Распределение потоков в многопоточных сетевых процессорах, основанных на однокристальных мультипроцессорах
Автор: Y.-N. Lin, Y.-D. Lin, Y.-C. Lai.
Перевод с англ.: Д.Д. Моргайлов
Источник: Lin Y.-N., Lin Y.-D., Lai Y.-C. Thread Allocation in CMP-based Multithreaded Network Processors / Y.-N. Lin, Y.-D. Lin, Y.-C. Lai // Parallel Computing. – 2010. – vol. 36 (2-3). – pp. 104-116.
1. Введение
Традиционные многопоточные-многопроцессорные архитектуры обладают тремя преимуществами: увеличение вычислительной мощности путем соединения нескольких процессорных элементов, разделение ограниченного ресурса памяти с другими элементами и формирование распределенной общей памяти, снижение накладных расходов на доступ к памяти за счет многопоточности. Однако, подсистема памяти, как правило, является узким местом системы ввиду длительных задержек доступа к ней. Современный уровень информационных технологий делает возможным расположить несколько процессоров и блоков памяти на одном чипе, что значительным образом снижает данную задержку. Такая архитектура была положена в основу многопоточных сетевых процессоров, построенных на базе однокристальных мультипроцессоров [1-3].
Хотя эта архитектура является перспективной, благодаря своей масштабируемости и расширяемости, в частности для некоторых сетевых процессоров [4-6], определение параметров архитектуры, таких как число процессоров, потоков процессора и блоков памяти, представляет собой нетривиальную задачу с учетом конкретных областей применения и показателей производительности. Кроме того, эффективная на сегодняшний день архитектура может не соответствовать требованиям ближайшего будущего в силу неравномерного развития технологий производства различных функциональных блоков. В то же время, необходимы некоторые общие рекомендации для эффективной и соответствующей целевому назначению процессора процедуры определения параметров.
Аналитические подходы широко используются во многих работах, поскольку они позволяют провести быструю оценку исследуемой системы [7]. Rafael'ем и его коллегами была предложена модель для прогнозирования производительности (с точки зрения эффективности процессора) многопоточных архитектур с различным числом потоков [8]. Эффект многопроцессорности может быть сэмулирован путем корректировки задержки при доступе к памяти, которая, предположительно, имеет геометрическое распределение. Модель обладает достаточным уровнем абстракции архитектуры, однако взаимодействие между процессорными элементами и подсистемой памяти не учитывается.
Эта проблема была устранена в [9] за счет включения в данную модель подсистемы памяти. Процессорные элементы здесь, так же, как и блоки памяти, являются распределенными и разделяемыми. Каждый поток способен выполнять полную обработку пакета и характеризуется интенсивностью обращения к локальным и отдаленным блоками памяти в процессе обработки. Тем не менее, модель не является осуществимой, так как она основана на закрытых сетях массового обслуживания. Следовательно, не рассматривается возможность приема и отправки пакетов сетевыми приложениями.
Моделирование многопоточных сетевых процессоров, построенных на основе однокристальных мультипроцессоров, рассматривается в ряде недавних работ [10-11]. В них подробно описаны параметры архитектур и проанализированы парадигмы программирования, но не уделяется достаточного внимания обсуждению вопросов распределения потоков обработки по процессорным элементам. Lakshmanamurthy и соавторы предложили методологию для анализа производительности сетевого процессора Intel IXP2400 [4]. Однако работа посвящена исключительно оценке производительности системы: не учитывается коэффициент использования процессоров и подсистемы памяти и недостаточно исследованы подходы к проектированию сетевых процессоров.
В данной работе мы стараемся представить рекомендации для дальнейшего проектирования архитектуры путем (1) разработки аналитической модели для предварительной оценки и (2) построения среды моделирования на базе сетей Петри для проверки модели и анализа результатов проектирования. Наш подход учитывает влияние памяти и очереди готовых к выполнению на процессоре потоков, что часто игнорируется в других публикациях. Хотя установлено, что аналитическая модель не является достаточно масштабируемой для проведения глубокого изучения, результаты моделирования демонстрируют интересные зависимости в проекте. Нами предложена концепция, названная Р-М соотношением, где Р и М представляют собой вычислительные нагрузки и накладные расходы на доступ к памяти, вызванные работой приложения, и выполнена оценка зависимости между различными Р-М соотношениями и соответствующим им числом потоков на процессоре. Описаны также способы устранения эффекта «узкого места», возникающего при малых Р-М соотношениях. Parsons и Sevcik [15], Zuberek и прочие [16] рассматривают аналогичные вопросы ограничений ресурса памяти и вычислительных ограничений. Несмотря на это, статистика на уровне команд, полученная с помощью реальных образцов, не используется в качестве входных параметров моделей.
Другой особенностью нашего похода является учет схемы распределения потоков. Данные схемы определяют, как потоки процессора распределены для обработки пакетов. Выбор неподходящей схемы может привести к несбалансированной загрузке процессоров. Мы сравниваем четыре возможные схемы распределения и выбираем наиболее эффективную в качестве базового допущения нашей работы. Факторы, влияющие на выбор, включают объем аппаратных ресурсов, сложность проектирования и гибкость обработки.
2. Архитектурные допущения о схеме распределения потоков
Анализу архитектуры должно предшествовать тщательное изучение различных схем распределения потоков по процессорам. В настоящее время существует четыре схемы распределения потоков, пригодных для реализации, в которых число активных потоков процессора не превышает одного. Первая предполагает, что каждый поток отвечает за полную обработку пакета. Тем не менее, маловероятно, что нагрузка по обработке распределяется по процессорам равномерно, и поддержание порядка пакетов представляет собой сложную задачу.
На рисунке 1 приведены другие две схемы: гомогенного и гетерогенного распределения. При гомогенном распределении все потоки процессора принадлежат к одному типу, например, «приемник», «планировщик», «отправитель» и так далее. Каждый поток процессора выполняет только одну стадию обработки пакета, после чего он оповещает определенный поток следующего процессора о необходимости дальнейшей обработки. Поток процессора может иметь статическое или динамическое назначение задач. Он может работать с определенным входным портом или поддерживать при необходимости другие порты. Поскольку все потоки процессора имеют один и тот же тип, такая схема характеризуется пониженными требованиями к объему памяти для команд. Тем не менее, маловероятно, что вычислительная нагрузка будет равномерно распределена по процессорам. Также сложной задачей здесь является поддержание порядка пакетов.
Данной ситуации можно избежать, используя гетерогенное распределение потоков, при котором трафик назначается на процессоры с помощью некоторого оборудования и механизмов, балансирующих загрузку. В этой схеме потоки процессора принадлежат к разным типам и, предположительно, принимают равную нагрузку при обработке пакетов. Несмотря на то, что рассматриваемая схема требует большого объема памяти для команд, чтобы поддерживать различные задачи, в настоящее время это не является проблемой, так как большинство распространенных приложений для обработки заголовков пакетов состоят по меньшей мере из 5 тысяч команд [18], которые уже поддерживаются во многих коммерческих продуктах, как Intel IPX2400 [19] и Motorola C-5 [20]. Другим достоинством схемы являются незначительные затраты на синхронизацию, так как связь между потоками осуществляется через глобальные регистры процессора. Сравнение этих двух схем приведено в таблице 1. По описанным выше причинам сделаем предположение о гетерогенном распределении в нашей модели.
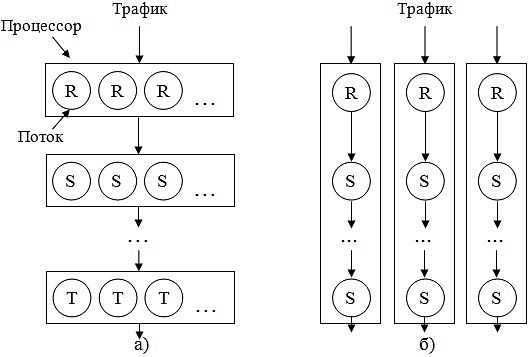
Рисунок 1 – Гомогенная (а) и гетерогенная (б) схемы распределения потоков. Число активных потоков на каждом процессоре не превышает одного
Таблица 1 – Сравнение гомогенной и гетерогенной схем
Схема распределения |
Потоки процессора |
Обработка пакетов |
Объем памяти для команд |
Балансировка загрузки |
Затраты на синхронизацию |
Гомогенная |
Одного типа |
Частичная |
Малый |
Трудновыполнима |
Высокие |
Гетерогенная |
Разного типа |
Полная |
Большой |
Легковыполнима |
Низкие |
3. Аналитическая модель
В этом разделе мы представляем приблизительный анализ архитектуры сетевого процессора с использованием непрерывных цепей Маркова. Мы определяем пространство состояний модели, получаем интенсивности переходов между ними и затем решаем модель. В дополнение к гетерогенной схеме распределения, описанной в предыдущем разделе, мы исходим из предположения о блокирующем режиме при обработке пакетов (рисунок 2). Блокирующий режим отличается от неблокирующего отсутствием буфера между двумя соседними потоками. То есть, текущий поток не может передать пакет следующему потоку, если следующий поток занят. Поскольку зачастую накладные расходы на обработку пакетов и доступ к памяти равномерно распределены между потоками, это упрощающее допущение слабо влияет на корректность модели и в то же время значительно сужает пространство состояний.
3.1. Описание состояний и определение пространства состояний
Модель состоит из I процессоров, каждый из которых содержит J потоков и разработана для оценки поведения процессоров, потоков и памяти. Чтобы это осуществить, необходимо выяснить возможные действия потоков, то есть переходы между состояниями. Они показаны на рисунке 3 и подробно рассмотрены ниже. Когда пакет поступает в свободный поток, данный поток либо помещается в очередь готовых к выполнению потоков процессора, ожидая выполнения, либо переходит в активное состояние, если в текущий момент на процессоре нет активного потока. Иногда поток запрашивает доступ к памяти, например, для работы с таблицей маршрутизации или дескрипторами пакета. После обслуживания подсистемой памяти он помещается в очередь готовых к выполнению либо вновь поступает на обслуживание, если данная очередь пуста. Обычно поток снова становится свободным после того, как пакет будет обслужен и передан следующему потоку. Однако если следующий поток занят обслуживанием пакета, текущий поток переходит в состояние «завершен».
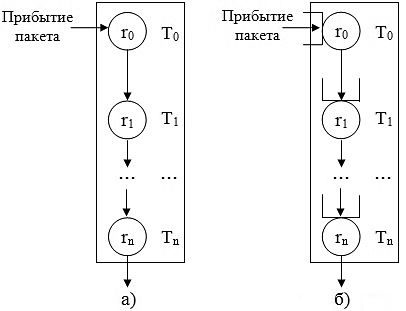
Рисунок 2 – Блокирующий (а) и неблокирующий (б) режимы обработки. Поток Ti запрашивает в ходе обработки пакета доступ к памяти с интенсивностью ri
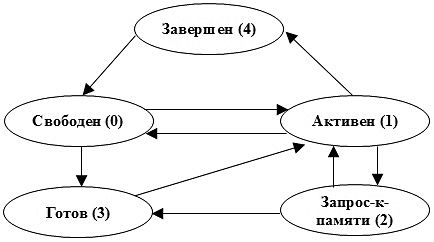
Рисунок 3 – Диаграмма состояний потока
Пространство состояний модели формально можно определить следующим образом:
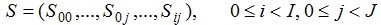
где 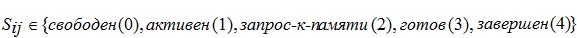 представляет собой состояние
представляет собой состояние  j-го потока i-го процессора.
Введем обозначение
j-го потока i-го процессора.
Введем обозначение  . Тогда число выполняющихся потоков и обращений к памяти будут равны соответственно |S(1)| и |S(2)|.
Определим также
. Тогда число выполняющихся потоков и обращений к памяти будут равны соответственно |S(1)| и |S(2)|.
Определим также  . Так, длина очереди запросов к памяти процессора i обозначается как |h(i)|.
Кроме того, использование дисциплины RSS (Random Selection for Service) для обслуживания очередей запросов к памяти и готовых к выполнению потоков позволило значительно уменьшить пространство состояний, не cнижая при этом корректность аналитических результатов.
Пусть (I, J) = (2, 2), тогда пространство состояний может быть получено путем исключения недостижимых состояний, которые выявляются следующим образом:
. Так, длина очереди запросов к памяти процессора i обозначается как |h(i)|.
Кроме того, использование дисциплины RSS (Random Selection for Service) для обслуживания очередей запросов к памяти и готовых к выполнению потоков позволило значительно уменьшить пространство состояний, не cнижая при этом корректность аналитических результатов.
Пусть (I, J) = (2, 2), тогда пространство состояний может быть получено путем исключения недостижимых состояний, которые выявляются следующим образом:
1. Процессор имеет более одного активного потока. Например, (1, 1, 0, 0).
2. Имеется как минимум один готовый к выполнению поток, но нет активного потока. Например, (2, 3, 0, 0). Один из готовых потоков должен перейти в активное состояние, как только предыдущий активный поток завершает свое выполнение на процессоре.
3. Sij = 4 пока Si,j + 1 = 0,  .
В этом случае Tij должен немедленно передать пакет потоку Ti,j + 1 вместо того, чтобы находиться в завершенном состоянии.
.
В этом случае Tij должен немедленно передать пакет потоку Ti,j + 1 вместо того, чтобы находиться в завершенном состоянии.
4. Si,j – 1 = 4; аналогично случаю 3. Ti,j – 1 должен немедленно передать пакет.
3.2. Построение диаграммы состояний и определение матрицы переходов
Для решения модели необходима матрица переходов. Однако чтобы определить данную матрицу, мы должны рассмотреть диаграмму состояний потоков, поскольку изменение состояния системы возникает, когда один или более потоков изменяют свое состояние. Обозначив интенсивность поступления пакетов на i-й процессора как λi, интенсивность обращения к памяти и обслуживания пакета j-ого потока как rij и 1/μij соответственно, интенсивность обслуживания заявок подсистемой памяти как m, мы может построить диаграмму состояний потока с указанием интенсивностей переходов (рисунок 4). Интенсивности обслуживания, так же, как и обращения к памяти, для потоков с одинаковым индексом на всех процессорах имеют одинаковые значения в силу гомогенного характера данных потоков. Таким образом, μij = μj и rij = rj. Интенсивность поступления пакетов на процессоры, которые также являются однородными, составляет λ пакетов в секунду.
Два дополнительных перехода (из активного состояния снова в активное и из активного состояния в состояние готовности) обнаруживаются на рисунке 3 и показаны на рисунке 4. Первый переход происходит, когда активный поток, обслужившись на процессоре, снова поступает на процессор для обработки пакета, полученного от предыдущего потока; второй переход выполняется аналогично, за исключением того, что поток не выбирается для обслуживания на процессоре, а помещается в очередь готовых к выполнению потоков.
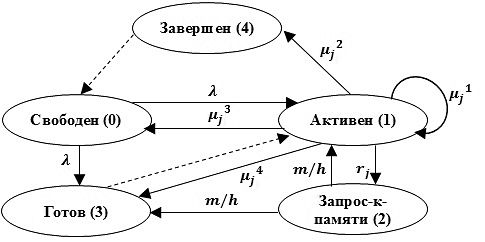
Рисунок 4 – Диаграмма состояний потока Tij. μjk = 0 или μj/n, n: число ненулевых μjk
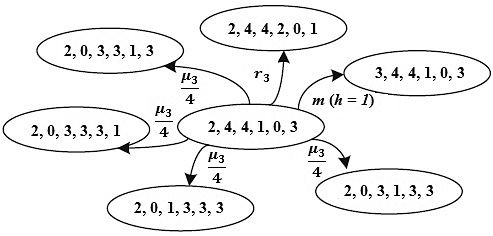
Рисунок 5 – Пример переходов для (I, J) = (1, 6)
Переходы, обозначенные на рисунке 4 пунктирной линией, не имеют интенсивности, поскольку являются подчиненными. Переход называется подчиненным, если он не инициирует изменение состояния, а возникает под действием определенного активизирующего перехода, который осуществляется другим потоком. Например, поток, завершивший обработку пакета и блокируемый следующим потоком процессора, может перейти в свободное состояние (выполнить подчиненный переход) только после того, как следующий поток завершит обработку своего пакета и передаст его далее (инициирует активизирующий переход). Также готовый к выполнению поток никогда не перейдет в активное состояние, пока активный поток не перейдет в другое состояние.
Список возможных переходов и, следовательно, матрица интенсивностей переходов могут быть определены в соответствии с диаграммой состояний. В частности, переход считается действительным, если он вызван единственным активизирующим событием, которое состоит из активизирующего перехода и возможно нескольких с ним подчиненных переходов. Для случая (I, J) = (1, 6) на рисунке 5 показан пример шести переходов. Из них четыре связаны с завершением обработки пакета, один – с обращением к подсистеме памяти (все пять переходов вызваны событием на потоке T03). Последний переход связан с завершением обслуживания в памяти потока T00. Интенсивность каждого из четырех переходов, завершающих обработку пакета, равна μ3/4, поскольку происходит случайный равновероятный выбор одного из них.
3.3 Оценка производительности с использованием аналитической модели
Показатели эффективности, которые можно получить с помощью аналитической модели, включают оценки производительности процессоров и подсистемы памяти. Эти показатели можно вычислить, зная вектор стационарных вероятностей π, полученный путем расчета непрерывной цепи Маркова. Среднее число работающих процессоров, которое называется вычислительной мощностью (Ppower) и коэффициент использования процессора – эффективность процессора (Pefficiency) можно вычислить следующим образом

Коэффициент использования памяти, или эффективность памяти (Mefficiency), число обращений к подсистеме памяти (Maccesses), число готовых к выполнению потоков на процессоре (Rlength) рассчитываются по формулам
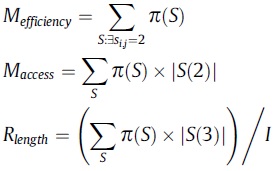
Перечень ссылок
- S. Kapil, H. McGhan, J. Lawrendra, A chip multithreaded processor for network-facing workloads, IEEE Micro 24 (2) (2004).
- A. Fedorova, M. Seltzer, C. Small, D. Nussbaum, Performance of multithreaded chip multiprocessors and implications for operating system design, in: Proceedings of USENIX’05, April 2005.
- V. Ramamurthi, J. McCollum, C. Ostler, K.S. Chatha, System level methodology for programming CMP based multi-threaded network processor architectures, in: Proceedings of International Symposium on VLSI (ISVLSI), May 2005.
- S. Lakshmanamurthy, K.Y. Liu, Y. Pun, L. Huston, U. Naik, Network processor performance analysis methodology, Intel Technology Journal 6 (3) (2002).
- Y.D. Lin, Y.N. Lin, S.C. Yang, Y.S. Lin, DiffServ edge routers over network processors: implementation and evaluation, IEEE Network Special Issue on Network Processors 17 (4) (2003) 28–34.
- G. Byrd, M. Holliday, Multithreaded processor architectures, IEEE Spectrum 32 (8) (1995).
- K. Skadron, M. Martonosi, D. August, M. Hill, D. Lilja, V.S. Pai, Challenges in computer architecture evaluation, IEEE Computer (2003).
- R. Saavedra-Barrera, D. Culler, T. Eicken, Analysis of multithreaded architectures for parallel computing, in: Proceedings of the Second Annual ACM Symposium on Parallel Algorithms and Architectures, 1990.
- S.S. Nemawarkar, R. Govindarajan, G.R. Gao, V.K. Agarwal, Analysis of multithreaded multiprocessor architectures with distributed shared memory, in: Proceedings of the Fifth IEEE Symposium on Parallel and Distributed Processing, Dallas, 1993, pp. 114–121.
- M. Franklin, T. Wolf, A network processor performance and design model with benchmark parameterization, in: Network Processor Workshop in conjunction with Eighth International Symposium on High Performance Computer Architecture, February 2002.
- T. Wolf, J.S. Turner, Design issues for high-performance active routers, IEEE Journal on Selected Areas in Communications 19 (3) (2001).
- M. Gries, C. Kulkarni, C. Sauer, K. Keutzer, Comparing analytical modeling with simulation for network processors: a case study, in: Proceedings of the Design, Automation, and Test in Europe (DATE), 2003.
- P. Crowley, M. Fiuczynski, J.-L. Baer, On the Performance of Multithreaded Architectures for Network Processors, UW Technical Report, October 2001.
- P. Crowley, J.-L. Baer, A modeling framework for network processor systems, in: Network Processor Workshop in Conjunction with Eighth International Symposium on High Performance Computer Architecture, February 2002.
- E.W. Parsons, K.C. Sevcik, Coordinated allocation of memory and processors in multiprocessors, in: Proceedings of SIGMETRICS’96, May 1996.
- W.M. Zuberek, R. Govindarajan, F. Suciu, Timed colored Petri net models of distributed memory multithreaded multiprocessors, in: Proceedings of Workshop on Practical Use of Colored Petri Nets and Design/CPN, Aarhus, Denmark, June 1998.
- W. Bux, W.E. Denzel, T. Engbersen, A. Herkersdorf, R.P. Luijten, Technologies and building blocks for fast packet forwarding, IEEE Communications Magazine (2001).
- R. Ramaswamy, T. Wolf, PacketBench: a tool for workload characterization of network processing, in: Proceedings of Sixth IEEE Annual Workshop on Workload Characterization, 2003.
- Intel IXP2400 Network Processor. http://www.intel.com/design/network/products/npfamily/.
- Motorola C-5 Network Processor. http://e-www.motorola.com/.