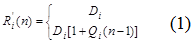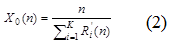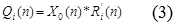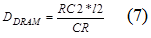Аннотация
Мельник А.В., Ладыженский Ю.В. Анализ
производительности программного обеспечения сетевых процессоров. Описана модель для
оценки производительности программного обеспечения сетевых процессоров. Разработано программное обеспечение по основе этой модели. Проведен экспериментальный
анализ характеристик и построены зависимости показателей эффективности
программного обеспечения с помощью математических моделей.
Ключевые слова: сетевой процессор, производительность
программного обеспечения, анализ характеристик.
Постановка проблемы
Постоянный рост трафика в компьютерных сетях делает
актуальной проблему создания высокопроизводительных специализированных сетевых
процессоров (СП) и их программного обеспечения (ПО) для обработки потоков
данных на разных уровнях стека протоколов. Необходимость анализа ПО на
стадии проектирования и отсутствие достаточно простых и широко применимых
моделей и методов анализа аналитического или имитационного характера, делают
задачу создания моделей и методов анализа производительности программ весьма
актуальной.
Анализ литературы
Современное состояние моделирования СП и существующие способы
моделирования СП рассматриваются в [1-2]. Модель для оценки производительности
программного обеспечения СП описана в [3]. Основные аспекты анализа
эффективности программного обеспечения СП рассмотрены в [4-7].
Цель исследования - анализ моделей описания и методов оценки производительности
программного обеспечения сетевых процессоров, разработка программного
обеспечения, реализующего математические модели СП.
Модель для анализа производительности
Для оценки производительности программного
обеспечения коммутаторов и маршрутизаторов, построенных на сетевых процессорах
(СП) предлагается использовать следующую модель (рис.1).
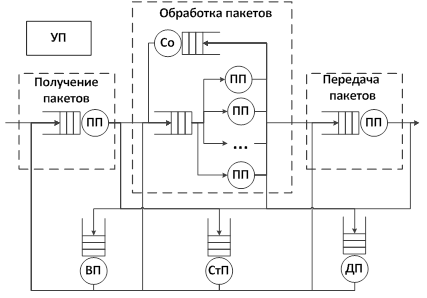
Рисунок 1 – Модель системы
Потоки пакетов на сетевом процессоре
моделируются как сеть массового обслуживания (СМО). В этой модели СМО
представлены отдельные входные очереди для каждого процессора обработки пакетов
(ПП), сопроцессора (Со) и модулей памяти. Считается, что есть три уровня
иерархии памяти: внутренняя память кристалла (ВП), статическая RAM (СтП) и
динамическая RAM (ДП). Управляющий процессор (УП) является процессором общего
назначения, который выполняет встроенную операционную систему. Он обеспечивает
полный контроль, осуществляет управление конфигурацией и обрабатывает
исключения. Управляющий процессор имеет небольшое влияние на общую производительность
приложения, поэтому он не был включен в модель. Получение и передача пакетов
осуществляются выделенными пакетными процессорами, а обработка пакетов
осуществляется параллельно несколькими пакетными процессорами. Использование
механизма многопоточности позволяет пакетным процессорам не ждать ответа от сопроцессора.
Сопроцессоры смоделированы таким же образом как и пакетные процессоры [3].
Входными данными являются затраты на
обслуживание каждого блока СП.
Выходными данными являются характеристики,
которые важны для оценки аналитических моделей для каждого блока, а также
всего СП:
пропускная способность (X0) – это количество запросов (пакетов), завершенных за секунду;
среднее пребывания в системе (R'i) – это среднее время, которое запрос (пакет) проводит внутри СП;
средняя длина очереди (Qi) – это среднее количество запросов, которые находятся на блоке.
Модель (рис. 1) является замкнутой моделью
и она используется для анализа производительности на уровне компонентов. В
системе циркулирует определенное количество запросов.
Для расчета характеристик замкнутой СМО
был выбран метод приближенного анализа средних значений (MVA)[4]. В расчетах
применяются следующие формулы (1) - (3): расчет времени пребывания (R'i), расчет пропускной способности (X0) и вычисление средней длины очереди (Qi).
Здесь i обозначает индекс блока
архитектуры СП, k - общее количество блоков, n - общее число
запросов, находящихся в СМО. Затраты на обслуживание (Di) в каждом блоке определяются путем
анализа псевдокода алгоритма обработки пакета, реализуемого блоком.
Для того чтобы алгоритм MVA сходился
необходимо найти границу пропускной способности системы.
В соответствии с законом затрат на
обслуживание [5], Di=Ui/X0, где Ui - загрузка блока i, X0
- пропускная способность всей системы. Так как загрузка любого блока не может
превышать 100%, X0 ≤ 1/Di для любого блока i. Тогда:
Максимальная пропускная способность
системы достигает предельного значения в блоке с наибольшими затратами на
обслуживание. Поэтому такой блок является узким местом сети СМО.
Моделирование параллельных пакетных
процессоров.
В СМО (рис. 1),
есть несколько пакетных процессоров, которые обрабатывают данные параллельно на
стадии обработки пакетов. В этом случае, есть несколько блоков, обслуживающих
запросы из одной очереди. Основные формулы MVA не применимы для данного случая.
В [6] показано, что затраты на
обслуживание в таком случае можно вычислять по следующим формулам: для ресурса
с очередью - D / m, а для ресурса с задержкой - D*(m-1)/m.
При слабой загрузке запросы не тратят
время на ожидание в очереди. Таким образом, среднее время ответа на запрос в
новой конфигурации - D/m + D*(m-1)/m = D. Это соответствует среднему
времени ответа на запрос в исходной параллельной конфигурации.
При большой нагрузке блоки заняты большую
часть времени. Большая часть среднего времени отклика – это время ожидания в
очереди. Время задержки в блоке задержки становится очень малым, практически
несущественным, таким, что его можно не учитывать. Среднее время ожидания в
очереди для одного блока такое же, как среднее время ожидания в очереди для m
параллельных блоков.
Используя это приближение, параллельные
пакетные процессоры заменяются одним блоком очереди и одним блоком задержки (рис. 2).
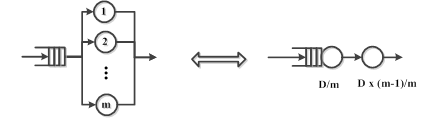
Рисунок 2 – Приближенное
моделирование параллельных процессоров
Анализ приложений и результаты исследований
Для СП,
работающего в сети, легко получить частоту поступления запросов и средний
размер пакета. Однако, сложно измерить средние затраты на обслуживание для
каждого запроса и число пакетов в очереди на каждый блок. Затраты на
обслуживание можно оценить с помощью анализа псевдокода каждого приложения. Например,
ПП в сетевом процессоре IXP2400 являются RISC процессорами и, поэтому
большинство инструкций обрабатываются за один такт. Таким образом, затраты на
обслуживание для ПП можно получить на основе количества инструкций для
обработки каждого запроса. Средняя эффективность обращения к памяти может быть
получена с помощью среднего времени ожидания доступа и количества ссылок на
ячейки памяти для каждого запроса.
Ниже представлены формулы для расчета затрат
на обслуживание для ПП (5) и на затраты на обращение к памяти (6) – (8).
где NI – количество инструкций,
необходимых для выполнения операции, CR – частота процессора, RCi
– количество ссылок на ячейки памяти для i-го типа памяти, li –
задержка для i-го типа памяти: i=1 –
кеш-память, i=2 – статическая память, i=3 – динамическая память.
При параллельном использовании нескольких
ПП на стадии обработки, ПП заменяются двумя блоками в модели на (рис. 2).
Следовательно, затраты на обслуживание для агрегированного блока (9) и блока с
задержкой (10) отличаются от аналогичных требований для одного ПП.
где NME – количество ПП.
Технические характеристики для сетевых
процессоров IXP2400 приведены в таблице 1 [5].
Таблица 1 - Характеристики Intel IXP2400
Тактовая частота |
Потоки ПП |
Время ожидания (в тактах процессора) |
|
ВП
|
СтП
|
ДП
|
|
600
|
8
|
16
|
90
|
120
|
С помощью анализа псевдокода можно
получить приблизительные затраты на обслуживание для модулей. Разработано приложение
на языке С#, позволяющее оценить эффективность
программного обеспечения СП на основе этих данных. На (рис. 3) изображен пример
работы программы: получены затраты на обслуживание для всех ресурсов,
максимальные затраты на обслуживание, которые определяют максимальную
производительность, а также максимальная производительность для данных условий,
которая достигается при количестве пакетов J и
среднее время отклика.
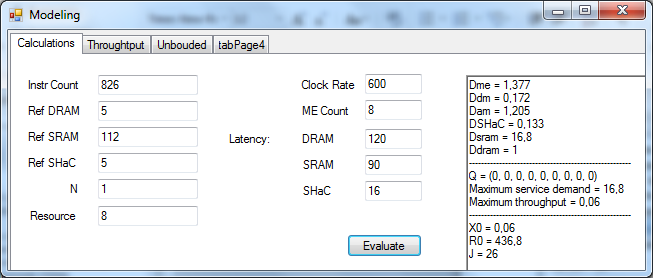
Рисунок 3 – Пример работы программы
По этим результатам расчетов на (рис. 4) показана зависимость
производительности от количества запросов. Как видно из графика, при количестве
в 5 запросов достигается предел производительности.
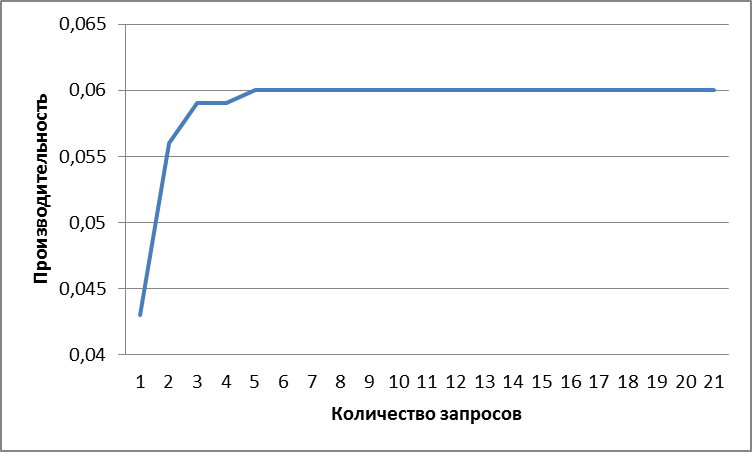
Рисунок 4 – Зависимость
производительности от количества запросов
Было замечено, что добавление
дополнительных ПП не приводит к существенному улучшению производительности,
потому что узким местом приложения является доступ к СтП.
Выводы
Описана модель для оценки
производительности программного обеспечения сетевых процессоров.
Разработано программное обеспечение,
позволяющее на основе псевдокода алгоритмов СП оценить производительность
программного обеспечения без необходимости создания рабочего приложения.
На модели проведен экспериментальный
анализ характеристик и построены зависимости показателей эффективности
программного обеспечения с помощью математических моделей.
Список литературы
- В.И. Грищенко, Ю.В. Ладыженский, Моатаз Юнис. Влияние выделенного кэша команд на производительность сетевого процессора.// Наукові праці Донецького національного технічного університету, серія «Інформатика, кібернетика та обчислювальна техніка»,вып. 13 (185), Донецк, ДонНТУ, 2011. – С. 85-91.
- В.И. Грищенко, Ю.В. Ладыженский. Исследование влияния раздельной памяти на производительность многоядерного сетевого процессора.// Наукові праці Донецького національного технічного університету. Серiя «Проблеми моделювання та автоматизації проектування» (МАП-2011). Випуск: 9 (179) - Донецьк: ДонНТУ. - 2011. – 356 с.
- Jie Lu, Jie Wang, "Analytical Performance Analysis of Network-Processor-Based Application Designs", Computer Communications and Networks, 2006. ICCCN 2006. Proceedings.15th International Conference on, October 2006
- M. Reiser and S. Lavenburg, “Mean-Value Analysis of Closed Multichain Queuing Networks,” Journal of the Association for Computing Machinery, Volume 27, Number 2, April 1980
- P. Denning and J. Buzen, “The Operational Analysis of Queueing Network Models,” Computing Survey, Volume10, Number 3, September 1978
- A. Seidmann, P. Schweitzer and S. Shalev-Oren, “Computerized Closed Queueing Network Models of Flexible Manufacturing Systems,” Large Scale Systems, Volume 12, Number 4, 1987
- D. Menasce and V. Almeida, “Capacity Planning for Web Services,” Prentice Hall PTR, 2002