1.1 От графической обработки к общецелевым параллельным вычислениям.
Под влиянием ненасытных запросов рынка нашего времени, 3D-графики высокого разрешения, программируемое Графическое Процессорное Устройство или ГПУ стало высокопараллельным, многопоточным, многоядерным процессором с огромной вычислительной силой и очень высокой пропускной способностью памяти, как показано на рисунке 1-1.
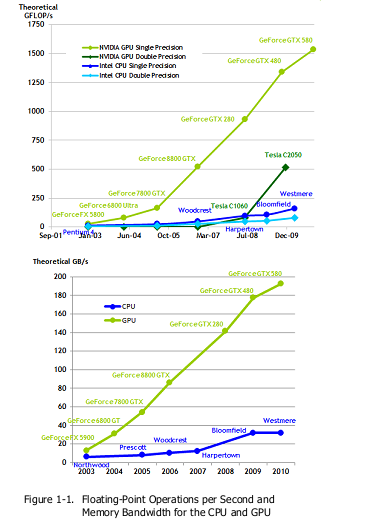
Рисунок 1-1
Причина в различии способности вычислений с плавающей запятой между ЦПУ и ГПУ в том, что ГПУ специализировано на интенсивных, высокопараллельным вычислениях – именно то, что нужно для графических построений – и поэтому разработано таким образом, что транзисторы лучше обрабатывают информацию, чем выполняют кеширование информации и управление потоками, как схематически показано на рисунке 1-2.
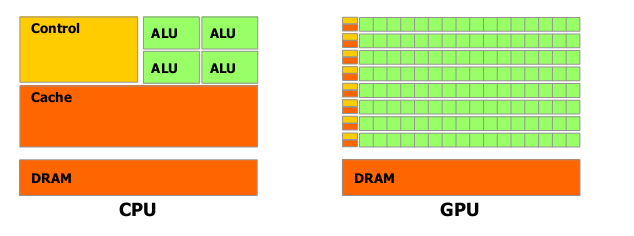
Рисунок 1-2. ГПУ выделяет больше транзисторов для обработки информации
Более определённо, ГПУ особенно подходит для решения проблем, которые могут быть представлены в виде параллельных вычислений – одна программа выполняется на многих элементах данных параллельно – с большой арифметической мощью – отношение арифметических операций к операциям памяти. Так как одинаковая программа выполняется для каждого элемента данных, существуют низкие требования к сложному управлению потоком, и так как она выполняется на многих элементах данных и имеет высокую арифметическую мощь, латентность доступа к памяти может быть покрыта вычислениями вместо больших кэшей данных.
Параллельная обработка данных распределяет элементы данных на параллельно обрабатываемых потоках. Многие приложения, которые обрабатывают большие множества данных, могут использовать параллельную программную модель для ускорения вычислений. В 3D построении, большие множества пикселей и вершин распределяются в параллельные потоки. Так же, приложения обработки изображений и медиа, такие как постобработка построенных изображений, кодирование и декодирование видео, масштабирование изображения, стерео изображение, распознавание шаблонов могут распределять блоки изображений и пикселей в потоки параллельной обработки. По факту, многие алгоритмы вне области построения и обработки изображений ускоряются параллельной обработкой данных, от общей обработки сигнала или физической симуляции до вычислительных финансов или вычислительной биологии.
1.2 CUDA™: a General-Purpose Parallel Computing Architecture (Общецелевая архитектура параллельных вычислений)
В ноябре 2006, NVIDIA представила CUDA™ , общецелевую архитектуру параллельных вычислений – с новой параллельной программной моделью и набором инструкций для архитектуры – которая использует движок параллельных вычислений в NVIDIA GPUs для решения многих сложных вычислительных проблем более эффективным способом, чем ЦП.
CUDA предоставляется с программным окружением, которое позволяет использовать Си как язык высокого уровня программирования. Как показано на рисунке 1-3, поддерживаются другие языки или интерфейсы программирования приложений, такие как CUDA FORTRAN, OpenCL, и DirectCompute.

Рисунок 1-3. CUDA создана с поддержкой различных языков и интерфейсов программирования приложений
1.3 Масштабируемая программная модель
Наступление эпохи многоядерных ЦП и многоядерных ГПУ означает, что сейчас основное направление для процессорных чипов – параллельные системы. Более того, их параллелизм продолжает расти по закону Мура. Сложно разработать приложение, которое явно увеличивает параллелизм, используя увеличенное число процессорных ядер, почти так как графические 3D приложения явно увеличивают их параллелизм на многоядерных ЦПУ с часто меняющимся числом ядер.
Параллельная программная модель CUDA создана, чтобы побороть эту сложность, пока есть мало изученная кривая для программистов, знакомых со стандартными языками программирования, такими как Си.
В центре этого есть три абстракции – иерархия групп потоков, разделённая память, и барьер синхронизации – они просто представлены в программе как минимальный набор языковых расширений.
Эти абстракции обеспечивают мелкозернистый параллелизм данных и потоков, вложенный в крупнозернистый параллелизм данных и задач. Они заставляют программиста разделять проблему на большие подпроблемы, которые могут быть решены независимо и параллельно с помощью блоков потоков, и каждая подпроблема маленькими кусками может быть решена совместно и параллельно с помощью всех потоков в блоке.
Это расчленение сохраняет языковую выразительность, позволяя потокам сотрудничать, когда решается каждая подпроблема, и в то же время даёт возможность автоматического масштабирования. В самом деле, каждый блок потоков может быть распределён на любом количестве процессорных ядер, в любом порядке, параллельно или последовательно, так что скомпилированная CUDA-программа может выполняться на любом количестве процессорных ядер, как показано на рисунке 1-4, и только во время выполнения системе нужно знать физическое количество процессоров.
Эта масштабируемая программная модель позволяет архитектуре CUDA охватывать широкую полосу рынка с помощью простого масштабирования числа процессоров и разделов памяти: от высокопроизводительных энтузиастских GeForce GPU и профессиональных Quadro и Tesla вычислительных продуктов до разнообразных недорогих, основных GeForce GPUs.
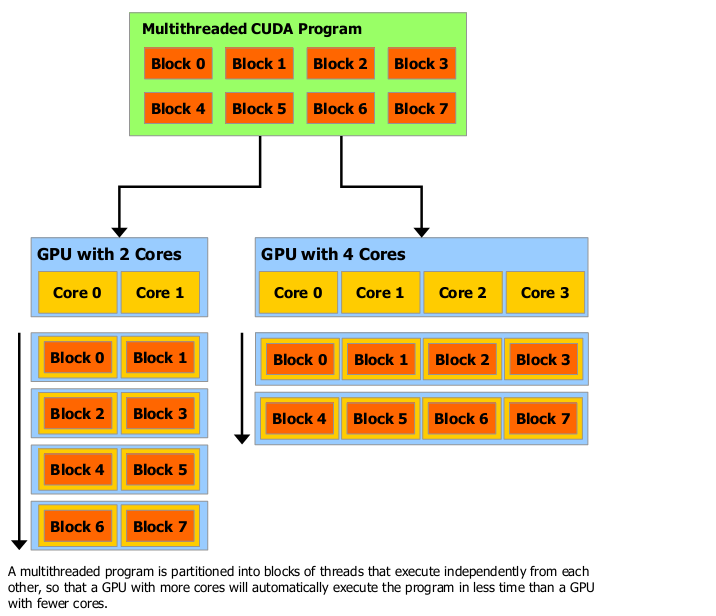
Рисунок 1-4. Автоматическое масштабирование.
Глава 2. Программная модель
Эта глава представляет основные концепции программной модели CUDA (Compute Unified Device Architecture), показывая, как они воплощаются в языке Си. Обширное описание CUDA дано в Главе 3.
Полный код примера дополнительного вектора используется в этой главе. Он может быть найден в образце кода vectorAdd SDK (Sofеware Development Kit, набор средств для разработки ПО)
2.1 Ядра
CUDA Cи основан на Си, позволяет программисту использовать функции Си, вызывать программные ядра, которые при запуске выполняются N раз параллельно на N разных CUDA потоках, в отличие от обычных Си функций, использующих только один поток.
Ядро описывается с помощью спецификатора __global__ , и количество выполняемых CUDA-потоков для данного вызова ядра обозначается с помощью нового синтаксиса конфигурации <<<…>>> (Приложение B.16). Каждому потоку, который выполняется на ядре, дан уникальный идентификационный номер, к которому есть доступ в ядре с помощью встроенной threadIdx переменной.
Например, следующий код складывает два вектора А и В размера N и сохраняет результат в векторе С:
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
}
Здесь каждый из N потоков выполняет VecAdd(), производя попарное суммирование
2.2 Иерархия потоков
Для удобства, threadIdx является 3-компонентным вектором, поэтому потоки могут быть идентифицированы с помощью одномерного, двумерного или трёхмерного индекса потока, формируя одномерный, двумерный или трёхмерный блок потока. Это обеспечивает естественный способ запуска вычислений через элементы в домене, такие как вектор, матрица или блок.
Индекс потока и его ID имеют прямую зависимость друг от друга: Для одномерного блока они одинаковы; для двумерного блока размера (Dx,Dy), для потока с индексом (x,y), ID потока – (x+yDx); для трёхмерного блока размера (Dx,Dy,Dz), для потока с индексом (x,y,z), ID потока – (x+yDx+zDxDy).
Например, следующий код складывает матрицы А и В размера NxN и сохраняет результат в матрице С:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<
}
Существует лимит количества потоков в одном блоке, так как все потоки в блоке могут находиться на одном процессорном ядре и должны совместно использовать ограниченные ресурсы памяти этого ядра. На современных GPU блок потоков может содержать до 1024 потоков.
Однако ядро может выполняться на многих эквивалентных блоках потоков, поэтому общее число потоков равно числу потоков на блок, умноженному на число блоков.
Блоки представляют собой одномерные, двумерные или трёхмерные решётки потоковых блоков, как показано на рисунке 2-1. Количество потоковых блоков в решётке обычно определяется размером данных, которые обрабатываются, или количеством процессоров в системе, которое могут значительно уступать количеству блоков.

Рисунок 2-1.Сетка (grid) блоков потоков
Количество потоков на блок и количество блоков на решётку определяется синтаксисом <<<…>>>, который может иметь тип int или dim3. Двумерные блоки или решётки могут быть определены как в примере выше.
Каждый блок внутри решётки может быть идентифицирован одномерным, двумерным или трёхмерным индексом, доступным внутри ядра через встроенную переменную blockIdx. Измерение потокового блока доступно внутри ядра через встроенную переменную blockDim.
Расширенный код предыдущего примера MatAdd() управления множественными блоками приведен ниже:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<
}
Блок потоков размером 16х16 (256 потоков), хотя в этом случае, это общий выбор. Решётка создана с достаточным количеством блоков, для того, чтобы иметь один поток на элемент матрицы, как и раньше. Для простоты, этот пример принимает число потоков на решётку в каждом измерении таким, которое делится без остатка на число потоков на блок в этом измерении. Но это может быть не так.
Потоковые блоки должны выполняться независимо: должна быть возможность их выполнения в любом порядке, параллельно или последовательно. Это требование независимости позволяет потоковым блокам быть размещёнными в любом порядке на любом количестве ядер, как показано на рисунке 1-4. Это позволяет программистам писать код, который приспосабливается под количество ядер.
Потоки внутри блока могут сотрудничать с помощью разделения данных в некоторой общей памяти и синхронизации их выполнения для координации доступа к памяти. Более точно, можно установить точки синхронизации в ядре с помощью вызова встроенной функции __syncthreads(); __syncthreads() работает как барьер, на котором должны ждать все потоки блока, пока один из них не сможет возобновиться. Раздел 3.2.3 имеет пример использования общей памяти.
Для эффективного взаимодействия, общая память должна иметь низкую латентность, близкую к латентности ядра процессора (похожую на L1 кэш), и __syncthreads() должна быть ниже среднего.
2.3 Иерархия памяти
Потоки CUDA могут иметь доступ к памяти из множественных областей памяти в течение их выполнения, как показано на рисунке 2-2. Каждый поток имеет приватную локальную память. Каждый поток блока имеет общую память, видимую для всех потоков в блоке, и с тем же временем жизни, что и блок. Все потоки имеют доступ к той же глобальной памяти.
Существуют две дополнительных, доступных только для чтения областей памяти, к которым имеют доступ все потоки: области констант и текстур. Глобальные, константные и текстурные области памяти оптимизированы для различного использования памяти (Разделы 5.3.2.1, 5.3.2.4 и 5.3.2.5). Текстурная память также позволяет различные режимы адресации, такие как фильтрация данных, для некоторых специфических форматов данных (Раздел 3.2.10).
Глобальные, постоянные и текстурные области памяти сохраняются в течение использования ядра приложением.
2.4 Неоднородное программирование
Как показано на рисунке 2-3, модель программирования CUDA предполагает, что потоки CUDA выполняются на физически отдельных устройствах, которые действуют как сопроцессор хоста, и выполняют Си-программу. Это случай, когда, например, основа выполняется на ГПУ, а остальная часть Си-программы выполняется на ЦПУ.
Модель программирования CUDA также предполагает, что и хост, и устройство, содержат их собственные отдельные области памяти на DRAM, ссылающиеся на память хоста и память устройства, соответственно. Поэтому, программа управляет глобальными, константными и текстурными областями памяти, видимыми для ядер во время выполнения CUDA (описано в главе 3). Это включает в себя распределение и освобождение памяти устройства так же, как и передачу данных между памятью хоста и устройства.
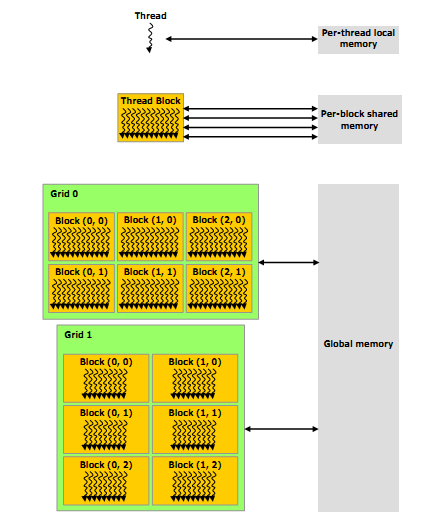
Рисунок 2-2. Иерархия памяти
2.5 Вычислительные возможности
Вычислительные возможности устройства определены в старшей и младшей частях номера версии.
Устройства с одинаковым номером версии имеют одинаковую архитектуру ядра. Старшая часть номера устройств, основанных на архитектуре Ферми, равна 2. Предшествующие устройства имеют вычислительные возможности 1.х (их старшая часть номера версии равна 1).
Младшая часть номера версии соответствует постепенному улучшению архитектуры ядра, возможно, включая новые черты.
Приложение А содержит список устройств, поддерживающих CUDA, вместе с их вычислительными возможностями.
Приложение F даёт техническую спецификацию для каждой вычислительной возможности.
Глава 3. Программный интерфейс
CUDA Си обеспечивает пользователям, привыкшим к Си, простой путь для лёгкого написания программ для выполнения на устройстве.
Этот язык содержит минимальный набор расширений языка Си и библиотеку выполнения.
Расширения языка ядра были представлены в главе 2. Они позволяют программистам определить ядро как функцию Си, а также используют новый синтаксис для установки измерений решётки и блока каждый раз, когда функция вызывается. Полное описание всех расширений можно найти в приложении В. Людой файл источника, который содержит некоторые из этих расширений, должен быть скомпилирован с помощью nvcc, как описано в Разделе 3.1.
Время выполнения (tuntime) представлено в Разделе 3.2. Оно предоставляет функции Си, которые выполняются на хосте для распределения и освобождения памяти устройства, передачи данных между памятью хоста и памятью устройства, управления системами с множественными устройствами и т. д. Полное описание времени выполнения может быть найдено в справочных материалах по CUDA.
Время выполнение построено на вершине низкого уровня API(интерфейс программирования приложений) Си, CUDA драйвере API, который также доступен приложению. Драйвер API обеспечивает дополнительный уровень контроля, раскрывая низкоуровневые концепции, такие как фон CUDA – аналог процессов хоста (для устройства) – и CUDA модули – аналог динамически загруженных библиотек (для устройства). Инициализация, фон и управление модулями являются неявными во время рантайма, что приводит к большему сжатию кода. Обычно приложение использует или рантайм, или драйвер API, но может использовать оба, как описано в разделе 3.4.
Драйвер API представлен в разделе 3.3. Полное описание может быть найдено в справочных материалах по CUDA.
Раздел 3.2 представляет концепцию, которая одинакова для рантайма и драйвера API: линейная память, массивы CUDA, общая память, текстурная память, память хоста с заблокированными страницами, перечисление устройств, асинхронное выполнение, совместимость с графическими API. Раздел 3.3 представляет знания об этих концепциях и описывает, как они воплощены в драйвере API.
3.1 Компиляция на NVCC
Ядра (основа программы) могут быть написаны с использованием набора инструкций архитектуры CUDA, названного PTX, который описан в справочных материалах по PTX. Однако, обычно более эффективно использовать языки высокого уровня, такие как Си. В обоих случаях, для выполнения на устройстве ядра должны быть скомпилированы в двоичный код компилятором nvcc.
nvcc – драйвер компиляции, который упрощает процесс компиляции Си или PTX кода: Он обеспечивает простые и привычные опции командной строки, и выполняет их путём применения набора инструментов, которые осуществляют различные стадии компиляции. Этот раздел даёт обзор рабочего процесса и командных опций nvcc. Полное описание может быть найдено в справочных материалах по nvcc.
3.1.1 Рабочий процесс компиляции
3.1.1.1 Оффлайн компиляция
Файлы источника, скомпилированные nvcc, могут содержать смешенный код хоста (то есть, код, который выполняется на хосте) и код устройства (то есть, код, который выполняется на устройстве). Основной рабочий процесс nvcc состоит из кода устройства, отделённого от кода хоста, и:
- компиляции кода устройства в ассемблерную форму (PTX код) и/или двоичную форму (объект cubin);
- модификации кода хоста путём замещения синтаксиса <<<…>>>, представленного в Разделе 2.1 (и описанного более детально в в Разделе В.16) необходимой рантайм функцией CUDA Си, запускающей загрузку и выполнение каждого скомпилированного ядра из кода PTX и/или объекта cubin.
Модифицированный код хоста создаётся как Си код, скомпилированный другим методом, или как код объекта, позволяющего nvcc вызывать компилятор хоста в течение последней стадии компиляции.
В этом случае приложения могут:
- Либо связываться со скомпилированным кодом хоста;
- Либо игнорировать модифицированный код хоста (если такой имеется) и использовать CUDA драйвер API (Рздел 3.3) для загрузки и выполнения PTX кода или объекта cubin.
3.1.1.2 Just-in-Time компиляция
Любой PTX код, загруженный приложением во время выполнения компилируется в дальнейшем в двоичный код драйвером устройства. Это называется Just-in-Time компиляция («в нужный момент»). Just-in-Time компиляция увеличивает время загрузки приложения, но позволяет приложениям получать выгоду от дальнейших усовершенствований компилятора. Это также единственный путь для приложений, чтобы запуститься на устройствах, которые не существовали в то время, когда приложение было скомпилировано.
Когда драйвер устройства компилирует методом Just-in-Time некоторый PTX код для некоторого приложения, автоматически скрывается копия сгенерированного двоичного кода, чтобы запретить повторение компиляции в более поздних вызовах приложения. Кэш передаётся как обработанный кэш – он автоматически аннулируется, когда обновляется драйвер устройства, так что приложения могут получить выгоду от совершенствований нового Just-in-Time компилятора, встроенного в драйвер устройства.
Переменные окружения, доступные для управления Just-in-Time компиляцией:
- Установка CUDA_CACHE_DISABLE в 1 отключает кэширование (то есть двоичный код не добавляется в кэш и не возвращается из него);
- CUDA_CACHE_MAXSIZE устанавливает размер обрабатываемого кэша в байтах; по умолчанию размер 32 Мб, максимальный размер 4 Гб; двоичный код с размером, превышающим размер кэша, не кэшируется; более старый двоичный код удаляется из кэша, чтобы дать место новому двоичному коду, если необходимо;
- - CUDA_CACHE_PATH устанавливает папку, где сохраняются файлы обработанного кэша; значения по умолчанию:
- в Windows, %APPDATA%\NVIDIA\ComputeCache,
- в MacOS, $HOME/Library/Application\ Support/NVIDIA/ComputeCache,
- в Linux, ~/.nv/ComputeCache.
- Установка CUDA_FORCE_PTX_JIT в 1 заставляет драйвер устройства игнорировать любой двоичный код, встроенный в приложение (см. Раздел 3.1.4) и, вместо него, компилирует методом just-in-time встроенный PTX код; если ядро не имеет встроенного PTX кода, оно не загрузится; эта переменная окружения может быть использована для подтверждения того, что PTX код встроен в приложение и того, что его just-in-time компиляция работает как ожидалось – гарантирует совместимость с будущими архитектурами.
3.1.2 Двоичная совместимость
Двоичный код привязан к архитектуре. Объект cubin генерируется с использованием опции компилятора –code, которая устанавливает целевую архитектуру: например, компилирование с опцией –code=sm_13 порождает двоичный код для устройств с вычислительной способностью 1.3. Двоичная совместимость гарантируется при переходе к следующему коду с небольшими изменениями, но не к предыдущему коду или коду с большими изменениями. Другими словами, объект cubin, сгенерированный для вычислительной способности X.y, точно выполнится только на устройствах с вычислительной способностью X.z, где z>=y.
3.1.3 PTX совместимость
Некоторые инструкции PTX поддерживаются только на устройствах с высокими вычислительными способностями. Например, атомные инструкции глобальной памяти поддерживаются только на устройствах с вычислительной способностью 1.1 и выше; инструкции с двойной точностью поддерживаются только на устройствах с вычислительной способностью 1.3 и выше. Опция компилятора –arch устанавливает вычислительную способность, которая присваивается при компиляции Си в PTX код. Таким образом, код, который содержит арифметику двоичной точности, например, должен быть скомпилирован с опцией “-arch=sm_13” (или более высокая вычислительная способность), иначе арифметика с двойной точностью понизится до арифметики с одинарной точностью.
PTX код создаётся для некоторых специфических вычислительных способностей, которые всегда могут быть скомпилированы в двоичный код с более высокой или равной вычислительной способностью.