
Abstract
Content
- Introduction
- 1. Theme urgency
- 2. Goal and tasks of the research
- 3. A review of research and development
- 4. Conclusion
- References
Introduction
Data preprocessing is an essential step, the quality of the execution of which depends the possibility of obtaining qualitative results of the whole process of data analysis.If you need to use a neural network techniques to solve specific problems, the first thing with which to face - is the training data. Typically, when different neyroarhitektur description, assume that the default training data is available and presented in a form accessible to the neural network. In practice, it is pre-processing stage can be the most time-consuming part of the neural network analysis [5]. According to some estimates, the preliminary stage of data processing can take up to 80%[2] all the time allotted for the project. The success of the neural network learning may also crucially depend on the form in which information is presented for its training.Actually, the pre-processing of data allows both to improve the quality of data mining, as well as improve the quality of the data itself.
1. Theme urgency
One of the predictions necessary, and therefore the relevance, increasing the quality of data made Duffy Brunson[4] (Duffie Brunson) reads as follows: Prediction. Many companies have begun to pay more attention to the quality of the data , as poor data quality costs money in the sense that it leads to lower productivity , making wrong business decisions and the inability to get the desired result, and also makes it difficult to meet the requirements of legislation. Therefore, the company does intend to take specific actions to address data quality issues .
reality . This trend has continued , especially in the financial services industry. This primarily applies to businesses who are trying to implement the agreement Basel II. Poor quality data can not be used in systems of risk assessment , which are used to set prices for loans and computing needs of the organization in the capital . It is interesting to note that significantly changed views on ways to address the problem of data quality. Initially, management focuses on quality assessment tools , assuming that the owner
of the data must address the problem at the source , for example , clearing data and retrain employees. But now, their views have changed significantly. The concept of data quality is much broader than just their accurate introduction to the first stage. Today, many already know that the quality of data should be provided processes to extract, transform and load (extraction, transformation, loading - ETL), as well as receive data from sources that prepare the data for analysis.
2. Goal and tasks of the research
The purpose of this paper is to implement the algorithm and software training data for later analysis and neural network forecasting.
Main tasks:
- Explore methods of data processing.
- Choose a combination of methods to implement the algorithm of data preparation.
- Explore the literature on the preparation of the preliminary data.
- Implement the learned methods of data preparation in a software project.
3. A review of research and development
3.1 Maximization of entropy
Information content of each field/parameter data in the problem, should be maximum [8]. Consequently, one can argue about the need to maximize the entropy to increase the probability of a correct prediction and classification.
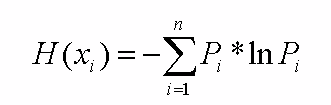
where xi – the state of some of the field/parameter data, Pi – the probability of this state, n – the number of such states.
Such pretreatment is designed to encode the data inputs-outputs of neural networks, as they are perceived only numerical information [1].
3.2 The normalization of the data
Obviously, the results of neural network modeling should not depend on the units of measurements. Hence, it can be argued that to improve the quality and speed of neural network training, there is the need to bring the data to a single scale by normalizing the data.Conversion of data to a single scale is provided by normalizing each variable on the range of variation of its values. In its simplest form it is - a linear transformation:
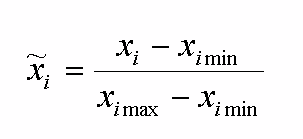
where xi – selected state of the field/parameter data, xi max – maximum state of the field/parameter data, xi min – the minimum condition of the field/parameter data.
3.3 Decrease the dimensions of inputs
There are two types of algorithms:
- selection of the most informative features and their use in the process of training a neural network (in this case, the most appropriate would be to use a genetic algorithm to select the most informative features, but the variant with the assessment, according to the feature vectors, the distance between the stochastic probability distributions);
- encoding source data fewer variables, but possibly containing all information stored in the source data (principal component analysis[7] using a neural network).Was chosen method of principal component analysis using a neural network in a general form looks like this:
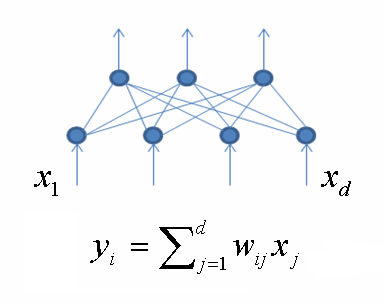
where yi – output from the i-th neuron of the inner layer, wij – network weights between input and output layers, xj – component input vector.
3.4 An algorithm for constructing a classifier based on neural networks[3]
- Data handling
- Compile a database of examples specific to the task.
- Smash all the data into two sets: training and testing (possibly splitting into three sets: a training, testing and confirmation).
- Preprocessing
- Select system features for the given task and convert the data appropriately to feed the input of the network (the normalization, standardization, etc.). As a result, it is desirable to obtain a linear discharge space of the set of samples.
- Select a coding system output values (classic encryption, 2 2 coding etc.).
- Design, training and assessment of the quality of the network.
- Select network topology: the number of layers, the number of neurons in the layers, etc.
- Select the activation function of neurons (eg,
sigmoid
). - Select the network learning algorithm.
- Assess the quality of the network on the basis of confirmation of the set or other criteria, to optimize the architecture (reduced weight, thinning feature space).
- Stop at the option of the network that provides the best ability to summarize and evaluate the quality of the work on the test set.
- Usage and diagnostics
- Determine the degree of influence of various factors on the decision makers (heuristics).
- Verify that the network provides the required classification accuracy (number of correctly detected few examples).
- If necessary, return to step 2, change the way the sample or changing the database.
- Virtually use the network to solve the problem.

Figure 1 - Model prediction/classification in the general form[6]
(animation: 7 frames, 5 cycles of repetition, 137 KB)
4. Conclusion
To perform the tasks of the provisional data, allowing faster and better solve the problems of classification and prediction methods have chosen the following data: the maximization of entropy, individual normalization of data, reducing the dimensionality of inputs trained network by the method of principal component analysis. Selected algorithm for constructing a classifier based on the use of neural network.References
- Ежов А.А., Шумский С.А. Нейрокомпьютинг и его применение в экономике и бизнесе – М. 1998г., c. 126-145
- Курс лекций по Data Mining, Чубукова И. А., Соискатель ученой степени кандидата экономических наук в Киевском национальном экономическом университете имени Вадима Гетьмана, кафедра информационных систем в экономике, ведущий инженер-программист в Национальном банке Украины, c. 206-214
- Применение нейронных сетей для задач классификации / Интернет ресурс – Режим доступа: http://www.basegroup.ru
- Десять основных тенденций 2005 года в области Business Intelligence и Хранилищ данных Интернет ресурс – Режим доступа: http://citforum.ru
- Великие раскопки и великие вызовы / Интернет ресурс – Режим доступа: http://www.kdnuggets.com
- Барсегян А.А., Куприянов М.С., Степаненко В.В., Холод И.И. - Технологии анализа данных. Data Mining, Visual Mining, Text Mining, OLAP (2-е издание) с. 90-94
- Прикладная статистика: Классификация и снижение размерности: Справ. Изд. / С. А. Айвазян, В. М. Бухштабер, И. С. Енюков, Л. Д. Мешалкин; Под ред. С. А. Айвазяна. – М.: Финансы и статистика, 1989. – 607с.: ил. с. 339
- Технология Data Mining: Интеллектуальный Анализ Данных, Степанов Р. Г. – Казань, 2008. – c. 14