Сравнение LAM-MPI и MPICH интерфейсов передачи сообщений в кластерных вычислениях
Автор: Daniel Cleary
Перевод: Е.В. Лютый
Источник: http://www.jyi.org/issue/a-comparison-of-lam-mpi-and-mpich-messaging-calls-with-cluster-computing/
Аннотация
В этом эксперименте исследовано общее время, необходимое, чтобы осуществить предачу сообщений в параллельных программах в распределенной вычислительной среде. Эти сообщения определены в Message Passing Interface (MPI) стандарте, который представляет собой набор рекомендаций по проектированию коммуникационных запросов для параллельных программ. Существуют различные библиотеки на основе MPI стандарта, и это проект направлен на две широко используемых реализации: MPICH и LAM-MPI. Обе обеспечивают такие же основные методы и функции, но структуры их пакетов и алгоритмов отличаются настолько, что организационное время, время обработки и время обмена сообщениями программы может быть улучшено путем выбора одного пакета над другим. При адекватном предвидением сильных и слабых сторон MPI пакетов, программисты и администраторы могут лучше выбрать пакет в зависимости от их потребностей. Для обоих пакетов, экспериментально измерили время выполнения в кластерной среде для часто используемых, глобальных и точка-точка MPI методов коммуникации. При прямом сравнении, ни одна реализация полностью не доминирует в любой категории, но у обоих были явные преимущества в программировании. Эксперименты показали, что каждая реализация имеет значительные преимущества и области, в которых она обеспечивает быструю передачу данных. С одним исключением, сообщения LAM-MPI обладали меньшим времен выполнения и были заметно быстрее (в четыре раза), при использовании нескольких процессоров.
Введение
Суперкомпьютеры, кластеры Beowulf обладают заметным присутствием в мире современных высокопроизводительных вычислений и вычислений. Многие из ведущих пятисот суперкомпьютеров в мире, которые не построены из стандартных аппаратных средств, основаны на парадигме распределённой модели. Распределенный суперкомпьютер объединяет вычислительные мощности многих небольших компьютеров, в виде выделенных вычислительных узлов или даже настольных машин, в одной вычислительной машине. Среди супер-ЭВМ использующих парадигму распределённой модели находятся Симулятор Земли, японский суперкомпьютер, который превзошел все другие суперкомпьютеры с пиковой теоретической производительностью 40 терафлопс (40 000 миллиардов операций с плавающей точкой в секунду). Многие кластерные суперкомпьютеры используют варианты операционной системы Linux с открытым исходным кодом, а также с Linux поставляется множество инструментов с открытым кодом, которые облегчают взаимодействия между узлами в параллельных программах. Многие пакеты коммуникации параллельных вычислений основаны на Message Passing Interface (MPI) стандарте и находятся в свободном доступе для большинства современных компьютерных архитектур и операционных систем. Пакеты, которые реализуют MPI стандарт облегчают взаимодействие между процессами и, таким образом, являются процессорно независимыми; это различие позволяет параллельным программам использующим MPI запускаться подобным образом на многих различных системах, в том числе одно-и двухпроцессорных машинах и гетерогенных кластерах. Для наиболее часто используемых реализаций MPI, в предыдущей работе были измерены различия в производительности по сравнению с сетевыми возможностями (Ong et al., 2000; Thakur and Gropp, 2003; Benson et al., 2003; Van Voorst and Siedel, 2000). Ong и Farrell (2000) сравнивали три MPI реализации (MPICH, LAM-MPI, MVICH) и сосредоточились на том, как сетевые переменные влияют на время передачи сообщений. Они показали, от настройки сети сильно зависит время выполнения, но и обнаружили, что каждый пакет имел явные преимущества производительности. Этот эксперимент следует в том же направлении. Целью было оценить возможности двух пакетов, MPICH и LAM-MPI, и показать, как различия во времени выполнения и реализации могут сделать один пакет быстрее или лучше, чем другие (Protopopov and Skjellum 2001).
Основной целью эксперимента было спроектировать и испытать параллельный Fortran90 код с двумя реализациями MPI на однородном кластере с пятью узлами на Pentium-Pro процессорах. Для 32-битной Intel x86 архитектуры, MPICH и LAM-MPI два свободно доступных и часто используемых пакета на основе MPI (Foster et al., 1997; Squyres and Lumsdaine, 2001; Swann 2001). Оба являются пакетами с открытым исходным кодом, которые включают набор библиотек на основе MPI стандарта, скрипты для установки и запуска, и предварительно скомпилированные программы, которые облегчают программирование на MPI. MPICH в значительной степени развивается и поддерживается Аргоннской национальной лабораторией. Пакет является очень гибким и простым в использовании: MPICH исходный код и скомпилированные пакеты доступны для широкого диапазона архитектур и операционных систем, включая версии для Microsoft Windows, основанной на ядре NT. MPICH также поддерживает большую часть новейшей версии MPI стандарта (MPI-2). Самый последний релиз версии LAM (Local Area Multiprocessor) MPI также поддерживает MPI-2 стандарт, который несколько лучше поддерживается и имел больше времени на разработку. LAM-MPI доступен в виде исходного кода и в скомпилированных пакетах для различных систем; он поддерживает операционные системы основанные нп Apple OS-X и предоставляет совместимость с операционными системами Microsoft Windows.
Программный интерфейс между двумя пакетами незначительно отличается, но основные алгоритмы двух библиотек MPI делают их очень разными. Этот проект сравнивает различие во времени между MPICH и LAM-MPI для передачи тех же сообщений и определяет какой пакет выполняется лучше, чем другой.Выбор аппаратного и программного обеспечения для кластера влияет на время выполнения программы, но факторы помимо сырого времени вычислений могут повлиять на продолжительность времени, необходимого для проведения вычислительного эксперимента (Farrell и Ong, 2003).
Методы и материалы
Проект состоял из трех основных очагов: физическое построение кластера Beowulf, настройка программного обеспечения на каждом узле и программирование четырех параллельных программ. Каждая часть проекта определяет некоторые функциональные возможности в системе, сочетание аппаратных средств, программного обеспечения, а также программы определяют, насколько хорошо каждый пакет ответил. При использовании однородного кластера с точно такой же операционной системой, оборудованием и программным обеспечением на каждом узле, проект имел меньшее число переменных, которые могут повлиять на выполнение. Таким образом, любые сопротивления выполнению были универсальными между программами и пакетами.
Аппаратное обеспечение
Самым низким уровнем и первой частью было планирование аппаратных средств. Кластер был построен с пятью узлами, что стало максимальным количеством узлов, с которым может справиться коммутатор. Вычислительные узлы получили обновления в памяти и понижения в аппаратном обеспечении для достижения однородности. Узлы также были идентичны с точки зрения операционной системы и программного обеспечения. В результате кластер был однородным относительно аппаратного и программного обеспечения, необходимых сетей, программных и аппаратных исключений на главном узле.
Готовый кластер с пятью узлами, названный Jaguar, имел один главный узел для локального интерфейса пользователя и четыре вычислительных узла, как показано на рисунке 1. Каждый вычислительный узел был разработан только для запуска расчетов; доступ пользователей была возможен только через SSH. Главный узел имеет модифицированное аппаратное и программное обеспечение для обеспечения взаимодействие с пользователем и сетей. Сетевая файловая система (NFS) через главный узел позволяет вычислительным узлам доступ и изменение файлов, доступных для всех других узлов.
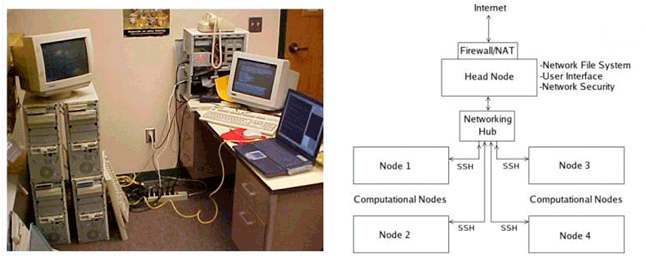
Рисунок 1 – Кластер Beowulf с пятью узлами, схема планирования Jaguar
Каждый узел состоит из одного Pentium-S 200 МГц процессора, материнской платы FIC PT2006, 64 мегабайт оперативной памяти, 2 гигабайт пространства локального жесткого диска, S3 ViRGE видео карты, и 3Com сетевых интерфейсных плат (NIC). Соедтнение между узлами обеспечивается Belkin 10/100 пяти-портовым Ethernet коммутатором. На рисунке 2 показана внутренняя конфигурация отдельного узла.

Рисунок 2 – Внутренняя конфигурация одного узла кластера Beowulf, Jaguar
Программное обеспечение
Над аппаратным уровнем находится одним из наиболее важных компонентов системы в кластере: программная среда. Центральный пакет программного обеспечения, установленного на компьютере является операционной системой. В кластере Linux, выбор операционной системы определяет, какое программное обеспечение будет работать в системе и сколько усилий потребуется, чтобы обеспечить правильную работу программного обеспечения. Jaguar использует имеющийся в наличии RedHat Linux 7.2. В процессе установки ненужные пакеты программного обеспечения, которые обычно сопровождают операционные системы (например, OpenOffice) были удалены. После его завершения, было достигнуто улучшение времени выполнения и усилено меры безопасности путем удаления ненужных служб и процессов (например, kudzu and Apache). В целях безопасности, каждый узел запустил Secure Shell (SSH) серверной программы и, для удобства параллельных программ, каждый узел был настроен так, чтобы он мог войти в любой другой узел через SSH без пароля. Однако, SSH доступ к вычислительным узлам из внешней сети был ограничен использованием главного узла. Главный узел выступал в качестве маршрутизатора кластера к сети Интернет и в нем содержится брандмауэр и используется трансляция сетевых адресов (NAT), чтобы скрыть исходящий трафик и блокировать нежелательный входящий трафик. Весь входящий трафик, за исключением трафика через SSH, был отклонён главным узлом.
Главный узел также имеет второй жесткий диск, который сконфигурирован как диск сетевой файловой системы (NFS) для других узлов; этот жесткий диск содержал все пользовательские файлы и программные приложения. Среди программных комплексов были установлены на все машины Portland Group Workstation версии 5.1, MPICH версии 1.2.5, LAM-MPI версии 6.5.9, и OpenPBS. Workstation Portland Group включает в себя компиляторы для FORTRAN 90, язык программирования, используемый в большинстве тестовых программ; OpenPBS является очередью системы, которая контролирует вход на MPI реализации. Для упрощения процесса тестирования, OpenPBS не использовалась. Кроме того, LAM-MPI использует другой метод запуска программ, чем MPICH; с LAM-MPI, каждый узел запрашивает доступ к LAM-MPI двоичным файлам перед тем, как параллельная программа может быть запущена. Первоначально главный узел имел основную копию LAM-MPI пакета, а все остальные имели к нему доступ через общий диск. Однако, из-за проблемы с запуском вновь скомпилированных версий LAM-MPI на диске NFS, узлы вместо этого запускали предварительно скомпилированные версии реализации MPI.
Разработка программы
Для лучшего сравнения пакетов параллельного программного обеспечения, проектирование и тестирование параллельных программ включает в себя две категории: пример и практика. Примерами программ были параллельные алгоритмы на основе MPI, которые не имеют никакой цели с их сообщениями. Скорее, параллельные вызовы методов были реализованы для отсчета времени и в целях тестирования. Практические программы были решениями реальных и образцовых математических и компьютерных проблем науки. После того, как первоначальные версии программ стали полными, программы были объединены скриптами, чтобы повторять каждый параллельный алгоритм десять раз и писать индивидуальные результаты времени в файлы.
Первый из примеров программ протестировал только неявные MPI механизмы времени. Функция отсчёта времени является одной из главных для эксперимента, так как значительная разницы в пакетной реализации времени вызова может смещать данные для остальной части эксперимента. Эта программа была очень простой параллельной программой; она записывала точное время последовательных вызовов функции MPI_Wtime. Результирующая разница во времени между вызовами является минимальным дополнительным временем, которое добавляется к времени записи для любого другого вызова. Так как задержка передачи данных возрастает с увеличением числа процессов и процессоров, результаты включают тесты программ с различным количеством процессоров. Несмотря на отсутствие математических вычислений в вызовах, латентность для этого вызова может увеличивается с увеличением числа процессоров. Данные от временных программ включали время выполнения на одном, трёх и пяти процессорах.
Второй из примеров программ использовал временные методы протестированые в первой программе, хотя он проверил количество времени, необходимое для выполнения других MPI вызовов. Эта программа сделала синхронные вызовы на девять различных функций на основе MPI, не включая MPI_Wtime и инициализационных вызовов. Результаты имеют данные для MPI_BCAST (эфир и те же данные в множество процессов), MPI_Scatter (разбор и отправить уникальных данных к отдельным процессам), MPI_REDUCE (принятие данные от многих процессоров и выполнение математического преобразования данных), MPI_Sendrecv (одновременно передача и прием данных), MPI_SEND (послать данные только одному процессу), а MPI_RECV (прием данных только от одного процесса). Этот пример программы также выполнил специальные вызовы, используя различное количество данных; у всех секций с MPI_BCAST, MPI_Scatter, MPI_SEND, и MPI_RECV есть вызовы с использованием больших наборов данных и небольших наборов данных. Различия в результатах от различного количества данных сравнительно не изменяются при изменении размера задачи, так что представлены только результаты от крупнейшего набора данных. Результаты основаны на различном количестве процессоров (от одного до пяти) и фиксированном размере блока данных (тысяча элементов в стандартном FORTRAN массиве целых чисел).
Первая практическая прорамма была основана на параллельной версии умножителя матриц. Серийная версия программы вычисляет полученную матрицу от умножения двух матриц соответствующего размера с использованием стандартного алгоритма умножения матриц. Параллельная версия программы посылает части матрицы с использованием MPI_Scatter команды, затем она принимает и суммирует меньшие матрицы с использованием MPI_REDUCE. Поскольку программы используют только данные испытаний, параллельные версии не требуют методов проверки ошибок данных. Для параллельной матричной программы, работающей на пяти процессорах, скрипт записал информацию о времени вызовов MPI_REDUCE и MPI_Scatter с разными размерами векторов и матриц.
Вторая практическая программа приближает значение числа Пи использованием интегрального исчисления. Алгоритм апроксимирует интегральный эквивалент Пи путем расчета площади под кривой, используя метод трапеции. Параллельная версия программы присваивает каждому процессору диапазон значений, которые он вычисляет и суммирует площадь трапеции под кривой. Основная часть программы получает заполненные области из других процессов и суммы этих значений с использованием MPI_REDUCE. Эта программа использует версию математического алгоритма реализованого в параллельном режиме; она также включает вызовы времени и цикла для записи времени, требуемого для выполнения функции MPI_REDUCE. Данные, представленные из вычислений числа Пи, основаны на программе, запущенной на пяти процессорах, последовательно используя более мелкие трапеции.
.
.
.
Список использованной литературы
1. Benson, G.D., Chu, C.W., Huang, Q., Caglar, S.G. (2003) A Comparison of MPICH Allgather Algorithms on Switched Networks. Lecture Notes in Computer Science 2840: 335-343.
2. Farrell, P.A. and Ong, H. (2003) Factors involved in the performance of computations on Beowulf clusters. Electronic Transactions on Numerical Analysis 15: 211-224.
3. Foster, I., Geisler, J., Kesselman, C., Tuecke, S. (1997) Managing Multiple Communication Methods in High-Performance Networked Computing Systems. Journal of Parallel and Distributed Computing 40: 35-48.
4. Ong, H. and Farrell, P. (2000) Performance Comparisons of LAM/MPI, MPICH, and MVICH on a Linux Cluster connected by a Gigabit Ethernet Network. Proceedings of the 4th Annual Linux Showcase and Conference 353-362.
5. Protopopov, B.V. and Skjellum, A. (2001) A Multithreaded Message Passing Interface (MPI) Architecture: Performance and Program Issues. Journal of Parallel and Distributed Computing 61: 449-466.
6. Squyres, J.M. and Lumsdaine, A. (2003) A Component Architecture for LAM/MPI. Lecture Notes in Computer Science 2840: 379-387.
7. Sterling, T.L. (2001) Beowulf Cluster Computing with Linux. MIT Press.
8. Swann, C.A. (2001) Software for parallel computing: the LAM implementation of MPI. Journal of Applied Econometrics 16: 185-194.
9. Thakur, R. and Gropp, W.D. (2003) Improving the Performance of Collective Operations in MPICH. Lecture Notes in Computer Science 2840: 257-267.
10. Van Voorst, B. and Seidel, S. (2000) Comparison of MPI Implementations on a Shared Memory Machine. Lecture Notes in Computer Science 1800: 847.