Управление веб-знаниями на основе онтологий.
Автор: Yanmei Wang, Zhonghua Yang, Pe Hin Hinny Kong, and Robert Kheng Leng Gay
Автор перевода: Машичев А.В.
Автор: Yanmei Wang, Zhonghua Yang, Pe Hin Hinny Kong, and Robert Kheng Leng Gay
Автор перевода: Машичев А.В.
Управление знаниями становится все более и более важным в организациях, а также в Интернете. В этой статье мы представляем фреймворк на основе онтологий для управления веб-знаниями с помощью языка DAML+OIL, основанном на веб-онтологиях. Этот фреймворк поддерживает ориентированный на содержание подход к управлению знаниями, а не традиционный документо-ориентированный подход. Три фундаментальных составляющих блока для семантической обработки знаний: аннотации, основанные на онтологиях; базы знаний на основе утверждений в онтологии и неравномерное распределение веб-ресурсов; система логического вывода, основанная на правилах. Наш подход к управлению знаниями является результатом наших усилий в семантическом веб-исследовании. В нашей разработке по управлению знаниями мы используем специальные программы на основе веб-стандартов. Мы полагаем, что этот подход неравномерно распределенного логического вывода аннотаций (ACI) является гибким и эффективным в поддержании совместного использования знаний в веб. Текущий прототип кратко описан.
Ключевые слова: Онтология, DAML, DAML+OIL, Управление знаниями, Semantic Web.
Существующий и растущий интересы к Semantic Web привели к бурной активности в органах по стандартизации, W3C, чтобы точно определить семантику, используя формальные языки и механизмы логического вывода. Как было отмечено изобретателем WWW, Тимом Бернерсом-Ли, одной из важнейших основ для приложений, поддерживающих Semantic Web, является управление знаниями. Управление знаниями, основанными на Web, обеспечивает привлекательную альтернативу для традиционного подхода управления знаниями. Организациям нужны программы для управления знаниями, чтобы пользователи могли лучше понимать контекстные изменения знаний, что способствует эффективному и результативному сотрудничеству, пока происходит сбор, представление и интерпретация ресурсов знаний в контексте их сферы деятельности и бизнес контексте [1].
Традиционно, большинство управлений знаниями сфокусированы на информационной технологии, но они не содержат четкой формулировки, что понятие «знание» должно поддерживаться и должно быть доступно через стандарты Web-онтологий. Например, IT-поддерживаемые решения по управлению знаниями построены на основе организационной памяти, которая представлена неформальными, полу-формальными и формальными знаниями, в целях облегчения доступа и совместного использования членами организации, для решения индивидуальных или коллективных задач [2]. Управление знаниями манипулирует знаниями, содержащимися в документах. Каким-то образом знания могут быть приобретены или «открыты» автоматически из различных, гетерогенных источников информации, например, Web-страницы и сетевые коллекции документов. Однако этот подход кажется в лучшем случае наивным, так как он игнорирует контекст и целевое назначение источника информации [18]. Без установления контекста и цели, кажется маловероятным, что много полезных «знаний» может быть обнаружено, так как используется широкое толкование. Кроме того, подавляющее большинство документов системы управления используют ключевые слова, как метод поиска, в сочетании с информационным поиском без относительного значения логического поиска.
Semantic Web, основанный на представлении семантических знаний, обеспечивает взаимодействие между машинами. Основная идея Semantic Web заключается в формировании информационно доступного для человека и программных агентов, семантического базиса. Знания должны быть смоделированы, структурированы и взаимосвязаны для поддержания гибкой интеграции и персонализированного представления пользователю. Проблема заключается не в данных, а в правилах и смысле данных (метеданных), которые определены достаточно точно, так что машины могут правильно интерпретировать и быстро обрабатывать данные в качестве управления знаниями. Онтологии показали, что правильным решением для этих структур и проблем моделирования является обеспечение формальной концептуализации конкретного домена, разделенного группой людей в организации [3]. Управление знаниями на основе онтологий использует онтологии как скелет для представления метаданных для обеспечения и доступа к источникам знаний. Онтология – это ключ для Semantic Web.
В этой статье мы представляем наши начальные достижения в Semantic Web. Мы исследуем стандартные технологии W3C, особенности языка Web-онтологий DAML-OIL для управления знаниями. Основанный на онтологиях, framework показывает как мы применяем подход, основанный на аннотациях, неравномерном распределении и логическом выводе. Идея управления знаниями на основе онтологий в Web демонстрирует использование прототипа.
Статья организована следующим образом. В части 2 мы предоставляем краткий обзор новых Semantic Web и языков Web-онтологий. В третьей части мы описываем наш framework для управления Web-знаниями. В четвертой части описано доказательство концепции. Мы обсудим некоторые похожие работы в разделе 5. Выводы этой статьи в разделе 6.
Согласно определению Тима Бемерса-Ли и других, Semantic Web является расширением существующего Web, в котором информация имеет хорошо определенное значение, позволяющее компьютерам и людям лучше сотрудничать [19]. W3C устанавливает стандарты Semantic Web на основе RDF. Ожидается, что сервисы Semantic Web, как универсальная доступная платформа, будут позволять данным быть общими и обрабатываться машинами так же хорошо, как и людьми. RDF представляет собой метод представления знаний. RDF сети состоят из узлов со связями между ними. Узлы в семантической сети представляют собой понятия. Ссылки являются парными для представления отношений и обратных отношений [5].
Онтологии, которые собирают семантику информации и делают ее лаконичной, универсальной и декларативно описанной, приобрели значение, в связи с достижениями Semantic Web. Онтология воплощают человеческие знания через символы, которые обрабатываются машиной. Таким образом, польза онтологий в машинном чтении данных заключается в использовании онтологий для индексирования данных и выражения метаданных [6]. В контексте управления знаниями, онтология описывает информацию, основанную на семантическом контексте, а не синтаксической связи, позволяя агентам и программным компонентам компьютера понимать семантическое значение определенного ключевого слова в онтологии. Например, если мы определили концепцию «Тигр» является «Животным» и имеет свойство «4 лапы». В следующий раз, когда мы будем использовать «Тигр», семантическое значение будет подразумевать, что «это животное Тигр имеет 4 лапы». Когда мы ищем Semantic Web, программные агенты или программные компоненты собирают один раз семантические значения концепции «Тигр». После того, как запрос передан в поисковую систему, возвращаются правильные результаты (рис. 1).
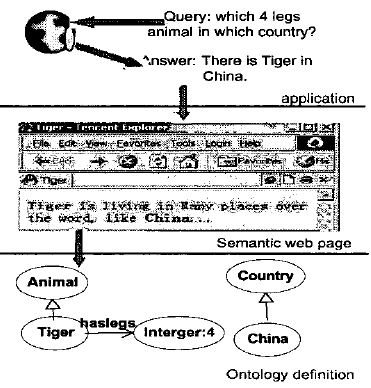
Рисунок 1 – Онтологии и семантический запрос
Web-онтологии определены с помощью языка Web-онтологий. Количество языков описания онтологий в Интернете, таких как RDF (S), DAML + OIL и OWL, находятся в стадии разработки. Эти языки онтологий вобрали в себя лучшие практические представления знаний, доступных в индустрии, и являются гибкими и расширяемыми с помощью новых свойств, а также включают и обеспечивают совместимость с различными моделями знаний. RDF схемы отличаются от схем XML тем, что они не определяют синтаксис, но вместо классов, свойств, и их взаимосвязи они действуют непосредственно на уровне модели данных, а не синтаксиса уровня. RDF схемы являются одним из ключевых технологий, так как они позволяют машинам сделать выводы о данных, собранных в Интернете [7]. Язык DAML-OIL был разработан совместным комитетом для США DAML (DARPA Agent Markup Language) и European OIL (Ontology Inference Layer), проектирование и уклон делались в поддержку W3C XML схемы типов данных [11]. DAML позволяет быть еще более выразительным, чем RDF схемы, и приводит нас в нужное русло для обсуждения Semantic Web [7].
Умение эффективно и рационально управлять знаниями имеет жизненно-важное значение для устойчивого успеха организации. Технологии, основанные на онтологиях, являются ключом для приложений для управления знаниями. Самое главное, что управление знаниями на основе онтологий делает возможным повторное использование знаний и обмена знаниями в доле общего понимания.
В этом разделе мы представляем framework для ввода в действие приложения, в основу которого заложены онтологии, для управления Web-знаниями. Фремворк состоит из трех информационных уровней и потоков знаний. Они аннотированы, неравномерно распределены и логически выведены. Мы называем это A-C-I подход (рис. 2).
3.1 Потоки данных
Первым шагом к разработке системы управления знаниями является выявление потоков знаний системы. Потоки знаний заключают в себе набор процессов, событий и мероприятий, по которым данные, информация, знания и мета-знания собираются, передаются и преобразовываются из одного состояния в другое [10]. Наш framework содержит 4 типа знаний в связи с разным уровнем концептуализации.
Для того, чтобы собрать и представить знания, мы разрабатываем область знаний онтологии после консультации с экспертами этой области. Создатели аннотаций будут вставлять в семантическую концепцию, смоделированную онтологией, в их Web-страницу. В сущности, Web-ресурсы (обычно Web-документы) отмечаются в Web-онтологии языка. В принципе, все утверждения и экземпляры, как указано в онтологии, отмеченые в Web-документах, войдут в базу знаний (БЗ). База знаний является неотъемлемой частью мышления (логического вывода) системы. Система мышления применяет правила для получения новых знаний.
Чтобы получить артефакты знаний из неструктурированных знаний, мы используем процессы знаний, они аннотируют разработки онтологий, неравномерное распределение и логический вывод. Аннотирование и разработка процесса получения знаний для неструктурированных знаний структурирует знания по его семантическому смыслу. Неравномерно распределенные процессы собирают рассеянные знания в семантические Web-страницы. Процесс логического вывода осуществляет машинную обработку знаний. В результате указанных выше трех процессов, также основанных на онтологии, выделены три фундаментальных блока frameworkа для управления Web-знаниями.
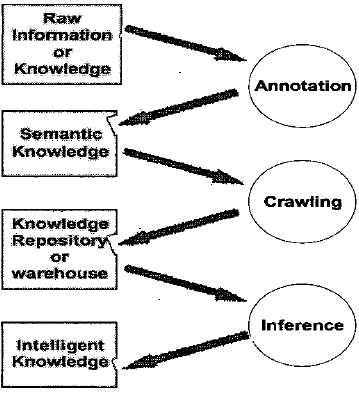
Рисунок 2 – Потоки знаний и используемые инструменты
Управление знаниями включает в себя базу знаний для хранения элементов знаний и отношений между знаниями. База знаний является абсолютной коллекцией экспертных оценок, опыта и знаний, которые находятся в организации [9]. Как указывалось ранее, наша база знаний тесно связана с онтологией и системой мышления.
Управление знаниями на основе онтологий – это приложение, которое предлагает структурированный доступ к большим объемам неструктурированной информации в Интернете. Онтология служит фундаментом для управления знаниями на основе онтологий, для того, чтобы позволить обмен знаниями с помощью Web.
Из анализа знаний артефактов и знания процессов в потоке знаний, мы разработали framework управления знаниями, как показано на рисунке 3. Этот framework поддерживает поток знаний как определено выше и имеет три основные функциональных блока для аннотирования и развития онтологии, неравномерного распределения и логического вывода. Кроме того, DAMLJessKB используется для добавления некоторых правил логического вывода в базу знаний [15]. Конкретное использование этих средств будет обсуждаться более подробно, когда будем обсуждать прототипирование. Наш framework является достаточно гибким для поддержки развития любой онтологии, любого приложения и данных экземпляра, встроенных в Web-страницу, в домене для управления знаниями в Web.
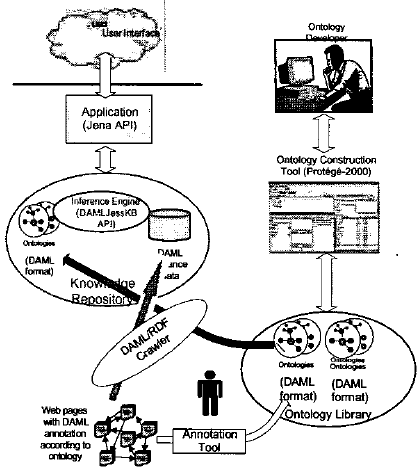
Рисунок 3 – Фреймворк A-C-I
Мы используем Protege-2000 как редактор онтологий и знаний. Protege является самым простым в использовании и поддерживает построение интерфейсов для приобретения знаний, основанных на онтологических данных [20]. Мы добавили DAML+OIL плагин для поддержки наших онтологии и создания экземпляра.
Инструмент аннотирования решает задачу создания и поддержания онтологической DAML+OIL разметки, то есть создание DAML-экземпляров, атрибутов, отношений и обогащение ими Web-страниц с DAML-метаданными [21].
Построение базы знаний опирается на неравномерное распределение в RDF. RDF неравномерное распределяет загрузки взаимосвязанных фрагментов RDF из Интернета и создает базу знаний из этих данных. RDF обход может собрать DAML утверждения, известные как DAML+OIL на основе RDF-схемы. Для возможного встраивания в другие элементы, RDF Crawler обеспечивает высокий уровень программного интерфейса (Java API). Утилита RDF Crawler является оберткой этого API – либо консольное приложение, либо оконное приложение, либо сервлет. Узнать подробнее о спецификации RDF можно в источнике [12]. Для реализации наших целей нам интересна его способность обрабатывать DAML+OIL. Он помогает извлечь онтологии из библиотеки онтологий и собрать утверждения RDF и утверждения DAML+OIL из Web-ресурсов.
Полученные результаты, которые содержат онтологии и экземпляры, отправляются в базу знаний. Эта база знаний объединяется с утверждениями (des) и формирует ядро управления знаниями основанного на онтологиях, используя новейшие артефакты знаний в потоке знаний (рис. 2). Механизм логического вывода, в сочетании с базой знаний, отвечает на запросы, основанные на семантике. Кроме того, он получает новые знания сочетанием фактов и онтологии [13]. Наша система мышления является инструментальной системой на основе DAMLJessKB, который позволяет добавлять правила хранилище знаний [15]. DAMLJessKB использует Java Expert System Shell (Jess [14] является движком для правил и скриптовая среда, написанная на языке Java), разработанная в Sandia National Laboratories.
Как видно на рисунке 3, наша база включает Инструментальные средства для разработки приложений KM. Пока framework не предусматривает обязательное использование конкретного инструментария или среды разработки, мы обнаружили, что HP Labs Semantic Web toolkit Jena является удобным инструментарием для манипулирования RDF моделями для разработки приложений в рамках Semantic Web [22,16]. Jena API разработан специально для языка программирования Java. Приложение разработано с использованием Jena API будет обрабатывать данные экземпляра в соответствии с метаданными в онтологии. Для разработчиков проводят консультации эксперты предметной области, чтобы получить знания предметной области и создать хорошие онтологии.
Эта модель логического вывода ведет нас в разработке различных приложений KM. В этом текущем исследовании, мы разрабатываем прототип для демонстрационных целей. Мы построили приложение в качестве простой системы управления навыками для людей отдела ресурсов в ИТ-компании. Приложение и разработчик онтологий может реализовать другие виды приложений и другие онтологии, в соответствии с конкретными потребностями бизнес-доменов. Есть много исследований по развитию онтологий. Мы разработали онтологию, которая описывает концепцию и структуру человеческих навыков ИТ-компании. Снимок онтологии показано на рисунке 4. Кусок кода, показывающий следующий навык онтологии представленный с использованием DAML + OIL, выглядит следующим образом, где имя пространства : "xmlns: daml_oil=http://www.daml.org/2001/ 03/darnl+oil#".
Заметим, что в компании существует понятие «Личность», которые моделируют детали о служащих и кандидатов. Схема других онтологий показана здесь с ограничениями длины.
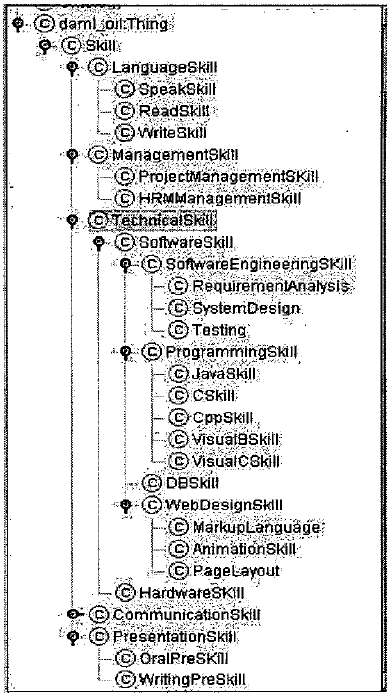
Рисунок 4 – Онтология способностейI

AQSearch является проектом разработки программного обеспечения (Northeastern University College of Engineering) для разработки программного обеспечения, которое поддерживает процесс хранения и получения информации о проекте. Эта информация хранится в виде DAML-аннотированных документов. Соответствующие онтологии, собрав знания предметной области (в данном случае домен управление разработкой и проектированием программного обеспечения) являются частью результатов. Различные пользователи затем могут просмотреть эту информацию, разместив запросы через механизм запросов. Двигатель получает информацию и предоставляет ответы для пользователей [17].
AQSearch недостаточно для практического применения в организациях, особенно для международных организаций. AQSearch помещает информацию (экземпляр данных) в DAML файл с тем же расширением, что и файл онтологий. На практике, информация может быть, на Web-страницах, в базе данных или где-то еще. Наш подход ACI преодолевает проблемы AQSearch и добавляет еще несколько функций в представляемый framework. То есть, эта модель является более полной, чем AQSearch.
В этой статье мы показали наш подход управления Web-знаниями на основе онтологий. С нашей точки зрения, наше предложение более универсальное потому, что Web-интерфейсом легче реализовать систему, а организовать многоуровневую структуру можно благодаря знанию артефактов.
Что касается будущего, мы видим ряд новых важных тем, появившихся на горизонте. Например, мы рассматриваем изучение онтологий, как преобразования между различными языками представления онтологий. Это помогает онтологии более широкое повторное использование онтологии, а также экономное использование человеческих ресурсов.
Исследования представленные в этой статье были бы невозможными без спонсорства EEE School и NTU-Sun ASP Centre.
[I] York Sure, Steffen Staab, Rudi Studer. Methodology
for Development and Employment of Ontology based
Knowledge Management Applications. Institute AIFB,
University of Karlsruhe. Association for Computing
Machinery, Volume 3 1, Number 4. December 2002.
[2] R. Dieng, 0. Corby, A. Giboin, and M. Ribiere.
Methods and tools for corporate knowledge
management. Int, Journal of Human-Computer Studies,
51(3):567-598, 1999
[3] D. O’Learv. Using AI in knowledge management: Knowledgk basesand ontologies. kEE Intelligent
Systems, 13(3): 34-39, May/June 1998.
[4] Nenad Stoianovic, Alexander Maedche, Steffen Staab,
Rudi Studer, York Sure. SEAL-A Fkework for
Developing Semantic PortALs. Lecture Notes in Computer Science, Institute AIFB, University of
Karlsruhe. 2001.
[5] Edward Pattison-Gordon, Knowledge Representation
for Medical Concepts.
[6] Jeremy Rogers. Developing and applying ontologies:
experiences from the medical domain. Medical
Informatics Group, University of Manchester. 2002.
[7] Sean B. Palmer. The Semantic Web An Introduction.
SGML Center Presentation. UK. October 2001.
[SI Christian Ohlms, Mckinsey & Company. The
Business Potential Ontology-based Knowledge
Management. KnowTech 2002.15 October 2002.
[9] Aegiss Corporation. Introduction to Knowledge
Management and the Knowledge Base. 1995.
[10] Brian (Bo) Newman. A Framework for Characterizing
Knowledge Management Methods, Practices, and
Technologies. January 1999, in support of The
Introduction to Knowledge Management, George
Washington University Course EMGT 298.T1, Spring
1999
[11] Eric Van Der Vlist. DAML and OIL embrace W3C
XML Schema. 28 Mar 2001 UTC.
[12] Kalvis Apsitis. Specification of a RDF Crawler.
Institute AIFB, University of Karlsruhe.
[13] Steffen Staah, Jurgen Angele, Stefan Decker, Michael
Erdmann, Andreas Hotho, Alexander Maedche, Hans-
Peter Schnurr, Rudi Studer, York Sure. Al for the Web
- Ontology-based Community Web Portals. Institute
AW, University of Karlsruhe. In AAA1 2000.
[14] Emest Friedman-Hill. Jess: The rule engine for the
Java platform. httD:/merzbere.ca.sandia. 1995.
[15] Joe Kopena William C. Regli. DAMLJessKB: A Tool
for Reasoning with the Semantic Web. Geometric and
Intelligent Computing LaboratoIy, Department of
Computer Science, College of Engineering, Drexel
University. October 28,2002.
[16] Brian McBride. Jena: Implementing the RDF Model and Syntax Specification. Hewlett Packard
Laboratories. Bristol, UK. 2000.
[17] J. H. Tu, R. Feng,Z. Y. Li, W.Tong,Z. Q. Liu.
MIM3152 & MIM3153 PROJECT SPECIFICATION.
Northeastern University College of Engineering.
January 07,2002 -June 06,2002.
[18] Clifford Behrens and Vipul Kashyap. The “Emergent”
Semantic Web A Consensus Approach for Deriving
Semantic Knowledge on the Web. In the F’rocessings
of the Firs Semantic Web Working Symposium, pp
55-74, July 30-1 August 2001.
[19] Tim Bemers-Lee, James Hendler, Ora Lassila. The
Semantic Web, Scientific American, May 2001.
[20] Protege Users Guide,
htto: //m. smi. stanford. edU/DrO.ieCtS/DrOtene
/doc/users mide/index. html
[21] What is OntoMat-Annotizer? http: //annotat ion. semant icweb. org/tools/ontomat
[22] Hp Labs Semantic Web Research,
http://www.hpl.hp.com/semweb/index.htd