Рисунок 1 – Части с OFDM внутренней приемника
Автор:
A. Carlsson, J. Ekker, C. von Platen,
T. Olsson
Автор
перевода: Леухин С. Г.
Источник:http://www.ericsson.com/res/docs/review/scalable_parallelism.pdf
Модели для функционального программирования и потоков данных программирования - в центре внимания этой статьи-есть потенциал, чтобы облегчить параллельное программирование. Чтобы эта концепция практично, однако, средства разработки должны развиваться.
Обработка сигнала часто моделируется как потоки данных. Схема, например, является одной из форм описания потоков данных, особенно на уровне блок-схемы. Многие формы расчета хорошо подходят для описания и реализации потоков данных. Некоторые общие примеры включают сложные медиа-кодирования, обработки сети, изображений и цифровую обработку сигнала и встроенный контроль.
Цифровое радио является одним домен приложения, которые могут быть успешно моделируется с помощью потоков данных. Поток данных моделирования облегчает компонента изоляцию и "подключаемые" обработки цепочек. Производительность повышения функциональности, такие как гибридный автоматической запрос на повтор (HARQ), может быть реализована в качестве дополнительного модуля. Учитывая, что каждое новое поколение мобильных терминалов будет поддерживать большее количество стандартов радиосвязи, более функциональность реализуется в программном обеспечении или программируемого оборудования. Построение технологической цепочки от подключаемых модулей - либо стандартный - специфический или универсальный с параметрами - поэтому привлекательным предложением.
Поток данных моделирования не только средством создания приемопередатчиков реализации. Использование потоков данных моделирования также может выявить узкие места от недостатка параллелизма, присущего стандарта радио. Это особенно полезно при разработке новых стандартов. Для поддержки более широкого спектра максимальными скоростями связи, стандарты радиосвязи следующего поколения будет масштабируемым с точки зрения требований к емкости и обработки. В идеале, она должна быть возможность построить большой емкости трансивер, дублируя аппаратные средства базового трансивера. Чтобы сделать это,Потенциальный параллелизм должен масштабировать в линейный путь с требованиями к обработке.
Параллельное программирование не новое предложение или проблемой. В конце 1960-х годов, исследователи пытаются сделать переход к параллельным вычислениям. В то время, производительность обработки в два раза примерно каждые 18 месяцев, и эта тенденция, которая продолжалась в течение следующих трех десятилетий. По большей части, увеличение тактовых частот поехали такое развитие событий. В результате быстрое развитие производительности, последовательные программы оказалось достаточно для многих вычислительных дисциплин, но эта тенденция развития компьютерной техники закончилась. Постоянно растущее тактовые частоты пришли к резкому концу в 2005 году из-за, среди прочего, основных проблем, связанных с блоком питания и тепла.
Будущие достижения в производительности, как ожидается, приходят из более широкого использования параллелизма, чему способствует улучшенной плотности транзистора. Компьютеры Многоядерные примером этого развития, и прогнозы на других секторах указывают в том же направлении. Для портативных потребительской электроники, Международный научно-технический Дорожная карта для полупроводников (СПУ) издание 2009 предусматривает экспоненциальный рост в параллелизма, в результате чего сотни параллельных процессорных элементов в пределах пяти до десяти лет.
Чтобы использовать эту разработку, исполнение приложения или системы должна быть масштабируемой через параллелизма. Тем не менее, большинство приложений были построены для размещения традицию постоянно растет тактовых частотах и по сути своей последовательной и поэтому не подвержены параллелограмма lelization, представляя собой вызов для индустрии программного обеспечения. В противоположность этому, телекоммуникационный сектор находится в хорошем положении, благодаря своей практике проектирования параллельных систем. Задача состоит в том, чтобы сделать-флзических использование ofincreasing параллелизм, а не позволяя параллельное выполнение.
Несколько исследовательских центров были созданы и многие проекты были начаты по решению проблем, связанных с многоядерными процессорами. Примеры включают параллельные вычисления лаборатория (ParLab) в Университете Калифорнии в Беркли, повсеместная Параллелизм лаборатория (PPL) в Стэнфордском университете и HiPeac Европейская сеть Excellence. Сотрудничества с внешними партнерами включают ACTORS и DSL4DSP. Ericsson также активно исследования в этой области.
С и родственные языки программирования являются доминирующими для программного обеспечения в области потребительской электроники, встраиваемых мультимедиа и коммуникационного оборудования. Тем не менее, контроль C над низкоуровневых деталей, как правило, считается хорошей вещью, как правило, предопределенной программ. Помимо указания алгоритмов, C определяет, как по своей сути параллельные вычисления секвенировали, как входы и выходы передаются между алгоритмов и, на более высоком уровне, как вычисления, отображенных на тему, переработчиков и конкретных приложений оборудовании.
Используя анализ, это не всегда можно восстановить оригинальную знания о программе и шансы на преобразования реструктуризации ограничены. Таким образом, С не является хорошей отправной точкой для распараллеливания. Инструменты и механизмы, такие как OpenMP5 и интерфейсом передачи сообщений (MPI), используются для облегчения строительство параллельных программ на языке Си для многоядерных и многопроцессорных систем. Эти инструменты являются, однако, сильно ограничены, так как они могут подвергать параллелизм только тогда, когда она была четко определены программистом, и они не поддерживают программистов в оценке правильности распараллеливания.
В аппаратного обеспечения, нынешняя практика заключается в создании низкоуровневое описание, также известный как Регистрация Transfer Logic (RTL). Уровень абстракции RTL имеет тенденцию к снижению, что приводит к длительным циклом развития, влияющих на рынок.
Великие достижения в эффективности оборудования могут быть изготовлены из архитектурного оптимизации. По этой причине желательно, чтобы повысить уровень абстракции описания аппаратного обеспечения, и, как следствие, использование инструментов высокого уровня.
Потому что RTL по своей сути параллельно, легко перевести параллельный описание на языке высокого уровня в RTL. К сожалению, описания в традиционных языках программирования, таких как C, не карту одинаково хорошо из-за трудностей в решении последовательный характер традиционных языков программирования в параллельных аппаратных средств.
Программа потока данных определяется как ориентированного графа, где узлы предста - послал вычислительных блоков или актеры, и дуги представляют поток данных - каналов связи, которые соединяют актеров. Актер занимается исключительно отображение свой вклад в выход. Зависимости выражаются подключения актеров; нет другой источник зависимости. Эти свойства делают потоков данных программ очень гибким с точки зрения разделения и последовательности вычислений.
Было показано, что модели потока данных предлагают представление, которое может эффективно поддерживать задачи параллелизации и векторизации, таким образом обеспечивая практические средства поддержки многопроцессорных систем и использования вектора инструкции. Интересно, что поток данных программы увеличиваются в размерах они имеют тенденцию подвергать более параллелизм.
В параллельных вычислений, различие между параллелизм, что весы с размером проблемы, известной как параллелизма данных и параллелизм, что весы с размером программы, известной как целевой параллелизма. Масштабирование алгоритм над большими объемами данных является относительно хорошо понимал проблема, которая относится к потока данных программ, а также других моделей программирования. В то время как программа поток данных имеет простой механизм параллельной композиции, трудно, например, сочинять, программу на С, чьи части выполняться параллельно без вмешательства.
Есть несколько классов программ данных потока. Эти классы различаются по выразительности и analyzability. На одном конце спектра находятся технологические сети Kahn, которые могут выразить любые вычисления. Хотя не все интересные свойства этих сетей может быть установлена путем анализа программ (процесс Кан сети Тьюринга). На другом конце находятся синхронные потоков данных сетей, для которых создание статических планов и связанные требования к памяти могут быть определены для того, чтобы заявления о (отсутствие) тупик. Недостатком является ограниченное выразительность, как одновременно поток данных не может выразить поток управления, например зависит ввод итерации.
Ограниченное модели потоков данных, таких как синхронное потока данных, может быть синтезируется в особенно эффективен
Код, в то время как более общих форм потока данных программ, таких как процесса Кан сетей, как правило, планируется динамически, что порождает времени выполнения накладных расходов.
CAL язык актер (CAL) является предметно-ориентированный язык, что дает полезные абстракции для потоков данных программирования с актерами. Он был использован в широком спектре приложений и скомпилирован для аппаратных и программных реализаций. Работа по смешанной аппаратных и программных реализаций продолжается.
Базовая структура актера CAL показан например ниже, который имеет два входных порта, А и В. Актер содержит одно действие, что при выстреле, потребляет один маркер на каждом из входных портов и производит один маркер на выходном порту. Действие может сработать, если наличие маркеров на входных портов соответствует модели портов, который в этом примере, соответствует один жетон на порты А и В.
Приведенные выше примеры довольно тривиально, как типичные субъекты могут быть несколько сотен строк кода. Сортировка, например, могут быть реализованы с парой актеров (тот, который содержит два действия и другой, который содержит четыре действия) вместе с сетью, которая связывает несколько случаев в цепи в соответствии с количеством данных, которые должны быть отсортированы.
CAL позволяет несколько способов экспрессии и управления потоком данных. Два актера никогда не может разделить государство и их единственным средством связи осуществляется через актер портов. Исполняющая система отвечает за то, как и когда актер планируется. Актер просто спецификация, которая описывает действия, которые будут происходить в ответ на присутствие данных . Актер модель CAL допускает полное разделение между планирования субъектов и алгоритма, что сеть актера определяет. И той же сети могут быть запланированы в различных ofways, в результате чего все же функционального результата, но с разными сроками и вычислительных свойств.
Актеры могут быть записаны в различных языках. CAL исключает некоторые повторяющиеся кодирование, но в остальном сопоставимой эффективности, с точки зрения строк кода. Еще одним преимуществом использования CAL является то, что он определяет сетевые соединения вне кода актер. Это упрощает необходимость любого структурного мастерить с алгоритмы и в конечном итоге приводит к более эффективным реализациям.
Реконфигурируемая видео кодирования мультимедиа обработку можно легко моделируется с помощью потоков данных. Недавнее развитие в MPEG делает CALподходит язык для экспериментов в этой области. MPEG реконфигурируемая кодирование видео (РВК ) база является новым стандартом ISO, которая призвана обеспечить характеристики видео кодеков на уровне компонентов библиотеки, вместо монолитных алгоритмов. Основная идея заключается в определении декодер, выбрав компоненты (или актеров ) из стандартной библиотеки алгоритмов кодирования. Возможность динамического конфигурирования и перенастроить кодеки требует новых методологий и новых инструментов для описания битового потока синтаксиса и парсеров новых кодеков. Рамки РВК использует язык актер CAL указать стандартную библиотеку и экземпляра модели РВК декодера. РВК состоит из двух спецификаций ISO/IEC.
Во всем мире асинхронный локально синхронная ( ГАЛС ) Асинхронный архитектура крупнозернистый, например, ГАЛС, позволяет использовать преимущества синхронные, а также асинхронные конструкции методик. Обычно разница в показаниях часов в синхронных цифровых устройств ограничена в результате осуществления сбалансированной часы дерево. Цель сбалансированного часы дерево, чтобы сделать все задержки часы равны. Тем не менее, достижение равных задержки в часы дерево становится все труднее по мере усложнения системы возрастает. ГАЛС конструкции уменьшить сдвиг часового пояса ограничений и дать меньшие тактовые деревья, потому что синхронизация не глобальная проблема в ГАЛС. ГАЛС может снизить индуцированного шума от часов в аналоговые, а шум от цифровой части поступает из нескольких меньших тактовых област, а не из одной большой тактовой области. Переключение шум от тактовых сетей есть Поэтому распространено в течение долгого времени. Кроме того, отсутствие глобальной синхронизации дает возможность экономить энергию в тактовой сети.
Существует тесная связь между ГАЛС и описания потока данных. Использование первым вошел, первым вышел (FIFO) каналов общаться между процессами в описаниях потока данных может перевести непосредственно в спецификации ГАЛС. Процессы потоков данных реализованы как синхронных блоков и каналов FIFO реализованы в виде асинхронных коммуникационных каналов. CAL потоков данных сети поддерживают несколько доменов часы, с до одного часы домена на актера. Замена FIFO каналов между тактовых доменов с асинхронными FIFO каналов преобразует поток данных в сеть ГАЛС, делая CAL DataFlow привлекательным кандидатом для моделирования Галс архитектуры. Потому ГАЛС конструкции состоят из модулей с четко определенным интерфейсом, ГАЛС также способствует модульной конструкции. Работа, чтобы попытаться превратить CAL поток данных к сети ГАЛС в продолжается.
Следующие тематические исследования иллюстрируют различные приложения потоков данных программирования, где и аппаратное и программное обеспечение были синтезированы из моделей CAL потока данных.
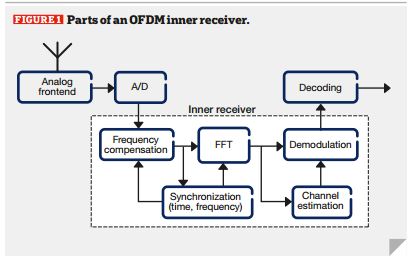
OFDM внутренний приемник Цифровой приемник радио можно разделить на аналоговый переднего плана, цифровой интерфейс, внутренний приемник и внешний приемник.
Рисунок 1 – Части с OFDM внутренней приемника
Основной OFDM внутренний приемник состоит из синхронизатора, частота ошибок компенсатора, быстро трансформатора Фурье (БПФ), оценки канала, эквалайзер и демодулятора. Из этих частей, реализация состоит компенсации частоты, синхронизатор и БПФ.
Синхронизатор, который оценивает положение времени и погрешность частоты с координатной вращения цифровой вычислительной машины (CORDIC) ротатора для компенсации цифровой погрешности частоты; и БПФ - в этом случае, конфигурируемый FFT, который поддерживает максимальную длину сим бол 8К образцов.
Спецификация языка использовали CAL. Описание потока данных был синтезирован на основе ПЛИС платформы совсем готовые разработки с использованием открытых DataFlow (OpenDF) и OpenForge инструменты. Данные испытаний была передаваться по Ethernet на плату разработки и результат был показан на подключенном дисплее VGA. Синтезированное оборудование способно обработки 50 Megasamples/с, что вполне достаточно для реального времени. Для получения дополнительной информации о выполнении, см. Реконфигурируемая OFDM Внутренний приемник Реализовано в CAL Dataflow языка.
Удалось достичь поставленных целей производительности, но реализация CAL используется больше ресурсов, чем сопоставимые реализации RTL, в значительной степени из-за относительно сырой инструментов. По сути, существует связь один -к-одному между кодом CAL и RTL, возложение бремени оптимизации на набора инструментов RTL. Некоторые источники накладных расходов были выявлены в CAL для перевода RTL, и ведется работа по резко сократить это.
В другом примере,декодер MPEG-4 было указано в CAL и реализованы на FPGA.18код, генерируемый из спецификации CAL превзошли ссылку в VHDL (язык описания аппаратных средств), достижения более высокой производительности с меньшим аппаратным ресурсам. Реализация CAL требуется значительно меньше усилий в области развития. CAL поощряет рассуждения, касающиеся интерфейсов и структуры. Предрасполагающими факторами являются: строгая изоляция внутренних органов актера, асинхронные интерфейсы маркеров и иерархическая моделирование сети. Эти особенности также ограничить влияние изменений актер.
В результате сравнительно легко перестроить систему, пока он не встречает желаемых эксплуатационным требованиям. В конечном счете, это приводит к значительно снижается усилие разработчиков для данной функциональности, с минимальным или без штрафа в районе или производительности; особенно для больших и сложных проблем. Тем не менее, для небольших систем с регулярной структурой и широкими каналами данных, таких как БПФ, накладные расходы на управление потоком и действий планировщика появляются затмить структурные выгоды.
Многоядерных MPEG-4 декодер Во втором примере,декодер MGEG-4 простой профиль реализованы в программном обеспечении на 200 МГц четырехъядерным процессором ARM11 MPCore, используя инструменты генерациикода разработанные в рамках проекта актера. ACT ПРС Поток данных модель была взята из инструментов РВК. Основные функциональные блоки - сами по себе иерархические композиции актер сетей (рис.2)
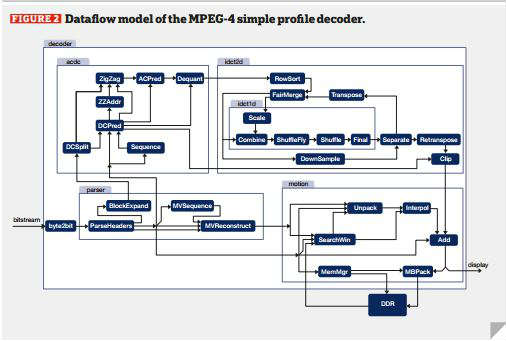
Рисунок 2 – Поток данных модель простого профиля декодер MPEG4
Эффективное реализация модели потока данных на архитектуре многоядерного, включает в себя вызов, как разделить нагрузку. В то время как семантика модели потока данных позволит любому из актеров, которые будут развернуты на любом из ядер без нарушающего зависимости данных, то, как актеры разделены воздействия значительно на производительность системы. Два (иногда противоречивые) цели, которые должны быть рассмотрены в сбалансированная нагрузка в течение ядер и минимальными затратами связи. Разметка может выполняться статически (офлайн) или динамически (во время выполнения).
Наивный исполнение модели потока данных связано с значительными накладными расходами. В первом, наивной, попытки, каждый актер был казнен в отдельном потоке, синхронизированы с FIFO, в общей памяти. Таким образом, планировщик операционной системы (SMP Linux) удалось нагрузки динамически. В второй попытки, актеры были разделены статически и каждое ядро выполняется один рабочий поток. Этот подход повышение производительности на несколько порядков величины. Очевидно, что первый подход сильно пострадала от накладных расходов на переключение контекста. Предпринимаются усилия, чтобы преследовать идею разделения субъектов динамически, но пока еще, отличным решением не были разработаны.
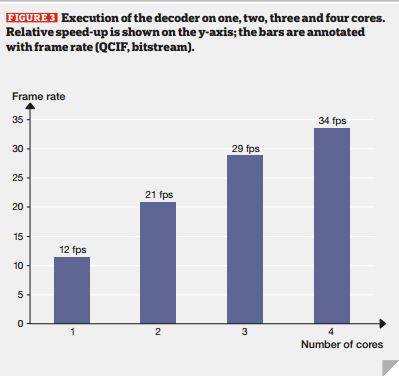
Рисунок 3 – Выполнение декодера на один, два, три и четыре ядра. относительная скорость вверх показан на оси у; бары аннотируются с частотой кадров (QCIF, битового потока).
Рисунок 3 показывает результаты разбиения декодер MPEG на один через четыре ядра. Хорошая скорость планы были достигнуты за счет увеличения количества ядер. Перегородки были, однако, найдено вручную, а это означает, что это решение остается неисследованным по большей части. Более продвинутые инструмент поддержки будет способствовать дальнейшему ускорить процесс поиска и значительно улучшить качество разделов.
Существует возможность для улучшения, когда дело доходит до Частота кадров. Текущее решение еще незрелый, составление актеров отдельно и рассматривая их как отдельные объекты, даже во время выполнения. Учитывая прекрасно уровень детализации, к которому декодер MPEG указан, то накладные расходы этой модели выполнения высока по отношению к полезному труду она выполняет. Модель Компилятор, недавнее развитие АКТЕРЫ проект, позволяет несколько актеров, которые будут обобщены совместно. Для более ранней позиции на компилятором модели, см. эффективной реализации видеодекодер CAL на мобильный Termina Для классической работе в этой области см. ссылки 7 и 20. Предполагается, что совместные кофакторы синтеза позволит значительно повысить производительность за счет снижения накладных расходов, связанных с передача данных и планирование.
Исторический тенденция постоянно увеличивающихся тактовых частотах пришел к концу. В будущем увеличение производительности будут выведены из увеличения параллелизма. Поэтому системы, исполнение весы с увеличения параллелизма сделать привлекательным предложением.
Особая проблема с современной практикой является более - спецификации. Программное обеспечение имеет тенденцию быть указан таким образом, что расчеты по частям, в противном случае подвергать потенциал параллелизма. Спецификация Низкий уровень аппаратных (например, RTL) является дорогостоящим для разработки и спецификация времени усложняет рефакторинга конструкций.
Потоковые модели хорошо подходят для описания многих форм вычисления, особенно в области цифровой обработки сигналов. Таким образом, поток данных программирования интересный подход, который может быть применен к высоко параллельных вычислительных систем, найденных в мобильных терминалов и базовых станций.
Программа потоков данных состоит из вычислительных блоков называемых актеры, которые могут, но не обязательно должны выполняться параллельно. Это очень гибкая модель программирования позволяет для исследования пространства дизайна. Потоковые модели были использованы в двух тематических исследований для определения декодер MPEG-4 видео и мульти-стандартного приемника в OFDM. Аппаратное и программное обеспечение были синтезированы из моделей. Большая часть этой работы была выполнена в рамках европейских FP-7 актеров и проектов MultiBase, используя инструменты и методологии, предоставленные на initiative. OpenDF, модели MPEG РВК использовались в случае видеодекодером учиться, в то время как модель OFDM был разработан в рамках этой работы.
Способность принимать быстрые итераций проектирования, имеет огромное значение при разработке оборудования из модели OFDM. Удалось исследовать массив дизайнерских идей на архитектурном уровне в ограниченное время разработки. Цели в - производительности были встречены, но потребности в ресурсах (соответствующие кремния области) превысили сопоставимой конструкции RTL. Программное обеспечение, который был синтезирован из модели MPEG РВК, может быть разделена таким образом, что производительность масштабируется с числом доступных ядер. Однако производительность на одном ядре значительно ниже, чем у сравнимого реализации в С.
Тематические исследования показано несколько интересных свойств потока данных программирования. В частности, модели могут быть разделены и реструктурировать на гибкой основе. Дальнейшее совершенствование OpenDF инструментов требуется сделать синтезированный код более эффективным.