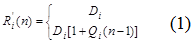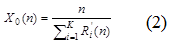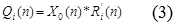Аннотация
Сетевые процессоры (СП) предназначены для обеспечения производительности и гибкости за счет
параллельной и программируемой архитектуры, которая дает им преимущество перед процессорами общего назначения в производительности и аппаратными
решениями в гибкости. Но использование СП также продуцирует новые трудности. Важно изучить ограничения архитектуры СП, чтобы можно было в полной
мере использовать преимущества блоков СП для достижения требуемой производительности для данного приложения. Поэтому желательно разработать общий
подход для анализа производительности приложений для СП. В данной статье представлены аналитический метод решения этой проблемы. В частности, разработана
сеть массового обслуживания для моделирования блоков сетевого процессора и потоков, с которыми работает приложение. Для расчета характеристик, таких как
производительность и время отклика, на уровне компонентов, а также на уровне системы, была использована теория массового обслуживания и операционный анализ.
Разработанная модель для анализа производительности была применена к алгоритму SpliceNP, фактической реализации TCP склеивания для коммутаторов на СП,
зависимых от содержимого представленной в [10], чтобы показать соответствие результатов экспериментов на модели фактической реализации.
Ключевые слова: модель оценки производительности, сетевой процессор.
I. Введение
Сетевой процессор является программируемым устройством обработки пакетов, которое сочетает в себе преимущества низкой стоимости и гибкости RISC-процессоров,
а также масштабируемости стандартного кристалла (т.е. ASIC чипов) [2]. Сетевые процессоры, специально разработанные для хранения, обработки и передачи больших
объемов пакетных данных на высокой скорости с помощью параллельной и конвейерной архитектуры, являются превосходными строительными блоками для конструирования
сетевых систем, имеющих возможность обрабатывать пакеты данных любого типа. Эти операции выполняются с помощью программного обеспечения, обеспечивающего гибкую
платформу для реализации различных сетевых приложений без необходимости создания нового оборудования. Кроме того, программные модули могут быть легко
использованы повторно. Таким образом, СП, с помощью программного обеспечения, позволяют пользователям создавать и добавлять новейшие и наилучшие сетевые
сервисы, и в то же время уменьшить стоимость разработки, а также обеспечить быстрый выход продуктов на рынок.
Программирование СП является сложной задачей. Эта проблема – один из первоочередных вопросов, с которыми сталкиваются все разработчики программного обеспечения. Например, существует несколько проектов, решающих одну и ту же проблему, как узнать какая модель архитектуры потоков данных обеспечит наилучшую производительность? Чтобы ответить на этот вопрос мы должны были бы получить количественные результаты анализа.
Для пакетных процессоров нет операционных систем. Это означает, что разработчикам программного обеспечения необходимо явно выделить блоки СП при проектировании приложений, в том числе циклы процессора, потоки и блоки памяти. Для примера возьмем блоки памяти, очевидно, что структуры данных, доступ к которым производится не часто, такие как пакеты с полезной нагрузкой, должны быть помещены в динамическую память, в то время как структуры данных, к которым требуется частый доступ, например, таблицы поиска, должны быть помещены в статическую память. Однако некоторые СП имеют несколько каналов для одного блока памяти, что вызывает затруднения в определении в каком канале выделить память для отдельных структур данных, чтобы получить максимальную производительность. Решение будет зависеть от модели доступа в конкретном приложении, для которого эта проблема решается. Другие функциональные блоки СП имеют аналогичные проблемы.
Большинство сетевых приложений предъявляют конкретные требования к производительности, в том числе требования к пропускной способности и времени ожидания. Как можно узнать отвечает ли целевой СП указанным требованиям? Если нет, существует ли альтернативный СП, или массив СП, обеспечивающий необходимую производительность?
Эти вопросы требуют наличия инструментов анализа производительности, с помощью которых можно получить количественные результаты. Основными методами анализа являются расчет ограничений и моделирование дискретных событий. Расчет ограничений, который также называется "предварительными" расчетами, часто используются, чтобы быстро оценить максимальную пропускную способность одного компонента системы. Но этот метод имеет ряд серьезных ограничений. Например, расчет ограничений обычно выдает оптимистичные прогнозы, которые являются нереальными для прогнозируемой производительности, которая, скорее всего, уменьшиться при учете более подробной информации о системе. Рассмотрим другой пример: СП имеет несколько компонентов, у каждого из которых есть запросы, которые находятся в очереди ожидания обслуживания. В данном случае с помощью простого расчета ограничений нельзя получить прогнозное время ожидания, поскольку данный метод не предполагает моделирование взаимодействия между компонентами.
Метод дискретного моделирования событий использует глобальное время и планировщик событий для измерения производительности приложения. Переходы представлены различными объектами события. Все события связаны с временными метками. Программа моделирования выполняет события по одному в порядке возрастания временной метки. Глобальное время перескакивает с одной временной метки события к другой. В дополнение к моделированию логики системы, событиям необходимо обновить счетчики использующиеся для статистики, предоставляющей подробные характеристики производительности моделируемой системы. Большинство производителей СП предоставляют наборы инструментов для разработчиков, в том числе симулятор, который может быть использован для обеспечения более точного анализа производительности приложения. Но большинство симуляторов позволяют оценить производительность после для уже готовой программы. Отметим, что часто невозможно реализовать все возможные проекты, чтобы выбрать лучший из них. Таким образом, на данном этапе много времени и усилий будут потрачены впустую, если выяснится, что выбранная модель архитектуры не отвечает требованиям производительности. Отметим также, что симуляторы предназначены для конкретной модели СП или линии продуктов СП. Насколько нам известно, не было инструмента, который позволял бы пользователям сравнивать (даже для примерного сравнения) производительность различных типов СП.
Для преодоления ограничений в методе расчета ограничений и методе моделирования дискретных событий, представим в данной работе аналитический метод, который обеспечивает общий подход для анализа приложений для СП без необходимости их реализации.
Остальная часть статьи построена следующим образом. В разделе II мы описываем общую архитектуру для любого типа сетевых процессоров. В разделе III строится модель сети массового обслуживания, для моделирования вычислений для СП. В разделе IV, мы сравниваем аналитические результаты, полученные на нашей теоретической модели с фактической реализацией TCP склеивания для контентозависимых коммутаторов - SpliceNP.
Мы показываем, что наши аналитические результаты согласуются с фактическими результатами анализа производительности.
III. Модель сети массового обслуживания
Любые приложения на основе СП, как правило, проходят через три этапа конвейерной обработки: получение пакета, обработка пакета и передача пакета. Как получение, так и передача пакетов могут быть реализованы либо на одном процессоре обработки пакетов, либо параллельно на нескольких процессорах. Обработка пакетов может осуществляться на нескольких таких процессорах параллельно или конвейерно.
Потоки пакетов на сетевом процессоре моделируются как сеть массового обслуживания, которая изображена на рисунке 2.
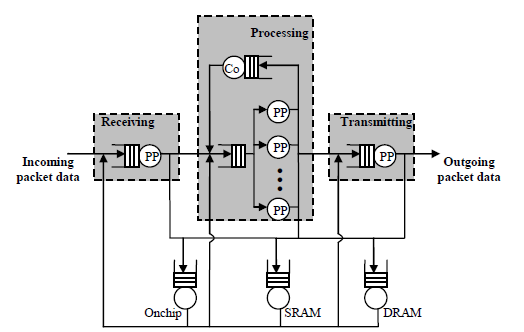
Рисунок 2 – Сеть массового обслуживания для сетевого процессора
В этой модели сети массового обслуживания предоставляется отдельные входные очереди для каждого процессора обработки пакетов, сопроцессора и модуля памяти. Считается, что есть три уровня иерархии памяти: встроенная память, статическая память и динамическая память. Поскольку управляющий процессор, как правило, используется для управления конфигурациями и обработки исключений, а не обработки пакетов на быстром канале передачи данных, он имеет небольшое влияние на общую производительность приложения и поэтому он не был включен в модель. Считается, что и получение, и передача пакетов осуществляются пакетным процессором, и обработка пакетов осуществляется параллельно несколькими пакетными процессорами. Использование механизма многопоточности позволяет пакетным процессорам не ждать ответа от сопроцессора. Сопроцессоры смоделированы таким же образом как и пакетные процессоры. Существует несколько способов выделения ресурсов. Для простоты представлена упрощенная модель, которая может быть расширена с помощью несложных модификаций для использования с другими конфигурациями.
Критические параметры
Определяются следующие параметры, которые важны для оценки аналитических моделей для каждого блока, а также за всего СП:
- интенсивность входного потока: это количество запросов (пакетов), которые поступают за секунду;
- пропускная способность: это количество запросов (пакетов), завершенных за секунду;
- использование ресурсов: это процент времени занятости ресурса обработкой запросов;
- среднее время пребывания: это среднее время, которое каждый запрос (пакет) проводит внутри СП.
Интенсивность входного потока может быть легко измерена извне. Она также может быть указана в явном виде. Если анализируемый интервал достаточно велик, пропускная способность системы, в соответствии с принципом равенства потоков, равна интенсивности входного потока для системы.
В традиционной компьютерной системе, операционная система измеряет точное использование таких ресурсов, как загрузка процессора, использование памяти. Естественно, приложения для СП всегда должны стремиться к достижению оптимальной производительности и устранению ненужных расходов. Обычно нет измерений коэффициентов использования пакетных процессоров. Тогда как относительно легко измерить длину очереди для каждого пакетного процессора, частые измерения длины очереди могут вызвать значительное отрицательное влияние на производительность. С другой стороны грубые измерения могут вызвать большие искажения. Таким образом, используется метод затрат на обслуживание. Затраты на обслуживание для каждого ресурса может быть рассчитана с помощью анализа псевдокода.
Сначала измеряется скорость обслуживания, пропускная способность и время отклика на уровне компонентов, при этом используется анализ сети массового обслуживания. Затем эти результаты применяются для измерения производительности и времени отклика на уровне системы, рассматривая всю систему как черный ящик.
Моделирование на уровне компонентов
Модель СМО, изображенная на рисунке 2, является закрытой моделью. Она используется для анализа производительности на уровне компонентов. В системе присутствует определенное количество запросов.
Для решения модели замкнутой СМО был выбран метод Анализа Средних Значений (MVA) [7]. MVA является интуитивно понятным и широко используемым.
Алгоритм можно упростить c помощью процедуры рекурсивного применения трех формул: расчета времени пребывания, расчета пропускной способности и вычисления длины очереди – формулы с 1 по 3 соответственно.
- Формула расчета времени пребывания:
- Формула расчета пропускной способности:
- Формула вычисления длины очереди:
Здесь i обозначает индекс блока, k - общее количество блоков, n - общее число запросов, находящихся в сети массового обслуживания. Предполагается, что требования по обслуживанию для каждого блока, Di, получены с помощью анализа псевдокода.
Время пребывания - это общее количество времени, которое запрос проводит на блоке. Это сумма времени обслуживания и времени пребывания в очереди, когда запрос ожидает обслуживания. Время пребывания на блоке задержки равно времени обслуживания, так как на эти блоки нет очереди. Под формулами расчета времени пребывания для блоков очередей понимается время, которое запрос тратит на ожидание в очереди – это накопленное время обслуживания всех запросов, которые находятся в очереди перед ним.
Формула пропускной способности выводится из Закона Литтла. Сквозное время отклика запроса, проходящего через СМО, это сумма времени, проведенного запросом на каждом блоке, которое является временем пребывания.
Средняя длина очереди для блока i, при N заявках в системе, Qi(n), это среднее количество запросов на блоке. Таким образом, формула длины очереди может быть получена из закона Литтла и Закона вынужденного потока [3].
Ссылки (англ.)
- http://www.amcc.com/products/process.html
- D. Comer, “Network Systems Design Using Network Processors,” Pearson Prentice Hall, 2004
- P. Denning and J. Buzen, “The Operational Analysis of Queueing Network Models,” Computing Survey, Volume10, Number 3, September 1978
- Intel IXP2400 Network Processor Datasheet, February 2004
- http://developer.intel.com/design/network/products/npfamily/
- D. Menasce and V. Almeida, “Capacity Planning for Web Services,” Prentice Hall PTR, 2002
- M. Reiser and S. Lavenburg, “Mean-Value Analysis of Closed Multichain Queuing Networks,” Journal of the Association for Computing Machinery, Volume 27, Number 2, April 1980
- T. Robertazzi, “Computer Networks and Systems: Queueing Theory and Performance Evaluation,” Springer-Verlag, 1990
- A. Seidmann, P. Schweitzer and S. Shalev-Oren, “Computerized Closed Queueing Network Models of Flexible Manufacturing Systems,” Large Scale Systems, Volume 12, Number 4, 1987
- L. Zhao, Y. Luo, L. Bhuyan and R. Iyer, “SpliceNP: A TCP Splicer using A Network Processor,” ACM Symposium on Architectures for Network and Communications System, Princeton, NJ, October 2005