Разработка протокола поддержки когерентности кеша для систем с активной памятью.
Автор: Mainak Chaudhuri, Daehyun Kim, and Mark Heinrich
Источник: Cache Coherence Protocol Design for Active Memory Systems
Перевод: Вавринюк И.О.
Статья была ранее переведена магистром Лебединским А.А., но статья имела некорректный перевод, поэтому была переведена вновь.
Источник на ранее переведенную статью: Cache Coherence Protocol Design for Active Memory Systems
Аннотация
Системы с активной памятью улучшают поведение кэша приложения или проводя параллельную обработку данных в элементах памяти, или поддерживая переназначение адресов с помощью специального контроллера. Первый подход позволяет более чем одному элементу памяти обрабатывать одни и те же данные, а второй позволяет процессору получать доступ к одним и тем же данным с помощью более чем одного адреса. Поэтому когерентность данных имеет большое значение для правильности и прозрачности вычислений в системах с активной памятью. В этой работе показано, что можно расширить обычный DSM-протокол и справиться с этой проблемой, эффективно и прозрачно, как в однопроцессорной, так и в многопроцессорной системе. С помощью контроллера со специализированной программируемой памятью можно выполнять несколько операций с активной памятью с минимальными изменениями кода протокола когерентности и без аппаратных изменений. Эта статья покажет детали расширений протокола DSM , которые позволяют ускориться в несколько, от 1,3 до 7,6 раз, по сравнению с обычными системами памяти по целому ряду симулируемых однопроцессорных и многопроцессорных приложений.
Ключевые слова: Активные системы памяти, переназначение адресов, когерентности кэшей, распределенная разделяемая память, гибкий контроллер памяти.
1. Введение
Активные системы памяти обеспечивают перспективный подход к преодолению предела памяти для приложений с нерегулярным характером доступа, которые не поддаются улучшению с помощью таких методик, как предварительная выборка или улучшения в иерархии кэш-памяти. Главная идея этого подхода заключается в проведении параллельных по данным вычислений [2, 4, 7] или операций разброса/сборки, вызываемых с помощью методов переназначения адресов [1] в системе памяти, чтобы либо непосредственно перераспределить вычисления, либо сократить число промахов кэша процессора. Оба подхода создают проблемы с когерентностью даже на однопроцессорной системе, так как есть или дополнительные процессоры в системе памяти, воздействующей на данные непосредственно, или основному процессору позволено обращается к тем же данным с помощью нескольких адресов.
Эта работа фокусируется на проблемах разработки протоколов когерентности кэша для активных систем памяти. Потребность соблюдения когерентность данных между нормальной строкой кэша и строкой кэша доступной по переназначенным адресам, делает поведение протокола и требования к производительности сильно отличающимися от тех, которые предъявляются к стандартному протоколу DSM. Мы предлагаем активную систему памяти, которая поддерживает переназначение адресов, усиливая и расширяя аппаратный протокол DSM, основанный на каталогах. Ключом к нашему подходу является то, что активный контроллер памяти не только выполняет операции переназначения адресов, но также и выполняет основанный директориях протокол когерентности и, следовательно, управляет тем, какие отображения существуют в кэше процессора.
Работа организована следующим образом. Раздел 2 описывает расширения протокола и особенности реализации протокола уникальные для активных систем памяти. Раздел 3 обсуждает проблемы производительности, связанные с протоколами активной памяти. Раздели 4 показывает как однопроцессорное ускорение, так и улучшение производительности приложений активной памяти на многопроцессорных системах с одним узлом. Раздел 5 завершает работу.
2. Расширения протокола DSM для активных систем памяти
Наш встроенный контроллер памяти выполняет последовательности программных команд для реализации протоколов когерентности с использованием той же философии, что и многопроцессорная система FLASH [6]. Тем не менее, контроллер также включает в себя специализированное оборудование, чтобы ускорить выполнение протоколов активной памяти. Наши базовые (не расширенные) протоколы это общепринятые, основанные на признании линий кэша недействительными, использующие битовые вектора, опирающиеся на структуру директорий, протоколы MSI, выполняющиеся согласно модели консистентности по выходу. Для всех нормальных (не переназначенных) запросов к памяти, наш контроллер памяти следует этим протоколам. Каждая запись каталога (для 128-байтной строки кэша) имеет размер 8 бит. Вектор распределения занимает 4 бита, таким образом, мы можем поддерживать до 4 процессоров. Оно может быть увеличено за счет размера этого поля. Эти четыре бита хранят вектор со списком совместного использования, если строка находится в состоянии совместного использования, или идентификаторе владельца для «грязного» эксклюзивного состояния. Два бита выделены, чтобы указывать информацию о состояние строки кэша. «Грязный» бит указывает, находится ли строка кэша в «грязном» эксклюзивном состоянии. Бит AM используется для нашего расширения протокола активной памяти и не используются основным протоколом. Два остающихся бита не используются.
2.1 Расширение активной памяти
Как пример того, что методы переназначения адреса порождают проблему когерентности, рисунок 1 показывает, что элемент данных D0 в строке кэша C0 отображен некоторым методом переназначения адреса на элементы данных D1, D2 и D3, принадлежащие трем различным строкам кэша C1, C2 и C3, соответственно. Это означает это D1, D2 и D3 представляют те же данные, что и D0 и наши расширения протокола памяти должны сохранить их когерентными. На рисунке, если С1 и С2 кэшируются в грязном состоянии и состоянии совместного использования соответственно, процессор может записать новое значение в D1, но читать устаревшие значения из D2. Мы расширяем протокол, чтобы осуществить взаимное исключение между состояниями строк, которые отображены друг на друге, так, чтобы только одна строка из четырех отображенных строк кэша (как в примере выше) могла кэшироваться одновременно. Если процессор получит доступ к другой отображенной строке кэша, то за этим последует промах кэша и наш протокол признает недействительной старую строку кэша, прежде чем ответит с помощью требуемой строкой кэша.
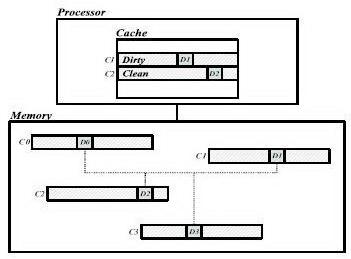
Рисунок 1. Проблема согласованности данных
Для каждого запроса к памяти, наш протокол сверяется с битом AM в поле директории требуемой строки кэша. Бит AM из строки кэша указывает, были ли какие-либо данные в строке повторно отображены и кэшируется процессорами в системе по различным адресам. Если бит AM в нуле, нет никакой возможности нарушения когерентности и протокол ведет себя точно так же, как основной протокол с одной дополнительной задачей - гарантировать когерентность в будущем. Протокол устанавливает биты AM в записях директорий всех строк кэша, которые отображены на требуемую строку. Однако если бит AM установлен, некоторые повторно отображенные строки кэша (мы называем эти строки R), кэшируются в системе и есть потенциальная проблема когерентности данных. Состояния R получают, читая соответствующие записи директорий. Если R находится в грязном эксклюзивном состоянии, протокол отправляет запрос владельцу R, чтобы получить наиболее новую копию данных, обновляет отображенное значение данных в требуемой строке кэша, отправляет данные запрашивающей стороне и записывает полученный кэш обратно в главную память. Если R находится в состоянии совместного использования, протокол отправляет запросы признания строк кэша недействительными всем, между кем кэш распределен, читает требуемую строку кэша из памяти (так как там строка чистая) и отправляет данные запрашивающему. В обоих случаях протокол обновляет AM биты в записях директорий всех строк кэша отображенных из требуемой строки.
2.2 Поддержка Active Memory Transpose
Хотя мы реализовали четыре операции с активной памятью - транспонирование матрицы, разброс/сбор разреженных матриц, линеаризацию связного списка и слияние на стороне памяти [5], для экономии места мы представим лишь транспонирование матрицы в качестве примера. Предположим следующее: А - квадратная матрица размерности N, А` является транспонированной матрицей, отображенной из А, есть два процессора с доступом к ним - P0 и P1. Размер строки кэша составляет 128 байтов и размер элемента данных 8 байтов (одно двойное слово), таким образом, одна строка кэша содержит 16 элементов. В определенный момент, снимок памяти таков, как на рисунке 2 и P0 выполняет следующий код:
for i=0 to N-1
for j=0 to N-1
x += A'[i][j];

Рисунок 2. Пример – транспонирование матрицы
P0 читает строку кэша C` матрицы A`, эти данные отсутствуют в кэше. C` составлен из 16 двойных слов w0` w1`… w15`, которые совпадают с w0, w1… w15 и эти 16 строк кэша C0, C1… C15 из A содержат их. P0 и P1 кэшируют C1, C2 и C14 в грязном или совместно используемом состоянии как показано на рисунке. P0 отправляет запрос чтения в основную память и контроллер памяти вызывают надлежащую когерентную обработку.
Обработчик протокола читает запись директории в C` и проверяет Бит AM. В этом случае бит AM установлен потому, что C1, C2 и C14 отображены на C`, и они кэшируются. Таким образом, вместо использования базового протокола, вызван наш расширенный протокол. Из физического адреса C0 , аппаратура переназначения (подробная микроархитектура контроллера может быть найдена в [5]), вычисляет адреса строк кэша отображенных на C`, которые в этом случае являются C0 C1… C15. Так как C` принадлежит переназначенному адресному пространству и переназначенное физическое адресное пространство непрерывно, от физического адреса C` протокол может узнать позицию C` в транспонированной матрице (т.е. A`), если знает размерности матрицы и размер каждого элемента матрица в байтах. Эта информация вместе с виртуальным адресом матрицы (т.е. A) сохранена в таблице, которая инициализирована в начале работы приложения через системный вызов библиотеки. Протокол вычисляет виртуальные адреса C0, C1… C15 и ищет в буфере TLB в памяти контроллера данные, чтобы вычислить соответствующие 16 физических адресов. Затем, протокол читает записи директорий для каждой из этих строк кэша и проверяет грязный бит и вектор совместного использования. Для C1 мы находим, что он кэшируется P0 в грязном эксклюзивном состоянии. Протокол отправляет запрос в P0 потому что в w1` хранится устаревшее значение, а новое значение - w1, находится в кэше P0. Получив ответ от P0, протокол обновляет w1` и также записывает C1 обратно в память. Для C2 мы узнаем, что это кэшируемый P0 и P1 в состоянии совместного использования, таким образом, протокол отправляет команды признания недействительным P0 и P1 для этой строки. В этом случае протокол может считать корректное значение w2` непосредственно из главной памяти. Случай для C14 подобен C1 за исключением того, что P1, вместо P0, кэширует эту строку. Для других строк кэша, которые чисты, протокол ничего не должен делать. Теперь, когда протокол вытеснил все кэшируемые строки, переадресованные на C` из кэша P0 и P1 и обновил данные C` новыми значениями, можно ответить P0 с помощью C`. Наконец, протокол обновляет биты AM всех записей директорий строк кэша переадресованных на C`. Поскольку C` теперь кэшируется, биты AM C0… C15 и C` чистые. Это гарантирует правильность для будущего доступа к любой из этих строк кэша.
Мы описали, как наш протокол транспонирования, осуществляет взаимное исключение между кэшем нормальных и переадресованных строк. Однако, это чрезмерно строго, так как вполне законно кэшировать и нормальные и переадресованные строки, если она находятся в состоянии совместного использования. Но мы обнаружили, что для транспонирования, осуществлением взаимных исключений достигается более высокая производительность, потому что все приложения для транспонирования, которые мы исследовали, имею следующую последовательность действия для случая совместного использования: процессор сначала читает нормальные строки кэша из набора данных, присвоенных ему, в конечном счете, пишет в него и затем продвигается к считыванию и, в конечном счете, обновлению переадресованных строк кэша. Поэтому, доступы имеют тенденцию "мигрировать" от одного пространства к другому. Когда активный контроллер памяти видит запрос чтения на нормальный или переадресованный кэш, он знает, что, в конечном счете, будет запрос обновления той же строку кэша. Далее, не будет никакого доступа от другого пространства кэша между чтением и обновлением. Таким образом, наши расширения протокола когерентности кэша принимают решение о недействительности всех строк кэша в другом пространстве, отображенном на требуемую строку во время чтения. Это делает обработчик обновления более простым, потому что это он не должен беспокоиться о недействительности совместно используемой строки кэша. Однако мы нашли, что алгоритм разброса/сбора матриц, не демонстрирует миграционный процесс совместного использования, и поэтому мы ослабляем ограничение взаимного исключения в этом случае. Это иллюстрирует преимущество гибких контроллеров памяти с адаптацией протокола когерентности к потребностям приложения.
2.3 Расширения протокола для систем с множеством узлов
В этом разделе обсуждаются вопросы расширения нашего протокола памяти для одного узла, связанные с несколькими узлами. Наш основной протокол для многих узлов - это MSI. Чтобы уменьшить заполнение в домашнем узле, подтверждения признания строк кэша недействительными собраны на запрашивающей стороне. Чтобы сократить количество отрицательных подтверждений в системе, домашний узел передает данные отложенной записи запрашивающей стороне, чьи запросы были отправлены слишком поздно, и грязный третий узел буферизует ранние запросы, которые прибывают перед ответами в виде данных.
Наши первичные результаты при работе с множеством узлов предполагают особое внимание при присвоении страниц домашним узлам. Все строки кэша, отображенные друг на друге, должны быть собраны на одном узле; в противном случае запрос строки локальной памяти может потребовать сетевых транзакций, чтобы запросить состояние директорий другой удаленной строки. Это усложнило бы обработчики протокола, а также ухудшило производительность. Дальнейшие сложности могут возникнуть во время сбора подтверждений признания строк недействительными в системах со многими узлами. Протокол активной памяти должен признать недействительными строки кэша, которые отображены на требуемой строке и кэшируются одним или более процессорами. Но у запрошенных строк и строк, которые станут недействительными - различные адреса. Поэтому подтверждение признания строки недействительной и соответствующее сообщение запроса, должны нести в себе различные адреса или во время сбора подтверждений признания строк недействительными придется использовать процедуру отображения, чтобы запросы и подтверждения совпали. Наконец, мы также должны уделить специальное внимание удаленному доступу. В то время как стандартным протоколам, вероятно, придется отправить не больше одного запроса на вмешательство на запрос к памяти, активный протокол памяти может отправить множество запросы на вмешательство, адреса которых отличаются, но отображаются на запрашиваемой строке. Поэтому, обработчик ответов на запросы на вмешательство должен собрать все ответы на запросы на вмешательство прежде, чем ответить требуемой строкой.
3. Оценка протокола
В этом разделе рассматриваются издержки протокола памяти и связанные с протоколом проблемы производительности. Дополнительные издержки памяти в протоколе активной памяти происходят из-за увеличения размера кода обработчика протокола, увеличение объёма директорий для переадресованных строк кэша, а также места требуемое для хранения информации о переадресациях в таблице, доступной встроенным протоколам процессора. Например, начальный размер кода протокола составляет 20 КБ, но расширение протокола для поддержки транспонирования матриц в памяти из раздела 2, увеличивает размер кода протокола до 33 КБ. Остальные операции увеличивают размер до 24-26 КБ. Издержки пространства для директорий зависят от размеров переадресованного адресного пространства. Наконец, таблица переадресаций занимает только 128 байт. Эти дополнительные издержки независимы от числа узлов в системе, кроме того, что маленькая таблица переадресаций должна быть продублирована в каждом узле системы.
Есть много проблем производительности для протоколов активной памяти, которые не касаются стандартных протоколов DSM. Мы кратко обсудим некоторые из них. Одно главное потенциально узкое место в производительности - заполнение контроллера памяти. Чтобы обслужить запрос на определенную строку кэша, протоколу, вероятно, придется запрашивать записи директорий всех переадресованных строк кэша (в прошлом примере - 16), и, вероятно, придется предпринять ряд действий, в зависимости от состояний директорий. Выполнение всех этих просмотров директорий с помощью программного обеспечения, работающего на нашем контроллере, было слишком медленным. Вместо этого у нашего контроллера есть специализированный конвейерный аппаратный модуль вычислений адресов, который вычисляет 16 переназначенных адресов строк кэша, загружает записи директорий в специальные аппаратные регистры и инициирует любой необходимый доступ к памяти. Наши программные обработчики протокола строго контролируют этот блок данных памяти, удерживая баланс между надежностью и производительностью. Как пример среднего заполнения контроллера, в системе с одним узлом для 1, 2 и 4 процессоров для нормального выполнения задач, заполнение контроллера составило 7.7%, 21.3% и 43.2% от полного времени выполнения соответственно, в то время как для активной памяти это - 15.5%, 29.4% и 47.8%, хотя нужно помнить, что время выполнения в протоколе активной памяти меньше, поэтому проценты заполнения естественно выше.
Другая важная проблема производительности - поведение кэша данных директорий, к которому получает доступ только встроенное программируемое ядро процессора на контроллере памяти. Так как доступ к одной записи директории может требовать доступ ко многим отображениям (16 в вышеупомянутом примере), которые могут не соответствовать записям директорий для непрерывных строк кэша, кэш директорий может быть сильно разбросан и, следовательно, будет иметь место большое количество промахов. Использование записи директории размером в один байт смягчают эту проблему в системах с одним процессором или активных многопроцессорных системах с одним узлом. Однако производительность кэша директорий может стать проблемой для чрезвычайно больших заданий на маленьких вычислителях, так как ширина записи директории увеличивается для систем со многими узлами.
Наконец, активному протоколу памяти, вероятно, придется отправить много запросов на вмешательство (максимум 16 в вышеупомянутом примере) и каждый локальный запрос потребует буфер данных, который заполняется через шину процессора, когда процессор отправит ответ на запрос на вмешательство. Это вызывает потребность в большом количестве буферов данных в контроллере. Мы решили сохранить четыре буфера зарезервированными с этой целью и использовать их, если обработчик должен отправить больше чем четыре запроса на вмешательство.

4 Результаты моделирования
Мы представляем результаты для систем с одним и многими процессорами на рисунках 3 и 4, соответственно. FFT и FFTW используют операции транспонирования матрицы, вычисления сопряженных градиентов, разброс/сбор разреженных матриц, а задача минимального охвата дерева использует линеаризацию списка. Отслеживание на уровне микроопераций параллельной редукции матриц показывает улучшение результатов для слияния на стороне памяти. Наш симулятор подробно моделирует соревнование за ресурсы в контроллере активной памяти между самим контроллером и его внешними интерфейсами, а главное памяти и системной шине. Более подробная информация о моделировании окружающей среда и моделируемых приложениях может быть найдена в [5]. В рисунке 3 столбцам «AM+Prefetch» соответствует ускорение, достигнутое нашими методами наряду с эксплуатацией новых возможностей созданных нашей оптимизацией AM (например, при транспонировании матриц теперь возможна предварительная выборка переадресованных рядов, которые были колонками в оригинальной матрице). Таблицы 1 и 2 показывают сравнение промахов кэша L2 для нормального AM-выполнения без предварительной выборки, в то время как Таблица 3 сравнивает данные промахов кэша TLB, замеченных ЦП, для двух выполнений на однопроцессорной системе, в сравнении с результатами с рисунка 3. Все таблицы показывают сокращение времени вычислений, достигнутое AM в сравнении с нормальным выполнением для однопроцессорного моделирования. Для параллельного микро-слежения (на рисунке 4) ускорение нормального приложения прекращается после отметки в два процессора, в то время как техника AM продолжает ускоряться (в 3.83 раза) для узла с четырьмя процессорами. Это ясно показывает, что для него даже занятость контроллера не становится узким местом. И однопроцессорная и мультипроцессорная системы демонстрируют успех нашей усиленной техники поддержания когерентности. Более того, ускорение в мультипроцессорной системе показывает, что наши протоколы активной памяти пропорционально расширяются с увеличением числа процессоров.
Вывод
Методы работы с активной памятью, улучшая способы доступа приложения к данным, создают проблему когерентности этих данных. Так как диспетчер памяти обрабатывает каждый промах кэша и управляет протоколом когерентности, он имеет полный контроль над тем, которые строки памяти могут быть закэшированы каждым из процессоров в системе и в каком состоянии. Наш подход проводит в жизнь взаимное исключение между состояниями кэширования переадресованных строк кэша, естественно улучшая обычный протокол когерентности DSM, таким образом, эффективно решая проблему когерентности. Однако дизайн протоколов активной памяти поднимает некоторые уникальные проблемы, которые сильно отличаются по своей природе от проблем DSM. Преимущество использования программного обеспечения протоколов когерентности вместо аппаратных конечных автоматов в том, что первые могут поддержать новые техники работы с памятью без изменения аппаратных средств. Эта работа представляет значимые результаты для однопроцессорных систем и мультипроцессорных систем с одним узлом, которые подтверждают, что наш подход хорошо работает и расширяется с увеличением числа процессоров. Далее, это расширение протокола естественно необходимо применить в научных исследованиях систем с активной памятью со многими узлами, которые мы называем кластеры с активной памятью [3], которые могут достигнуть той же производительности, что и аппаратный DSM.
Список литературы
- Carter J. B. Impulse: Building a Smarter Memory Controller. In Proceedings of the Fifth International Symposium on High Performance Computer Architecture, January 1999.
- Hall M. Mapping Irregular Applications to DIVA, A PIM-based Data-Intensive Architecture. Supercomputing, Portland, OR, Nov. 1999.
- Heinrich M., Speight E., Chaudhuri. M. Active Memory Clusters: Effcient Multiprocessing on Commodity Clusters. In Proceedings of the Fourth International Symposium on High-Performance Computing, Lecture Notes in Computer Science, Springer-Verlag, May 2002.
- Kang Y. FlexRAM: Toward an Advanced Intelligent Memory System. International Conference on Computer Design, October 1999.
- Kim D., Chaudhuri M., Heinrich M. Leveraging Cache Coherence in Active Memory Systems. In Proceedings of the 16th ACM International Conference on Supercomputing, New York City, June 2002.
- Kuskin J. The Stanford FLASH Multiprocessor. In Proceedings of the 21st International Symposium on Computer Architecture, pages 302-313, April 1994.
- Oskin M., Chong F. T., Sherwood T. Active Pages: A Computation Model for Intelligent Memory. In Proceedings of the 25th International Symposium on Computer Architecture, 1998.