильтрами для улучшения качества. Этап сегментации – выделение символов для дальнейшего распознавания выбранным методом.
Цель статьи – рассмотрение и анализ методов обработки изображений и распознавания номерных знаков транспортных средств.
Методы обработки изображений при локализации номерного знака
Входные изображения Bi с камеры чаще всего зашумленные, размытые, поэтому проводится предварительная обработка их сглаживающими и ранговыми фильтрами (гауссовский и медианный фильтры) F(Bi) для устранения аддитивного и импульсного шума. При фильтрации яркость (сигнал) каждой точки исходного изображения, искаженного помехой, заменяется некоторым другим значением яркости, которое считается имеющим наименьшую степень искажения [1].
Сглаживающие и ранговые фильтры
В обработке изображений используется двумерная дискретная функция Гаусса с нулевым средним:
Фильтр, построенный на ее основе, служит для сглаживания. При этом выполняются манипуляции с параметром σ² (установленное значение дисперсии обычно намного больше вычисленного, что приводит к более эффективному шумоподавлению, но и увеличивает степень размывания изображения).
При медианной фильтрации используется двумерное окно (маска фильтра), имеющее центральную симметрию. Центр окна располагается в текущей точке фильтрации. Форма окна может быть различна. Размеры апертуры оптимизируются в процессе анализа обработки, зависят от детальности изображения. Отсчеты, оказавшиеся в пределах окна, называются рабочей выборкой текущего шага.
Значения элементов рабочей выборки упорядочиваются по возрастанию. Выбирается элемент, занимающий центральное положение в этой последовательности – медиана. Если центральное значение является шумовым выбросом, то фильтр обеспечит его подавление.
Для выполнения последующих этапов необходимо выполнить выделение на изображении границ объектов – непрерывных кривых, в которых наблюдается резкий скачок яркости.
Обнаружение границ (контуров)
Выделение границ осуществляется при помощи градиентных фильтров первого и второго порядка. Применим, например, фильтр второго порядка – LoG-фильтр (Marr-Hildreth), который работает путем сверки изображения с лапласианом функции Гаусса. Он сочетает в себе обнаружение границ со сглаживанием. Используется маска фильтра G:
Результат работы фильтра LoG представлен на рис. 1.
а) б)
Рисунок 1 – а) исходное изображение, б) с выделенными границами
Сегментация номерного знака
Алгоритм сегментации производит поиск координат предполагаемых символов на локализованной зоне. На первом этапе сегментации вычисляются оценки правдоподобия принадлежности пикселей линиям символов, в простейшем случае используются либо готовые результаты наложения фильтра H, либо непосредственно яркость пикселей. Результатом первого этапа является массив оценок правдоподобия EZhxw.
Второй этап – вычисление вектора средней оценки правдоподобия по столбцам:
Вектор A позволяет обнаружить промежутки фона между символами, которые проявляются в виде экстремумов, если рассматривать A как функцию.
На третьем этапе производится обнаружение вертикальных разделителей – границ между символами. Для этого каждому элементу сопоставляется оценка правдоподобия Hi. Чем выше эта оценка, тем выше вероятность того, что в данном месте находится промежуток фона между символами. Индексы i выбранных Hi – это координаты вертикальных разделителей (границы) между символами:
Dev = {dev1,dev2,…,devk}, где k – количество найденных разделителей.
На четвертом этапе осуществляется уточнение вертикальных и горизонтальных границ символов. Для этого методом Отсу вычисляется пороговое значение яркости для фрагмента изображения между двумя разделителями. Порог позволяет бинаризовать фрагмент и в результате найти координаты выделенного на фрагменте объекта [2].
Для упрощения задачи распознавания символов номерного знака применяется морфологическая эрозия. Цель такой обработки – получение скелета символа (изображения шириной в 1 пиксель).
Эрозия бинарного изображения А структурирующим элементом В обозначается A θ B и задается выражением:
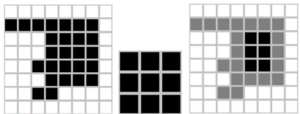
При выполнении операции эрозии структурный элемент проходит по всем пикселам изображения. Если в некоторой позиции каждый единичный пиксел структурного элемента совпадет с единичным пикселом бинарного изображения, то выполняется логическое сложение центрального пиксела элемента с соответствующим пикселом выходного изображения (см. рис. 2).
а) б)в)
Рисунок 2 – а) бинарное изображение A, б) структурный элемент B, в) утончение изображения A структурным элементом B²
В результате применения операции эрозии все объекты, меньшие, чем структурный элемент, стираются, а объекты, соединённые тонкими линиями становятся разъединенными, и размеры всех объектов уменьшаются. Если структурный элемент представляет собой единственный пиксель, то в результате получается тонкий остов объекта.
После предварительной обработки можно приступать к решению задачи распознавания.
Методы распознавания образов
Для реальных задач распознавания применяются, в основном, три подхода, использующие методы: корреляционные, основанные на принятии решений по критерию близости с эталонами; признаковые и синтаксические – наименее трудоемкие.
При полностью заданном эталоне многошаговая корреляция путем сканирования входного поля зрения является, по сути, полным перебором в пространстве сигналов. Поэтому эту процедуру можно считать базовой, потенциально наиболее помехоустойчивой, хотя и самой трудоемкой.
Наиболее помехоустойчивы при действии, как случайных помех, так и локальных помех, являются алгоритмы, основанные на методе частных корреляций. При этом частные коэффициенты корреляций, полученные для отдельных фрагментов эталона в сигнальном пространстве, могут рассматриваться как признаки. Обработка таких признаков, т.е. их свертка, зависит от типа изображений, присутствия значительных локальных помех и может быть осуществлена методами проверки статистических гипотез.
Распознавание изображений путем двумерной корреляции заключается в нахождении наиболее похожей пары изображений: эталон B0i – входное изображение B, i = 1,..,n0. Под максимальным сходством понимается определение минимального значения некоторой меры сходства ρ(B,B0i). Распознавание в условиях геометрических искажений осуществляется на основании следующего правила:
где G – группа предполагаемых искажений (например, группа смещений); dВ – пороговая величина, введение которой объясняется наличием на входном изображении помех.
Меры сходства между изображениями могут определяться по одной из следующих формул:
где B(x,y) и B0(x,y) – средние значения яркостей изображений B и B0 соответственно; N – количество точек области D.
В качестве эталонных изображений предлагается рассматривать сегментированные полутоновые изображения, отцентрированные по центру тяжести.
Эталонные изображения должны соответствовать условию непохожести:
где n0 – количество эталонных изображений; d0 – пороговая величина.
Величина сигнал/шум определяется следующим образом:
где B(x,y) – средняя яркость изображения, d – среднеквадратическое отклонение гауссова шума (случайная помеха, распределенная по нормальному закону с нулевым математическим ожиданием и задаваемой величиной дисперсии).
Вероятность правильного распознавания при заданном уровне шума определяется путем многократного повторения экспериментов с данным уровнем шума для разных изображений путем деления количества правильных результатов на количество всех экспериментов.
Признаковые и синтаксические методы наиболее разработаны в теории распознавания образов. Они основаны как на статистических, так и детерминированных подходах. Главную трудность в признаковых методах составляет выбор признаков. При этом исходят из естественных правил: а) признаки изображений одного класса могут различаться лишь незначительно (за счет влияния помех); б) признаки изображений разных классов должны существенно различаться; в) набор признаков должен быть минимально возможным, т.к. от их количества зависит и надежность, и сложность обработки.
В первом приближении синтаксические методы можно отнести к признаковым, они основаны на получении структурно-лингвистических признаков, когда изображение дробится на части – непроизводные элементы (признаки). Вводятся правила соединения этих элементов, одинаковые для эталона и входного изображения. Анализ полученной таким образом грамматики обеспечивает принятие решений [3].
Все рассмотренные методы могут быть применены для решения задачи локализации номерной пластины, но наиболее эффективными являются корреляционные методы.
Распознавание символов
Задача непосредственного распознавания номера решается при помощи специфических методов, к которым, в частности, относятся методы классификаторов и нейронных сетей.
Существует три основных типа классификаторов: шаблонный, признаковый и структурный.
Шаблонные классификаторы преобразуют исходное изображение символа в набор точек и затем накладывают его на шаблоны, имеющиеся в базе системы. Шаблон, имеющий меньше всего отличий, и будет искомым. У этих систем достаточно высокая точность распознавания дефектных символов (склеенных или разорванных). Недостаток – невозможность распознать шрифт, хоть немного отличающийся от заложенного в систему (размером, наклоном или начертанием).
Признаковые классификаторы по каждому символу вычисляют набор чисел (признаков) и сравнивают эти наборы. Но так как набор признаков никогда полностью не соответствует объекту, то заведомо часть информации о символе будет теряться.
Структурные классификаторы хранят информацию о топологии символа. Структурные методы представляют объект как граф, узлами которого являются элементы входного объекта, а дугами – пространственные отношения между ними. Этот способ тоже имеет свои недостатки: трудности при распознавании дефектных символов [4].
При решении задачи распознавания символов активно используются типы нейронных сетей: многослойные нейронные сети, нейронные сети Хопфилда, нейронные сети Кохонена и др. Ключевым аспектом здесь является обучение нейронной сети, которое сводится к определению связей (синапсов) между нейронами и установлению силы этих связей (весовых коэффициентов). Алгоритмы обучения нейронной сети упрощенно сводятся к определению зависимости весового коэффициента связи двух нейронов от числа примеров, подтверждающих эту зависимость. Наиболее распространенным алгоритмом обучения нейронной сети является алгоритм обратного распространения ошибки.
Выводы
В статье рассмотрены основные методы обработки изображений и распознавания номерного знака транспортного средства.
Необходимыми для решения этой задачи являются шумоподавляющая фильтрация, обнаружение границ, скелетизация и сегментация, а наиболее подходящими методами распознавания – корреляционные, шаблонные методы и нейронные сети.
В дальнейшем планируется применение этих методов для распознавания автомобильных номеров и проверка их на эффективность.
Список использованной литературы
1. Грузман И.С., Киричук В.С. Цифровая обработка изображений в информационных системах: Учебное пособие. – Новосибисрк: Изд-во НГТУ, 2002. – 352 c.
2. Воскресенский Е.М., Царев В.А. Моделирование и адаптация систем распознавания текстовых меток на видеоизображениях. – Череповец: ИНЖЭКОН-Череповец. – 2009. – 154 с.
3. Е.П. Путятин. Нормализация и распознавание изображений/ Интернет-ресурс. – Режим доступа: www/ URL: http://sumschool.sumdu.edu.ua/is-02/rus/lectures/pytyatin/pytyatin.htm – Загл. с экрана.
4. Абраменко А. Компьютер читает/ Интернет-ресурс. Режим доступа: www/ URL: http://www.ocrai.narod.ru/fr.html – Загл. с экрана.