Построение онтологий для вэб-приложений.
Автор: А.В. Григорьев, Е.В. Павловский
Источник: Материалы четвертой международной научно-технической конференции “Моделювання та комп’ютерна графіка”.
Автор: А.В. Григорьев, Е.В. Павловский
Источник: Материалы четвертой международной научно-технической конференции “Моделювання та комп’ютерна графіка”.
В предлагаемой статье рассматривается специфика представления сайта, выполненного на языке HTML, как типичной модели структурного уровня абстракции САПР. Приводится пример выявления структурной модели в типичном сайте. Показывается, что данная модель структуры соответствует возможностям концептуальной модели предметной области инструментальной оболочки для автоматизации построения САПР, что позволяет сформулировать задачу построения такого рода оболочки.
Ранее авторами рассматривался подход представления вэб- приложений с точки зрения онтологического подхода как модель некоторого объекта предметной области, призванного обеспечить представление знаний для БЗ. В данном случае база знаний относится к САПР вэб-приложений.
Нашей общей задачей является создание инструментальной оболочки, способной автоматизировать создание базы знаний о методиках проектирования вэб-приложений на требуемых языках программирования (HTML). Данная база знаний и является требуемым САПРом. Такой САПР должен обеспечить синтез требуемого вэб-приложения, исходя из параметров, задаваемых конечным пользователем.
Приведенная ранее онтология соответствует стандартному подходу представления вэб-страницы. Однако в таком виде она не обеспечивает возможность построения базы знаний о методиках проектирования вэб-приложений в силу своей упрощенной и примитивной структуры.
Чтобы возможным было обеспечить построение такой базы знаний, необходимо обеспечить представление, например, страницы сайта с точки зрения стандартных методов представления объектов проектирования в САПР технических объектов. Такие модели делятся по уровню абстракции, например: структурные модели, функционально-логические модели, количественная микро и макро модели.
Представить модель объекта, как структурную модель означает, ввести отношения: принадлежности к множеству для компонентов модели, класс – подкласс, часть – целое, экземпляр – класс и т.д. Представление подобного рода моделей для произвольных объектов любых предметных областей на уровне структурной модели ранее были рассмотрены автором в статье [2].
Целью предлагаемой работы являются:
Для раскрытия данной темы необходимо осветить следующий ряд вопросов:
Сам по себе язык разметки HTML строго структурирован. Язык состоит из множества тегов. Теги могут быть вложены друг в друга и могут иметь атрибуты. Обычно страница сайта разбивается на блоки. Это может быть лента новостей, форма авторизации, переключение языка, гостевая книга и т.д. Каждый блок имеет свои атрибуты и позиционирование относительных других блоков сайта. Распространенной является табличная верстка. Страница сайта разбивается на блоки с помощью таблицы, т.е. каждый отдельный блок – это отдельной ячейке таблицы. В свою очередь, блоки могут содержать неограниченное количество подблоков. Таким образом, каждый блок имеет входы и выходы. Его входами являются любые существенные воздействия среды на синтезируемый объект, выходами – связи объекта со средой. Язык HTML однозначно позиционирует блоки относительно друг другу. Вложенность тегов друг друга – это мощное структурная особенность языка. На сегодняшний день является актуальным представление информации в виде онтологии. Причем каждый трактует это понятие по-своему. Есть базовое понятие и базовое формальное описание. Для конкретных задач можно формальное описание дополнять какими- либо параметрами.
Онтология – это точная спецификация некоторой предметной области. Другими словами это модель данных, которая описывает понятия предметной области, что они означают, как они соотносятся друг с другом, и как они могут или не могут быть связаны друг с другом. Эта модель отображает представление о знании в некоторой предметной области и множество связей между ними.
X — конечное множество понятий предметной области,
R — конечное множество отношений между понятиями,
F — конечное множество функций интерпретации.
Обычно, выделяют такие отношения между понятиями:
Проанализировав существующие структуры данных, сделан вывод, что онтология – это оптимальный вариант для представления и связи компонентов HTML страницы в единую систему.
С точки зрения формального описания онтологии, для представления страницы HTML в виде онтологии, минимально необходимым является знание о составе объекта предметной области (в нашем случае это блоки) и связей между ними (в нашем случае вложенность блоков).
Выполним подобное представление для типичной страницы сайта. На рис. 1 представлен исходный текст главной страницы сайта.
Как видно из текста, сайт разбит на блоки таблицы id=”table_main”. Содержимое отдельной ячейки этой таблицы – это то, что находится между тегами <td></td>. Это главные блоки страницы сайта. Подблоками главных блоков являются элементы, которые находятся в главном блоке.

Рисунок 1 – Исходный код главной страницы сайта на языке HTML
На рис. 2 представлена логическая структура страницы сайта. Каждый блок (прямоугольник) – это ячейка главной таблицы (id=”table_main”). С помощью этой таблицы сайт разбивается на блоки. Эти блоки и есть ячейки главной таблицы. Другими словами, ячейки главной таблицы – это блоки, которые являются вершиной иерархии блочной структуры сайта.
В свою очередь эти блоки могут иметь подблоки, которые принимают от внешнего блока его атрибуты, а также имеют свои. На многих сайтах при переходе на другие страницы меняется только центральный блок. Центральный блок обязателен, т.к. в нем содержится главная информация. Остальные блоки, такие как верхний или боковой, могут отсутствовать.
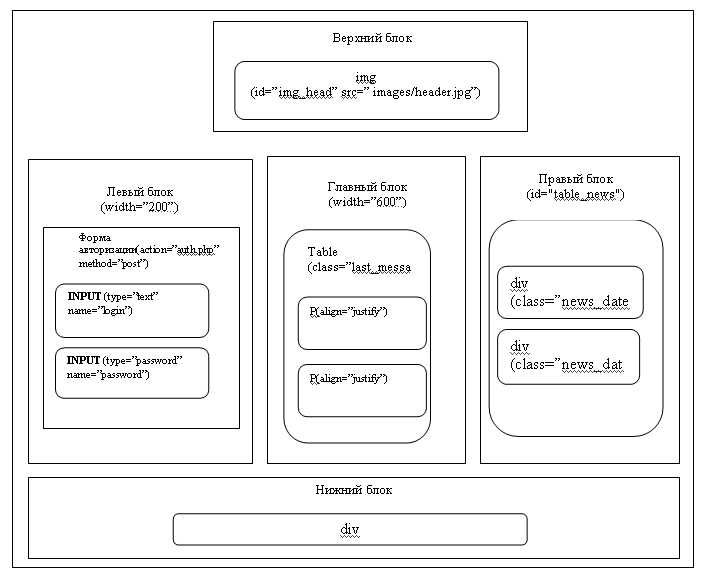
Рисунок 2 – Логическая структура страницы сайта
Многие элементы страницы (теги) имеют атрибуты. Например, <img src="images/header.jpg" width="960" height="200" id="img_head" />. Тег img – является изображением, адрес которого находится в теге src. Также элемент содержит атрибуты ширины и высоты изображения, а также идентификатор id. Элемент <img> является подблоком главного блока (таблица id=”table_main”). Атрибуты находятся на внутренней границе блока.
Как известно, заголовок HTML страницы находится в теге <title>. Из этого следует, что текст заголовка – это подблок блока title. Вход для блока с текстом заголовка страницы – является выходом из блока title. Текст заголовка – подблок блока title (тега <title>).
Вышеизложенные сущности представлены на рис. 3. Остальные элементы находятся в блоке body. При синтезе HTML страницы это будет предусмотрено, но на данной стадии блок body на схеме не обозначен, т.к. это само собой разумеется. Все что мы видим на странице сайта – находится в теге
, т.е. все элементы являются подчиненными блоку body.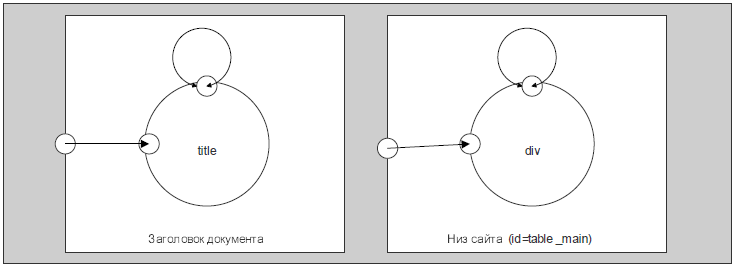
Рисунок 3 – Блок заголовка страницы и блок с автором сайта
Изображение вверху сайта находится в верхнем блоке главной таблицы. К нему на вход подаются атрибуты внешнего блока (рисунок 4). Как видно из листинга страницы (рис. 1), блок с изображением занимает три колонки таблицы. Этот атрибут подается на внутреннюю границу блока изображения.
Текст приветствия находится в центральной ячейке главной таблицы. Текст находится в теге <p>, который находится во внешнем блоке главной таблице. Ему на вход передаются атрибута внешнего блока.
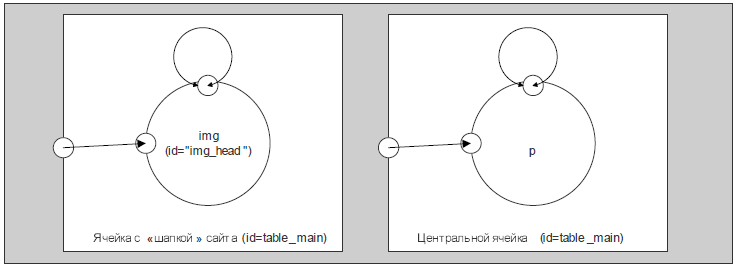
Рисунок 4 – Блок «шапки сайта» и центральный текст главной страницы
Форма авторизации находится во вложенной таблице id=”table_auth”. Блок table у которого id=”table_auth”, является подблоком блока form с id=”form_auth”, который в свою очередь является подблокам блока главной таблицы id=”table_main”.
Для полей ввода логина и пароля входами является выход блока пользователь, т.е. информация которую вводит пользователь. Выходы блоков логина и пароля является входами для базы данных.
Поля для ввода – это ассоциативный массив вида [[name1,value],[name2,value],..,[nameN,value]]. Name – это имя элемента для ввода, value – это значение введенное пользователем. Их содержимое отправляется на сервер, после чего сопоставляется с содержимым базы данных.
Как видно из рис. 5, элементы html страницы могут быть вложены друг в друга. Форма авторизации <form id=”form_auth”></form> вложена в ячейку таблицы <table id=”table_auth”></table>. Последняя в свою очередь содержится в ячейке главной таблицы <table id=”table_main”></table>.
Приходим к выводу, что подблок должен иметь вход только от одного внешнего блока, который ближе к нему. Ведь атрибуты дальнего внешнего блока, будут переданы на вход подблоку. Этого достаточно для построения четкой иерархии, которую предусматривает формат HTML.
Из рис. 1 видно, что на странице сайта присутствует лента новостей. Обычно эта информация извлекается из базы данных и в удобочитаемом виде располагается на странице (обычно в таблице).
Новость состоит из даты и самого текста новости. Данные из базы данных возвращаются в массиве. Каждый элемент – это дата и текст новости. Упрощенно – это массива вида [[div1,div2],[div3,div4]…[divN-1,divN]], где каждый элемент – это одна новость.
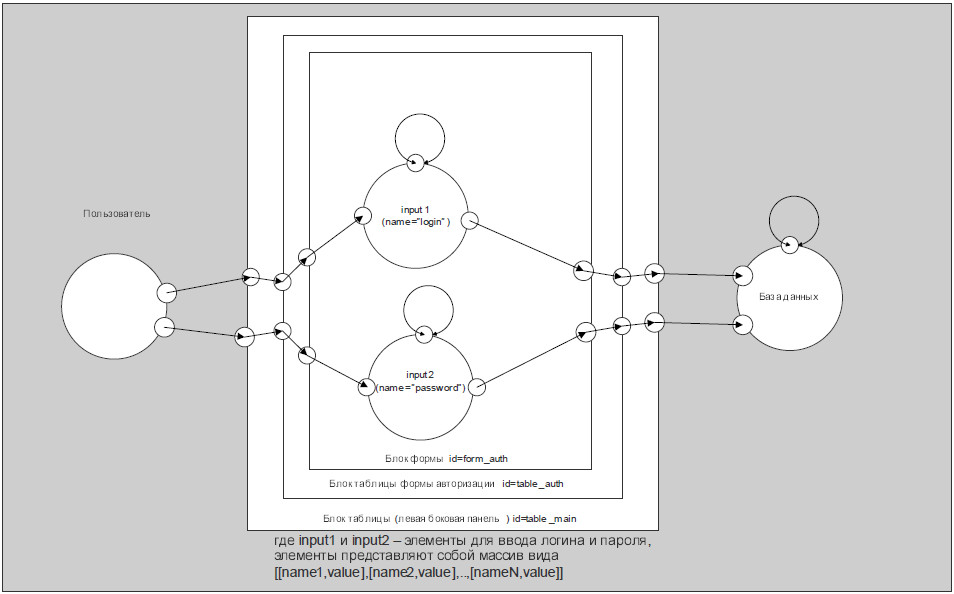
Рисунок 5 – Блок формы авторизации
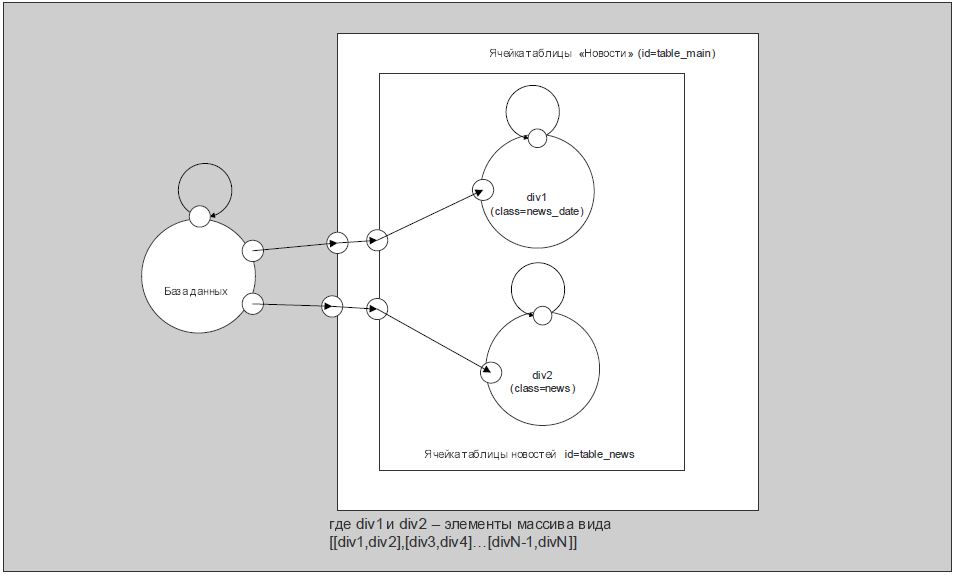
Рисунок 6 – Блок ленты новостей
Из рис. 6 видно, что данные из базы данных подаются на границу внешнего блока главной таблицы id=”table_name”, затем внешний блок передает данные и атрибуты на подблок id=”table_news”.
Подобное представление структуры html файла позволяет создать систему модулей знаний о методах построения блоков различных типов, имеющихся в html файле. Подобное представление соответствует заданию структуры объекта на универсальном языке формальных спецификаций. При наличии транслятора «язык формальных спецификаций» -> проблемно-ориентированных язык (HTML) можно обеспечить синтез желаемого сайта пользователем, эксплуатирующего готовую базу знаний.
Таким образом, предлагаемый путь разработки инструментального комплекса, способного обеспечить создания в его среде баз знаний для автоматизации синтеза сайтов как интеллектуального САПР потенциально эффективен. Однако стоит отметить, что задача имеет ряд специфических особенностей, что требует разработки соответствующего комплекса средств концептуальной модели, способного учесть специфику задачи.
1. Онтология [Электронный ресурс]. Энциклопедия Википедия. – Режим
доступа: http://ru.science.wikia.сom/ wiki/Онтология.
2. Григорьев А.В. Организация временного и пространственного логического
вывода в концептуальной модели интеллектуальных САПР. [Электронный
ресурс] / А.В. Григорьев – Режим доступа:
http://www.nbuv.gov.ua/portal/natural/Npdntu_ikot/2008/08gavmis.pdf.