Автоматический краткосрочный прогноз солнечных вспышек с использованием машинного обучения и объединений солнечных пятен
Авторы: R. QAHWAJI and T. COLAK
Название в оригинале: Automatic Short-Term Solar Flare Prediction Using Machine Learning And Sunspot Associations
Перевод: Н.А. Прокопчук
Источник(англ): Solar Physics, 241,pp. 195-211, 2007,
http://spaceweather.inf.brad.ac.uk/library/publications/solarphysic1
Аннотация
R. QAHWAJI and T. COLAK Автоматический краткосрочный прогноз солнечных вспышек с использованием машинного обучения и объединений солнечных пятен.В этой статье представлено машинное обучение на основе системы, которая могла обеспечить автоматизированные краткосрочные предсказания солнечных вспышек. Проведено сравнение алгоритмов машинного обучения.Эта система принимает два набора входных параметров: McIntosh классификации групп солнечных пятен и данные солнечного цикла. Для того чтобы установить связь между солнечными вспышками и группами пятен, система исследует общедоступные солнечные каталоги из Национального геофизического центра данных (NGDC), чтобы связать пятна с соответствующими вспышками в зависимости от их сроков и NOAA номера. Классификация McIntosh для каждого соответствующего пятна извлекается и преобразуется в цифровой формат, который подходит для алгоритмов машинного обучения. С помощью этой системы мы стремимся предсказать определенный класс солнечных пятен в определенное время, для получения значительной вспышки в течение шести часов и является ли эта вспышка X или M класса. Был проведен сравнительный анализ алгоритмов машинного обучения, таких как Каскад-корреляция нейронных сетей (ГЦЯН), метод опорных векторов (SVM) и радиальные базисные функции сети (RBFN), и чтобы определить алгоритм обучения, которые обеспечит наилучший прогноз производительности. Сделан вывод, что SVM обеспечивает наилучшую производительность для прогнозирования, и предсказывает, будет ли вспышка или нет на основе McIntosh классификации, но ГЦЯН больше способна предсказать класс предстоящей вспышки. Предлагается в будущем использовать гибридную систему, которая сочетает в себе SVM и ГЦЯН.
Введение
Солнечная активность является движущей силой космической погоды. Таким образом, важно, быть в состоянии предсказать сильные извержения, такие как выбросы корональной массы (CME) и солнечные вспышки (Коскинен и соавт., 1999).Для эффективного прогнозирования космической погоды, система должна анализировать последние солнечные данные и предоставлять надежный прогноз предстоящей солнечной активности, и ее возможное воздействие на Землю. Космическая погода определяется американской космической Национальной метеорологической программой (NSWP) как условия на Солнце, солнечного ветра, магнитосферы, ионосферы и термосферы, которые могут влиять на производительность и надежность космических и наземных технологических систем и могут создать угрозу жизни или здоровью человека
. Важность понимания космической погоды растет по двум причинам. Первая причина: солнечная активность влияет на жизнь на Земле. Вторая: мы больше и больше полагаемся на связь и энергетические системы, которые являются уязвимыми к космической погоде.
Прогнозирование космической погоды является новой наукой, которая сталкивается со многими проблемами. Одной из этих проблем является автоматизация процесса определения классификации и представления солнечной функций, установление точной корреляции между проявлениями солнечной активности (например, солнечных вспышек и CME) и солнечной функцией (например, солнечных пятен, нитей и активных областей) наблюдаемых в различных длинах волн.
Для прогнозирования солнечной активности мы должны использовать высокое качество данных и методы обработки данных в режиме реального времени (Ван и соавт., 2003). Исследования солнечных вспышек показало, что вспышки в основном связаны с пятнами и активными областями (Лю и др., 2005;. Зирин и Лиггетт, 1987; Ши и Ван, 1994). В данной работе мы стремимся разработать автоматизированную систему, которая использует алгоритмы машинного обучения для обеспечения эффективного краткосрочного прогнозирования значительных вспышек. Подготовка алгоритмов машинного обучения основана на сопоставлении пятен с соответствующими вспышками и на численное моделирование солнечного цикла. В ближайшем будущем мы намерены расширить работу, представленную в данной статье и объединить ее с автоматизированием алгоритмов обработки изображения, который будет анализировать изображения Солнца в режиме реального времени. Солнечные функции будут извлечены и классифицированы в режиме реального времени, и будут подаваться в алгоритм машинного обучения, чтобы в режиме реального времени автоматизировать краткосрочное прогнозирование солнечных вспышек.
В последнее время обработкой солнечных изображений и автоматическим обнаружением различных солнечных особенностей, занимались такие ученные: Гао и др.. (2002), и др. Turmon. (2002), Ши и Ковальский (2003), и др. Benkhalil. (2003), Лефевр и Rozelot (2004) и Qahwaji и Colak (2006a). Несмотря на последние достижения в области солнечных изображений, машинного обучения и интеллектуального анализа данных, они не были широко применены для солнечных данных. Тем не менее, не существует алгоритма машинного обучения, что, как известно, обеспечивает лучшее
обучение производительности, особенно в солнечной области. Одна из первых попыток прогнозирования солнечной активности была зарегистрирована в Кальво соавт. (1995). Однако, в Кальво и др.. (1995), солнечная активность была представлена с точки зрения чисел Вольфа, а не в плане вспышек или КВМ. Методы визуализации, использующиеся для солнечных функции распознавания были представлены в Жаркова и др.. (2005) Борда и соавт. (2002). Они описали метод автоматического обнаружения солнечных вспышек с использованием многослойного персептрона (MLP) с обратным распространением правил подготовки и использовали технику контролируемого обучения, которая требует большого количества итераций. Цюй соавт. (2003) сравнивал эффективность сепарации для функций, извлеченных из солнечных вспышек с помощью радиальной базисной функции сети (RBFN), методом опорных векторов (SVM) и MLP методами. Каждая вспышка представлена с использованием девяти особенностей. Однако эти возможности не дают никакой информации о положении, размерах и классификации солнечных вспышек. Нейронные сети (NNs) использовавшиеся в Жаркова и Щетиниа (2003) для ламп накаливания используются и в работах Qahwaji и Colak (2006a) для солнечных изображений. NNs были использованы после сегментации изображений для проверки регионов, представляющих интерес.
Существует также ряд работ о корреляции между классификацией солнечных пятен, бликов явлений и предсказаний. В NOAA Space Environment лаборатории разработана экспертная система, которая называется ТЕО (McIntosh, 1990). Она использует факельные группы пятен классифицированные по схеме Макинтош, динамические свойства солнечных пятен роста, вращение, сдвиг и предыдущую вспышечную активность, полученную в течении 24 часов, для рентгеновских вспышек класса Х. Система была субъективной, потому что прогнозирование основывалось на решении человека-эксперта и не была оценена статистически. В Самис соавт. (2000), описано восьмилетнее наблюдение активного региона от ВВС США / Маунт Вилсон набора данных, поставляемых NOAA Мировым центром данных, для изучения связи между пятнами и большими вспышками. Они подтвердили Kоnzel (1960) с выводами, что регионы классифицирующиеся как регионы производящие все больше и больше вспышек, чем другие регионы сопоставимого размера. В частности, они пришли к выводу, что каждый регион больше, чем 1000/1000000 полушария и классифицирующийся, как регион, котрый дает с вероятностью 40% прогноз вспышки класса X1 или даже больше. Борнман и Шоу (1994) использовали линейный регрессивный анализа для получения эффективных солнечных взносов засветкой каждого Макинтош параметра классификации. Они пришли к выводу, что первоначальные семнадцать параметров в Макинтош Классификации могут быть уменьшены до десяти и до сих пор воспроизводить наблюдаемые скорости вспышки. Галлахер и др. (2002) предложил способ нахождения сжигания вероятность активной области в данный день, используя статистику Пуассона и исторические средние вспышки номеров для классификации Макинтош. Ведланд (2004) ввел байесовский подход к предсказанию вспышки. Этот подход может быть использован для улучшения или измельчения исходного предсказания большой вспышки в течение последующего периода времени с использованием сжигания запись активной области вместе с феноменологическими правилами вспышечной статистики. Этот метод был протестирован на ограниченном наборе данных (то есть, десять дней сжигание), но автор сделал интересные моменты о том, как он может быть адаптирован для обработки данных в реальном времени. Совсем недавно Тернулло соавт. (2006) представил статистический анализ, который проводился путем сопоставления группы пятен данных, собранных на INAF-Катания, астрофизической обсерватории с данными M-и Х-класса вспышек получены GOES-8 спутником в мягком рентгеновском диапазоне в период с января 1996 года по июнь 2003 года. Было установлено, что сжигание вероятности солнечных пятен увеличивается незначительно с возрастом пятен и как сжигание пятна имеют более длительное время жизни по сравнению с не-те сжигания. Эти предыдущие работы показали, что существует четкая корреляция между солнечной классификацией и сжиганием вероятности. Тем не менее, эта связь не была проверена на крупномасштабных данных с помощью автоматизированных алгоритмов машинного обучения. В этой работе, мы стремимся создать полностью автоматизированную систему, которая может проанализировать все эти данные о вспышках и солнечных пятен за последние четырнадцать лет, чтобы изучить степень корреляции и обеспечить точное предсказание с использованием данных временных рядов. Работы, представленные в данной статье, являются первым шагом на пути к строительству в реальном времени, автоматизированных, веб-совместимых систем, позволяющих извлекать последние изображения Солнца в режиме реального времени и обеспечивать автоматизированный прогноз больших вспышек за 6 часов. Эта статья организована следующим образом: солнечные данные, используемые в настоящем документе описаны в разделе 2. Машинное обучение алгоритмов, обсуждается в разделе 3. Внедрение системы и экспериментальные результаты приведены в разделе 4. Наконец, заключительные замечания приведены в разделе 5.
Данные
В этой работе мы использовали данные из общедоступных Каталога групп солнечных пятен и Каталога солнечных вспышек. Оба каталога предоставлены Национальным геофизическим центром данных (NGDC). НЦГД ведет учет данных из нескольких обсерваторий во всем мире и занимает одну из наиболее полных общедоступных баз данных для солнечных функции. Вспышки классифицируют в соответствии с их рентгеновской яркостью в диапазоне длин волн от 7:59 ангстрем. C, M, X класс вспышки может повлиять на Землю. Вспышки С-класса - умеренные вспышки с несколькими заметными последствиями на Земле (т.е. незначительные геомагнитные бури). M-класса вспышки -большие, они обычно вызывают краткое отключение радио, которые влияют на Землю в полярных регионах, вызывая основные геомагнитные бури. X-класса вспышки могут вызвать по всей планете перебои в радиосвязи и являются источником длительного излучения. НЦГД Каталог вспышки (рис. 1) содержит информацию о датах, времени начала и окончания для вспышки извержений, местоположение, рентгеновские классификации, а число NOAA для активных областях, которые связаны с обнаруженными вспышек. Каталог НЦГД солнечных пятен (рис. 1) содержит записи многих солнечных обсерваторий мира, которые отслеживали пятна регионов и поставляющих свою дату, время, место, физические свойства и классификации. Две системы классификации существуют для пятен: Макинтош и Mt. Уилсон. Макинтош Классификация зависит от размера, формы и плотности в месте пятен, в то время как Mt. Wilson классификации (Хале и соавт., 1919) основана на распределении магнитных полярностей в месте групп (Greatrix и Curtis, 1973). В этом исследовании мы использовали классификацию Макинтош, которая является стандартным для международного обмена солнечных геофизических данных. Она представляет собой модифицированную версию системы Цюрих классификацию, разработанную Вальдмайер. Эти два каталога анализируются в компьютерной программе, которую мы создали для того, чтобы связать пятна с соответствующими вспышками с использованием их времени и информации о местоположении. Эта компьютерная программа предоставляет обучение и тестирование наборов данных для алгоритмов машинного обучения с помощью этих ассоциаций. Более подробная информация представлена в программе и наборах данных в разделе 4.
Алгоритмы машинного обучения
В этой работе, используются и сравниваются для предсказания вспышки алгоритмы: Каскад-корреляция нейронных сетей (ГЦЯН), метод опорных векторов (SVM) и радиальные сети базисной функции (RBFN). ГЦЯН и RBFN используются из-за их эффективной работы в приложениях, связанных с классификацией и прогнозированием временных рядов (Frank и др.., 1997). В нашей предыдущей работе Qahwaji и Colak (2006b) выполняли несколько Н.Н. топологий и алгоритмов обучения, был сделан вывод, что ГЦЯН обеспечивает лучшую связь между солнечными вспышками и пятнами классов. Это одна из последних тенденций в области машинного обучения, чтобы сравнить производительность SVM и нейронных сетей. Работа, о которой в ACIR и Guzelis (2004), Pal и Mather (2004), Хуанг и др.. (2004), и др. Расстояние. (2003), хотя и не связанные с предсказанием солнечной активности, показали, что SVM выиграли у нейронных сетей в задачах классификации для различных приложений. Аналогичные показатели для SVM были зарегистрированы для обнаружения вспышек в Ку и др.. (2003), где статистические функции были извлечены из изображений Солнца и были обучены использованию MLP, RBFN и SVM для автоматического обнаружения вспышек. Многие существующие ссылки, такие, как Цюй соавт. (2003), подробно описывают для SVM и РФБ. Однако то же самое нельзя сказать о ГЦЯН, поэтому мы решили предоставить более подробную информацию для ГЦЯН.
3.1. КАСКАД-корреляционная нейронная сеть (ГЦЯН)
Подготовка обратного распространения нейронных сетей считается медленным из-за размера шага и проблемы подвижной мишени (Fahlmann и Lebiere, 1989). Для преодоления этих проблем в каскад нейронных сетях. Топологию в этих сетях не зафиксировано. Контролируемое обучение начинается с минимальной топологии сети. Новые скрытые узлы постепенно добавляют для создания многослойной структуры. Новый скрытый узел добавляется к максимальной величине корреляции между выходом нового узла и остаточным сигналом ошибки. Вес каждого нового скрытого узла является фиксированными и не изменен позже, следовательно, делает его постоянным элементом детектора в сети. Эта функция детектора может давать результаты, или создать другие, более сложные функции детекторов (Fahlmann и Lebiere, 1989).
В ГЦЯН, количество входных узлов определяется на основе входных функций, а число выходных узлов определяется в зависимости от количества различных классов выходов. Обучение ГЦЯН начинает без скрытых узлов. Непосредственный ввод-вывод соединений обучается с использованием всей обучающей выборки с помощью алгоритма обучения обратного распространения. Скрытые узлы добавляют постепенно, и каждый новый узел подключен к каждому входному узлу из уже существующих скрытых узлов. Обучение осуществляется с использованием вектора обучение и веса новых скрытых узлов, который корректируется после каждого прохода (Fahlmann и Lebiere, 1989).
Тем не менее, одной из основных проблем, стоящих перед этими сетями является более облегающие обучающих данных, особенно при работе с реальными проблемами (Smieja, 1993). С другой стороны, Каскад-корреляционная архитектура имеет несколько преимуществ. Во-первых, она очень быстро учится, по крайней мере в 10 раз быстрее, чем с обратным распространением ошибки алгоритмов (Shet соавт., 2005). Во-вторых, сеть определяет свои размеры и топологию и она сохраняет структуры даже если она создала обучающий набор изменений (Fahlmann и Lebiere, 1989). В-третьих, она не требует обратного распространения ошибки сигнала через связи сети (Fahlmann и Lebiere, 1989). Наконец, эта структура полезна для инкрементного обучения, при которой новая информация добавляется к уже обученной сети (Shet соавт., 2005).
3.2. Метод опорных векторов (SVM)
SVMs становятся мощным инструментом для решения разнообразных проблем оценки функции. По сравнению с нейронными сетями, SVMs имеет твердую статистическую основу и гарантированно сходится к глобальному минимуму во время тренировки. Предполагается, что SVM есть обобщение лучшей возможности, чем нейронные сети. Это было описано в ряде приложений (Ку и др., 2003;. ACIR и Guzelis, 2004; Pal и Mather, 2004; Huang и др., 2004;.. Расстояние др., 2003). SVM является алгоритмом обучения, который основан на статистической теории обучения. Он был разработан Вапником (1999) и использует структурный принцип минимизации риска. Получив на входе вектор, SVM классифицирует его в один из двух классов. Это делается путем поиска оптимальной разделяющей гиперплоскости, которая обеспечивает эффективное разделение для данных и максимальную маржу, т.е. максимизирует расстояние между ближайшими векторов в обоих классах в гиперплоскости. Это, конечно, с предположения, что данные линейно разделимы. Для случая, когда данные не линейно разделимы, SVM будет преобразовывать данные в пространство более высокой размерности функцию, где данные могут стать линейно разделимы. Это делается с помощью функции ядра. Более подробная информация о SVM можно найти в Цюй соавт. (2003) и Вапник (1999)
3.3. Радиальные базисные функций сети (RBFN)
RBFN мощные методы интерполяции, которые могут быть эффективно применены в многомерном пространстве. RBFN подход к классификации основан на кривой. Обучение достигается при многомерной поверхности, что может обеспечить оптимальное разделение многомерных данных обучения. В общем, RBFN может моделировать непрерывные функции с достаточной степенью точности. Радиальные базисные функции представляют собой набор функций, предоставляемых скрытых узлов, представляющих собой произвольный набор входных сигналов (Qu соавт., 2003). Подготовка RBFN обычно проще и короче по сравнению с другими NNs. Это одно из основных преимуществ использования RBFN. Тем не менее, требуется большие вычисления и хранения классификации входных параметров, когда обучается сеть (Sutton и Барто, 1998). RBFN применяет смесь контролируемых и неконтролируемых форм обучения. Слой из входных узлов невидимых узлов без присмотра, в то время как обучение с учителем существует в слое от скрытых узлов для вывода узлов. Нелинейное преобразование существует от входа до скрытых пространств, а линейное преобразование существует со скрытым к выходу пространством (Bishop, 1995). Подробнее по теории и реализации RBFN можно найти в Цюй соавт. (2003) и Саттон и Барто (1998)
4.Внедрение и результаты.
Как показано ранее, на C ++ была создана платформа для доступа к каталогам солнечных пятен и вспышек и автоматически связывающая все вспышки Х и М класса с соответствующими группами пятен. Переписка была определена на основе расположения (т.е. столько же NOAA) информации о синхронизации (максимум шесть часов разницы во времени между вспышкой и временем извержения, за которое классифицируются соответствующие группы пятен). После обнаружения всех ассоциаций, создаются численные данные для алгоритмов машинного обучения. Весь процесс описан в следующих этапов:
- Разбор вспышки НЦГД данных из мягкого рентгеновского каталога вспышки
- Разбор группы пятен данных из каталогов НЦГД солнечных пятен.
- потребление ресурсов;
- быстродействие.
- ОС – Windows XP x64 edition
- Процессор – AMD Athlon 64 1.6GHz
- ОЗУ – DDR2 4 Гб
Если X-или M-вспышка класса найдена, то пытаемся определить связанные пятна следующим образом:
Если число вспышечной NOAA указано в каталоге, то проводим поиск по каталогу солнечных пятен, чтобы найти группы пятен с соответствующим числом NOAA с вспышкой.
Найти разницу во времени между моментом вспышки и извержением извлеченного времени пятна. Если разница во времени составляет менее шести часов, то запись бликов и пятен записи помечаются как связанные. Если есть более одного протокола классификации для вспышки связанной группы солнечных пятен в течение шести часов, то выбираем с минимальной разницей времени.
Получаем группы пятен, которые не связаны с любой вспышкой. Если ни одной солнечной вспышки в любом месте на Солнце не происходит в течение одного дня после классификации этой группы солнечных пятен, то она помечается как несвязанные. Производится запись всех связанных с ней групп и соответствующих им классов вспышке.
Запись несвязанных групп.
Создание наборов данных с использованием Макинтош классов групп и классов вспышки (табл. I).
Из рис.3 видно, что в среде Simulink эта запись занимает всего 1 блок Fcn. В этом блоке находится наша функция, которая записана математическим выражением (2).
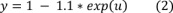
4.1 Создание начального набора данных
Нам необходимо определить соответствующие численные представления для связанных и несвязанных групп, которые были извлечены ранее, потому что большинство алгоритмов машинного обучения имеют дело с цифрами. Это означает, что мы должны преобразовать классификации Макинтош каждого пятна с соответствующим числовым значением. Для этого мы вернемся к основам классификации Макинтош которая представляется как кондитерская фабрика, как объяснялось ранее. Есть семь классов в соответствии с частью Z классификации (например, A, B, C, D, E, F, H), шесть классов в соответствии с частью р (т. е. X, R, S, A, H, K), а также четыре класса в соответствии с частью с (т. е. X, O, I, C). Таким образом, три числовых значения используются для представления каждой группы солнечных пятен. Чтобы найти эти значения классификации McIntosh для группы пятен, разделим на три составляющие класс заказ, деленное на общее количество классов для каждого компонента. Что касается вспышки, то используются два числовых значения. Первое значение представляет значительная ли вспышка происходит или нет. Это значение становится 0,9, если значительная вспышка происходит в противном случае оно составляет 0,1. Кроме того, если вспышка класса X-вспышки, оно представлено на 0,9 и если это M-вспышка класса, она представлена 0,1. Численные преобразования наборов данных объясняются более подробно в таблице I.
В этой работе, мы обработали все данные солнечных пятен и вспышек на период с 01 до 31 Jan1992 декабре 2005. Наше программное обеспечение проанализировало данные, относящиеся к 29 343 110 241 вспышек и группы пятен и сумело связать 1425 X-или M-класса вспышек с соответствующими группами пятен. В завершение нашего набора данных мы обработали НЦГД каталоги и снова выбрали 1457 несвязанных групп пятен на основе правил, упомянутых ранее. Таким образом, общее число выборок, используемых для наших обучающих и проверочных наборов для машинного обучения составляет 2882.
Стоит упомянуть, что общее число зарегистрированных X-или M-класса вспышек в каталогах НЦГД -1870 что на 6,3% от общего числа вспышек в этом каталоге. Тем не менее, из этих 1870 вспышек, только 1425 вспышки имеют NOAA номера и включены в наше исследование. Веронинг соавт. (2002) сообщил, около 10% всего мягкого рентгеновского излучения X-или M-класса на основе изучения всех вспышек в период между 1976 и 2000 годами. Сравнивая эти результаты с нашим показывает, что существует разница 3,7%. Данные, используемые для Веронинг соавт. (2002) является более всеобъемлющим, так как состоят из 24 лет данных с трех солнечных максимумов, в то время как мы извлекли все доступные НЦГД данные, только за 14 лет и только с одного солнечного максимума. Веронинг соавт. (2002) сообщил, что М-и X-класса вспышки происходят реже главным образом в период максимума солнечной активности
, который может объяснить 3,7% разницу между двумя выводами.
4.3 Начальная подготовка и тестирование
4.3.1. Техника складного ножа
Для нашего исследования, тестирования экспериментов проводятся с помощью техники складного ножа (Фукунага, 1990). Этот метод обычно реализуется для обеспечения правильной статистической оценки для выполнения классификатора при реализации на ограниченное число образцов. Этот метод делит полное число выборок на две группы: набор обучение и тестирование множества. Практически, генератор случайных чисел решает, какие образцы используются для обучения классификатора и какие для его проверки. Классификация ошибки в основном зависит от обучения и тестирования образцов. Для конечного числа проб, ошибка процедуры подсчета может быть использована для оценки производительности классификатора (Fukunaga, 1990). В каждом эксперименте 80% образцов были выбраны случайным образом и используются для обучения, а остальные 20% использовали для тестирования. Таким образом, число обучающей выборки 2305, в то время как 577 образцов используют для тестирования классификатора.
4.3.2. Начальное обучение и тестирование
Чтобы проверить пригодность наших данных для предсказания солнечных вспышек, мы начали наши эксперименты с обучения и тестирования ГЦЯН с нашим начальным набором данных. Этот набор данных делится на входы и выходы, как описано в разделе 4.2. Если входные параметры для нашего обучения
состоят из трех численных значений, представляющие классификации Макинтош пятна. Выходной набор состоит из двух узлов, представляющих, произойдет ли вспышка и является ли это X-или M-вспышка класса. Несколько экспериментов, основанных на техники складной нож, были проведены, и мы обнаружили, что предсказание скорости для вспышек в лучшем случае составило 72,9%. Это показывает, что существует связь между входным и выходным наборов, но это не является основанием для обеспечения надежного прогнозирования солнечной активности. Вскоре стало очевидно, что наши обучающие данные не позволяет классификатору создать точную дискриминацию между входными и выходными данными. Мы пришли к выводу, что использование классификации Макинтош по себе недостаточно, и более разборчивыми данные должны быть добавлены к входным данным. Таким образом, мы решили связать объявление пятен с циклом солнечных пятен. Новый ввод вычисляется путем нахождения времени пятна по отношению к солнечному циклу. Наше решение включает информацию о времени, казалось, подтверждается тем фактом, что подъем и падение солнечной активности совпадает с солнечным циклом (мазок и соавт., 1990), а также тем, что М-и X-класса вспышки в основном происходят во время максимума солнечной активности (Веронинг соавт., 2002). Когда солнечный цикл является максимальным, достаточно в большой активной области обнаруживаются многие вспышки. Количество активных областей уменьшается по мере приближения к минимальной части своего цикла (мазок и др.,. 1990). Подробная информация представлена в разделе для подражания.
4.3.3. Солнечный цикл
Для определения связи между секретной группой солнечных пятен и их расположение на солнечном цикле, важно использовать математическую модель, которая может моделировать поведение солнечного цикла. Модель введена Хэтэуэй и др.. (1994), которая показана в уравнении (1), может служить этой цели. Это уравнение позволяет оценить числом солнечных пятен для любой заданной даты, и это позволяет прогнозировать будущие значения, а также.
(1) Уравнение Хэтэуэй
В уравнении (1), параметр а
представляет амплитуду связанную с ростом цикла минимума, б
относится к времени в месяцах от минимального до максимального, с
дает асимметрию цикла, а также t
обозначает время начала. Более подробную информацию о выводе уравнения (1) можно найти в Хэтэуэй и др.. (1994).
Чтобы убедиться в правильности этой модели мы применили эту модель для даты, начиная с 1 января 1992 до 31 декабря 2005. С помощью нашего программного обеспечения, мы извлекли солнечные пятна за тот же период и обнаружили фактическую среднюю ежемесячного числа солнечных пятен. Это значение показано на рисунке 2. Сравнивая оба участка, очевидно, что модель Хэтэуэй обеспечивает надежное моделирование для взлета и падения солнечного цикла. Альтернативный способ для имитации солнечного цикла может быть модель NN введен Calvo соавт. (1995). Стоит отметить, что Лантос (2006) показал, что все методы предсказания солнечного цикла дают, по крайней мере для одного из циклов, ошибки больше, чем 20%, особенно когда циклы 13 до 23 считаются. Хотя модель Хэтэуэй представляет эволюцию солнечного цикла несколько грубо, мы использовали эту модель из-за ее легкой реализации для существующих и будущих солнечных циклов. Кроме того, модель Хэтэуэй обеспечивает автоматизированное численное моделирование поведения солнечного цикла, которое может быть использовано для изучения прошлого, настоящего и будущего развития цикла. Это особенно важно для любой автоматизированной системы предсказания, как определенная группа солнечных пятен классов, более вероятно, вспышки в определенное время. Таким образом, модель Хэтэуэй интегрирована в подготовке и тестировании наших алгоритмов машинного обучения. После, алгоритмы машинного обучения обучаются, информация о времени для любых будущих солнечных пятен может быть смоделирована и подаваться им в режиме реального времени.
4.3.4. Окончательный набор данных
После использования модели Хэтэуэй, окончательный набор данных для обучения может быть построен. Для каждого образца множество обучающих данных состоит из шести числовых значений: четыре входных значения и два выходных значения. Первые три входные значения представляют классификации Макинтош солнечных пятен, а последние представляют числовое значение смоделированного и нормированного числа солнечных пятен на основе модели Хэтэуэй. Значение моделируемой Хэтэуэй нормирована разделив его на фактическое или расчетное число солнечных пятен на солнечных максимумах, чтобы получить значение между нулем и единицей. Выходной набор состоит из двух значений: первое значение используется для прогнозирования будет ли пятна производить значительные вспышки или нет. Для целей оценки эффективности, это значение будет называться правильным Flare прогнозированием (СФП)
значения. Второе значение используется для определения предсказанного класса вспышки X или M, и он будет упоминаться как Правильный прогноз (CFTP)
. Конечное множество входных и выходных данных приведено в таблице II. Кроме того, некоторые примеры из множества данных представлены в таблице III.
4.4. FINAL ТРЕНИНГИ и тестирования для сравнений
Для того чтобы определить, какой алгоритм машинного обучения больше подходит для нашего приложения, предсказания производительности ГЦЯН, SVM и RBFN необходимо сравнивать. Однако эти алгоритмы обучения должна быть оптимизированы до фактического сравнения. Для того, чтобы найти лучшие параметры и / или топологии для трех алгоритмов обучения начального обучения и тестирования применяются эксперименты. Результаты этих экспериментов используют для определения оптимальных параметров и топологии для каждого алгоритм машинного обучения, прежде чем он может быть сравнен с другими алгоритмами обучения.
4.4.1 Оптимизация ГЦЯН для окончательного сравнения
В Qahwaji и Colak (2006b), было доказано, что ГЦЯН обеспечивает оптимальное выполнение нейронных сетей для обработки солнечных данных в каталогах. Однако многие скрытые узлы просто одним скрытым слоем были использованы для обучения сети в Qahwaji и Colak (2006b). Для упрощения топологии ГЦЯН были проведены эксперименты с двумя скрытыми слоями заключенными в этой работе путем изменения количества скрытых узлов в каждом слое от 9:59. В конце нам удалось сравнить 100 различных ГЦЯН топологий на основе лучших CFP и CFTP. ГЦЯН с шестью скрытыми узлами в первом слое и четырьма скрытыми узлами во втором слое дает лучшие результаты для CFP и CFTP.
4.4.2 Оптимизация SVM для окончательного сравнения
Для нашей работы, SVM эксперименты проводятся с использованием mySVM программы, разработанной S.Ruping. Чтобы оптимизировать производительность SVM, оптимальное ядро и его параметры должны быть определены опытным путем. В работе, были испытаны многие ядра, такие, как точка, полиномиальные, нейронные, радиальные и Anova ядра, для того, чтобы выбрать ядро, которое обеспечивает лучшее классификации производительности. После нанесения всех этих ядер мы пришли к выводу, что ядро дисперсионного анализа, которое показано в уравнении (2), дает лучшие результаты по сравнению со всеми другими ядрами. Наши данные соответствуют результатам Маник соавт. (2004).
Выводы
В данной работе в системах Simulink и МВТУ было промоделировано уравнение Ван дер Поля с затухающей амплитудой. Выполнены сравнительные характеристики систем моделирования Simulink и МВТУ. Все промоделированные уравнения имеют временные графики.
Так же стоит отметить, что программное обеспечение имеет характеристики, которые необходимо отметить в ходе сравнения:
По окончанию моделирования МВТУ занимало почти в 2 меньше оперативной памяти. Что касается быстродействия, то SimeLink затратил на моделирование примерно 9 секунд, а МВТУ около 2 секунд. Тесты проводились на компьютере со следующими параметрами:
Список использованной литературы
1. Model.Exponenta.Ru — учебно-методический сайт о моделировании и исследовании систем, объектов, технических процессов и физических явлений. http://model.exponenta.ru/
2. Хайрер Э., Ваннер Г. Решение обыкновенных дифференциальных уравнений. Жесткие и дифференциально-алгебраические задачи. М.: Мир, 1999. 685 с.
3. Сайт разработчиков ПК МВТУ
. http://mvtu.power.bmstu.ru/
4. Shampine L.F., Reichelt M.W. The MATLAB ODE Suite // SIAM J. on Scientific Computing. Vol. 18. 1997. № 1. P. 1-22.
5. Bogacki P., Shampine L.F. A 3(2) pair of Runge-Kutta formulas // Applied Mathematics Letters. Vol. 2. 1989. № 4. P. 321-325.
6. Hosea M.E., Shampine L.F. Analysis and implementation of TRBDF2 // Applied Numerical Mathematics. Vol. 20. 1996. № 1-3. P. 21-37.
7. Скворцов Л. М. Адаптивные методы численного интегрирования в задачах моделирования динамических систем // Изв. РАН. Теория и системы управления. 1999. № 4. С. 72-78.