Параллельные вычислительные процессоры NVIDIA: настоящее и будущее
Авторы: © МИР NVIDIA, 2000–2013
Источник: http://nvworld.ru/articles/cuda_parallel/
Авторы: © МИР NVIDIA, 2000–2013
Источник: http://nvworld.ru/articles/cuda_parallel/
Когда пишут об архитектуре NVIDIA CUDA, принято начать с экскурса в историю развития GPU, роста их функциональных возможностей, как они, шаг за шагом, превращались в универсальные вычислительные устройства. Но, в данной статье этому не будет уделено никакого внимания, видеоускорители уже эволюционировали в процессоры. И разработчикам, и пользователям программного обеспечения в принципе все равно, был ли этот путь ровным или извилистым. Как правило, новые процессорные архитектуры — есть эволюционное развитие предшествующих. Например, не будет очень большим преувеличением сказать, что процессор Core есть сильно улучшенный, доведенный до архитектурного совершенства, многоядерный Pentium II–III. А процессоры Phenom отличаются от первых Атлонов поддержкой SSE, прикрученным контроллером памяти, большими кэшами, 64-битным расширением набора инструкций и мелкими архитектурными улучшениями, такими как предвыборка данных и новые алгоритмы предсказания условных переходов. Но это нельзя сказать о технологии CUDA. Это принципиально новая архитектура, которая стала возможной только благодаря невероятному улучшению технологических процессов за последние годы. Миллиарды транзисторов на кристалл обернулись сотнями вычислительных CUDA-модулей. Причем, важно, что этот рост техпроцесса произошел «вширь», а не «вглубь». То есть, вылился не в повышение тактовой частоты, а именно в увеличение площадей кристалла. Если бы открыли какой-то способ повышения тактовой частоты, вместо утончения норм производства, то ни о какой CUDA и речи бы ни шло. Так как современные, высоко конвейеризированные CPU достигли бы высоких частот и превосходной производительности в однопоточном режиме, а места для большого количества низкочастотных по своей природе CUDA-процессоров, на кристалле не нашлось бы.
Но случилось так, как случилось и технологии многоядерной мультипоточности, среди которых CUDA — самая радикальная, выходят на первый план.
Итак, суть архитектуры — это размещение на кристалле нескольких десятков процессорных ядер с собственной памятью, каждое из которых одновременно выполняет несколько сотен программных потоков. И, в данном случае термин «нить», как нельзя лучше подходит для описания одной из тысяч параллельно выполняющихся частей CUDA-программы. Как будет описано далее, эти нити переплетаются между собой и они ещё сплетены в более крупные структуры, как отдельные тонкие провода в большом кабеле. Процессорные ядра, называемые в CUDA-терминологии мультипроцессорами, имеют собственный доступ к глобальной памяти, расположенной на видеоплате и устройство обменивается данными с CPU через шину PCI-Express.
Всегда модно сравнивать скорость современных настольных компьютеров с суперкомпьютерными системами прошлого, восхищаясь ростом производительности. Но архитектура настольных процессоров, до самого последнего времени была максимум двухпоточной, и пусть четырехъядерные процессоры появились в изобилии на рынке, двуядерные модели также продолжают вовсю выпускаться. В этом плане, CUDA-устройство гораздо больше похоже по архитектуре на настоящий кластерный суперкомпьютер из сотен вычислительных узлов. Только размещенный на одном кристалле. И разные элементы архитектуры взяты из суперкомпьютеров самых разных лет.
Необходимо сразу отметить, что программироваться это CUDA-устройство должно по принципам настоящего суперкомпьютера. С мерками программирования для PC, к нему подходить нельзя.
Есть два факта, их можно назвать законами вычислительной техники, которые составляют теоретическую основу востребованности высокопараллельных вычислительных архитектур. Потребляемая мощность процессора пропорциональна примерно квадрату тактовой частоты, примерно степени 2,5. То есть, процессор с тактовой частотой 3 ГГц потребляет больше, чем 9 процессоров частотой 1 ГГц. Таким образом, для параллельной программы энергоэффективность массы мелких процессоров будет выше в три раза. Иными словами, многоядерный процессор, с той же потребляемой энергией, будет в три раза производительнее при исполнении параллельного кода.
Второй факт относится уже к программному обеспечению и алгоритмам. Если задача распараллеливается, то есть, допускает реализацию с помощью параллельного алгоритма, который может исполняться одновременно на нескольких процессорах, то чем на большее количество потоков она уже распараллелена, то тем больше вероятность, что задача может быть распараллелена на ещё большее количество потоков. Например, большое количество задач не допускает параллельной реализации, многие распараллеливаются только на два потока, а если алгоритм допускает три потока, то весьма вероятно, что он распараллелиться и на четыре и на пять и на шесть потоков.
А если программа имеет десять потоков, то, скорее всего, можно будет использовать и двадцать, и пятьдесят нитей. И дальше — больше: где сто, там и тысяча. И так далее. Таким образом, если отправляться в мир параллельных вычислений, то имеет смысл бросаться, как в омут головой. Потому, что после превышения количества потоков определенной величины уже становится безразлично, сколько их, их просто много.
Такая ситуация типична для вычислительных задач с большими объемами данных, которые по своей природе, в принципе, допускают параллельный алгоритм решения. А если такого нет, то можно и не надеяться на увеличение производительности в обозримом будущем, ибо тактовая частота современных CPU растет очень медленно. В таких случаях, выгодно реализовать многопоточный алгоритм, пусть он будет и на порядок более вычислительно затратным, все равно, площади кристаллов девать некуда и, на мультипроцессорной системе такой, сам по себе малоэффективный алгоритм, будет работать быстрее. Но, уже имея задачу с тысячами потоков, можно заранее адаптировать вычислительную архитектуру с учетом мультипоточности, сконцентрироваться на общей производительности программы, а не каждой отдельной нити, сильно сэкономив на многих традиционных архитектурных деталях.
Важно также, что конструировать низкочастотный процессор гораздо легче. Проще реализовать разнообразную сложную логику, большинство инструкций исполняются за один такт, что упрощает планировщик выполнения инструкций и требует меньшего количества разнообразных буферов и очередей инструкций. А также упрощает и делает более удобной саму ISA. (ISA — Instruction Set Architecture, архитектура системы команд). И пропускная способность памяти растет гораздо быстрее, чем уменьшается её латентность. Таким образом, обеспечить данными множество низкочастотных CPU гораздо проще и дешевле, чем один высокочастотный. Так как он будет часто простаивать, в ожидании данных из медленной памяти.
Эти факты, взятые вместе, делают многопоточную технологию CUDA востребованной и перспективной.
Среди всевозможных компьютерных задач можно выделить три больших класса: серверные задачи работы с базами данных, задачи управления (например, внутренняя логика какой–нибудь компьютерной игры или симулятора) и вычислительные задачи. Архитектура CUDA, в её текущей аппаратной реализации ориентирована, в первую очередь, на вычислительные задачи. Так называемые compute bound applications. Это не обязательно решение математических уравнений, это может быть и обработка изображений, и проверка ключей, и анализ строк. Но суть в том, что надо считать, считать и считать, а не различные функции вызывать с ветвлениями.
Итак, возьмем для конкретности последнюю реализацию CUDA в графическом процессоре GT200. Он имеет 30 мультипроцессоров, один мультипроцессор работает на частоте примерно 1,4 GHz, имеет 8 исполнительных устройств общего назначения, выполняющих за такт типичные операции, как то: сложение и умножение вещественных чисел типа float, сравнения, условные переходы, логические операции, операции с регистрами.
Один мультипроцессор может одновременно выполнять 1024 программных нитей. Но исполнительных устройств всего 8, не считая специального устройства вычисления библиотечных функций типа синуса и косинуса. Поэтому инструкции всех 1024 потоков в один момент исполняться не могут. Нити разбиты на группы по 32 штуки, называемые warp. Этот термин можно художественно перевести как пучок нитей, само английское значение слова имеет, видимо, морское происхождение, связанное с тросами. Очень, кстати, показательно. В один момент исполняется один варп, он исполняется 4 такта (8 исполнительных устройств за 4 такта исполняют 32 операции). Если там нет длинной специальной инструкции. Но, из всех 32 нитей, в один заход реально исполняются только те, которые находятся в одном месте программы. То есть, исполняют одну и ту же инструкцию программы. Техническими словами, если совпадают указатели инструкций, другими словами — адреса инструкций в коде программы.
Каждая нить CUDA-приложения исполняет одну и ту же программу, но алгоритму доступен номер нити среди всех запущенных, и поэтому алгоритм может произвольно меняться, в зависимости от её номера. Можно запустить хоть 10000 различных подпрограмм, для каждой нити выбрав свою, в самом начале кода. Но это будет неэффективно, из-за вышеприведенной особенности исполнения варпа целиком. Когда все нити, внутри каждого варпа, имеют одинаковый путь исполнения, достигается максимальная производительность.
Если ветвления, в программе нити, уводят её в сторону от других, она начинает исполнять отдельный кусок программы, тогда время исполнения мультипроцессором целого варпа удваивается. Потому, что сначала он исполняет инструкцию, соответствующую 31 нити, а потом инструкцию оставшейся нити. Если половина варпа, 16 нитей, будет в одном месте программы, а другая половина — в другом, то варп тоже будет исполняться в два раза медленней. А если все нити варпа разбредутся по разным частям программы и будут выполнять каждая свои инструкции, то скорость упадет в 32 раза.
Но, именно для вычислительных задач, такой сильный разброс не характерен и с ним можно успешно бороться, что определяет наилучшую область применения технологии. В плотных вычислительных циклах нити имеют, как правило, сходный путь. Впрочем, даже при полностью сериализованном (от английского слова serial), иными словами, последовательном исполнении, CUDA-устройство имеет неплохую производительность, благодаря большому количеству мультипроцессоров и достаточно высокой тактовой частоте. И генератор машинного кода для CUDA анализирует программу, детектирует циклы и вставляет точки реконвергенции для нитей, где они ждут друг друга, если расходились, чтобы дальше пойти дружным шагом, а не совсем разбредаться из-за первого же дивергентного ветвления.
И, надо сказать, что уже различные варпы, то есть пучки или связки нитей по 32 штуки, могут выполняться полностью независимо. Каждый варп может выполнять инструкции из любого места программы. Имея 1024 нити, в стадии выполнения на мультипроцессоре, можно, таким образом, иметь 32 активных варпа, исполняющихся параллельно. Для исполнения выбирается тот варп, для инструкций которого подгружены данные из глобальной памяти, т.е. который готов для исполнения.

Схематическое изображение исполняющейся CUDA-программы «в разрезе». Большие синие прямоугольники обозначают 30 мультипроцессоров. На каждом 4 активных блока нитей, обозначенных кружками. Каждый блок состоит из 4 варпов по 32 нити. Варп обозначен прямоугольником. Варп состоит из двух полуварпов по 16 нитей. Каждая нить обозначена точкой. Итого имеем 15360 (30*4*4*32) одновременно исполняющихся нитей.
Память, в текущих CUDA-устройствах, находится на отдельных микросхемах на видеоплате, как системная память на системной. Поэтому, время доступа к ней исчисляется несколькими сотнями тактов. Но, имея сотни исполняющихся нитей, можно частично скрыть эту латентность, все равно в один момент может исполняться только группа из 32 нитей. Остальные пока подождут данных. Таким образом, можно сэкономить на размерах различных кэшей и, вместо памяти, на кристалле разместить ещё больше исполнительных устройств. Вот в этом проявляется использование существенной многопоточности алгоритма.
Также, есть одна специальная возможность, доставшаяся от далеких предков: это доступная только для чтения текстурная память, которая читается при помощи текстурных блоков. Она имеет небольшой кэш 6–8 Кб на мультипроцессор и общий L2-кэш 256 Кб на всё устройство. С её помощью, можно ускорить доступ к немодифицируемым, в процессе работы программы, данным. Можно сказать, исходным данным. Текстурные кэши оптимизированы для двумерных массивов, что предоставляет неплохую оптимизационную возможность для приложений, которые работают с данными такого типа, изображениями например.
Но все же, латентность глобальной памяти очень велика, её легче скрыть, если она читается по такой схеме: последовательно читаются данные, они обрабатываются и в глобальную память пишется результат.
Но часто бывает, что нужно хранить большой объем промежуточных вычислений. Для этого существует локальная память мультипроцессора, которая в CUDA-терминологии называется разделяемой (shared). Потому, что она общая для всех нитей одного блока. Да, нити объединяются в блоки, это задается программистом при запуске программы. В отличие от размера варпа, равного 32 нитям и задаваемого требованиями железа, размер блока может варьироваться. Для простоты изложения концепции можно было бы считать, что в один момент мультипроцессор может исполнять один блок, состоящий из 1024 нитей, который обладает всей локальной памятью мультипроцессора, которая вся целиком доступна каждой нити блока. Но в реальности, размер блока может быть любым, в пределах 512 нитей и кратным размеру варпа, и мультипроцессор может одновременно выполнять несколько блоков, и память мультипроцессора, в этом случае, делится поровну между этими блоками.
Размер этой памяти составляет всего 16 Кб. Но это соизмеримо с размером кэша данных первого уровня современных процессоров, средняя скорость доступа к ней довольно высока и составляет несколько тактов.
Таким образом, CUDA-программа может работать с памятью по одной из двух схем: либо читать и писать все в глобальную память, надеясь на то, что количество потоков, в значительной мере скроет латентность, либо разбить данные задачи на куски и последовательно помещать их в локальную память для обработки.
Первый вариант оправдан, если программа перенасыщена вычислениями и читает, а также пишет в память относительно редко. Второй вариант предпочтительнее, он позволяет достичь близкой, к теоретическому максимуму, производительности, но не всегда возможен. Но первый легко программировать, не требуется специальной оптимизации. Возможна и комбинация двух подходов.
Также есть общая для всех нитей, доступная только для чтения, память программных констант, размером 64 Кб, с быстрым доступом. У каждого мультипроцессора есть 8 Кб специального кэша для констант.
Помимо разделяемой памяти блока и общей глобальной памяти, каждой нити доступны собственно её регистры. Типичное их количество — 32 обычных 32-битных регистров. Точное количество регистров задается программистом, от этого зависит максимальное количество нитей, выполняющихся на мультипроцессоре, поскольку каждый мультипроцессор имеет банк из 16384 регистров, которые делятся между нитями.
И опять, благодаря большому количеству нитей на мультипроцессоре, можно полностью скрыть латентность доступа к файлу регистров и иметь много регистров. Сама же ISA вполне обычна, это очень стандартный, простой и компактный, так называемый скалярный RISC с некоторыми важными ограничениями: GT200 не поддерживает С++, то есть, нет виртуальных функций и нет рекурсивных функций. Потому, что нет стека, все на регистрах. Для вычислительных задач это непринципиальный момент, все равно, в главных вычислительных циклах нельзя пользоваться виртуальными функциями, а рекурсивный алгоритм можно изменить так, чтобы не было вызова функций.
Широко используются предикатные регистры, то есть значение регистра устанавливается в зависимости от значения логического выражения, вроде (a>b), которое либо истина, либо ложь. И далее, в коде следующей инструкции, например, перехода, задается, при каком значении какого предикатного регистра она выполняется. Так, переход становится условным. Очень удобно, на самом деле, и для компиляторов, и для ручного кодирования.
Что нужно сделать, чтобы запустить CUDA-программу? Надо загрузить исходные данные в память CUDA-устройства и запустить саму исполняемую функцию, указав ей количество нитей в блоке и общее количество блоков. Каждая из тысяч нитей прочитает в системной переменной свой номер, в соответствии с ним — свои данные для работы и запишет в соответствующую область памяти результат.
Самый простой пример: нужно вычислить некую математическую функцию f от массива значений из 128000 элементов. Мы загружаем этот массив элементов в память устройства, запускаем программу, её код инструкций система загружает на все мультипроцессоры. При запуске мы указываем, например, размер блока 128 нитей, а количество блоков 1000. Каждый мультипроцессор обрабатывает 8 блоков из 128 нитей, каждая нить читает, в соответствии со своим номером, элемент массива чисел, вычисляет функцию и записывает обратно. По мере выполнения всех нитей блока, мультипроцессор загружает на выполнение новые блоки. И далее, мы читаем данные из устройства обратно.
Это самый простой пример, но сразу можно сказать, что производительность его, в первую очередь, зависит от того, сколько серьезных ветвлений есть в алгоритме функции f, насколько путь исполнения зависит от значений аргумента. Если сильно дивергентных, то есть по-разному исполняющихся в зависимости от аргумента, ветвлений мало, то производительность будет очень большой.
Но нити не обязаны исполняться совсем независимо друг от друга. Для нитей внутри одного блока (это примерно 256 нитей), есть стандартные инструкции синхронизации исполнения Wait — ждать, когда все нити синхронизируются. Напомню, что нити абсолютно произвольны в своем поведении и совсем не похожи на SSE-инструкции. Есть так же инструкции атомарной записи данных в память блока, для обмена данными между нитями.
То есть, нити в одном блоке могут переплетаться между собой. А вот блоки, в рамках CUDA-идеологии, предполагаются более независимыми. Они как будто бы исполняются на разных, далеко друг от друга расположенных, кластерах одного большого суперкомпьютера. Каждый из этих кластеров получил свое задание и, в каком порядке они исполняются, программисту неизвестно. Но некоторую синхронизацию, в частных случаях, можно организовать с помощью флагов в глобальной памяти. Например, организовать счетчик выполнения и старта блоков и, в зависимости от номера, блок будет выполнять свою часть задачи. Например, последний исполняющийся блок узнает, что он последний и может выполнить специальный завершающий этап работы. Или можно запустить новую программу, новый этап вычислений, который воспользуется сохраненными в памяти GPU результатами работы предыдущей программы.
На практике, принципиальная схема создания CUDA-программы такова: поставляемый NVIDIA компилятор встраивается в среду разработки, он компилирует исходный файл с кодом функции, которая должна исполняться на устройстве и превращает его в ассемблерный код для CUDA-устройства, который присоединяется к программе, как ресурс данных. При запуске программы на конкретной системе, этот код, с помощью библиотечной функции, передается видеодрайверу, который компилирует его для имеющегося CUDA-устройства в машинный код, специфичный для данного устройства. Так обеспечивается совместимость между редакциями архитектур. И далее, с помощью вызова библиотечных функций из кода основной программы, данные загружаются в GPU и для исполнения на устройстве вызывается скомпилированная драйвером функция.
Можно также, на этапе компилирования, дополнительно создать несколько вариантов машинного кода для различных типов CUDA-GPU. Тогда драйвер, при запуске программы, может не компилировать ассемблерный код в машинный, а взять уже готовый вариант, если он существует для данного GPU. А если его нет (например, этот GPU ещё не вышел в момент написания программы), то будет компилироваться универсальный ассемблерный код.
Итак, мы ознакомились с главными моментами архитектуры CUDA, но смысл её существования в дополнительной производительности. Что можно, на данный момент, ожидать от присутствующих на рынке CUDA-устройств? Для сравнения с тридцатью мультипроцессорами архитектуры GT200, возьмем четырехъядерные Lynnfield вдвое большей частоты и сделаем, для начала, самую грубую оценку теоретического максимума в вычислениях, с вещественными числами одинарной точности. Как раз, у наиболее массовых моделей Lynnfield, частота примерно вдове выше массовых моделей GT200.
GT200, за такт, теоретически выполняет 8*30=240 инструкций, а одно ядро Lynnfield, за два такта (что соответствует одному такту GT200), начинает выполнение четырех SSE-инструкций с 4 парами float-переменных. Таким образом, получается 4 ядра*2 такта*2 инструкции*4 переменных=64 инструкции.
В теории, GT200 может быть примерно в 5 раз быстрее. Кстати, GT200 может за тот же свой такт выполнять инструкцию mul–add, умножения двух операндов и сложения с третьим. Если её посчитать, то в теории и в 10. Но на самом деле, для большинства задач, разница в этом моменте в 2 раза, что является мелочью, ничего бы не изменилось в этом мире, если бы GT200 не умел выполнять mul–add.
Но на практике, все может обернуться самым разным образом. И тот, и другой теоретический максимум, не так легко, на самом деле, достичь. В архитектуре нынешних GPU есть несколько темных углов, которые могут убить реальную производительность, даже теоретически полностью параллельного приложения. Мы их обсудим ниже. Но и Lynnfield`у не просто приблизиться к максимуму, для многих задач четырехкомпонентный SSE трудно применить, а «мягкая» модель параллельного исполнения одной инструкции 32 нитями CUDA прекрасно работает. Потому, что каждая нить CUDA-программы имеет прямой естественный доступ к своим данным, а работать с каждым элементом SSE-вектора в отдельности, непросто. И мелкие дивергенции нитей не оказывают заметного влияния на скорость. И не все программы вообще используют SSE, могут производить смешанные вычисления, но прекрасно распараллеливаемые в рамках CUDA-модели.
Потому, что модель SIMT (single instruction multiple thread — «одна инструкция, много нитей») гораздо гибче, чем SIMD (single instruction multiple data — «одна инструкция, много данных»), ибо в SIMT, эта инструкция может быть любой и в первую очередь — условным переходом. А в SIMD, если что-то случилось с одним элементом данных, который требует специальной обработки, вся параллельность пропадает и очень непросто эффективно программировать такие случаи.
Надо отметить, что и той, и другой системе, для приближения к максимуму, нужна высокая степень параллельности. И если программа эффективно использует SSE и многопоточность, то велики шансы, что она хорошо совместится с архитектурой CUDA. Потому, что два, из трех главных требований к эффективной CUDA-программе, уже частично выполнено: параллелизм на уровне потоков и на уровне инструкций. Остается только решить проблему с памятью. А без SSE, теоретический максимум Lynnfield`а уменьшится в 4 раза, но и вероятные, в такой не поддающейся SSE-оптимизации программе, дивергентные ветвления могут существенно уменьшить скорость CUDA-варианта. Может в 7 раз, а может в 3.
Уже примерный анализ теоретического максимума показывает некоторую бессмысленность его подсчета. Алгоритм может хорошо подойти высокопараллельной CUDA-архитектуре и тогда GPU выиграет с явным преимуществом в данной задаче. А в других случаях, можно получить не столь существенный прирост, не стоящий возни с технологией. Максимум скорее дает оценку, что можно ожидать от CUDA в лучшем случае. Но необходимо помнить, что использовать несколько GPU значительно дешевле, чем системы на CPU. Как известно, многопроцессорные системы — уже другой рынок с другими ценами. Даже если GT200 равен по производительности Lynnfield, можно легко собрать систему с четырьмя GT200 на одной плате, а вот систему с четырьмя CPU купить — это гораздо более ответственный шаг.
Так как CUDA-архитектура предназначена, в первую очередь для вычислений, а CPU универсальны, они выполняют множество серверных задач, для которых стоимость решения — не самый важный параметр, особенно по сравнению с совместимостью. Просто перекомпилировать многие приложения дороже, чем купить новую систему. А не то, что портировать. Но их обязательно надо исполнять и, с ростом бизнеса, потребности увеличиваются. Такой спрос на CPU автоматически удорожает их, по сравнению со специализированными устройствами.
Представьте, вы покупаете танк и вам предлагают модель, обитую изнутри дорогой обшивкой со стразами. Конечно, такая машина будет стоить дороже сходного по боевым возможностям обычного танка. Всякие олигархи захотят купить гламурный танк, и поднимут цену. А важно ли это, для боевого применения?
По мнению автора, сама программная модель CUDA, особенно после того, как туда были добавлены примитивы для атомарной записи в память, необходимые для синхронизации потоков, вполне хороша в своем классе специализированных вычислительных архитектур и завершена. Но в текущей реализации в железе, есть несколько нетривиальных тонких моментов, требующих особого внимания разработчика и пренебрежение ими может существенно снизить производительность некоторых программ. В первую очередь, это так называемый совмещенный доступ к памяти. Когда нити одного варпа или полуварпа осуществляют общую операцию чтения данных из глобальной памяти, они все должны читать данные из одного 128-байтного участка, иначе одна транзакция разобьется на множество мелких. Должна соблюдаться жесткая локальность данных внутри полуварпа и надо за этим специально следить. Иначе, программа будет слишком долго ждать данные от множества запросов на чтение. То же самое относится и к записи данных.
В архитектуре традиционных CPU, такую проблему значительно уменьшают кэши. И латентность самой памяти несколько меньше. В CUDA же, призвано на помощь большое количество активных нитей на устройстве, но при совсем нелокальном чтении всех нитей и это не спасает. Тут, кстати, и дивергентные нити плохо себя проявляют, ибо если все нити читают одновременно, то это одна транзакция, а если они выполняются последовательно и, таким образом, читают последовательно, то очень дорогостоящих операций обращения к памяти будет больше.
В ранних CUDA-устройствах, эта проблема стояла ещё более остро, нити должны были читать данные последовательно, первая нить в варпе — начальный адрес, вторая нить — последующий и так далее. В последнем, на данный момент, графическом процессоре GT200, это ограничение снято.
Момент совмещенной записи требует обязательной оптимизации приложения, которое часто читает из памяти, и сильно снижает эффективность CUDA на классе задач с частым нелокальным доступом к памяти. Когда количество вычислений соизмеримо с количеством обращений к памяти. Но если операции доступа к памяти довольно редки, то большое количество одновременно выполняющихся на мультипроцессоре нитей прекрасно скроет латентность памяти.
Это лишний раз показывает бессмысленность сравнения теоретического максимума скорости GPU и CPU. И для приложений, интенсивно работающих с памятью, очень желательно разбить данные на блоки и поместить во внутреннюю память мультипроцессора.
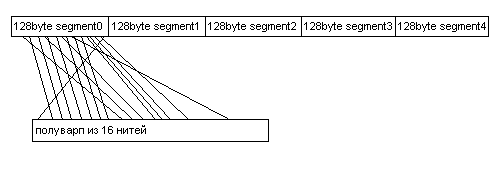
В случае доступа к 32-битным данным, память представляется разделенной на сегменты по 128 байт и если все нити полуварпа читают или пишут из одного сегмента, то осуществляется всего одна транзакция памяти.
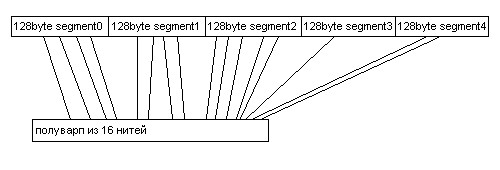
Когда нити варпа читают из различных сегментов, осуществляется несколько, в данном случае 5, дорогостоящих обращений к памяти.
Вторая проблема связана с разделяемой памятью, расположенной на мультипроцессоре. Она разделена на 16 банков, как таблица на 16 колонок. И нити осуществляют операции доступа к ней по 16 штук за раз. То есть, сначала первая половина из 32 нитей варпа, исполняющего инструкцию доступа к разделяемой памяти блока, а потом вторая.
И для максимальной производительности желательно, чтобы каждая нить читала данные из отдельной, собственной колонки. Не было такого, чтобы две нити запрашивали одну колонку. Такие запросы выполняются последовательно, что несколько снижает скорость доступа к локальной памяти мультипроцессора. Потому, что у каждой колонки свой порт и он не может в один момент обслужить две нити. Это не так страшно, как нелокальный доступ к глобальной памяти, но при активном использовании разделяемой памяти может привести к серьезным потерям производительности, это тоже лучше учитывать.
Чтобы это обойти, может понадобиться немного изменить распределение памяти, например, вставить пустые ячейки, чтобы реальные данные раскидались по различным колонкам. Допустим, что все нити читают одну колонку, а если вставить одну пустую ячейку, то колонка превратится в диагональную лесенку и каждая нить сможет читать из различной колонки через свой порт, с полной производительностью.
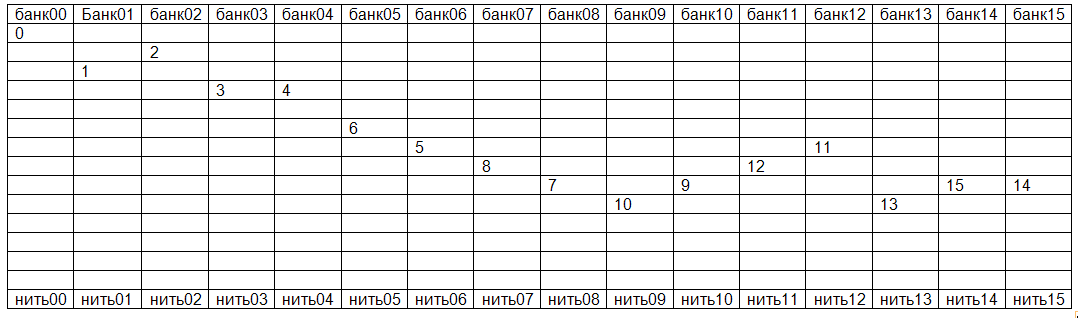
Разделяемая память мультипроцессора разделена на 16 банков, которые чередуются по адресам. Представлен случай оптимального доступа, каждая нить из полуварпа читает из своего банка. Номер в таблице показывает, из какой ячейки читает нить с соответствующим номером.
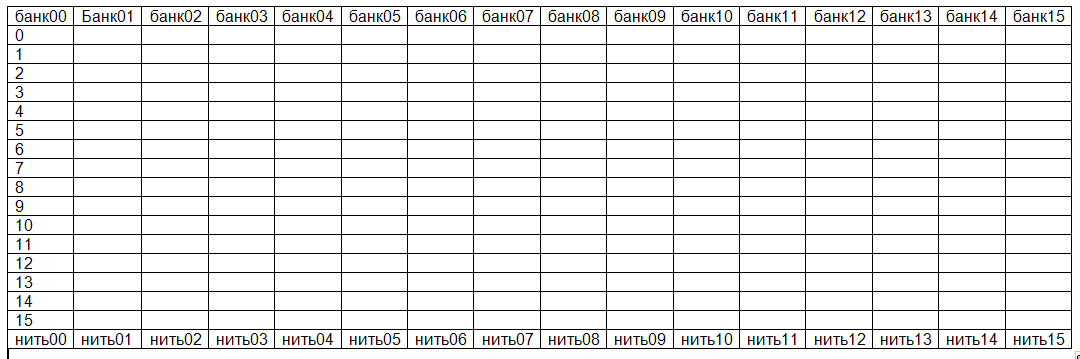
Неоптимальный случай, все нити полуварпа читают из разных ячеек одного банка и запросы выполняются последовательно, что в N раз медленней. Правда, случай, когда все нити полуварпа читают из одной ячейки разделяемой памяти, оптимизирован. Её значение передается сразу всем нитям и потери скорости не происходит.
Но все равно, если нелокальность глобальной памяти может снизить скорость в несколько раз, то конфликты банков в разделяемой памяти — лишь на несколько десятков процентов, в случае интенсивного использования. Потому, что это проблемы разного уровня, доступ к внешним устройствам всегда на порядки затратнее, чем любые внутричиповые коммуникации. Надо отметить, что различные варпы, даже полуварпы, составляющие один варп, уже полностью свободны и не связанны никакими ограничениями. Кстати, скорость передачи данных, собственно, от CPU до GPU космически медленная, по сравнению со скоростью вычислений. Проблема не только в пропускной способности, но и в латентности запуска процедуры копирования данных. И из GPU они идут по текущим интерфейсам на порядок медленней. Поэтому, CUDA-программу не имеет смысла вызывать, так сказать, по пустякам. Время её работы может оказаться мало, по сравнению с потерями на передачу данных и инициализацией системы и, никакого прироста не будет, даже если GPU все посчитает в 100 раз быстрее.
Есть ещё один темноватый угол — это ограниченность объема памяти на видеоплате в несколько гигабайт, когда в рабочую станцию на базе CPU можно поставить в несколько раз больше. Но, все же это не самый принципиальный момент, для параллельной программы почти всегда можно разделить больший объем на куски, по нескольку гигабайт.
Собственно, на этом почти все. Остальные углы менее тёмные. Эти аспекты очень хорошо продемонстрированы на примере программы транспонирования матриц из CUDA SDK, когда скорость возрастает в разы при каждой оптимизации. Небольшая модификация кода влечет значительное изменение производительности. Но пример слишком страшный и приведена очень простая задача, для CPU тоже можно такой привести, а в более сложном приложении, скорость сглаживается.
Если алгоритм не очень критичен к вышеупомянутым ограничениям памяти, или может быть изменён в соответствии с требованиями оптимального доступа, то можно ожидать великолепного прироста. Среди вышеупомянутого класса счетных задач есть множество таких, которые допускают реализацию CUDA оптимальным алгоритмом.
Вопрос об использовании CUDA возникает, когда требуется увеличить производительность. И это сразу поднимает тему оптимизации программы. Ведь это первый способ ускорения работы. Скорость выполнения оптимизированной и не оптимизированной программы на обычном, современном CPU, может отличаться в десятки раз. Использование многоядерности и SIMD может дать прирост в 16 раз, а оптимизация доступа к памяти ещё в несколько раз.
Оптимизация для CUDA состоит из двух взаимосвязанных этапов, надо выбрать подходящий и удобный для CUDA алгоритм решения требуемой задачи. Хорошо распараллеливающийся, естественно. Здесь надо отбросить все стереотипы мышления. Хороший алгоритм тот, который обеспечивает максимальную скорость с учетом данного железа. Вот образный пример: предположим, вы бизнес-леди и вам надо послать мужа за покупками. Вы пишете список, что купить, и муж отправляется обходить магазины, чтобы купить предметы по списку. А представьте, у вас целый гарем мужей и вы каждого отправляете в разные магазины с одним списком. Мужья не взаимодействуют между собой и принесут все товары, какие смогут купить. Разные мужья могут купить одинаковые вещи, ну и что, денег-то все равно навалом. Зато вы получите все, что вам нужно, гораздо быстрее, чем один, даже очень быстрый муж, оббегает множество магазинов.
Впрочем, в новой версии CUDA, которую мы рассмотрим чуть позже, по заявкам наиболее жадных западных бизнес-леди, мужьям ещё купили мобильные телефоны. Чтобы они могли больше переговариваться между собой и не покупать лишнего.
Алгоритм решения задачи надо выбирать, чтобы он по возможности обходил «темные углы» и вы точно получите значительный прирост. А при адаптации существующего алгоритма, надо в первую очередь обратить внимание на взаимодействие с памятью. Это ключевой момент, потому что вычислительная скорость несоизмерима с латентностью доступа к данным. Оптимизация уже имеющегося алгоритма, для CUDA, похожа на оптимизацию для классического CPU, только все гораздо более сильно выражено. Как эффекты от оптимизации, так и провалы производительности при её полном отсутствии.
При оптимизации для классического процессора, тоже очень полезно (и так часто делается) разбить данные на блоки, которые помещаются целиком в L1-кэш и там с ними работать. Для CUDA это часто обязательно, но и дает больший прирост. Современные процессоры так же страдают от нелокального доступа к памяти, прячутся за колоссальными кэшами и так далее. Для CPU очень полезно применить SIMD, это даст прирост в несколько раз. Это же верно и для CUDA, причем применить благодаря мягкой модели SIMT гораздо проще, а эффект гораздо выше. Оптимизация для CUDA поднимает размер банка в несколько раз, при сравнимой ставке.
По объективным причинам, производительность CPU растет медленно, т.к. на десктопе множество задач, которым не нужно много потоков и производители CPU делают двуядерные модели. Выпуск шести– и восьмиядерных моделей отнесен на конец следующего года, причем, это будут модели верхнего ценового уровня. В конце следующего года, компания Intel планирует представить новую архитектуру Sandy Bridge, мэйнстрим-вариант — четырехъядерный процессор с частотой около 3,5 GHz и интегрированным графическим ядром. С некоторыми небольшими архитектурными улучшениями, он может быть примерно в полтора раза быстрее топовой модели Lynnfield. А ещё, у Sandy Bridge будет восьмиэлементный SIMD набор AVX. Все SSE-программы придется переписывать для новых размеров векторов. Но увеличение размера вектора до 8, это какой-то неясный путь, непонятна его перспектива. Потом до 16? Потом до 32? Модель SIMT из CUDA гораздо удобнее в программировании, это просто программирование на языке высокого уровня, без всяких дополнительных громоздких векторных инструкций.
А если рассмотреть Larrabee, у которого вообще планировались шестнадцатиэлементные вектора? Ещё менее гибко и менее удобно. Такие длинные вектора мало где применимы, практически всегда требуется очень сложная оптимизация: както переставлять элементы, обрабатывать специальные случаи, когда нужно что-то сделать только с частью вектора. В этом смысле, даже сложная оптимизация под CUDA, более естественна для не узкоспециализированных программистов, для ученых, например. Она более алгоритмическая. Выбрать из множества алгоритмов с наибольшей локальностью обращений к памяти. Придумать, как разделить область задачи и как распараллелить её на тысячу потоков. Фишки AVX и архитектуры Larrabee ориентированы на ускорение сегодняшних алгоритмов, путем оптимизации с помощью низкоуровневых векторных инструкций. Но у модели Ларраби, выпуск которой перенесли надолго, согласно доступной информации, все равно была недостаточная производительность в 3D графике. Скорее всего, Intel многое переделает, поэтому о Larrabee говорить ещё рано.
Что мешает распространению CUDA? Благодаря предоставляемой архитектурой CUDA, высокой производительности, технология нашла большое количество применений в самых различных областях. На сайте компании NVIDIA можно найти примеры как экспериментальных, так и коммерческих приложений. Но области применения остаются локальными, они выглядят изолированными озерами на материке современного ПО. Это не море и не океан. Или лучше сравнить CUDA-приложения со скалами, которые поднимаются из безбрежного океана программ и возвышаются над ним. Чем больше производительность, тем выше пик. Они появляются и растут, то тут, то там, но пока ещё целые пласты не поднялись над спокойной гладью воды и не сформировали землю.
Надо сразу отмести приложения и расчеты, которые и так выполняются достаточно быстро на современных процессорах. С другой стороны, наиболее вычислительно требовательные из пользовательских задач — приложения компьютерной графики на PC — успешно решаются специальными ускорителями 3D-графики, которые по странному стечению обстоятельств имеют тот же адрес места жительства в компьютере, что и CUDA-устройство. Если бы не они, вся графика считалась бы сейчас на CUDA.
О проблеме совместимости можно и не говорить. Сейчас многие наоборот согласились бы на двукратную потерю производительности, чтоб только какую-то старую программу перенести без проблем с одной платформы на другую.
Но наиболее важная проблема для рынка персональных ПК, на взгляд автора, это отсутствие совместимой с CUDA технологии подобного уровня от компании AMD. Для коммерческих разработчиков важна поддержка всех систем. Не будут же они писать на коробках, что их ПО предназначено только для пользователей решений NVIDIA. Если бы CUDA была реализована, пусть даже с меньшей производительностью, в решениях AMD, то сейчас было бы гораздо больше инвестиций в CUDA-ПО.
Но, буквально в последние месяцы, AMD объявила о поддержке окончательного варианта OpenCL. По мнению автора, это другая обертка CUDA-архитектуры, по сути, абсолютно то же самое, как если бы мы конфету завернули в другой фантик. Автор нашел у OpenCL и CUDA меньше отличий, чем у OpenGL и Direct3D, например. А многие игры поддерживают и OpenGL, и Direct3D и картинка практически не отличается. Даже больше, между текущей реализацией CUDA и OpenCL меньше различий, чем между некоторыми версиями DirectX. Основные отличия в синтаксисе. В OpenСL текстура называется Image, например. Так что, эта проблема совместимости решена, пусть даже если ОpenCL-драйвера будут вначале хуже по исполнению видеодрайверов ATI.
Еще одна сфера применения — это профессиональные решения для предприятий и организаций, когда поставляется техника и специальное ПО под конкретную задачу. Это решения для конкретных заказчиков, они не имеют массового тиража. Но на западном рынке соотношение зарплат, тем более, квалифицированных программистов и цен аппаратного обеспечения, другое. Там чаще экономически выгоднее, при малых объемах поставок, просто купить процессоры той же производительности, но за более высокую цену, чем привлекать дополнительных разработчиков, тестеров и т.п. В этом смысле, нашими предприятиями технология может быть быстрее востребована.
Другая проблема — это ещё не полная «обкатанность» технологии, она просто ещё молода. Например, проблема, что некоторые операционные системы Windows пытаются действовать как OS реального времени и норовят прервать исполнение CUDA-программы, если оно продолжается больше 5 секунд. Таким образом, OS Microsoft не может «достучаться» до GPU и пытается что-то сделать. Очень бредово звучит. И разработчикам приходиться обходить эту проблему с использованием специфического системного программирования для каждой операционной системы Microsoft.
В последних версиях CUDA, SDK и компилятора, многие пожелания пользователей были учтены. В первую очередь, с точки зрения не аппаратной архитектуры, а программного интерфейса, поддержки различных операционных систем и сред программирования. У автора не было с последней версией SDK никаких проблем.
И последнее — вожделенный для NVIDIA рынок высокопроизводительных вычислений HPC. И тут, главным препятствием является недостаточная производительность вычислений с вещественными числами, типа double с двойной точностью. Все рекорды скорости GPU поставлены при работе с числами одинарной точности или целыми 32-битными или 16-битными. Для вычислений double, в нынешних GPU доступно только одно исполнительное устройство, таким образом, максимальная теоретическая скорость в 8 раз меньше и сравнима со скоростью любого современного четырехъядерного процессора. Такая игра не стоит свеч.
Конечно, многим физическим задачам не требуется двойная точность расчётов. Многие пользователи в области химии, электродинамики, биологии успешно применили CUDA и получили дешевую производительность для своих задач. В конце концов, производители CPU выкинули поддержку более точного 80–битного типа long double, потому что его размер не очень им удобен. Но, double — это стандарт в индустрии, все к нему привыкли. В конце концов, редко система собирается ради одного алгоритма. А если он изменится, если потребуется считать что-то иное. Такая узкая специализация устройства препятствует широкому применению. И дополнительная скорость CUDA-устройства может быть не настолько востребована, чтобы проверять и исследовать, выдержит ли используемый алгоритм переход на вычисления с числами одинарной точности, не накопится ли где-нибудь погрешность. Или разрабатывать новый, специально для работы с float.
Но отсутствие полной поддержки double не есть базовая черта архитектуры CUDA. Так сложилось, не будем говорить почему (подсказка, в графике тип double не очень востребован), что CUDA-устройства имеют исполнительные устройства, работающие с float. Если бы вместо 8 float-операций выполнялось 8 операций с вещественными числами двойной точности, уже сейчас применений CUDA в HPC было бы на порядок больше. И в новой версии CUDA-архитектуры, «Fermi», уже целенаправленно предназначенной для HPC и других «неграфических» применений, double поддерживается наравне со float, как и в обычных CPU. И является таким же базовым типом переменных.
В новой архитектуре так много качественных улучшений, решающих большинство из вышеперечисленных проблемы CUDA, что она претендует на статус революционной.
Хорошо, что на свете не бывает чудес, иначе жизнь была бы слишком пресной и скучной. Если бы чип, на основе представленной в начале октября архитектуре, появился прямо сейчас, по типичным ценам и объемам, это было бы чудо, настолько она продвинута на данный момент. Но проблемы с переходом на новый техпроцесс, которые случаются, время от времени, со всеми производителями чипов, задерживают выпуск продукта.
Это не так принципиально для разработки, так как существующим CUDA-программам не потребуется переделки, чтобы воспользоваться преимуществами новой архитектуры. Для полного ускорения может потребоваться некоторая переконфигурация, изменение количества нитей в блоке и размера разделяемой памяти блока. Но практически все CUDA-программы могут свободно варьировать эти параметры. Потому, что несколько все равно: что 128, что 256, что 512 нитей. И у разработчиков появится время, чтобы подготовить продукты к анонсу, с расчетом на его уже новые возможности. Зачем нужен чип, если для него нет программ?
У нового чипа нет пока имени и я придумал назвать его «Reflection» («Отражение»), потому что в новой архитектуре отражено огромное количество пожеланий авторов CUDA-программ. И он «отражает» критику слабых мест прежней архитектуры. И те, кто знаком с компьютерной графикой знает, что эффекты рендерятся долго и его применение как раз ускорит отрисовку таких сложных визуальных эффектов.
Самое главное для HPC–устремлений NVIDIA, новый чип полноценно поддерживает double. Каким образом это достигнуто? В новой архитектуре мультипроцессоры стали более «жирными». Вместо 8 исполнительных устройств, их стало 32. И, по-видимому, два соседних устройства вычисляют, вместо пары float-операций, одну double. Производительность в double просто в два раза меньше, чем во float. Либо 32 операции с числами с одинарной точностью, либо 16 с двойной. Это в точности как в SSE обычных CPU, производительность в double в два раза ниже. Количество мультипроцессоров уменьшилось до 16, но общее количество операций возросло более чем вдвое, а с double–числами почти на порядок.

Так представляет новый чип NVIDIA. 16 мультипроцессоров с 32 исполнительными устройствами, обозначенными зелеными прямоугольниками. 4 вертикальных прямоугольника салатового цвета обозначают модули вычисления специальных функций, тригонометрических и корней. Небольшие зеленые квадратики, видимо, обозначают 16 устройств калькуляции адресов.
Оранжевые прямоугольники обозначают «дуальный» планировщик и модуль dispatch. Синие области обозначают L1-кэш с разделяемой памятью, блок регистров, который по некоторым сведеньям удвоился и специальный кэш инструкций, подробности о функционировании которого не разглашаются.
Если бы NVIDIA ограничилась только этим, то это был бы уже большой шаг вперед. Но улучшения приняли тотальный характер.
Точность float-вычислений тоже была повышена, в соответствии со спецификациями самого последнего стандарта. Включена поддержка денормализированных чисел с полной скоростью, что CPU делать не умеют. Денормализированные числа — это маленькие числа, на границе точности формата float.
В результате, CUDA-устройство может считать точнее, чем CPU. Вполне очевидно, благодаря чему это стало возможно. Мультипроцессор работает на меньшей частоте, чем CPU, нет такой требовательности к дизайну модулей умножения, чтобы они работали на невероятной скорости и их можно совершенствовать «вширь». Этого изначально стоило ожидать от CUDA-архитектуры. Была бы потребность, можно было бы относительно легко и 128–битные вещественные числа сделать.
Критики архитектуры CUDA справедливо указывали, что для применения в системах HPC требуется поддержка алгоритмов коррекции ошибок ECC, которые иногда возникают в электронных устройствах. Когда тысячи устройств работают круглые сутки, ошибки неизбежно появляются, время от времени. На это энтузиасты технологии отвечали, что преимущество в скорости CUDA так велико, что можно для проверки результата считать его два раза, особенно конечный. Но, как будто бы ECC каким-то образом противоречит самой идее CUDA-архитектуры? Конечно же нет, на низкочастотном устройстве её воплотить даже легче. И новый чип имеет полную поддержку технологий коррекции.
На этом примере можно отметить, что многие претензии к CUDA носят поверхностный, непринципиальный характер. Их устранение можно с уверенностью ожидать в будущих релизах. Просто всё сразу невозможно сделать.
Как уже говорилось выше, в мультипроцессоре теперь 32 исполнительных устройства, которые в терминологии CUDA называются Scalar Processor Core, или CUDA Core. В процессорной терминологии, этому больше соответствует functional unit с небольшой оберткой. То есть, мультипроцессор может выполнить целый варп за такт. Но это неудобно, потому что остальная часть мультипроцессора работает на половинной частоте, по сравнению с частотой «скалярных процессорных ядер». Чтобы разрешить ситуацию, планировщик варпов был сделан двойным, он сразу отправляет на исполнение два варпа, каждый на 16 исполнительных устройств. Таким образом, варп из 32 одинаковых инструкций выполняется за два такта функциональных устройств и один такт остального ядра. Но два варпа, выполняющие инструкцию c данными типа double, не могут быть исполнены вместе, так как инструкции double выполняются два такта или двумя функциональными устройствами. То есть, так полный варп из 32 double-инструкций выполнится за один «длинный» такт.
Не предполагается, что такая конструкция как-то поможет ускорить дивергентные ветвления внутри одного варпа. Просто варп с такими ветвлениями будет исполняться дольше, пропорционально количеству ветвлений, в то время как другие варпы будут идти параллельно.
С применением нового техпроцесса, стало возможным увеличить размер локальной памяти мультипроцессора и сделать небольшой L1-кэш, а так же разместить на кристалле общий для всех мультипроцессоров L2-кэш размером 768 Кб.
Является ли это отходом от подхода, реализованного в предыдущих графических процессорах, которые обходятся почти без кэшей? Может, лучше было и этот кэш пустить на мультипроцессоры? Нет, он занимает мало места, а пользы может принести много.
Он служит, в первую очередь, для буферизации. Просто, даже если нить запрашивает из глобальной памяти 4 байта, транзакция все равно осуществляется минимум с 64 байтами. И весьма вероятно, что загруженные данные могут понадобиться вскоре этой или другим нитям. Эти загруженные блоки данных можно пока сохранить. С такой логикой, раз уж мы скопировали из памяти избыточные данные, пока оставим, вдруг пригодятся.
Теперь, размер локальной памяти мультипроцессора составляет 64 Кб и её можно сконфигурировать программно, оставить 16 Кб разделяемой и 48 Кб нового L1-кэша. Это полезно для старых CUDA-программ, которые не знают о том, что объем разделяемой памяти, доступной блоку нитей, увеличился. Зато они могут выиграть от большего размера кэша. Или сконфигурировать локальную память, в пропорции 48 Кб разделяемой, 16 Кб кэша. То есть, дать возможность программе самой решить, что загружать в память мультипроцессора. Но это тоже будет способствовать росту производительности старых CUDA-программ, так как большее количество блоков и нитей сможет одновременно выполняться на мультипроцессоре. Допустим, если раньше один блок из 256 нитей требовал 16 Кб разделяемой памяти и на мультипроцессоре мог выполняться только один блок, то сейчас — 3, так как им всем хватит памяти.
Также, L1-кэш очень поможет для быстрого свопа, то есть, временного хранения регистров. Сейчас, при программировании CUDA-приложения, желательно использовать как можно меньше регистров мультипроцессора, чтобы на одном мультипроцессоре можно было запустить больше нитей. И, крайне нежелательно, временно сбрасывать содержимое регистров в медленную глобальную память. На это иногда жалуются CUDA-программисты, что им не хватает регистров. А если хватает, то запускается меньше нитей, которые меньше скрывают различные задержки. Приходится думать, как программу реализовать с меньшим количеством временных регистров. Интересная оптимизационная задача конечно. Немного необычно: найти такой нетребовательный алгоритм, иногда бывает похоже на задачу из олимпиады по информатике.
Первая функция общего кэша второго уровня — это радикально ускорить и упростить синхронизацию всех исполняющихся нитей. Нити, выполняющейся на одном мультипроцессоре, не могут видеть содержимое L1–кэшей других мультипроцессоров, но когда данные сбрасываются в L2–кэш, например, принудительными синхронизирующими инструкциями, они сразу становятся видимыми для всех. Раньше, для синхронизации между блоками использовалась сверхмедленная, глобальная память. Это сильно упрощает написание сложных CUDA-программ.
И, конечно, L2 выступает неким общим пулом загружаемых из глобальной памяти данных. GT200 имеет 256 Кб кэша второго уровня для текстурной памяти на все мультипроцессоры, сейчас размер кэша утроился до 768 Кб. И он стал полноценным, а не только для чтения данных.
Удобно, конечно, для контроллеров памяти, оперирующих широкими кусками данных, наполнять строчки L1-; L2-кэшей. Именно в ширине интерфейса глобальной памяти кроется необходимость иметь достаточно большой промежуточный пул и несколько отойти от концепции тратить всю площадь кристалла на исполнительные устройства. Представьте, вы заказываете из магазина товар, но в вашем распоряжении самосвал, он привозит не только товар, но и все, что рядом лежит. Раньше оно выбрасывалось, а теперь сохраняется в кэше. И конечно, некоторые задачи с объемом данных, сравнимым с размером кэша, получат очень сильный прирост. Но никакой кэш, тем более, меньше мегабайта размером, не решит проблему доступности данных в случае, близкого к случайному, доступа десятков тысяч одновременно исполняющихся на мультипроцессоре нитей. Для этой цели служит большое количество активных нитей на мультипроцессоре. Кстати, максимальное количество одновременно исполняющихся нитей на мультипроцессоре также возросло.
Новая версия архитектуры CUDA включает полную поддержку C++, виртуальных функций, указателей на функции и конструкций try–catch. Это расширяет область применения решений на основе архитектуры Fermi и сильно облегчает портирование многих существующих приложений на GPU. Но главное, что многие программисты просто любят программировать на С++, даже если он не очень нужен для решения конкретной задачи. Очень характерно, что часто, обсуждение архитектуры «Ферми» моментально выливается в спор С vs С++. Чтож, скоро сторонники и противники разных подходов к программированию получат ещё одно поле битвы. На чем лучше программировать Fermi? С или С++?
Но на языках Си свет клином не сошёлся и, благодаря поддержке указателей на функции, стала возможной поддержка большого количества самых разнообразных языков программирования. Причем, не ориентированных на высокую скорость исполнения написанных на них программ.
Изначально, CUDA предназначалась для высокопроизводительных, во многом оптимизированных приложений, но многие программы выгоднее писать без оглядки на железо, а потом смотреть, как процессоры «страдают», выполняя тяжёлый код и выбирать лучшее для своей задачи. Параллельное программирование проникает в массы и, с полной поддержкой указателей, появилась возможность просто запускать на GPU широкий класс параллельных программ. Fermi и в этом случае может оказаться конкурентоспособным, т.к. такие программы и на классическом CPU будут отчаянно медленно исполняться. И на каждое обращение к памяти у них будет море инструкций обращения к собственным регистрам и так далее.
Да, для универсализации потребовалось объединить в одном адресном пространстве всю, доступную отдельной нити, память. Собственную память мультипроцессора и видимую глобальную память. Это также важно для заявленной поддержки операторов new и delete, то есть, выделения памяти прямо из CUDA-программы, исполняющейся на CUDA-устройстве. О чем раньше и подумать было нельзя. Очень интересно будет посмотреть, как в реальности будет работать собственный менеджер памяти.
Компания NVIDIA заявляет об увеличении скорости переключения задач, поскольку на GPU может выполняться несколько CUDA-приложений. Но более важно то, что теперь одновременно может выполняться несколько CUDA-функций одного приложения. Потому, что одна может не загрузить все устройство. И это делает возможным плотнее загрузить поддерживающий CUDA GPU при запуске нескольких задач подряд. Так как программа, приближаясь к своему завершению, может работать лишь на нескольких мультипроцессорах, в то время как остальные уже освободились.
Исполнение нескольких функций может помочь скрыть длительное время передачи данных по шине PCI-Express. Чтобы GPU не останавливался в ожидании передачи данных. Может быть, даже одну задачу выгодно будет делить на несколько меньших, чтобы первые блоки уже начинали считать, пока подгружаются остальные данные.
Последний пункт особенно четко демонстрирует «суперкомпьютерный» характер новой архитектуры. Можно смело сказать, что мы получаем настоящий суперкомпьютер на столе. Страшно подумать, что их ещё можно установить несколько в одной системе и объединить вместе несколько таких компьютеров. Получается целый вычислительный фрактал. Перечислим его: нить — полуварп (16) — варп (2*16) — блок нитей (2*16*8) — мультипроцессор (2*16*8*4) — GPU (2*16*8*4*30) — multiGPU (2*16*8*4*30*4) — узел из 8 компьютеров (2*16*8*4*30*4*8)= ~ пол миллиона нитей и десять тысяч операций за одну миллиардную секунды. И дешевле обычного сервера. Может, правда, запретить «Ферми» к продаже, а то какие-нибудь террористы рассчитают что–то вроде ядерного оружия?
«Революционность» новой архитектуры заключается в том, что улучшения произошли как количественные, так и качественные. Теоретических гигафлопов стало намного больше, особенно в вычислениях с двойной точностью. Одновременно с этим, их стало гораздо легче получить, как с точки зрения улучшения аппаратного обеспечения, так и со стороны поддержки средств разработки.