Процедуры построения хорошо интерпретируемых классификаций
Автор: Дорофелюк А.А., Чернявский А.Л.
Источник: Научно-теоретический журнал «Искусственный интеллект». – ІПШІ МОН і НАН України «Наука і освіта». – 2006. – № 2. – С. 57–60.
Аннотация
Дорофелюк А.А., Чернявский А.Л. – Процедуры построения хорошо интерпретируемых классификаций. В статье описаны два алгоритма построения хорошо интерпретируемой классификации, рассмотрены их свойства и особенности использования.
Введение
Классификационный подход к анализу данных широко используется для построения «сжатого описания» исходных данных [1], которое в последующем можно использовать, например, для принятия управленческих решений.
Сжатие информации достигается тем, что совокупность объектов разбивается на классы, а каждый класс представляется одним объектом mj (центром класса) и стандартными отклонениями δj, характеризующими разброс объектов этого класса относительно центра. При небольшом числеклассов такое описание оказывается достаточно экономным.
Однако для того, чтобы результат классификации можно было использовать в практических задачах, важно не только то, насколько экономно она представляет исходную информацию, но и то, насколько эта классификация удобна для интерпритации в содержательных терминах. Представление в виде набора центров классов и стандартных отклонений удобно для компьютера, но мало что говорит специалисту-предметнику. До сих пор проблеме интерпретируемости классификаций уделялось недостаточное внимание. Отчасти это связано с тем, что в практических задачах классификация часто использовалась как всомогательное средство для построения регрессивной зависимости (кусочная аппроксимация) [1], когда интерпретируемость классификации не так существенна. В статье описаны два алгоритма построения хорошо интерпретируемой классификации – покоординатная и спрямляющая.
Алгоритмы построения хорошо интерпретируемых классификаций
Для построения хорошо интерпретируемой классификации множества значений каждого исследуемого показателя разбиваются на небольшое число диапазонов. Так, например, при разбиении на 3 диапазона они интерпретируются как диапазоны «высоких», «средних» и «низких» значений показателя. Таким образом, хорошо интерпретируемая классификация задается набором границ диапазонов значений каждого показателя, учавствующего в классификации. Тогда задача сводится к нахождению таких границ диапазонов параметров, которые отражают реальную структуру взаиморасположения объектов в многомерном пространстве признаков.
Как только границы диапазонов найдены, каждый объект получает описание в виде позиционного вектора кодов, имеющего вид (Р1, Р2,..., Рk), где число позиций k равно числу участвующих в классификации показателей. Такой код означает, что этот объект принадлежит классу с номером Р1 для первого показателя, Р2 – второго, и т. д. Классом хорошо интерпретируемой классификации является совокупность объектов с идентичными описаниями. Разработано два алгоритма построения хорошо интерпретируемой классификации.
Покоординатная классификация
Очевидно, самый простой способ построения хорошо интерпретируемой классификации – независимое (от других показателей) разбиение множества значений каждого показателя на заданное число диапазонов. В этом случае хорошо интерпретируемая классификация задается как сочетание одномерных классификаций по каждому показателю. Такую классификацию будем называть покоординатной классификацией.
Основное преимущество такой классификации – возможность использования алгоритмов оптимальной одномерной классификации [2], позволяющих получать глобальный оптимум критерия качества классификации. Другим важным преимуществом покоординатной классификации является ее простота и наглядность. Отметим также, что если количестводиапазонов по каждому показателю задано, то довольно сложная для многомерной классификации проблема выбора числа классов отпадает. Пусть, например, построена трехмерная покоординатная классификация с тремя диапазонами по каждому показателю. Это означает, что пространство объектов оказывается разбитым на 33 = 27 областей, а число классов r будет таким, каким оно фактически получится, т.е. r = 27 – r0, где r0 – число областей, в которых не оказалось ни одного объекта.
Спрямляющая классификация
Недостатком покоординатной классификации является то, что она строится по одномерной проекции многомерного распределения объектов в пространстве показателей, т.е. не учитывает большую часть информации о структуре множества объектов. Второй способ построения хорошо интерпретируемой классификации позволяет устранить этот недостаток.
При этом способе основой для хорошо интерпретируемой классификации является многомерная классификация [1]. Хорошо интерпретируемая классификация строится как своего рода аппроксимация этой многомерной классификации.
Поскольку задача состоит в том, чтобы хорошо интепретируемая классификация наилучшим образом аппроксимировала многомерную классификацию, будем искать такие границы диапазонов, при которых количество отсеченных объектов, т. е. объектов, оказавшихся по другую сторону границы от большинства объектов своего класса, будет минимальным.
Очевидно, что такие границы легко находятся простым перебором. Описания отсеченных объектов, оказавшихся по другую сторону границы диапазона, изменяются. Новое описание может совпасть с описанием одного из имеющихся классов (в этом случае будем говорить, что объект переходит в другой класс). В противном случае отсеченный объект образует новый класс. Построеннную таким образом классификацию будем называть спрямляющей классификацией. Количество возникших при построении спрямляющей классификации новых классов и количество точек в них могут служить характеристикой качества аппроксимации исходной многомерной классификации спрямляющей классификацией.
Заметим, что число классов в спрямляющей классификации, как и в случае покоординатной классификации, в основном определяется фактической структурой точек в многомерном пространстве.
Сравнение спрямляющей и покоординатной классификации
В общем случае спрямляющей и покоординатной классификации даже при одинаковом числе диапазонов разбиения показателей могут давать разные результаты. Покажем это на следующем примере. На рис. 1 овалами условно изображены классы двумерных объектов с равномерным распределением объектов внутри классов. каждый из двух параметров классифицируется на 3 класса – с высокими (В), средними (С) и низкими (Н) значениями показателя.
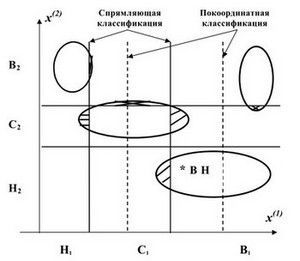
Рисунок 1 – Хорошо интерпретируемые классификации
В этом примере покоординатная классификация по показателю x с разбиением на три диапазона даст разбиение, показанное пунктирными вертикальными линиями, а спрямляющая классификация – разбиение, показанное сплошными вертикальными линиями. Заранее нельзя сказать, какое из этих разбиений предпочтительнее, это зависит от содержательной постановки задачи.
В прикладных работах в основном используется спрямляющая классификация. Описанные алгоритмы использовались при анализе и совершенствовании систем управления региональным здравоохранением и региональными пассажирскими автоперевозками, а также в задаче оценки и прогнозирования социального развития регионов России.
Заключение
В статье предложено два алгоритма построения хорошо интерпретируемой классификации, описаны их преимущества и недостатки, на модельном примере проведен сравнительный анализ этих алгоритмов.
Список использованной литературы
1. Бауман Е.В., Дорофелюк А.А. Классификационный анализ данных // Труды Междунар. конференции по проблемам управления. – Том 1. – М.: СИНТЕГ, 1999. – С. 62–77.
2. Дорофелюк А.А., Бауман Е.В., Корнилов Г.В. Оптимальные методы классификационного анализа в задаче кусочно-линейной аппроксимации // Искусственный интеллект. – 2004. – № 2. – С. 70–74.