Автор: Філонова О.О., Вороной С.М..
Источник: Информационные управляющие системы и компьютерный мониторинг / V международная научно-техническая конференция студентов, аспирантов и молодых ученых – Донецк, ДонНТУ – 2013, С. 388–392.
Філонова О.О. Вороной С.М. Алгоритм кластеризации поисковых профилей пользователей для системы персонализации сайта. Выполнен анализ методов кластеризации больших объемов категорийных данных. Выбран эффективный метод и предложен алгоритм кластеризации поисковых профилей пользователей для систем персонализации сайтов, отличающийся небольшой вычислительной сложностью и масштабируемостью.
Ключевые слова: методы кластеризации, категорийные данные, поисковые профили, системы персонализации, масштабируемость алгоритма.
Для крупных Web-порталов существует актуальная задача эффективной навигационной и поисковой поддержки пользователей. Эту задачу можно решать путем персонализации содержимого в соответствии с потребностями и особенностями поведения конечного пользователя. Недостатком существующих средств персонализации является ориентация только на текущие потребности пользователей, что снижает точность сформированных системой персонализации рекомендаций [1].
Выявление ранее не просмотренных конечным пользователем страниц удовлетворяющих его постоянным потребностям может осуществляться с учетом совокупности поисковых запросов, имевших место у того или иного пользователя с похожими профилями.Чтобы выявить такие страницы необходимо провести кластеризацию поисковых профилей и расширить поисковый профиль на основе соответствующего кластера. Универсальные алгоритмы кластеризации не эффективны при решении этой задачи из-за больших объемов и категорийности данных, высоких требований к скорости обработки. Поэтому актуальна задача разработки алгоритма кластеризации, ориентированного на использование в системах персонализации сайтов.
Цель статьи — анализ методов кластеризации больших объемов категорийных данных и разработка алгоритма кластеризации адаптированного к применению в системах персонализации.
Задачу кластеризации в том или ином виде формулировали в таких научных направлениях, как статистика, распознавание образов, оптимизация, машинное обучение. Отсюда многообразие синонимов понятию кластер – класс, таксон, сгущение. На сегодняшний момент число методов разбиения групп объектов на кластеры довольно велико - несколько десятков алгоритмов и еще больше их модификаций. Рассмотрим некоторые из них с точки зрения применения для решения задачи персонификации в Web.
Алгоритм CURE (Clustering Using REpresentatives). Выполняет иерархическую кластеризацию с использованием набора определяющих точек для помещения объекта в кластер. Предназначен для кластеризация очень больших наборов числовых данных. Эффективен для данных низкой размерности, работает только на числовых данных.
Достоинством являются возможность кластеризации на высоком уровне даже при наличии выбросов, выделение кластеров сложной формы и различных размеров, линейно зависимые требования к месту хранения данных и временная сложность для данных высокой размерности. К недостаткам следует отнести необходимость задания пороговых значений и количества кластеров. Алгоритм описан в [2].
Алгоритм MST (Algorithm based on Minimum Spanning Trees). Алгоритм минимального покрывающего дерева строит граф из N-1 рёбер так, чтобы они соединяли все N точек и обладали минимальной суммарной длиной. Такой граф называется кратчайшим незамкнутым путём, минимальным покрывающим деревом или каркасом графа. Выполняет кластеризацию больших наборов произвольных данных, выделяет кластеры произвольной формы, в т.ч. кластеры выпуклой и вогнутой формы, выбирает из нескольких удачных решений самое оптимальное. К недостаткам алгоритма относятся:
Описание алгоритма приведено в [3].
Алгоритм CLOPE. Предназначен для кластеризации огромных наборов категорийных данных. К достоинствам относятся высокие масштабируемость и скорость работы и качество кластеризации, что достигается использованием глобального критерия оптимизации на основе максимизации градиента высоты гистограммы кластера. Отличается простотой программной реализации. Во время работы алгоритм хранит в памяти небольшое количество информации по каждому кластеру и требует минимальное число сканирований набора данных. CLOPE автоматически подбирает количество кластеров, причем это регулируется одним единственным параметром коэффициентом отталкивания. CLOPE предложен в 2002 году группой китайских ученых [4]. При этом он обеспечивает более высокую производительность и лучшее качество кластеризации в сравнении с многими иерархическими алгоритмами.
Алгоритм k-средних (k-means). Алгоритм k-средних строит k кластеров, расположенных на возможно больших расстояниях друг от друга. Основной тип задач, которые решает алгоритм k-средних, - наличие предположений (гипотез) относительно числа кластеров, при этом они должны быть различны настолько, насколько это возможно. Выбор числа k может базироваться на результатах предшествующих исследований, теоретических соображениях или интуиции. Заданное фиксированное число k кластеров наблюдения сопоставляются кластерам так, что средние в кластере (для всех переменных) максимально возможно отличаются друг от друга. Достоинство алгоритма в простоте использования, понятности и прозрачности алгоритма. К недостаткам относятся чувствительность к выбросам, которые могут искажать среднее, медленная работа на больших базах данных; необходимость задания количество кластеров. Описан алгоритм в [5].
Анализ алгоритмов показывает, что из всех рассмотренных только CLOPE удовлетворяет необходимым требованиям.
Рассмотрим алгоритм CLOPE применительно к задаче кластеризации поисковых профилей.
Пусть имеется база поисковых профилей D, состоящая из множества
поисковых профилей {t1,t2,…,tn}. Каждый профиль ti есть набор поисковых
запросов {i1,…,im}. Множество кластеров {C1,…,Ck} есть разбиение множества
{t1,…,tn}, такое, что  и
и 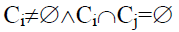 для 1<=i, j<=k.
Каждый элемент Ci называется кластером, n, m, k – количество профилей,
количество запросов в базе профилей и число кластеров соответственно.
для 1<=i, j<=k.
Каждый элемент Ci называется кластером, n, m, k – количество профилей,
количество запросов в базе профилей и число кластеров соответственно.
Каждый кластер C имеет следующие характеристики: D(C) – множество уникальных поисковых запросов; Occ(i,C) – частота вхождений запроса i в кластер C; W(C) = |D(C)|; H(C) = S(C)/W(C).

Гистограммой кластера C называется графическое изображение его расчетных характеристик: по оси OX откладываются объекты кластера в порядке убывания величины Occ(i,C), а сама величина Occ(i,C) – по оси OY (рис. 1).
Очевидно, что чем больше значение H, тем более "похожи" два профиля.
Поэтому алгоритм должен выбирать такие разбиения, которые максимизируют
H. Для более качественного разбиения вместо H(C) можно использовать
градиент 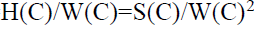 .
.
Задача кластеризации сводится к нахождению такого разбиения множества поисковых профилей на кластеры, при котором глобальная функция стоимости имеет максимальное значение:
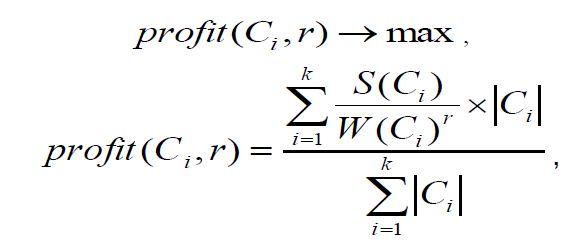
где 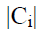 количество объектов в i-том кластере, k – количество кластеров,
r – положительное вещественное число большее 1.
количество объектов в i-том кластере, k – количество кластеров,
r – положительное вещественное число большее 1.

Рисунок 1. Пример гистограммы кластера
С помощью параметра r, названного авторами CLOPE коэффициентом отталкивания (repulsion), регулируется уровень сходства транзакций внутри кластера, и, как следствие, финальное количество кластеров. Этот коэффициент подбирается пользователем. Чем больше r, тем ниже уровень сходства и тем больше кластеров будет сгенерировано.
Рассмотрим реализацию алгоритма. Пусть поисковые профили хранятся в таблице базы данных. Для построения начального разбиения, определяемого функцией Profit(C,r) требуется первый проход по таблице профилей. После этого требуется незначительное (1-3) количество дополнительных сканирований таблицы для повышения качества кластеризации и оптимизации функции стоимости. Если в текущем проходе по таблице, изменений не произошло, то алгоритм прекращает свою работу.
При построении начального разбиения из таблицы читается очередной профиль и создается новый кластер (отдельная таблица) или помещается в уже существующий кластер, который дает максимум Profit(C,r).
На итерационном этапе просматривается таблица профилей и для
каждого профиля решается задача определения кластера, если новый кластер 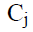 максимизирует Profit(C,r), то профиль переносится в этот кластер. В начале каждого цикла устанавливается индикатор перемещения moved := false. Если в цикле происходит перемещение профиля индикатор перемещения изменяется moved :=true. Итерации завершаются, если значение moved=false не изменится. После завершения итераций удаляются все пустые кластеры.
максимизирует Profit(C,r), то профиль переносится в этот кластер. В начале каждого цикла устанавливается индикатор перемещения moved := false. Если в цикле происходит перемещение профиля индикатор перемещения изменяется moved :=true. Итерации завершаются, если значение moved=false не изменится. После завершения итераций удаляются все пустые кластеры.
Алгоритм CLOPE является масштабируемым, поскольку способен работать в ограниченном объеме оперативной памяти компьютера. Во время работы в оперативной памяти хранится только текущая транзакция и небольшое количество информации по каждому кластеру, которая состоит из: количества транзакций N, числа уникальных объектов (или ширины кластера) W, простой хэш-таблицы для расчета Occ(i,C) и значения S площади кластера.
В результате кластеризации поисковый профиль конечного пользователя i окажется в определенном кластере  .
.
Для предъявления пользователю не просмотренных страниц, соответствующих постоянной информационной потребности, производится расширение его поискового профиля. Для этого поисковые запросы, входящие в состав кластера C*, ранжируются по частоте их вхождения в кластер. В расширенный поисковый профиль выбирается некоторое количество lm поисковых запросов с наибольшей частотой вхождения.
Выполнен анализ методов кластеризации больших объемов данных и выбран метод подходящий для решения задачи кластеризации поисковых профилей. Разработан масштабируемый алгоритм, ориентированный на применение в системах персонализации для Web порталов. В результате кластеризации устанавливаются близкие поисковые профили пользователей и на основе этого выявляются ранее не просмотренные пользователем страницы соответствующие его постоянным информационным потребностям.