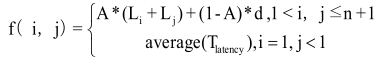Аннотация
Для SaaS-приложений (software as a service – программное обеспечение как сервис), которые распределяют таблицы в хранилище, один из самых главных вопросов – как эффективно управлять многопользовательскими облачными данными. В SaaS все данные каждого пользователя, в том числе его бизнес-данные и метаданные, помещаются в отдельный раздел, где СУБД может гарантировать атомарность, согласованность, изолированность и надежность. К сожалению, размещение разделов и их копий на случайные узлы, легко поддается влиянию нагрузки узлов. Более того, этот способ может увеличить время доступа к данным и затраты на обновление копий. Поэтому авторы предлагают стратегию размещения многопользовательских облачных данных и копий, основанную на графе. Авторы также предлагают динамический метод планирования доступа в соответствии с нагрузкой состояния узлов. Авторы используют алгоритм Paxos для дальнейшего обеспечения доступности и последовательности SaaS-приложений. Эксперименты показывают, что предлагаемая стратегия может не только сбалансировать нагрузку на узлы, но также может уменьшить время для обновления копии раздела, снизить стоимость доступа к данным.
Введение
С развитием облачных вычислений, SaaS как новая форма программных сервисов привлекает все больше внимания. Услуги SaaS зависят от программного обеспечения и Интернет. Все пользователи совместно владеют приложением, бизнес-данные хранятся поставщиком услуг в общей базе данных, а клиент думает, что он является единственным пользователем приложения SaaS, который используется другими клиентами одновременно.
С популяризацией сетевых технологий, а также продвижением SaaS-модели, традиционное хранилище метаданных SaaS не может удовлетворить спросу на хранение многопользовательских данных. В условиях массовых облачных данных SaaS-приложения, облачные базы данных назначают несколько узлов данных для своих сервисов, а все пользовательские данные делится случайным образом и размещаются в случайном порядке на узлах данных, но есть проблема. SaaS-приложения принимают общее хранилище, но управление облачными данными не предназначено для приложений SaaS, бесполезно с учетом многопользовательского доступа, а также не способствует управлению разделами и их копиями.
Стратегия размещения многопользовательских данных [9] обеспечивает пользователям данные в своем собственном пространстве во время физического размещения данных, но случайный выбор узлов может повлиять на нагрузку этих узлов, а также может увеличить время для доступа к данным пользователя и затраты на обновление копий. Таким образом, сетевые приложения и режим нагрузки должны учитываться в полной мере. В целях обеспечения высокой степени полезности облачной системы SaaS-приложений, провайдеры должны разумно размещать большие объемы облачных данных, в то же время пользователи могут получить высокий уровень качества обслуживания.
Для того чтобы избежать постоянной потери данных в некоторых узлах, авторы размещают несколько копий на разных физических узлах и регулируют запросы пользователей для доступа к их собственному пространству данных в соответствии с записью о состоянии нагрузки узлов.
Ввиду вышеуказанных проблем, на основе разбиения решения, предложенного в SaaS стратегии размещения многопользовательских данных [9], используют таблицы поиска, которые отображают состояние словаря динамических данных для установления соответствия между пользователем и узлами передачи данных. Одновременно в нее записывается идентификатор узла данных, где хранится копия раздела пользователя, и режим нагрузки каждого узла данных. Пользователь и все физические узлы считаются вершинами, а соединения всех вершин – ребрами.
Расчет веса каждого ребра основан на расстоянии в сети и режима нагрузки, затем применяя алгоритм поиска наименьшего полного подграфа на неориентированном графе, чтобы получить четыре вершины наименьшего полного подграфа, включая вершину, представляющую пользователя. Размещение данных пользователя происходит на этих трех узлах. Это не только может уменьшить нагрузку, вызванную размещением данных, но также может снизить стоимость доступа к данным, а также улучшить общую производительность приложения SaaS. Кроме того, авторы используют алгоритм Paxos для дальнейшей гарантии полезности приложений SaaS.
Статья организована следующим образом. В разделе 2 обсуждается работа по размещению облачных данных. В разделе 3, представлен метод размещения облачных данных в SaaS. В разделе 4 будет представлен метод последовательности копии. В разделе 5 представлен эксперимент авторов, а в завершении сделан вывод об идее этой статьи и предложены варианты работы в будущем.
Выполненная работа
В настоящее время многие ученые в стране и за рубежом, занимаются глубокими исследованиями по размещению данных в облаке. Файловая система HDFS [1] предполагает стратегию [2] по размещению данных. Политика хранения нескольких копий раздела на узле предполагает хранение копий на узле локально и дистанционно, когда пользователь запрашивает чтение данных с узла, можно убедиться, что данные могут быть считаны локально. Если локальный узел является недостаточным вследствие неисправности, то система может выполнить восстановление данных через копию на удаленном узле. Эта стратегия используется, когда размещения более одной копии случайно может привести к ненужным потерям производительности при восстановлении данных. Случайный выбор узлов дистанционно может быть слишком далеко от локального узла, занимая лишнее время при восстановлении данных, в то же время случайный выбор узел данных не может гарантировать баланс хранения данных между несколькими узлами. Из-за отказа узла, потеря производительности при восстановлении данных приведет к снижению производительности всей системы хранения данных [12]. Предлагаемая стратегия размещения данных для хранения берет во внимание емкости узлов данных и повышает производительность.
Карло Курино [3] [4] предложил стратегию разделения для кортежей, работающих вместе. Кортеж является вершиной, а взаимосвязь между вершинами – ассоциированный граф. Авторы пришли к выводу отношения ассоциации между кортежами согласно весу на графе, используя алгоритм деления, чтобы получить информацию о делении кортежей и информацию о делении копий. Метод может улучшить систему в целом, а именно ее производительность, приблизительно на 30%.
Ян-Ян Ву [5] рассматривает управление метаданными как ключевой вопрос, который влияет на производительность кластера сервера. Раздел метаданных между серверами имеет большое влияние на нагрузку всего кластера и поддержание метаданных. Он предложил динамический бинарный метод поиска, чтобы решить проблему раздела метаданных. После теоретического анализа и экспериментов было доказано, что алгоритм может снизить нагрузку между серверами, и эффективно максимизировать операции с метаданными.
Зильберштейн [6] предложил операцию вставки большого объема данных, если текущий узел данных не в состоянии удовлетворить требованию мощности, должны проводиться своевременные миграции данных, создаваться разделы для обеспечения целостности вставки. Эта стратегия состоит из трех фаз, в том числе входной фазы подготовки, этапа планирования и фазы вставки. Перед вставкой нужно осуществить планирование, сравнивать данные по расходам на перемещение, а затем сформулировать стратегию и выполнить пермещение. На этапе ввода, данные могут быть вставляться непосредственно для обеспечения высокой пропускной способности.
Национальный университет Сингапура предложил [7] [8], трехуровневую архитектуру, включающую распределенный слой хранения, копию слоя и слой управления транзакциями. Узлы хранения составляют сбалансированное дерево. Система облачного хранения не очень хорошо поддерживает согласованность обновления данных, и нет хорошей поддержки данных
Все вышеперечисленные стратегии разработаны для применения SaaS без учета характеристик, управление данными пользователя менее удобно, и размещение реплики случайно на случайно выбранный узел влияет на нагрузку узлов и может увеличить стоимость доступа к данным пользователей и обновления копии.
Таким образом, должны быть введены характеристики многопользовательских данных, чтобы обеспечить высокую доступность облачного SaaS-приложения и получить высокий уровень качества обслуживания.
Проектирование стратегии размещения многопользовательских облачных данных
Цель предлагаемого алгоритма – найти оптимальное разделение [9] и стратегию размещения копии, которые не влияют на балансировку нагрузки, и могут снизить стоимость доступа к пользовательским данным и стоимость обновления копии.
Представление работы алгоритма в виде графа
Как показано на рисунке 1, есть пользователь (0 < i < m) и 6 узлов данных. Пользовательi выражен как вершина1 в графе, каждый узел представлен как вершина(j+1) в графе j где j > 1, (1 < j < n). Любые две вершины соединены дугами, поэтому этот граф является полным неориентированным графом. Веса для ребер представляется как ωi,j. Как показано на рисунке 1, вес ωi,j представляет собой вес для дуги между вершиной1 и вершиной2.
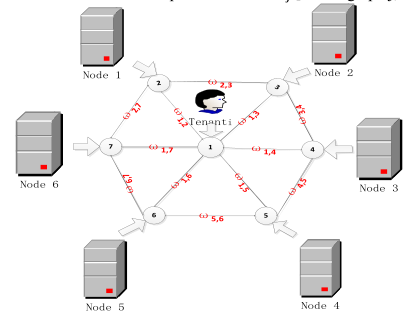
Рисунок 1 – Наглядное представление работы алгоритма в виде графа
Весовая функция
Как упоминалось выше, каждое ребро имеет вес. Эти веса имеют разные значения. Учитывая расстояние между узлом в топологии сети и текущим узлом и количеством разделов, хранящихся в настоящее время на каждом узле, удельная весовая функция определяется следующим образом:
i и j обозначают любые две вершины; f (vi, vj), обозначает весовую функцию дуги (vi, vj). Li и Lj обозначает нагрузку vi и vj которые пропорциональны количеству разделов на узлеi и узлеj. Переменная d является фактором расстояния и пропорциональна расстоянию между узломi и узломj. А ∈ [0, 1] – гравитационный параметр, используется для описания тяжести нагрузки и сети. Tlatency выражает время отклика на запрос пользователя в пространстве данных пользователя в хороших условиях.
Основная идея и описание алгоритма
Согласно представлению работы алогритма в виде графа и весовой функции, упомянутых в последних разделах, идея стратегии размещения многопользовательских облачных данных основанная на графе состоит в том, что любой пользователь tenantj сначала представляется в виде графа, а затем выбирает 4 узла полного подграфа, содержащего вершину пользователя с минимальными весами дуг. Данные пользователя размещается на узле, дуга которого с пользовательским узлом имеет наименьший вес. Оставшиеся два узла используются для копии пользовательских данных.
На основании идеи, описанной выше, на рисунке 2 представлен следующий алгоритм на языке Java в виде псевдо-кода.

Рисунок 2 – Алгоритм на языке Java в виде псевдо-кода
W представляет собой сумму весов всех 4 вершин полного подграфа, алгоритм направлен на выбор четырех вершин с минимальным весом (включая вершину пользователя) для размещения новых данных пользователя и их копии.
Алгоритм основанный на планировании динамического доступа
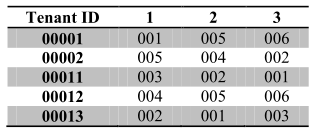
Рисунок 3 – Таблица связей
Эта таблица хранит связи между физическим идентификатором узла и ID пользователя. Таблица динамически изменяется с изменениями нагрузки на физический узел.
Каждый раз, когда пользователь отправляет запрос на доступ к его данным, алгоритм планирования доступа будет выбирать наименее нагруженный узел для ответа на запрос пользователя. Стратегия развертывания в узле метаданных вызывается при поступлении запроса.
Последовательность копирования
Так как расположение данных одного пользователя может быть разным на разных узлах и схема хранения может отличаться, авторы используют улучшенный алгоритм Paxos [12][13] адаптированный под характеристики приложений SaaS. Авторы ввели структуру данных, называемая очередь описания метаданных (MDQ) на каждый узел данных. После того, как узел данных получает запрос на запись пользователя, узел не сразу представить результаты в базе данных, а сначала прикрепить ее к очереди описания метаданных на основе XML файла.
Рисунок 4 – Диаграмма вариантов использования алгоритма Paxos
Как показано на рисунке 4, данные пользователяi соответственно хранятся в узлех, узлеу, узлеz. В какой-то момент, пользователь отправляет запрос на запись, запрос доступа посылается к узлу данных с наименьшей нагрузкой, предположим, что это узелх. После того как узелx получает запрос пользователя, этот запрос транслируется в таблицу связей, включая ID пользователя и добавляется к MDQ, а затем отправляет принятую информацию, включая описание метаданных, узлуy и узлуz. Узелy и узелz получают описание метаданных и добавляют его к своей очереди, а затем отвечают на принятые сообщения для узлах. Если по крайней мере один из узлов (узелy или узелz) ответил на принятое сообщение, узелх обновит описание метаданных в базе данных. Так как передаваемая информация была отправлена на узелy и узелz, как только было получено успешное сообщение по узлуy или по узлуz , узелy и узелz могут проводить операции записи данных. Большая часть времени тратится на задержку принятия сетевой информации, а очередь описания метаданных всегда находится в памяти, так что процесс копирования будет быстрым.
Выводы
На основании алгоритме наименьшего полного неориентированного подграфа, авторы предложили SaaS-стратегию размещения облачных данных на основе разделения графа, расстояние между сетевыми узлами и загрузки данных. Авторы также предложили динамическую стратегию планирования, основываясь на стратегии размещения, а также в зависимости от состояния нагрузки узла. Эксперимент доказал, что предлагаемая стратегия может уменьшить нагрузку и сократить время доступа к данным.
Проведение экспериментов и анализ результатов
Эксперимент авторов реализуется на Java 1.6.0. База данных - Oracle 10g и сервер Apache Tomcat 6. Операционная система Windows XP Professional, процессор Intel Core2 Duo 2,93 ГГц, память 4 Гб, а жесткий диск 500G. В экспериментах, приложение SaaS отображается с новой архитектурой хранения данных.
Авторы выполнили следующее, чтобы закончить эксперимент. Предполагается, что есть приложение SaaS, есть пять узлов данных и 20 пользователей. Авторы используют метод случайного размещения данных для каждого пользователя по пяти физическим узлам, а затем получают среднее время отклика для всех пользователей. Затем авторы используем облачную стратегию размещения SaaS и размещают данные каждого пользователя на пяти физических узлах, а затем сравнить результаты.
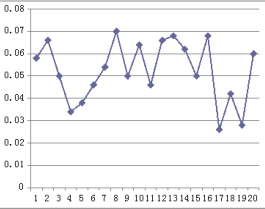
Рисунок 5 – Случайное размещение данных
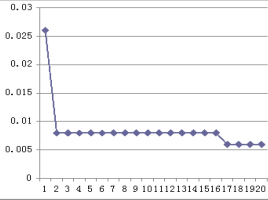
Рисунок 6 – Размещение данных с помощью разработанного алгоритма
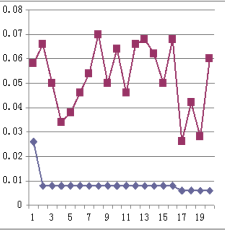
Рисунок 7 – Сравнение результатов работы обоих методов. Красной линией показан результат случанйого размещения данных, синей - результат работы разработанного авторами алгоритма
Из результатов эксперимента видно, что, случайное размещение многопользовательских данных вызовет длительное время отклика, а разработанная стратегия может значительно уменьшить время отклика системы для пользователей, как показано на рисунках 5-7.
Список литературы
1. Borthakur D. The Hadoop distributed file system: architecture and design.
2. Borthakur D. Hadoop [EB/OL]. [2011-06-15]. Электронный ресурс. Режим доступа: http://lucene.apache.org/hadoop
3. Carlo Curino, Evan Jones, Yang Zhang, Eugene Wu, Sam Madden, "Relational Cloud: The Case for a Database Service".Technical Report 2010-14, CSAIL, MIT, 2010.4.11
4. Carlo Curino, Evan Jones, Yang Zhang, Sam Madden." Sehism: a workload-Driven Approach to Database Replication and Partitioning”. In VLDB, Pages 48-57, 2010
5. Jan-Jan Wu, Pangfeng Liu, Yi-Chien Chung, "Metadata Partitioning for Large-Seale Distributed Storage Systems".2010 IEEE 3rd International Conference on Cloud Computing, 212-219.
6. Adam Silberstein, BrianF. Cooper, Utkarsh Srivastava, ErikVee, Ramana Yerneni, Raghu Ramakrishnan," Effieient bulk insertion into a distributed ordered table".Proc.SIGMOD, 2008.
7. Sudipto Das, Shashank Agarwal, Dlvyakant Agrawal, Amr EI Abbadl, " ElasTraS: An Elastic, Sealable, and Self Managing Transactional Database for the Cloud", In Technical Report. 2010-04, CS, UCSB, 2010. Электронный ресурс. Режим доступа: http://cs.ucsb.edu/research/tech_reports/ 1,2,7,8,9,11
8. Hoang Tam Vo, Chun Chen, Beng Chin Qoi,"Towards Elastic Transactional Cloud Storage With Range Query Support",pVLDB3(l):506-517(2010)
9. De Prisco, R., Lampson, B., Lynch, N: Revisiting the paxos algorithm. Theor. Comput. Sci. 243, 35–91 (2000)
10. Lamport, L.: Paxos made simple. ACM SIGACT News (DistributedComputing Column) 32(4), 18–25 (2001)
11. L. Lamport. The Part-Time Parliament. TR 49, Digital SRC,September 1989.
12. L. Lamport. The Part-Time Parliament. ACM Trans. onComputer Systems, 16(2):133–169, May 1998.