Неокогнитрон, способный инкрементально обучаться
Автор: Kunihiko Fukushima
Перевод с английского: Тимофей Труханов
Источник: Journal Neural Networks, Volume 17 Issue 1, January 2004, Pages 37-46, Elsevier Science Ltd. Oxford, UK, http://lrn.no-ip.info/other/books/neural/Neocognitron
Реферат
Данная работа предлагает новый неокогнитрон, который принимает инкрементальное обучение без нанесения большого ущерба уже обученным клеткам и без уменьшения скорости обучения. Новый неокогнитрон использует конкурентное обучение и обучение на всех этапах иерархической сети происходит одновременно.
Чтобы увеличить скорость обучения традиционные неокогнитроны последних версий жертвовали возможностью инкрементального обучения и использовали метод последовательного создания слоёв, в которой обучение следующего слоя начиналось только после того, как обучение предыдущего слоя полностью завершится. Если просто установить высокую скорость обучения для традиционного неокогнитрона, одновременное создание слоёв приведет к появлению большого количества "мусорных" клеток, которые впоследствии всегда остаются "молчаливыми" после завершения обучения. Предлагаемый неокогнитрон с новым методом обучения может предотварщать создание таких "мусорных" клеток даже при высокой скорости обучения.
Ключевые слова: Инкрементальное обучение; Неокогнитрон; Конкурентное обучение; Многослойная нейросеть; Распознавание рукописных цифр
1 Введение
Автор ранее предлогал модель нейросети когнитрона для надежного распознавания образов (Fukushima, 1980; Fukushima & Miyake, 1982). Она имеет иерархическую многослойную архитектуру, похожую на классическую гипотезу, предложенную Хьюбелом и Визелем. Она приобретает возможность распознавать с трудом зрительные образы через обучение.
Для увеличения скорости обучения неокогнитроны предыдущих версий жертвовали способностью инкрементального обучения. Данная работа предлагает неокогнитрон, который способен инкрементально обучаться без снижения скорости обучения. Новый неокогнитрон имет модифицированную нейросетевую архитектуру и использует новый метод обучения. Новый метод обучения позволяет одновременное создание всех уровней нейросети с высокой скоростью и по прежнему с возможностью инкрементального обучения. Старые связи (клетки), созданные предыдщуим обучением не будут серьезно повреждены последующим обучением.
2 Традиционный неокогнитрон
2.1 Параллельная или последовательная конструкция
Неокогнитрон состоит из слоёв из S-клеток, которые напоминают простые клетки в первичной зрительной коре, и слоёв из C-клеток, которые напоминают сложные клетки. Эти слои S-клеток и C-клеток расположены поочередно по иерархическому принципу.
S-клетки служат для выделения характерных черт, их входы являются переменными и измениются в процессе обучения. C-клетки, чьи входы являются фиксированными и неизменяемыми, проявляют приближенную инвариантность к положению стимулов, представленных в их рецептивных полях. C-клетки в последнем слое работают как распознающие клетки, которые определяют результат распознавания образа.
Когда обучающие стимулы поступают во время обучения, каждая S-клетка соревнуется с другими клетками в своей окрестности и изменяет свои входы только если выигрывает соревнование. Соединения модифицируются так, что клетка реагирует сильнее на обучающие стимулы, на которых она выиграла соревнования. Если в области соревнования ни одна S-клетка не выиграла, то создается новая S-клетка, и, следовательно, новая плоскость генерируется и обучается этому стимулу.
Что касается порядка следования изменения соединений различных слоёв, два альтернативных метода были предложены. Мы будем называть эти методы параллельным конструированием и последовательным конструированием.
В параллельном конструировании, которое используется в оригинальной версии неокогнитрона (Fukushima, 1980; Fukushima & Miyake, 1982), обучение всех слоёв нейросети происходило параллельно. В последовательном конструировании, которое было использовано в большинстве предыдущих версиях (Fukushima, 2003), обучение начинается с нижних уровней и продвигается последовательно к верхним уровням: после обучения нижнего уровня, начинается обучение следующего уровня.
И параллельное и последовательное конструирование имеет свои преимущества и недостатки для обычного неокогнитрона. Параллельное конструирование требует медленной скорости обучения, но может допускать инкрементальное обучение. С другой стороны, последовательное конструирование может выполнить обучение очень быстро, но не допускает инкрементального обучения.
Предлагаемый неокогнитрон позволяет параллельное конструирование всех уровней нейросети с высокой скоростью обучения и с поддержкой инкрементального обучения.
2.2 Обычные методы обучения
Сначала мы обсудим случай
параллельного конструирования. Пусть ![]() будет слоем S-клеток в l-ом уровне нейросети. Ответ слоя
будет слоем S-клеток в l-ом уровне нейросети. Ответ слоя ![]() предыдущего уровня работает как тренировочный сигнал для слоя
предыдущего уровня работает как тренировочный сигнал для слоя ![]() .[1] Количество клеточных плоскостей в слое
.[1] Количество клеточных плоскостей в слое ![]() постепенно увеличивается в процессе обучения. Увеличение количества
клеточных плоскостей в слое
постепенно увеличивается в процессе обучения. Увеличение количества
клеточных плоскостей в слое ![]() означает, что тренировочные сигналы подающиеся на слой
означает, что тренировочные сигналы подающиеся на слой ![]() изменяются, даже если на входной слой
изменяются, даже если на входной слой ![]() подаётся тот же самый образ. Если мы опишем это в многомерном векторном
пространстве, то измерение обучающих векторов для
подаётся тот же самый образ. Если мы опишем это в многомерном векторном
пространстве, то измерение обучающих векторов для ![]() постепенно возрастает с обучением слоя
постепенно возрастает с обучением слоя ![]() .
.
Если скорость обучения ![]() высокая, изменения в реакциях
высокая, изменения в реакциях ![]() происходят очень быстро, что обусловлено увеличением числа клеточных
плоскостей. Из-за внезапного изменения сингалов от пресинаптической клетки,
клетка слоя
происходят очень быстро, что обусловлено увеличением числа клеточных
плоскостей. Из-за внезапного изменения сингалов от пресинаптической клетки,
клетка слоя ![]() часто не в состоянии ответить на обучающий образ, к которому клетка
была исходной клеткой. Эта ситуация показана на рис. 1(b).
часто не в состоянии ответить на обучающий образ, к которому клетка
была исходной клеткой. Эта ситуация показана на рис. 1(b).
Так как клетка не может стать исходной
клеткой, входные соединения с клеточной плоскостью не могут быть изменены.
Клеточная плоскость не может адаптироваться к быстрому изменению слоя ![]() и прекращает реагировать навсегда. Другие клеточные плоскости должны
быть сгенерированы в слое
и прекращает реагировать навсегда. Другие клеточные плоскости должны
быть сгенерированы в слое ![]() вместо нереагирующей клеточной плоскости. Нереагирующая клеточная
плоскость становится "мусорной" в сети и только потребляет большое
количество процессорного времени когда нейросеть установлена на компьютере.
вместо нереагирующей клеточной плоскости. Нереагирующая клеточная
плоскость становится "мусорной" в сети и только потребляет большое
количество процессорного времени когда нейросеть установлена на компьютере.
Генерации нереагирующих
"мусорных" клеточных плоскостей можно избежать, если сделать скорость
обучения сети очень медленной. Из-за механизма маневрового торможения, выходные
сигналы S-клетки слабы когда слабы связи с ней (см.
формулы (3), (5), (9) и (10) ниже). Таким образом реакция клеточной плоскости
будет оставаться слабой некоторое время после создания, при медленной скорости
обучения. После этого реакция постепенно увеличивается. Другими словами,
реакция ![]() на тренировочный образ, которая становится тренировочным стимулом для
на тренировочный образ, которая становится тренировочным стимулом для ![]() , не изменяется быстро даже после увеличения количества клеточных
плоскостей в
, не изменяется быстро даже после увеличения количества клеточных
плоскостей в ![]() . Поэтому каждая клеточная плоскость
. Поэтому каждая клеточная плоскость ![]() адаптируется к увеличению размерности тренировочного вектора смещением
её ссылочного вектора постепенно в направлении нового тренировочного вектора
увеличенной размерности. Хотя генерацию «мусорных» клеток таким образом можно
избежать с помощью уменьшения скорости обучения, большое количество повторений
представления одного и того же обучающего образа необходимо для завершения
обучения, из-за медленного возрастания ответов клеток.
адаптируется к увеличению размерности тренировочного вектора смещением
её ссылочного вектора постепенно в направлении нового тренировочного вектора
увеличенной размерности. Хотя генерацию «мусорных» клеток таким образом можно
избежать с помощью уменьшения скорости обучения, большое количество повторений
представления одного и того же обучающего образа необходимо для завершения
обучения, из-за медленного возрастания ответов клеток.
Для увеличения скорости обучения без
генерации «мусора» в сети, последовательное конструирование часто используется
для обучения неокогнитрона последних версий. Поскольку обучение ![]() начинается после окончания обучения
начинается после окончания обучения ![]() , «мусорные» клетки не будут генерироваться в
, «мусорные» клетки не будут генерироваться в ![]() независимо от скорости обучения
независимо от скорости обучения ![]() .
.
Последовательное конструирование, однако, не принимает инкрементальное обучение. Предположим подаётся дополнительное множество тренировочных образов, после того, как сеть уже обучилась на определенном множестве тренировочных образов. Если слой, который обучился на первом тренировочном множестве образов, дополнительно учит второе тренировочное множество, новые клеточные плоскости обычно будут сгенерированы в этом слое. После этого слой начинает реагировать по-другому даже на образы из первого тренировочного множества. Это такая же ситуация, как и в случае параллельного конструирования с большой скоростью обучения. Некоторые клеточные плоскости следующего слоя перестают реагировать даже на те образы, на которые они раньше реагировали и становятся «мусорными».
3 Базовая идея обучения
3.1 Реакция S-клетки
Чтобы показать суть алгоритма
обучения, мы будем рассматривать только схему, относящуюся только к одной S-клетке (см. рис. 1а) и анализировать её поведение. Пусть ![]() будет силой возбуждающего сигнала к S-клетке от i-ой
C-клетки, у которой
будет силой возбуждающего сигнала к S-клетке от i-ой
C-клетки, у которой ![]() – выходы; и
– выходы; и ![]() будет силой тормозящего сигнала от V-клетки, у
которой
будет силой тормозящего сигнала от V-клетки, у
которой ![]() – выход. Также пусть
– выход. Также пусть ![]() будет силой возбуждающего сигнала к V-клетке от i-ой
C-клетки. Переменная
будет силой возбуждающего сигнала к V-клетке от i-ой
C-клетки. Переменная ![]() , которая будет рассмотрена в разделе 3.2, своего рода вес, впервые
вводится в предлагаемом алгоритме, и служит для компенсации разницы между
тренировочными
, которая будет рассмотрена в разделе 3.2, своего рода вес, впервые
вводится в предлагаемом алгоритме, и служит для компенсации разницы между
тренировочными ![]() . В данном случае, мы имеем
. В данном случае, мы имеем ![]() для обычного неокогнитрона.
для обычного неокогнитрона.
Мы также используем векторную нотацию ![]() для представления ответов пресинаптических C-клеток
для представления ответов пресинаптических C-клеток
![]() . Аналогично, вектор
. Аналогично, вектор ![]() используется для обозначения связей
используется для обозначения связей ![]() .
.
Выходной сигнал S-клетки представляется как
![]() (1)
(1)
где ![]() – функция, определенная как
– функция, определенная как ![]() .
. ![]() – константа
– константа ![]() , определяющая порог S-клетки.
, определяющая порог S-клетки.
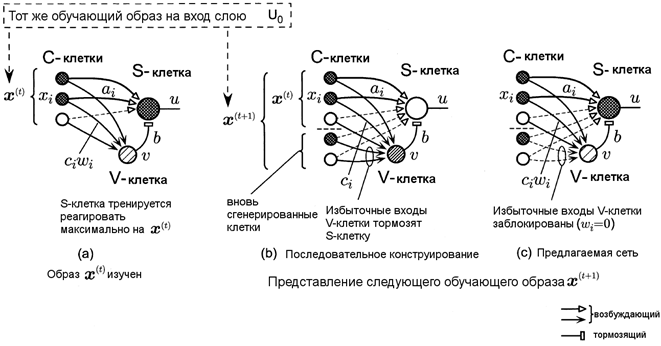
Рис. 1. Поведение S-клетки в процессе
инкрементального обучения.
Сравнение между последовательным конструированием и предлагаемой сетью.
Выход V-клетки определяется по формуле:
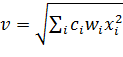 (2)
(2)
Если имеет место![]() , формула (1) может также иметь вид:
, формула (1) может также иметь вид:
![]() (3)
(3)
где
![]() (4)
(4)
и
![]() (5)
(5)
Переменная ![]() представляет некоторую схожесть между тестовым вектором
представляет некоторую схожесть между тестовым вектором ![]() и вектором
и вектором ![]() . Переменная
. Переменная ![]() может рассматриваться как константа
может рассматриваться как константа ![]() после некоторого прогресса в обучении, в котором тормозящая связь
после некоторого прогресса в обучении, в котором тормозящая связь ![]() становится достаточно большой, что удовлетворяет условию
становится достаточно большой, что удовлетворяет условию ![]() . Если входной сигнал S-клетки нулевой, однако, мы
имеем
. Если входной сигнал S-клетки нулевой, однако, мы
имеем ![]() и
и ![]() .
.
В процессе обучения каждая S-клетка соревнуются с другими S-клетками в своей
окрестности и победители соревнования становятся исходными клетками и обучаются
тренировочному образу. Не смотря на то, что большое количество тренировочных
образов представляется неокогнитрону, только часть из них делает определенные S-клетки победителями (или исходными клетками). Вектор ![]() , которые делает эту клетку победителем становится тренировочным
вектором для этой S-клетки, и t-ый тренировочный вектор для этой S-клетки
представляется как
, которые делает эту клетку победителем становится тренировочным
вектором для этой S-клетки, и t-ый тренировочный вектор для этой S-клетки
представляется как ![]() . Для упрощения, мы предполагаем здесь, без потери общей картины, что
та же S-клетка всегда выбирается как исходная из клеточной
плоскости.
. Для упрощения, мы предполагаем здесь, без потери общей картины, что
та же S-клетка всегда выбирается как исходная из клеточной
плоскости.
В промежуточном уровне сети,
количество пресинаптических C-клеток, а именно,
размерность тренировочного вектора ![]() , постепенно увеличивается в процессе обучения., из-за параллельного
конструирования всех уровней иерархической сети. Тренировочный вектор,
представленный ранее, обычно имеет меньшую размерность.
, постепенно увеличивается в процессе обучения., из-за параллельного
конструирования всех уровней иерархической сети. Тренировочный вектор,
представленный ранее, обычно имеет меньшую размерность.
Каждый раз, когда S-клетка становится победителем, возбуждающая связь ![]() увеличивается на число, пропорциональное реакции пресинаптической C-клетки. Если C-клетка еще не была сгенерирована,
увеличивается на число, пропорциональное реакции пресинаптической C-клетки. Если C-клетка еще не была сгенерирована, ![]() не изменяется. А именно
не изменяется. А именно
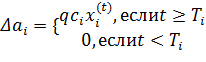 (6)
(6)
где ![]() – время, когда i-я пресинаптическая C-клетка сгенерирована. Параметр
– время, когда i-я пресинаптическая C-клетка сгенерирована. Параметр ![]() – положительная константа, определяющая скорость обучения. Так как
– положительная константа, определяющая скорость обучения. Так как ![]() в начальном состоянии,
в начальном состоянии, ![]() после завершения обучения
после завершения обучения ![]() раз
раз
![]() (7)
(7)
Это означает, что компоненты вектора
пропущенных размерностей считаются нулевыми, когда тренировочный вектор более
малых размерностей суммируется до ![]() .
.
Тормозящая связь ![]() определяется прямо из значений возбуждающих сигналов
определяется прямо из значений возбуждающих сигналов ![]() и весов
и весов ![]()
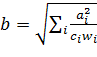 (8)
(8)
3.2 Гипотетический случай
Так как обучения всех слоёв сети
происходит параллельно, реакция пресинаптической C-клетки
не всегда одинаковая в процессе обучения, даже если на входном слое сети
представлен один и тот же тренировочный образ. Вес ![]() нужен чтобы компенсировать этот эффект.
нужен чтобы компенсировать этот эффект.
Мы предполагаем следующим образом. S-клетка выбирается исходной только когда один и тот же тренировочный
образ представлен на входном слое ![]() нейросети. Пусть
нейросети. Пусть ![]() есть реакция i-й пресинаптической C-клетки, когда тот же тренировочный образ представлен в t-е время. Пусть
есть реакция i-й пресинаптической C-клетки, когда тот же тренировочный образ представлен в t-е время. Пусть ![]() есть реакция этой C-клетки после завершения
достаточного количества обучений предыдущих уровней сети. Мы также используем
векторную нотацию
есть реакция этой C-клетки после завершения
достаточного количества обучений предыдущих уровней сети. Мы также используем
векторную нотацию ![]() для представления вектора, в котором i-й
элемент обозначается
для представления вектора, в котором i-й
элемент обозначается ![]() .
.
На начальном этапе обучения, реакция ![]() уменьшена по сравнению с
уменьшена по сравнению с ![]() на множитель
на множитель ![]() , который является своего рода усилением C-клетки,
где
, который является своего рода усилением C-клетки,
где ![]() представляет затраченное время с тех пор как клетка была сгенерирована.
То есть
представляет затраченное время с тех пор как клетка была сгенерирована.
То есть
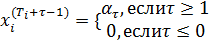 (9)
(9)
Значение ![]() увеличивается асимптотически до 1.0 в процессе обучения предыдущих
уровней. Мы подразумеваем здесь, что
увеличивается асимптотически до 1.0 в процессе обучения предыдущих
уровней. Мы подразумеваем здесь, что
![]() (10)
(10)
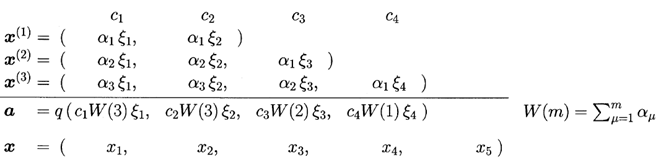
Рис. 2. Отношение между связью ![]() и тестовым вектором
и тестовым вектором ![]()
Формулы (9) и (10) получены приближённо в
предположении, что реакции пресинаптической C-клетки,
которые зависят от реакций S-клеток, также соответствуют
уравнениям (3) и (5). Другими словами ![]() соответствует
соответствует ![]() , а
, а ![]() соответствует
соответствует ![]() , в формуле (3).
, в формуле (3).
Если эта гипотеза справедлива, мы имеем из формул (7), (9) и (10)
![]() (11)
(11)
где ![]() – функция, определенная как
– функция, определенная как
![]() (12)
(12)
и ![]() показывает сколько раз выход i-й
пресинаптической C-клетки был использован для тренировки
этой S-клетки. А именно
показывает сколько раз выход i-й
пресинаптической C-клетки был использован для тренировки
этой S-клетки. А именно
![]() (13)
(13)
Эта ситуация показана на рис. 2. В этом
примере, первая и вторая пресинаптические C-клетки были
сгенеированы с начала обучения и их выходы суммировались трижды с ![]() . Так как третья C-клетка не была еще
сгенерирована в момент
. Так как третья C-клетка не была еще
сгенерирована в момент ![]() , её реакция считается нулевой когда векторы
, её реакция считается нулевой когда векторы ![]() суммируются с
суммируются с ![]() . Четвёртая C-клетка, которая сгенерировалась
только в момент
. Четвёртая C-клетка, которая сгенерировалась
только в момент ![]() , суммируется только один раз. Тестовый вектор
, суммируется только один раз. Тестовый вектор ![]() , который будет представлен позже, может иметь больше компонентов,
соответствующих C-клеткам, сгенерированным после этого.
, который будет представлен позже, может иметь больше компонентов,
соответствующих C-клеткам, сгенерированным после этого.
Подставляя формулы (2), (8) и (11) в
формулу (4), мы имеем ![]() для произвольного тестового вектора
для произвольного тестового вектора ![]()
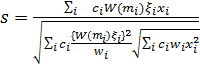 (14)
(14)
Если мы подкорректируем значение веса ![]() до
до
![]() (15)
(15)
формула (14) уменьшится до
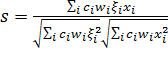 (16)
(16)
Формула (15) означает, что тяжелее вес ![]() присваивается сигналу от C-клетки, которая чаще
используется для тренировки.
присваивается сигналу от C-клетки, которая чаще
используется для тренировки.
Здесь мы определяем взвешенное
внутреннее произведение двух векторов![]() и
и ![]() так:
так: ![]() , где сила связей сходящихся к тормозящей V-клетке,
, где сила связей сходящихся к тормозящей V-клетке,
![]() , используется как вес. Мы также определяем норму вектора
, используется как вес. Мы также определяем норму вектора ![]() как
как
![]() (17)
(17)
Мы можем интерпретировать это как ![]() представляет собой некоторую схожесть между тренировочным вектором
представляет собой некоторую схожесть между тренировочным вектором ![]() и тестовым вектором
и тестовым вектором ![]() .
. ![]() принимает максимальное значение 1.0 когда
принимает максимальное значение 1.0 когда ![]() . Как видно из уравнения (3), S-клетка дает
ненулевой выход для
. Как видно из уравнения (3), S-клетка дает
ненулевой выход для ![]() . В векторном пространстве
. В векторном пространстве ![]() , коническая область, определяемая как
, коническая область, определяемая как ![]() вокруг тренировочного вектора
вокруг тренировочного вектора ![]() становится допустимой областью S-клетки. S-клетка реагирует тогда и только тогда, когда тестовый вектор
становится допустимой областью S-клетки. S-клетка реагирует тогда и только тогда, когда тестовый вектор ![]() попадает в допустимую область.
попадает в допустимую область.
4 Архитектура нейросети
Опираясь на дискуссии в предыдущем разделе, мы предлагаем новый неокогнитрон. Как показано на рис. 3, предлагаемый неокогнитрон имеет почти такую же архитектуру сети, как и неокогнитрон предыдущих версий, которые разработаны для распознавания рукописных цифр (Fukushima, 2003). Единственная разница между ними находится в V-клеточных плоскостях (точнее, клеточных плоскостей V-клеток). В обычном неокогнитроне, каждый слой S-клеток имеет только одну плоскость V-клеток, которая используется для всех плоскостей S-клеток слоя. В предлагаемом неокогнитроне, каждая S-клеточная плоскость имеет свою собственную плоскость из V-клеток. Другими словами, каждая S-клетка имеет свою собственную V-клетку.
Распознаваемый образ представлен
входному слою ![]() . Слой, выделяющий контраст клеток
. Слой, выделяющий контраст клеток ![]() , который соответствует ганглиозным клеткам сетчатки или боковым
клеткам коленчатого тела, следует за слоем
, который соответствует ганглиозным клеткам сетчатки или боковым
клеткам коленчатого тела, следует за слоем ![]() . Слой
. Слой ![]() состоит из двух клеточных плоскостей: плоскости, состоящей из клеток с
концентрическими центральными рецептивными полями и плоскости, состоящей их
клеток с нецентральными рецептивными полями. Первые клетки выделяют
положительный контраст в яркости, в то время как вторые выделяют отрицательный
контраст из изображений, подающихся на входной слой.
состоит из двух клеточных плоскостей: плоскости, состоящей из клеток с
концентрическими центральными рецептивными полями и плоскости, состоящей их
клеток с нецентральными рецептивными полями. Первые клетки выделяют
положительный контраст в яркости, в то время как вторые выделяют отрицательный
контраст из изображений, подающихся на входной слой.
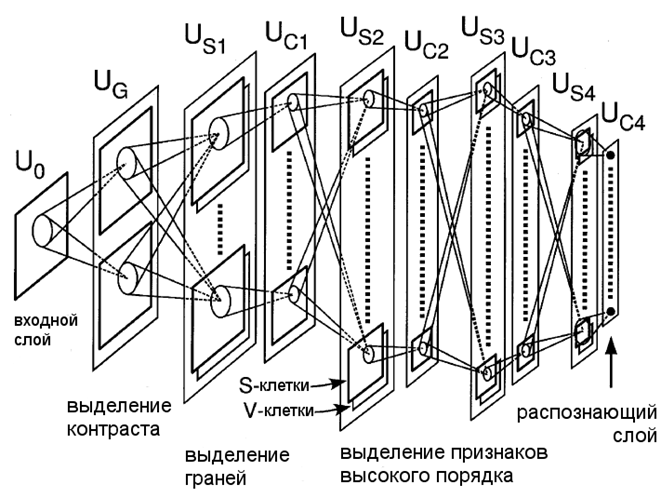
Рис. 3. Архитектура предлагаемого неокогнитрона
Выходные сигналы слоя ![]() посылаются на вход S-клеточному слою первого уровня
посылаются на вход S-клеточному слою первого уровня ![]() . S-клетки слоя
. S-клетки слоя ![]() соответствуют простым клеткам в первичной зрительной коре. Они были
обучены с учителем для выделения ориентированных граней из входного изображения
(Fukushima, 2003).
соответствуют простым клеткам в первичной зрительной коре. Они были
обучены с учителем для выделения ориентированных граней из входного изображения
(Fukushima, 2003).
Представленная модель имеет четыре
уровня из S- и C-клеточных слоев.
Выход слоя ![]() (S-клеточного слоя l-го
уровня) подается на вход слою
(S-клеточного слоя l-го
уровня) подается на вход слою ![]() , в котором генерируется размытая версия ответа слоя
, в котором генерируется размытая версия ответа слоя ![]() . Тормозящее окружение вводится вокруг возбуждающих связей к каждой C-клетке (Fukushima, 2003). Плотность клеток в каждой клеточной плоскости уменьшается между
слоями
. Тормозящее окружение вводится вокруг возбуждающих связей к каждой C-клетке (Fukushima, 2003). Плотность клеток в каждой клеточной плоскости уменьшается между
слоями ![]() и
и ![]() . Слой
. Слой ![]() , который в наивысшем уровне нейросети, является распознающим слоем,
ответ которого показывает финальный результат распознавания образа нейросетью.
, который в наивысшем уровне нейросети, является распознающим слоем,
ответ которого показывает финальный результат распознавания образа нейросетью.
S-клетки слоёв ![]() ,
, ![]() и
и ![]() являются самоорганизующимися, используя предложенный метод.
являются самоорганизующимися, используя предложенный метод.
Так как основная отличие от обычного неокогнитрона (Fukushima, 2003) находится в S-слоях, мы покажем математические выражения ответов только S-клеток.
Пусть ![]() ,
, ![]() и
и ![]() будут выходами S-, V- и C-клеток k-й клеточной плоскости l-го уровня соответственно, где
будут выходами S-, V- и C-клеток k-й клеточной плоскости l-го уровня соответственно, где ![]() является местоположением рецептивного поля клеток, а
является местоположением рецептивного поля клеток, а ![]() – порядковый номер клеточной плоскости. Выходные сигналы S-клеток вычисляется так
– порядковый номер клеточной плоскости. Выходные сигналы S-клеток вычисляется так
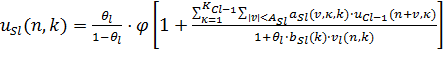 (18)
(18)
где ![]() является функцией, определенной как
является функцией, определенной как ![]() . Параметр
. Параметр ![]() – сила возбуждающей связи от C-клетки предыдущего
уровня. Однако для
– сила возбуждающей связи от C-клетки предыдущего
уровня. Однако для ![]() является
является ![]() и мы имеем
и мы имеем ![]() . Здесь стоит упомянуть, что все клетки в клеточной плоскости имеют
общие входные связи, следовательно
. Здесь стоит упомянуть, что все клетки в клеточной плоскости имеют
общие входные связи, следовательно ![]() не зависит от
не зависит от ![]() .
. ![]() означает радиус суммирующего диапазона
означает радиус суммирующего диапазона ![]() , то есть размер пространственного распределения входных связей к
определенной S-клетке. Параметр
, то есть размер пространственного распределения входных связей к
определенной S-клетке. Параметр ![]() определяет силу тормозящей связи с V-клеткой. Положительная
константа
определяет силу тормозящей связи с V-клеткой. Положительная
константа ![]() является «порогом» для S-клетки и определяет
выборочность в выявлении признаков. Кстати, если мы заменим
является «порогом» для S-клетки и определяет
выборочность в выявлении признаков. Кстати, если мы заменим ![]() на
на ![]() , уравнение (18) станет таким же как и для обычного неокогнитрона.
, уравнение (18) станет таким же как и для обычного неокогнитрона.
С другой стороны, выходные сигналы V-клеток определяются по формуле
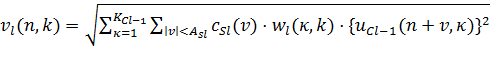 (19)
(19)
Возбуждающие входные связи от κ-й C-клеточной плоскости, состоящей из двух компонент: переменного веса ![]() , и фиксированной константы
, и фиксированной константы ![]() , что есть монотонно убывающая функция
, что есть монотонно убывающая функция ![]() .
.
В промежуточном уровне сети, ![]() , количество пресинаптических C-клеточных
плоскостей не остаётся постоянным, но увеличивается в процессе обучения, потому
что параллельное конструирование прогрессирует для всех уровней иерархической
сети. Как было изложено в разделе 3, возбуждающие сигналы
, количество пресинаптических C-клеточных
плоскостей не остаётся постоянным, но увеличивается в процессе обучения, потому
что параллельное конструирование прогрессирует для всех уровней иерархической
сети. Как было изложено в разделе 3, возбуждающие сигналы ![]() из слоя
из слоя ![]() увеличиваются пропорционально сигналам C-клеток
пресинаптических к исходной клетке, и клеточная плоскость, созданная ранее (скажем,
клеточная плоскость с
увеличиваются пропорционально сигналам C-клеток
пресинаптических к исходной клетке, и клеточная плоскость, созданная ранее (скажем,
клеточная плоскость с ![]() ) имеет больше возможностей для увеличения связей чем вновь созданная
клеточная плоскость, потому что она была представлена более чаще исходной
клетке. Разница в участии в возбуждающих связях отражается в связях V-клетки через вес
) имеет больше возможностей для увеличения связей чем вновь созданная
клеточная плоскость, потому что она была представлена более чаще исходной
клетке. Разница в участии в возбуждающих связях отражается в связях V-клетки через вес ![]() , который тоже изменяется в процессе обучения.
, который тоже изменяется в процессе обучения.
5 Метод обучения
Мы адаптируем параллельное конструирование, в котором обучение проходит параллельно во всех слоях нейросети.
5.1 Промежуточные уровни
S-клетки промежуточных уровней (![]() и
и ![]() ) самоорганизуются с помощью соревновательного обучения без учителя,
похожего на тот, что используется в обычном неокогнитроне (Fukushima, 2003).
) самоорганизуются с помощью соревновательного обучения без учителя,
похожего на тот, что используется в обычном неокогнитроне (Fukushima, 2003).
В процессе обучения каждая S-клетка
соревнуется с другими в своей окрестности и победители соревнования становится
исходными клетками. Как только исходная клетка определена, переменные связи ![]() и
и ![]() усиливаются в зависимоти от реакций C-клеток пресинаптических по
отношению к исходным клеткам.
усиливаются в зависимоти от реакций C-клеток пресинаптических по
отношению к исходным клеткам.
Пусть клетка ![]() выбрана исходной клеткой в некоторый момент времени. Переменные связи
выбрана исходной клеткой в некоторый момент времени. Переменные связи ![]() к этой исходной клетке и, следовательно, ко всем S-клеткам в этой
клеточной плоскости увеличиваются на следующее число:
к этой исходной клетке и, следовательно, ко всем S-клеткам в этой
клеточной плоскости увеличиваются на следующее число:
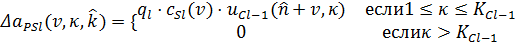 (20)
(20)
Следует отметить здесь, что количество
пресинаптических C-клеточных плоскостей, ![]() , не постоянно, а увеличивается в процессе обучения. Уравнение (20)
означает, что
, не постоянно, а увеличивается в процессе обучения. Уравнение (20)
означает, что ![]() не изменяется если пресинаптическая клетка
не изменяется если пресинаптическая клетка ![]() еще не создана. Положительная константа
еще не создана. Положительная константа ![]() определяет скорость обучения.
определяет скорость обучения.
Вес ![]() определяется следующим уравнением:
определяется следующим уравнением:
![]() (21)
(21)
где ![]() это функция, определённая как:
это функция, определённая как:
![]() (22)
(22)
и ![]() определяет сколько раз κ-я C-клеточная плоскость использовалась
для тренировки
определяет сколько раз κ-я C-клеточная плоскость использовалась
для тренировки ![]() -й S-клеточной плоскости. А именно,
-й S-клеточной плоскости. А именно, ![]() увеличивается каждый раз, когда S-клетка выбирается как исходная, если
κ-я C-клеточная плоскость уже создана к этому моменту:
увеличивается каждый раз, когда S-клетка выбирается как исходная, если
κ-я C-клеточная плоскость уже создана к этому моменту:
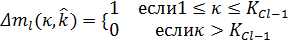 (23)
(23)
Тормозящая связь ![]() определяется прямо из значений возбуждающих связей
определяется прямо из значений возбуждающих связей ![]() и соответствующих весов
и соответствующих весов ![]() :
:
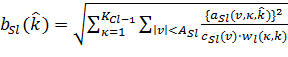 (24)
(24)
Для других клеточных плоскостей из
которых не выбрано ни одной исходной клетки (![]() ), все эти значения, а именно
), все эти значения, а именно ![]() ,
, ![]() и
и ![]() не изменяются в этот момент.
не изменяются в этот момент.
Метод двойного порога (Fukushima & Tanigawa, 1996) также
используется для обучения: соревнование между S-клетками основывается на
реакциях с высоким пороговым значением ![]() , и сигналах, которые посылаются в следующий уровень вычисляется с
малым пороговым значением
, и сигналах, которые посылаются в следующий уровень вычисляется с
малым пороговым значением ![]() .
.
Чтобы быть более конкретным, выходы
S-клеток вычисляются формулой (18), используя пороговое значение ![]() . Соревнование между S-клетками основывается на их выходах. Как только
исходная клетка выбрана из
. Соревнование между S-клетками основывается на их выходах. Как только
исходная клетка выбрана из ![]() и связи усилены по формулам (20), (23) и (24), выходы S-клеток
вычисляются снова, используя уже обновленные связи и уменьшенный порог
и связи усилены по формулам (20), (23) и (24), выходы S-клеток
вычисляются снова, используя уже обновленные связи и уменьшенный порог ![]() . Далее выходы S-клеток посылаются на следующий уровень. Таким образом,
во время фазы распознавания после завершения обучения, используется всегда
меньший порог
. Далее выходы S-клеток посылаются на следующий уровень. Таким образом,
во время фазы распознавания после завершения обучения, используется всегда
меньший порог ![]() .
.
5.2 Наивысший уровень
S-клетки наивысшего уровня (![]() ) тренируются используя соревновательное обучение с учителем (Fukushima, 2003). Обучающие правила напоминают
соревновательное обучение, используемое для тренировки
) тренируются используя соревновательное обучение с учителем (Fukushima, 2003). Обучающие правила напоминают
соревновательное обучение, используемое для тренировки ![]() и
и ![]() , но классовые имена тренировочных образов также используются для
обучения. Когда нейросеть учит множества деформированных тренировочных образов
через соревновательно обучение, создается обычно более одной клеточной
плоскости в
, но классовые имена тренировочных образов также используются для
обучения. Когда нейросеть учит множества деформированных тренировочных образов
через соревновательно обучение, создается обычно более одной клеточной
плоскости в ![]() . Поэтому, когда каждая клеточная плоскость впервые учит тренировочный
образ, классовое имя тренировочного образа присваивается этой клеточной
плоскости. Таким образом, каждая клеточная плоскость
. Поэтому, когда каждая клеточная плоскость впервые учит тренировочный
образ, классовое имя тренировочного образа присваивается этой клеточной
плоскости. Таким образом, каждая клеточная плоскость ![]() имеет метку, указывающую на одну из 10 цифр.
имеет метку, указывающую на одну из 10 цифр.
Каждый раз при демонстрации тренировочного образа, возникает соревнование между всеми S-клетками в слое. Если победитель воревнования имеет такую же метку как и тренировочный образ, победитель становится исходной клеткой и обучается тренировочному образу таким же способом, как и исходные клетки нижних уровней. Однако, если победитель имеет неправильную метку (или ни одна из клеток не выиграла соревнования), создается новая клеточная плоскость и ей присваивается классовая метка тренировочного образа.
Соревнование между S-клетками
возникает также в фазе распознавания, и метка S-клетки слоя ![]() с максимальным выходом определяет результат распознавания. Мы можем
также выразить этот процесс распознавания следующим образом. Распознающий слой
с максимальным выходом определяет результат распознавания. Мы можем
также выразить этот процесс распознавания следующим образом. Распознающий слой ![]() имеет 10 C-клеток, соответствующих 10 распознающимся цифрам. Каждый
раз, когда создаётся новая клеточная плоскость в слое
имеет 10 C-клеток, соответствующих 10 распознающимся цифрам. Каждый
раз, когда создаётся новая клеточная плоскость в слое ![]() в процессе обучения, возбуждающие связи создаются от всех S-клеток
клеточной плоскости к C-клеткам с этой классовой меткой. Только одна S-клетка
со всего слоя
в процессе обучения, возбуждающие связи создаются от всех S-клеток
клеточной плоскости к C-клеткам с этой классовой меткой. Только одна S-клетка
со всего слоя ![]() с максимальным выходном может передать свои выходы на вход слою
с максимальным выходном может передать свои выходы на вход слою ![]() .
.
В обычном неокогнитроне, порог
наивысшего уровня для фазы обучения был выбран таким же низким как и для фазы
распознавания, а именно, ![]() (Fukushima, 2003). Однако, в
представленной системе более высокий порог используется для фазы обучения,
потому что низкий порог порождает большую область допуска вокруг каждого
ссылочного вектора. Если мы используем низкий порог, граница между двумя
различными классами регулируется шаг за шагом созданием новых клеточных
плоскостей для ошибочно распознаных тренировочных образов, и в итоге
стабилизируется на балансе двух классов. Например, в эксперименте B, который
будет рассматриваться ниже в разделе 6.2 любой из тренировочных образов для
классов '0'-'4' ни разу не представлялись во время второй фазы обучения, в
которой нейроветь учит тренировочные образы классов '5'-'9'. Так как ни один
образ из класса не представлен во второй фазе обучения, граница этого класса
может быть захвачена другими классами. Однако, если порог высокий каждая
клеточная плоскость имеет маленькую допустимую область вокруг своего ссылочного
вектора, и не вторгается глубоко на территории других классов. Мы выбираем этот
высокий порог для защиты старых связей от разрушения инкрементальным обучением.
(Fukushima, 2003). Однако, в
представленной системе более высокий порог используется для фазы обучения,
потому что низкий порог порождает большую область допуска вокруг каждого
ссылочного вектора. Если мы используем низкий порог, граница между двумя
различными классами регулируется шаг за шагом созданием новых клеточных
плоскостей для ошибочно распознаных тренировочных образов, и в итоге
стабилизируется на балансе двух классов. Например, в эксперименте B, который
будет рассматриваться ниже в разделе 6.2 любой из тренировочных образов для
классов '0'-'4' ни разу не представлялись во время второй фазы обучения, в
которой нейроветь учит тренировочные образы классов '5'-'9'. Так как ни один
образ из класса не представлен во второй фазе обучения, граница этого класса
может быть захвачена другими классами. Однако, если порог высокий каждая
клеточная плоскость имеет маленькую допустимую область вокруг своего ссылочного
вектора, и не вторгается глубоко на территории других классов. Мы выбираем этот
высокий порог для защиты старых связей от разрушения инкрементальным обучением.
Однако порог не должен быть выше ![]() . Если мы имеем
. Если мы имеем ![]() , каждый тренировочный образ создаёт свою клеточную плоскость, и слой
, каждый тренировочный образ создаёт свою клеточную плоскость, и слой ![]() ведёт себя как классификатор ближайшего соседа.
ведёт себя как классификатор ближайшего соседа.
6 Компьютерное моделирование
6.1 Масштабирование нейросети
Мы тестировали поведение предложеной
нейросети с помощью компьютерного моделирования, используя рукописные цифры,
случайно выбранные из базы ETL1 2. Кстати, ETL1 это база сегментированных
рукописных символов. Нейросеть имеет такой же масштаб и параметры как и та, что
описана Fukushima (2003), кроме количества
V-клеточных плоскостей. То есть, общее количество клеток (не считая тормозящие
V-клетки) в каждом слое: ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() . Хотя количество клеток в каждой клеточной плоскости было заранее
установлено для всех слоёв, количество клеточных плоскостей в S-клеточном слое
(
. Хотя количество клеток в каждой клеточной плоскости было заранее
установлено для всех слоёв, количество клеточных плоскостей в S-клеточном слое
(![]() ) определяется автоматически в процессе обучения в зависимости от
тренировочного множества. На всех уровнях, кроме наивысшего, количество
клеточных плоскостей C-клеточного слоя (
) определяется автоматически в процессе обучения в зависимости от
тренировочного множества. На всех уровнях, кроме наивысшего, количество
клеточных плоскостей C-клеточного слоя (![]() ) такое же как и в
) такое же как и в ![]() . Распознающий слой
. Распознающий слой ![]() имеет
имеет ![]() клеточных плоскостей, соответствующих десяти цифрам, и каждая клеточная
плоскость содержит только одну C-клетку. Пороги S-клеток были выбраны следующим образом. Для слоя, распознающего края,
клеточных плоскостей, соответствующих десяти цифрам, и каждая клеточная
плоскость содержит только одну C-клетку. Пороги S-клеток были выбраны следующим образом. Для слоя, распознающего края, ![]() вы выбираем
вы выбираем ![]() . Для более высоких уровней
. Для более высоких уровней ![]() ,
, ![]() и
и ![]() , пороги для распознавания (а именно, пороги для вычисления ответов S-клеток) были
, пороги для распознавания (а именно, пороги для вычисления ответов S-клеток) были ![]() ,
, ![]() ,
, ![]() . Те для обучения (а именно, пороги, используемые для соревнования)
были:
. Те для обучения (а именно, пороги, используемые для соревнования)
были: ![]() ,
, ![]() . Однако для наивысшего уровня мы использовали
. Однако для наивысшего уровня мы использовали ![]() вместо
вместо ![]() что было использовано в предыдущей нейросети (Fukushima, 2003). Параметр
что было использовано в предыдущей нейросети (Fukushima, 2003). Параметр ![]() в уравнении (22) (или (12)) был задан как 0.5.
в уравнении (22) (или (12)) был задан как 0.5.
6.2 Скорость распознавания
Чтобы продемонстрировать, что нейросеть принимает инкрементальное обучение, мы будет показывать как уровень распознавания изменяется в зависимости от двух различных вариантов представления образов в обучении.
Эксперимент А. Нейросеть учит один тренировочный набор, состоящий из образов всех классов, а именно, рукописные цифры от '0' до '9'. Тренировочный набор имеет одинаковое количество образов для каждого класса. Образы выбраны случайным образом из базы ETL1. Чтобы протестировать как уровень распознавания изменяется в зависимости от общего числа образов в тренировочном наборе, мы подготовили тренировочные набор, состоящие из 500, 1000, 2000, и 3000 образов. Тренировочное множество из 500 образов является подмножеством 1000, которое в свою очередь является подмножеством 2000 и так далее. Образы в тренировочном множестве представлены в следующем порядке: ‘0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’, ‘0’, ‘1’,… Тренировочное множество представлено три раза нейросети.
После окончания обучения, уровень распознавания нейросети измеряется с помощью слепого набора тестов. Слепое множество тестов состоит из 3000 цифр (300 образов каждого класса), которые также выбираются случайным образом из ETL1 базы, но так, чтобы не было повторений с тренировочным множеством.
Эксперимент В. Тренировочное множество, используемое для эксперимента А делится на два: одно, состоящее из цифр от '0' до '4', и второе из цифр от '5' до '9'. Нейросеть изначально учит первый тренировочный набор. Образы представлены в следующем порядке: ‘0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘0’, ‘1’, ‘2’,… После завершения обучения первому тренировочному множеству, нейросеть учит второе Таблица 1. Скорости распознавания нейросети для экспериментов А и В с использованием тренировочных множеств разных размеров
|
Нейросеть |
Метод конструирования |
Тренировочные образы |
Скорость обучения (%) для тестового множества |
Масштабирование нейросети |
||||||
|
Метод представления |
Количество образов |
После |
'0'-'4' |
'5'-'9' |
'0'-'9' |
|
|
|
||
|
Новая |
Паралл. |
Одновременный (эксперимент А) |
500 |
|
96.2 (100) |
97.0 (100) |
96.6 (100) |
28 |
86 |
74 |
|
1000 |
|
96.5 (99.8) |
98.2 (100) |
97.3 (99.9) |
36 |
104 |
103 |
|||
|
2000 |
|
98.2 (99.9) |
98.5 (100) |
98.3 (100) |
43 |
128 |
146 |
|||
|
3000 |
|
98.1 (100) |
98.5 (99.9) |
98.3 (100) |
45 |
140 |
179 |
|||
|
Инкрементальный (эксперимент B) |
500 |
1/2 |
98.3 (100) |
- |
- |
24 |
64 |
27 |
||
|
|
2/2 |
94.1 (97.6) |
96.5 (100) |
95.3 (98.8) |
28 |
78 |
58 |
|||
|
1000 |
1/2 |
98.4 (100) |
- |
- |
26 |
72 |
33 |
|||
|
|
2/2 |
95.0 (99.0) |
97.5 (100) |
96.3 (99.5) |
32 |
85 |
76 |
|||
|
2000 |
1/2 |
99.1 (100) |
- |
- |
32 |
82 |
46 |
|||
|
|
2/2 |
97.5 (99.3) |
98.6 (100) |
98.0 (99.7) |
42 |
108 |
110 |
|||
|
3000 |
1/2 |
99.3 (100) |
- |
- |
35 |
91 |
57 |
|||
|
|
2/2 |
98.1 (99.1) |
98.7 (99.9) |
98.4 (99.5) |
48 |
129 |
126 |
|||
|
Старая |
Послед. |
|
|
|
98.3 (100) |
98.9 (100) |
98.6 (100) |
39 |
110 |
103 |
|
Паралл. |
|
|
|
98.4 (100) |
98.2 (99.7) |
98.3 (99.9) |
45 |
241 |
325 |
|
тренировочное множество. После завершения первой и второй половины обучения, уровень распознавания нейросети была измерена с помощью слепого тестового множества. Следует отметить здесь, что не производилось дополнительного обучения для первого тренировочного множества после начала второго обучения.
Таблица 1 обобщает уровни распознавания в этих различных условиях. Числа в скобках обозначают уровни распознавания для тренировочных множеств. Уровни распознавания для '0'-'4' и '5'-'9' были отдельно подсчитаны, так же как и для всех образов '0'-'9', в таблице. Также перечислены количества клеточных плоскостей созданных по окончанию обучения. Что касается эксперимента В, уровни распознавания после окончания первой фазы обучения также отмечены в таблице.
Как может быть видно из таблицы, уровни распознавания в экспериментах А и В почти одинаковые. Они иногда немного лучше в эксперименте А, а иногда лучше в эксперименте В, в зависимости от количества тренировочных образов. Когда мы использовали 3000 тренировочных образов, например, уровни обучения для эксперимента А и В были 98.3 и 98.4%, соответственно. Интересно заметить,
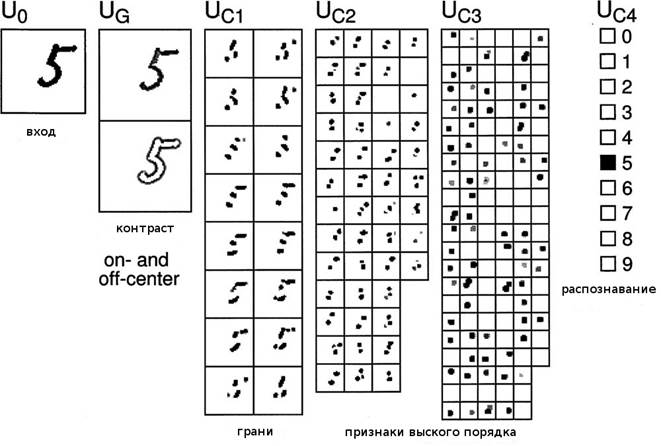
Рисунок 4. Пример распознавания неокогнитроном. Он был обучен
тренировочным множествам '0'-'4' сначала, потом множеством '5'-'9'. Входной
образ распознан правильно как '5'.
что количество клеточных плоскостей меньше в эксперименте В. Эти результаты показывают, что память первого обучения не сильно повреждена вторым обучением. Другими словами, предлагаемый неокогнитрон принимает инкрементальное обучение без нанесения серьёзного ущерба старым клеткам.
Для вашей информации, вторая строка с конца таблицы 1 показывает результаты для обычного неокогнитрона, в котором процесс обучения последователен от нижних до высших уровней (Fukushima 2003). Сравнивая полученные результаты, мы может видеть, что новый неокогнитрон показывает сравнительно высокий уровень распознавания без особого увеличения количества клеточных плоскостей, даже с параллельным конструированием, или даже использовано инкрементальное обучение.
Кстати, если параллельное конструирование применить к обычному неокогнитрону с теми же параметрами, будет генерироваться большое количество клеточных плоскостей, как показано в последней строке таблицы 1. Такое большое количество клеточных плоскостей практически неприемлемо. Вероятно было создано много мусорных клеток в нейросети. Уровень распознавания, однако, был 98.3% и был почти такой же как и для предлагаемой нейросети.
Рисунок 4 показывает ответ нейросети,
которая завершила обучение в эксперименте В, используя тренировочное множество
из 3000 образов. Ответы слоёв ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() и
и ![]() показаны в сериях слева направо. Самый правый слой,
показаны в сериях слева направо. Самый правый слой, ![]() , распознающий слой, чей ответ показывает финальный результат
распознавания.
, распознающий слой, чей ответ показывает финальный результат
распознавания.
7 Дискуссия
Эта работа предлагает новый неокогнитрон, принимающий инкрементальное обучения, без нанесения серьёзного ущерба старым клеткам или замедления скорости обучения. Новый неокогнитрон использует соревновательное обучение, и обучение всех уровней иерархической сети проходит параллельно с высокой скоростью обучения. Клетки в высоких уровнях адаптируются к изменениям в предшествующих уровнях сети, и может быть предотвращено создание мусорных клеток, которые никогда не реагируют после окончания обучения.
Различные системы для инкрементального обучения были предложены до сих пор (Carpenter, Grossberg, & Reynolds, 1995; Hoya & Chambers, 2001; Molina & Niranjan, 1996; Platt, 1991; Polikar, Udpa, Udpa, & Honavar, 2001; Williamson, 1996; Yamauchi, 2001; Yamauchi, Yamaguchi, & Ishii, 1999; Yingwei, Sundararajan, & Saratchandran, 1997). Большинство из них комбинируют различные методы для защиты старых клеток от разрушения инкрементальным обучением или восстановления поврежденных.
Некоторые из них пытаются удалять мусорные клетки, которые были созданы в процессе обучения. Другая группа методов пытается переобучать мусорные клетки для других целей. Однако сложно определить является ли клетка мусорной или нет как только она была создана в нейросети. Мы не можем использовать «зажигающую» вероятность или использовать силу ответа клеток как критерий для нахождения мусорных клеток. В эксперименте В, рассмотренном в разделе 6.2, например, любой из тренировочных образов для классов '0'-'4' ни разу не был представлен во время второй фазы обучения, в которой нейросеть учила тренировочные образы для классов '5-'9'. Так как тренировочные образы для классов '0'-'4' ни разу не были представлены во время второй фазы обучения, клетки необходимые для распознавания '0'-'4' могли вообще не реагировать. Мы не должны удалять клетки просто потому что они не реагируют во время второй фазы обучения.
Некоторые методы используют распад или забывающий фактор в переменных соединениях для адаптации к изменению вероятности появления тренировочных образов. Эти методы, однако, могут плохо работать в ситуациях как в эксперименте В. Память для '0'-'4' может исчезать в процессе обучения '5'-'9'.
В отличие от этих обычных методов обучения, наш метод обучения подавляет создание мусорных клеток, вместо удаления их после создания. Клетки в высоких уровнях адаптируются к изменениям в предшествующих уровнях иерархической нейросети, для продолжения исполнения своего предназначения. Так как клетки могут менять свои входные соединения только в случае победы, старая память хранящаяся в соединениях не разрушается даже если клетки не реагируют долгое время.
Некоторые другие традиционные методы предлагают хранить типичные примеры старых тренировочных образов и переобучать их для восстановления старой память, поврежденной инкрементальным обучением. Наш метод обучения не требует такого хранения.
В секции 3.2 мы предположили, что ![]() может быть аппроксимирована уравнением (10) и положить
может быть аппроксимирована уравнением (10) и положить ![]() . Размышляя о возможности упрощения правила обучения, мы попробовали
другую аппроксимацию для
. Размышляя о возможности упрощения правила обучения, мы попробовали
другую аппроксимацию для ![]() , а именно
, а именно ![]() , с помощью которой мы может иметь
, с помощью которой мы может иметь ![]() . Однако компьютерное моделирование показало, что уровень распознавания
при такой простой аппроксимации было немного хуже чем для формулы (10).
. Однако компьютерное моделирование показало, что уровень распознавания
при такой простой аппроксимации было немного хуже чем для формулы (10).
Перечень ссылок
Carpenter, G. A., Grossberg, S., & Reynolds, J. H. (1995). A fuzzy ARTMAP nonparametric probability estimator for nonstationary pattern recognition problems. IEEE Transactions on Neural Networks, 6(6), 1330–1336.
Fukushima, K. (1980). Neocognitron: a self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, 36(4), 193–202.
Fukushima, K. (2003). Neocognitron for handwritten digit recognition1. Neurocomputing, 51C, 161–180.
Fukushima, K., & Miyake, S. (1982). Neocognitron: a new algorithm for pattern recognition tolerant of deformations and shifts in position. Pattern Recognition, 15(6), 455–469.
Fukushima, K., & Tanigawa, M. (1996). Use of different thresholds in learning and recognition. Neurocomputing, 11(1), 1–17.
Hoya, T., & Chambers, J. A. (2001). Heuristic pattern correction scheme
using adaptively trained generalized regression neural networks. IEEE Transactions on Neural Networks, 12(1), 91–100.
Molina, C., & Niranjan, M. (1996). Pruning with replacement on limited resource allocating networks by F-projections. Neural Computation, 8(4), 855–868.
Platt, J. (1991). A resource allocating network for function interpolation. Neural Computation, 3(2), 213–225.
Polikar, R., Udpa, L., Udpa, S. S., & Honavar, V. (2001). Learn ++ an
incremental learning algorithm for supervised neural networks. IEEE Transactions on Systems, Man and Cybernetics, Part C, 31(4), 497–508.
Williamson, J. R. (1996). Gaussian ARTMAP: a neural network for fast incremental learning of noisy multidimensional maps. Neural Networks, 9(5), 881–897.
Yamauchi, K. (2001). Sequential learning and model selection with sleep. In L. Zhang, & F. Gu (Eds.), (vol. 1) (pp. 205–210). ICONIP 2001 (Eighth international conference on neural information processing), Shanghai: Fudan University Press.
Yamauchi, K., Yamaguchi, N., & Ishii, N. (1999). Incremental learning methods with retrieving interfered patterns. IEEE Transactions on Neural Networks, 10(6), 1351–1365.
Yanagawa, K., Fukushima, K., & Yoshida, T. (2002). Additional learnable neocognitron (in Japanese). Technical report of IEICE, No. NC2001-176.
Yingwei, L., Sundararajan, N., & Saratchandran, P. (1997). A sequential learning scheme for function approximation using minimal radial basis function neural networks. Neural Computation, 9, 461–478.