Аннотация
Бибиков И.В., Черевко Р.Ю. Автоматизированное извлечение знаний из реляционных баз данныхВыполнен анализ работы алгоритма С4.5 для извлечения знаний из реляционных баз данных. Построено дерево решений на основе таблицы БД. Получены продукционные правила из таблицы БД. Программно реализован алгоритм.
Ключевые слова: извлечение знаний, базы данных, дерево решений, алгоритм С4.5.
Постановка проблемы
В наше время ни одна организация, предприятие или заведение не может обойтись без системы реляционных баз данных. Для извлечения знаний вручную
из баз данных требуется много времени и сил. Чтобы облегчить данную задачу, рассмотрим алгоритм С4.5, для которого потребуется таблица с данными. Для корректного извлечения знаний потребуется:
- рассчитать данные таблицу по алгоритму С4.5;
- построить дерево решений;
- определить продукционные правила.
Анализ литературы
Проведен анализ инструментов извлечения знаний из баз данных. Наиболее распространенными на данный момент продуктами на рынке являются системы See5 и WizWhy.
Система See5 относится к наиболее представительному и популярному направлению, связанному с построением дерева решений. Разработана компанией RuleQuest и предназначена для анализа больших баз данных, содержащих до сотни тысяч записей и до сотни числовых или номинальных полей. Результат работы выражается в виде деревьев решений и множества if–then–правил. Стоимость See5 — 740$, некоммерческая версия для обучения ограничена количеством анализируемых записей (до 200). Для проверки качества построенных деревьев решений и соответствующего множества логических правил в системе See5 предусмотрена возможность работы со специальными фалами, в которых содержатся дополнительные тестовые данные.
Система WizWhy предприятия WizSoft является современным представителем подхода, реализующего ограниченный перебор. Этот алгоритм вычисляет частоты комбинаций простых логических событий в
подгруппах (классах) данных. Примеры простых логических событий: X = C1; X < C2; X > C3; C4 < X < C5 и др., где X — какой либо параметр (поле), Ci — константы. Ограничением служит
длина комбинации простых логических событий. На основании сравнения вычисленных частот в различных подгруппах данных делается заключение о полезности той или иной комбинации для
установления ассоциации в данных, для классификации, прогнозирования и пр. Хотя разработчики системы не раскрывают специфику алгоритма, положенного в основу работы WizWhy,
вывод о наличии здесь ограниченного перебора был сделан по результатам тщательного тестирования системы (изучались результаты, зависимости времени их получения от числа анализируемых
параметров и др.). По–видимому, в WizWhy ограниченный перебор используется в модифицированном варианте с применением дополнительного алгоритма Apriori
, заранее исключающего из анализа
элементарные логические события, встречающиеся с одинаково высокой (низкой) частотой в различных классах.
Авторы WizWhy акцентируют внимание на следующих общих свойствах системы:
- Выявление ВСЕХ if–then правил
- Вычисление вероятности ошибки для каждого правила
- Определение наилучшей сегментации числовых переменных
- Вычисление прогностической силы каждого признака
- Выявление необычных феноменов в данных
- Использование обнаруженных правил для прогнозирования
- Выражение прогноза в виде списка релевантных правил
- Вычисление ошибки прогноза
- Прогноз с учетом стоимости ошибок
В качестве достоинств WizWhy дополнительно отмечают такие:
- На прогнозы системы не влияют субъективные причины
- Пользователям системы не требуется специальных знаний в прикладной статистике
- Более точные и быстрые вычисления, чем у других методов Data Mining
Цель статьи
Провести анализ методики извлечений знаний из реляционных баз данных с помощью алгоритма С4.5, получить дерево решений и продукционные правила.
Постановка задачи исследования
Пусть нам задано множество примеров T, где каждый элемент этого множества описывается m атрибутами. Пусть метка класса принимает следующие значения C1, C2 … Ck.
Наша задача будет заключаться в построении иерархической классификационной модели в виде дерева из множества примеров T. Процесс построения дерева будет происходить сверху вниз. Сначала создается корень дерева, затем потомки корня и т.д.
Рассмотрим подробнее критерий выбора атрибута, по которому должно пойти ветвление. Очевидно, что в нашем распоряжении m (по числу атрибутов) возможных вариантов, из которых мы должны выбрать самый подходящий.
Пусть freq(Cj, S) — количество примеров из некоторого множества S, относящихся к одному и тому же классу Cj.
Выражение на рисунке 1 дает оценку среднего количества информации, необходимого для определения класса примера из множества T. В терминологии теории информации это выражение называется энтропией множества T.
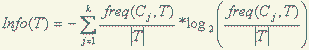
Рисунок 1 — Оценка среднего количества информации
Ту же оценку, но только уже после разбиения множества T по X, дает следующее выражение.
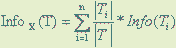
Рисунок 2 — Оценка после разбиения множества
Тогда критерием для выбора атрибута будет являться следующая формула.
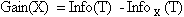
Рисунок 3 — Критерий для выбора атрибута
Критерий Gain считается для всех атрибутов. Выбирается атрибут, максимизирующий данное выражение. Этот атрибут будет являться проверкой в текущем узле дерева, а затем по этому атрибуту производится дальнейшее построение дерева. Т.е. в узле будет проверяться значение по этому атрибуту и дальнейшее движение по дереву будет производиться в зависимости от полученного ответа.
Такие же рассуждения можно применить к полученным подмножествам T1, T2 … Tn и продолжить рекурсивно процесс построения дерева, до тех пор, пока в узле не окажутся примеры из одного класса.
Решение задач и результаты исследований
Для анализа работы алгоритма С4.5 рассмотрим таблицу с данными о клинико–психологических особенностях больных алкоголизмом на начальном этапе формирования ремиссии. Данная таблица содержит 158 строк.
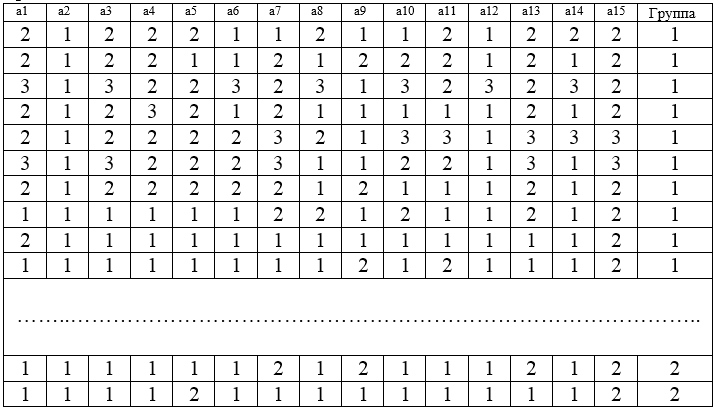
Рисунок 4 — Таблица с данными о клинико–психологических особенностях больных алкоголизмом на начальном этапе формирования ремиссии
Расшифровка атрибутов: a1 — установка на трезвость; a2 — спонтанные ремиссии в прошлом; a3 — влечение к алкоголю; a4 — тревога; a5 — внутреннее напряжение; a6 — снижение настроения; a7 — дисфория; a8 — апатия; a9 — эйфория; a10 — дистимия; a11 — астенические расстройства; a12 — неврозоподобные расстройства; a13 — психопадоподобные расстройства; a14 — психоорганические нарушения; a15 — критика к болезни;
Извлечение знаний следует провести отвечая на вопрос: К какой группе принадлежит пациент?
.
После обработки таблицы алгоритмом С4.5 было получено дерево решений и продукционные правила.
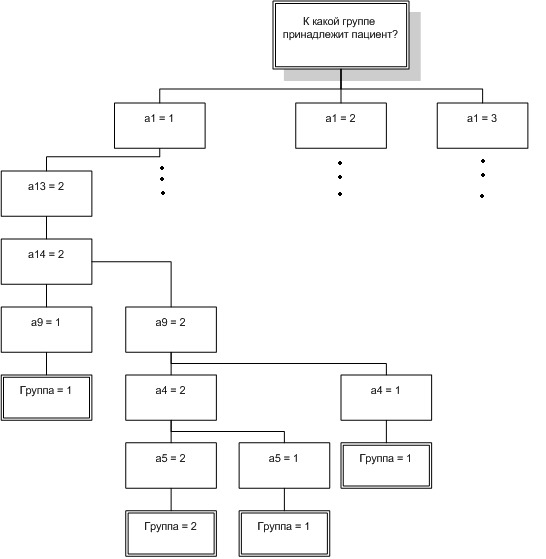
Рисунок 5 — Малая часть построенного дерева решений
Полученные продукционные правила:
- If Установка на трезвость = Продолжительностью до 6 мес., Психопаиоподобные расстройства = Слабо–умеренно–выраженные, Психоорганические нарушения = Слабо–умеренно–выраженная, Эйфория = Нет Then Группа = 1
- If Установка на трезвость = Продолжительностью до 6 мес., Психопаиоподобные расстройства = Слабо–умеренно–выраженные, Психоорганические нарушения = Слабо–умеренно–выраженная, Эйфория = Слабо–умеренно–выраженные, Тревога = Слабо–умеренно–выраженное, Внутреннее напряжение = Слабо–умеренно–выраженное Then Группа = 2
- If Установка на трезвость = Продолжительностью до 6 мес., Психопаиоподобные расстройства = Слабо–умеренно–выраженные, Психоорганические нарушения = Слабо–умеренно–выраженные, Эйфория = Слабо–умеренно–выраженные, Тревога = Слабо–умеренно–выраженное, Внутреннее напряжение = Нет Then Группа = 1
- If Установка на трезвость = Продолжительностью до 6 мес., Психопаиоподобные расстройства = Слабо–умеренно–выраженные, Психоорганические нарушения = Слабо–умеренно–выраженные, Эйфория = Слабо–умеренно–выраженные, Тревога = Нет Then Группа = 1
- If Установка на трезвость = Продолжительностью до 6 мес., Психопаиоподобные расстройства = Слабо–умеренно–выраженные, Психоорганические нарушения = Нет, Эйфория = Нет, Влечение к алкоголю = Слабо–умеренно–выраженные, Дисфория = Нет Then Группа = 2
- ……………………………………
- If Установка на трезвость = Нет, Эйфория = Слабо–умеренно–выраженные, Спонтанные ремиссии в прошлом = Постоянное Then Группа = 2
Выводы
Проведен анализ методики извлечения знаний из реляционной базы данных с помощью алгоритма С4.5. Построено дерево решений. Получены продукционные правила. Результаты показали, количество полученных правил более чем в два раза меньше записей в таблице.
Список использованной литературы
1. В.А. Дюк Data Mining — интеллектуальный анализ данных — СПб: Питер, 2001. — 382с.
2. J. Ross Quinlan. C4.5: Programs for Machine learning. Morgan Kaufmann Publishers, 1993. — 302с.
3. К. Шеннон. Работы по теории информации и кибернетике. М. Иностранная литература, 1963. — 832с.