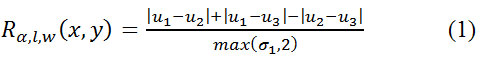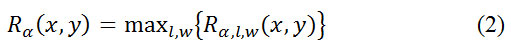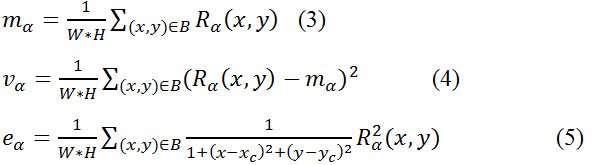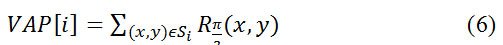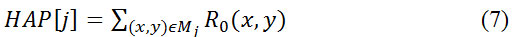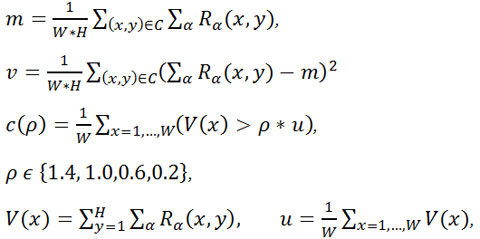Аннотация
Текст в изображениях и видео – это существенная подсказка для понимания
визуального содержания и поиска. В этой статье мы представим быстрый и
эффективный подход к выделению текстовых линий, даже на сложном фоне.
Во-первых, наш алгоритм использует штриховой фильтр для вычисления штриховых
карт по горизонтали, вертикали, а также по направлениям правой и левой диагоналей.
Затем извлекается 24-мерная функция для каждого раздвижного окна и используется
SVM для выделения грубых регионов. Грубые регионы текста в дальнейшем
переопределяются с помощью набора правил. Кандидаты в текстовые линии
определяются более точно с помощью проекций определенных регионов текста.
В конце другой SVM классификатор, основанный на 6-мерной функции,
используется для проверки кандидатов в текстовые линии. Результаты
экспериментов для сложной базы данных показали, что этот подход быстро
и эффективно определяет положение текстовых линий.
Ключевые
слова:
Обнаружение текста, Штриховой фильтр, SVM
Введение
Текст, встроенный в изображения и видео, обеспечивает краткой
и важной информацией для визуального обобщения информации и индексации.
За последние годы множество исследовательских работ были сфокусированы
на обнаружении и локализации текста на изображениях и видео.
Многие характеристики для распознавания текста были обобщены и
охарактеризованы эффективными подходами. Так, например,
встроенный текст обычно содержит плотные края [1]; большинство
текстовых пикселей имеют однородный цвет [2]; штрихи символа
образуют различные текстуры [3][4]. Лиу [5] анализирует свойства
штрихов символов и предлагает использовать штриховой фильтр для
непосредственного определения и локализации текста. Существует две
категории методов моделирования, основанных на разных подходах.
Первый включает методы, основанные на ограничениях, такие как [1][5][6][7].
Второй подход рассматривает методы, основанные на базе обучения, такие как
нейронные сети [8],[9], SVM [3][4][5][10]. Методы первой категории требуют
сами дизайнеры, чтобы закончить задачу обобщения эффективных правил
классификации, так что для инженеров это совсем непросто создать текстовый
детектор с хорошей производительностью.
В этой статье, вдохновленной авторами работы [5], мы использовали
штриховой фильтр для получения низкого уровня представления содержания изображения,
и затем получили более компактную классификацию особенностей для создания быстрого
и эффективного текстового детектора с помощью машинного обучения. По сравнению с [4],
наш алгоритм исследует использование более простых и отличительных черт, поэтому он
имеет более высокую вычислительную эффективность. В отличие от Лиу [5], который использовал
способ, основанный на ограничениях (анализ связных компонент) для обнаружения текста, наш
алгоритм использует SVM для идентификации текстовых областей.
Остальные части этой статьи организованы следующим образом. Раздел 2 представляет наш
подход в деталях к обнаружению текста. В разделе 3 мы предоставляем информацию о результатах
сравнительного эксперимента на двух сложных базах данных. Раздел 4 включает выводы всей работы.
2. Наш алгоритм
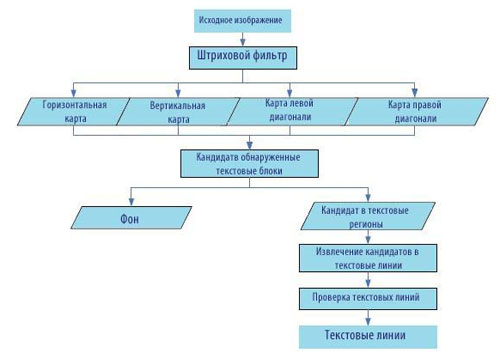
Рисунок 1 – Блок-схема предложенного алгоритма
На рисунке 1 изображена обобщенная блок-схема предлагаемого алгоритма. Для исходного
изображения мы используем штриховой фильтр [5], чтобы получить четыре штриховые маски,
которые характеризуют длину штриха в горизонтальном, вертикальном, лево- и право-диагональных
направлениях. Затем соответствующие особенности выделяются для всех раздвижных окон, и SVM
используется для классификации раздвижных окон в текстовые и нетекстовые блоки. Все текстовые
блоки, которые являются кандидатами в текстовые регионы, представляются с помощью бинарной маски
изображения. Далее некоторые правила предназначены для извлечения из кандидата текстовых линий
выполнением операций заполнения, слияния и удаления очевидно не текстовых прямоугольников.
По линиям кандидата в текст, в конечном итоге, извлекаются новые особенности из каждой линии
текста кандидата, и SVM используется, чтобы определить класс метки текстовых линий кандидата (текст или не текст).
2.1 Генерация штриховых масок
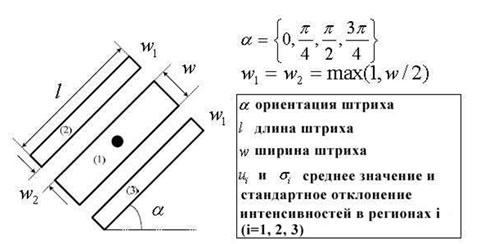
Рисунок 2 – Штриховой фильтр
Если изображение цветное, то оно конвертируется в grayscale изображение.
Затем группа штриховых фильтров применяется для генерации штриховых масок
соответствующих горизонтальным, вертикальным, лево- и право-диагональным направлениям.
Как показано на рисунке 2 отклик Rα,l,w(x,y) штрихового фильтра в центральной точке (x, y)
зависит от значения пикселей в трех прямоугольных регионах, где α, l и w три параметра,
которые соответствуют ориентации, длине и ширине штриха соответственно. Конкретно,
отклик штрихового фильтра определяется следующим образом:
Более подробную информацию о штриховом фильтре можно найти в статье [5].
В нашем методе штриховой фильтр соответствующим четырем направлениям и вычисляется следующим образом:
Используя формулу (2), мы получаем штриховые карты
для горизонтального ( α=0), вертикального (α=π/2), лево-диагонального (α=3π/4), право-диагонального (α=π/4) направлений.
2.3 Обнаружение кандидатов в текстовые блоки
Благодаря W*H раздвижного окна, SVM используется для определения, является ли
потенциальный текстовый блок в позиции, охватываемой раздвижным окном B. Соответственно,
24-мерная функция извлекается из четырех штриховых масок для каждого раздвижного окна.
Так как текстовые блоки обычно приводят к существенным значениям откликов в четырех штриховых
фильтрах и не текстовые блоки не имеют существенных значений откликов на всех картах.
Мы используем статистические признаки в штриховых картах, чтобы овладеть этими свойствами.
Конкретно, признаки включают математическое ожидание mα, дисперсию vα, весовую энергию eα :
где Rα(x,y), α ∈ {0,π/4,π/2,3π/4} обозначает значения отклика в
штриховой карте для четырех разных направлений, В – означает накрытие
раздвижным окном и (xc, yc) – координаты центральной локации В. Формула (5)
показывает, чьи интенсивности более близки к центральной точке скользящего окна,
имеют большие веса.
Для характеристики пространственного распределения штрихов мы определяем
соответствующие принципы, вертикальный аккумулирующий профиль (VAP) и горизонтальный
аккумулирующий профиль (HAP). Для каждого раздвижного окна в вертикально-штриховой
карте происходит разделение на восемь прямоугольных регионов. В каждом прямоугольнике
Si, i=1,2,…, 7, VAP вычисляется следующим образом:
Так же для каждого раздвижного окна в горизонтально-штриховой карте происходит разделение
на четыре прямоугольные региона. В каждом прямоугольнике Mj, j=1,2,3,4, HAP вычисляется следующим образом:
Таким образом, каждый блок покрыт раздвижным окном и представлен 24-мерным вектором признаков.
По сравнению с другими классификаторами, такими как нейронные сети и дерево решений и так далее,
SVM нуждается в меньшем количестве обучающих выборок и имеет лучшие способности обобщения, поэтому
мы выбрали SVM как наш классификатор для выделения кандидатов в текстовые блоки. В нашей работе
SVM на этапе обучается по данным множества, состоящего из 240 текстовых блоков и 480 не текстовых
блоков. Если выход SVM классификатора положительный, пиксели в раздвижном окне полностью обозначаются
как пиксели текста. Шаг перемещения раздвижного окна горизонтальный W/2 и вертикальный H/2.
В результате мы создаем двоичную маску изображения, чьи белые регионы представляют кандидатов
в текстовые регионы и черные регионы представляют собой фон. На рисунке 3 приведен пример вывода результата на этом этапе.

Рисунок 3 – Грубое обнаружение текста
2.3 Извлечение кандидатов текстовых линий
Как показано на рисунке 3, кандидаты в текстовые регионы должны покрывать несколько
не текстовых регионов и множество границ прямоугольников, соответствующих текстовым регионам,
часто соединены вместе. Таким образом, изначально мы используем следующие этапы вычисления для
разделения этих многоугольников в регулярные прямоугольники (рис 3, с):
- Разделение полигона на маленькие прямоугольники (рис 4, b).
- Если разрыв между двумя прямоугольниками на горизонтальной линии меньше, чем 1/6 от полной ширины, заполнить разрывы, соединив их (рис. 4,с).
- Для двух вертикальных смежных прямоугольников, если ширина прямоугольника, который короче превышает 4/5 от его длины, объедините их в больший прямоугольник, высота которого равна сумме их высот и ширине максимального из них.
- Если высота прямоугольника меньше 1/3 его смежного прямоугольника по вертикали, объедините их так же, как на шаге 3 (рис. 4, d).
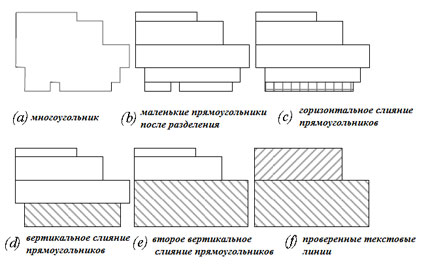
Рисунок 4 – Разделение прямоугольников
Тогда для каждого регулярного прямоугольника мы используем метод горизонтальных и вертикальных
проекций для эффективной локализации строк текста. Наш метод похож на метод из источника [1],
но участвует лишь один тип проекций. Интенсивность значений, используемых при оценке проекций
равна сумме откликов в четырех штриховых картах. Для сгенерированных границ прямоугольников,
соответствующих текстовым линиям, некоторые очевидно не текстовые прямоугольники удаляются,
если их высоты не принадлежат к нужному диапазону [α, β] или их соотношение превышает
определенный порог γ. На рисунке 3d показан финальный кандидат в текстовые линии после операции выделения проекций.
2.4 Проверка строк текста
Для всех кандидатов в текстовые линии C выделена 6-мерная функция,
и использована новым SVM классификатором для конечной проверки являются
ли линии текстовыми. Функция включает математическое ожидание m, стандартную
дисперсию v, и четыре особенности, которые отражают статистическое распределение
горизонтальных штрихов, накапливающихся в текстовой линии (более подробный анализ
может быть найден в источниках [4][8]).
где W и H обозначают ширину и высоту текстовых регионов. В нашей работе SVM был обучен
на выборке данных, включающей 200 текстовых линий и 160 не текстовых линий. На рисунке
5(b, c) показаны результаты до и после проверки текстовых линий.

Рисунок 5 – Проверка текстовых линий
3. Экспериментальные результаты
Два сложных набора тестов были выбраны для проверки вычислений нашего подхода.
Первый состоял из 308 изображений из Web, записанных видео-трансляций или цифрового
видео. Каждое изображение внимательно отбиралось, чтобы встроенный текст имел разные
размеры, цвета, языки, текстуры фона и так далее. Второй набор – общий набор тестов
от Microsoft, содержащий 46 изображений [11]. В наших экспериментах длина и ширина
штрихового фильтра содержит две группы данных (1) l=3, w=1 (2) l=4, w=3. Размер
раздвижного окна был установлен W=24, H=12 и параметры α, β и γ были установлены
в 6, 72 и 1.2 соответственно. На рисунке 6 показаны некоторые результаты экспериментов.

Рисунок 6 – Результаты
Для количественного сравнения были взяты три метрики:
- Скорость. Среднее количество обработанных изображений в секунду для обнаружения и локализации текста.
- Отклики. Отношение общего количества регионов к регионам, содержащим текст.
- Точность. Отношение количества регионов правильно обнаруженных системой к количеству утвержденных регионов.
Правильным считается обнаружение тогда и только тогда, когда пересечение регионов обнаруженного текста (DTR)
и регионов, истинно содержащих текст (GTR), покрывает 90% DTR и GTR. GTR в текстовых изображениях локализованы вручную.
Таблица 1 – Оценка эффективности трех подходов
| Подход |
Скорость |
Отзыв |
Точность |
| Наш подход |
12.9 |
91.1% |
95.8% |
| Ye из источника [4] |
10.1 |
90.8% |
90.3% |
| Liu из источника [5] |
11.7 |
91.3% |
92.4% |
Соответствующие экспериментальные результаты приведены в таблице 1.
Сравнивая с методами, представленными в источниках [4] и [5], наши методы имеют
лучшую производительность в определении скорости и точности. Причиной высокой скорости
является то, что рост региона или связных компонент не занимает много времени. Причиной
высокой точности является то, что в методе, основанном на обучении легче получить лучшие
модели классификации, чем в методе, основанном на ограничениях
4. Выводы
В этой статье, был предложен подход к быстрому и эффективному обнаружению текста.
Разработанные принципы основаны на штриховых картах в четырех направлениях, и способны
к лучшему представлению особенностей, характерных для текста. Метод, основанный на
машинном обучении, может сконструировать текстовый детектор с высокой производительностью
намного легче. Сочетание штриховых принципов и обучения машины является многообещающим
решением для проблемы обнаружения текста на изображениях и видео.
Ссылки
-
M.R Lyu, J.Song and M.Cai, "A comprehensive method for
multilingual video text detection, localization, and extraction,"
IEEE Trans. Circuits Syst. Video Technol., vol. 15, no. 2, pp. 243-
255, Feb. 2005.
-
V. Y. Mariano and R. Kasturi, “Locating uniform-colored text
in video frames,” in Proc. 15th Int. Conf. Pattern Recognit., vol. 4,
pp. 539–542, Barcelona, Spain, Sep. 2000.
- C. Zhu, W. Wang and Q. Ning, “Text detection in images using
texture feature from strokes”, 7th Pacific-Rim Conf. on Multimedia,
Hangzhou, China, Nov. 2006, pp. 295-301.
- Q.Ye, Q.Huang, W.Gao and D. Zhao, “Fast and robust text
detection in images and video frames,” Image Vis. Comput. vol. 23,
no. 6, pp. 565-576, Jun. 2005.
-
Q. Liu, C. Jung, S. Kim, Y. Moon and J.Kim,” Stroke filter for
text localization in video images,” in Proc. Int. Conf. Image
Process., Atalanta, GA, USA, Oct. 2006, pp. 1473-1476
- N. Otsu, “A threshold selection method from gray-scale
histograms,” IEEE Trans. Syst., Man, Cygbernet., vol. SMC-9, no.
1, pp. 62-66, Jan. 1979.
- C. Wolf, and JM. Jolion, “Extraction and recognition of
artificial text in multimedia documents,” Pattern Anal. Applicat.,
vol. 6, no. 4, pp. 309-326, Feb. 2004
- R. Lienhart and A. Wernicke, “Localizing and segmenting text
in images and videos,” IEEE Trans. Circuits Syst. Video Technol.,
vol.12, no.4, pp. 256-268, Apr. 2002.
- H. Li, D. Doermann, and O. Kia, “Automatic text detection and
tracking in digital video,” IEEE Trans. Image Process., vol. 9, no.
1, pp. 147-156, Jan. 2000.
- D. T. Chen, H. Bourlard, and J-P. Thiran, “Text identification
in complex background using SVM,” in Proc. IEEE Conf. Comput.
Vis. Pattern Recognit., Kauai, Hawaii, Dec. 2001, pp. 621-626.
- X.S. Hua, W.Y. Liu, and H.J. Zhang, “An automatic
performance evaluation protocol for video text detection
algorithms,” IEEE Trans. Circuits Syst. Video Technol. vol. 14, no.
4, pp. 498–507, Apr. 2004.