Аннотация
Rucha S. Dixit, S.S. Apte. Автоматическое реферирование текста подвергается широкому исследованию и становится более важным с увеличением доступности онлайновой информации. Автоматическое реферирование текста представляет собой сжатие большого оригинального текста в более короткий текст, называемый рефератом. Абстракция и экстракция являются двумя основными методами автоматического реферирования текста. Наш подход основан на методе экстракции. Реферирование методом экстракции включает в себя идентификацию важных функций и извлечение предложений, основанных на их оценке. 30 документов URL новостей используются в качестве входных данных. После предварительной обработки входного документа используются восемь функций расчета коэффициентов для каждого предложения. В данной статье предложен улучшенный метод извлечения предложений для реферата с использованием нечеткой логики.
Ключевые слова - нечеткая логика, основанный на функции, нечеткая средняя точка, вес предложения, реферирование текста
1. Введение
С экспоненциальным ростом количества и сложности источников информации в сети Интернет, стало очень важным предоставить пользователю улучшенные механизмы для нахождения точной информации из доступных документов. Реферирование текста стало важным и своевременным средством призванным помочь в интерпретации большого объема текста, доступного в документах.
Автоматическое реферирование текста представляет собой получение реферата исходного текста, создаваемого машиной, чтобы предоставить наиболее важную информацию оригинального текста в более короткой версии, сохраняя его основное содержание, и помогает пользователю быстро понимать большие объемы информации. Реферирование текста может решить проблему выбора наиболее важных частей текста так же, как проблемы генерирования когерентных сводок. Автоматическое реферирование текста существенно отличается от реферирования текста человеком, так как люди могут получить и связать глубокий смысл и темы текстовых документов, в то время как автоматизацию такого навыка очень трудно реализовать.
Автоматическое реферирование текста в основном может быть выполнено двумя методами: экстракцией и абстракцией. Метод реферирования экстракцией представляет собой выбор предложений или фраз, часто встречающихся в оригинальном тексте, и соединял их в новый более короткий текст, не изменяя исходный текст. Метод реферирования абстракцией использует лингвистические методы, чтобы исследовать и интерпретировать текст. Автоматическое реферирование текста лучше всего работает на хорошо структурированных документах, таких как новости, отчеты, статьи и научные работы. Метод реферирования экстракцией включает идентификацию функций, таких как длина предложения, расположение предложения, частота встречаемости термина, количество слов в заголовке, количество имен собственных, количество числовых данных и тематического слова. Наш подход использует метод слияния функций, чтобы решить, какие функции из доступных фактически полезны. В данной работе предлагается метод реферирования текста, основанный на нечеткой логике, для извлечения важных предложений и формирования реферата.
2. Подходы к реферированию
В ранней классической системе реферирования важные сводки создавались согласно частоте встречаемости слов в тексте. Лун создал первую систему реферирования [1] в 1958. Рат и др. [2] в 1961 предложил эмпирические доказательства для преодоления трудностей, свойственных понятию идеального реферата. Оба исследования использовали одно тематическое свойство - частоту встречаемости термина, таким образом они характеризовали поверхностные уровневые подходы. В начале 1960 г. новые подходы назвали методами появления уровня объекта; первый подход этого вида использовал синтаксический анализ [3]. Функции расположения были использованы в [4], где ключевые фразы, которые используются, имели дело с тремя дополнительными компонентами: прагматические слова; заголовок, слова подзаголовков и структурные показатели.
В данной статье предложен метод, который использует нечеткие правила и нечеткое множество для выбора предложения, основанные на их функциях. Метод нечеткой логики в форме приблизительного рассуждения обеспечивает систему поддержки принятия решений и экспертную систему с мощными рассуждающими возможностями. Разрешение нечеткости в процессах человеческого мышления предполагает, что большая часть логики вне человеческого понимания не является только традиционной двоичной или многозначной логикой, но также и логикой с нечеткими истинами, нечеткими соединительными словами и нечеткими правилами вывода [5]. Нечеткое множество, предложенное Заде [6], является математическим инструментом для того, чтобы иметь дело с неопределенностью, неточностью, неясностью и неоднозначностью. Нечеткая логика для текстового реферирования нуждается в большем количестве исследований. Несколько исследований были сделаны в этой области, Witte и Bergler [7] представили метод, основанный на нечеткой теории к кореферентному разрешению и его применение к текстовому реферированию. Автоматическое определение связи между именными группами чревато неопределенностью. Kiani и Akbarzadeh [8] предложили метод реферирования текста, с использованием комбинации генетического алгоритма (GA) и генетического программирования (GP) для оптимизации наборов правил и функций нечетких систем.
Методы выделения признаков используются, чтобы получить важные предложения в тексте. В методе выделения признаков некоторые функции имеют большую важность, а некоторые имеют меньшую, поэтому у них должен быть баланс в вычислениях, и мы используем нечеткую логику, чтобы решить эту проблему, определяя функцию принадлежности для каждой функции.
3. Эксперименты
3.1. Входные данные и предварительная обработка
Мы использовали новостные статьи URL новостей как входные данные для системы реферирования. Текстовая часть новостной статьи сохранена в текстовом документе, который является входным для системы реферирования. Входной документ имеет формат простого текста. В этой статье предварительная обработка включает четыре основных вида: сегментация предложения, маркировка, удаление стоп слов и стемминг. Сегментация предложения представляет собой обнаружение границ и разделение исходного текста на предложения. Маркировка разделяет входной документ на отдельные слова. Следующее, удаление стоп слов - удаление слов, которые часто появляются в документе, но имеют небольшое значение для идентификации важного контента документа, такие как «a», «an», «the» и т.п. Последний шаг предварительной обработки это стемминг - процесс удаления префиксов и суффиксов каждого слова.
3.2. Функции предложения
После такой предварительной обработки каждое предложение документа представлено вектором функций. Мы используем восемь функций для каждого предложения. Каждой функции присваивается значение между «0» и «1». Существуют следующие восемь функций.
3.2.1. Функция заголовка
Эта функция дает меру подобия между предложением заголовка и любым предложением документа. Это определяется числом соответствий между словами контента в предложении и словами в заголовке. Значение этой функции представляет собой отношение числа соответствий между предложением и предложением заголовка по числу слов в заголовке:

3.2.2. Длина предложения
Мы используем эту функцию, чтобы отфильтровать короткие предложения, такие как демаркационные линии суточного времени и имена авторов. Короткие предложения не будут входить в реферат. Сначала длина предложения вычисляется подсчетом количества слов в нем, и затем нормализуется. Значение функции представлено отношением длины предложения к длине самого длинного предложения в документе:
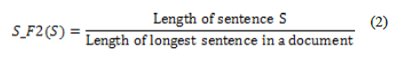
3.2.3. Вес термина
Эта функция использует понятие частоты термина [10], который часто использовался, чтобы вычислить важность предложения. Здесь под частотой термина мы имеем в виду частоту появление термина в пределах документа. Мы подсчитываем частоту для всех терминов в предложении. Значение этой функции представлено, как отношением сумм частот всех терминов в предложении к максимальному значению такой суммы среди всех предложений документа. Вес i-того предложения вычисляется по следующие формуле:

где k – количество слов в предложении. Значение этой функции вычисляется следующим образом:

3.2.4. Позиция предложения
Позиция предложения в тексте определяет его важность. Эта функция может включать несколько элементов таких, как позиция предложения в документе, разделе, абзаце и т.д. Для вычисления значения этой функции мы рассматриваем первые 5 предложений в документе.
Значение функции вычисляется следующим образом:
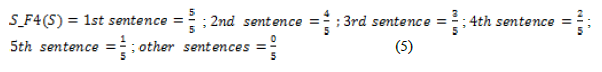
3.2.5. Подобие предложений
Эта функция является подобием между предложениями. Для каждого предложения S, подобие между S и любым предложением вычисляется методом маркерного соответствия. Формируется матрица [N] [N], где N – общее количество предложения в документе. Диагональные элементы матрицы нули, поскольку предложение не должно сравниваться само с собой. Подобие каждой пары предложений (6) вычисляется следующим образом:
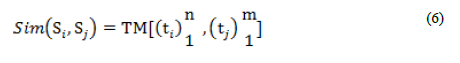
где ТМ – обозначает маркерный метод соответствия. Значение данной функции – это отношением суммы подобий предложения S с любым предложением к максимуму суммы и вычисляется (7) следующим образом:
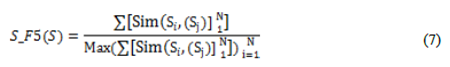
3.2.6. Имя собственное
Предложение, которое содержит больше имен собственных, является важным и оно с большей вероятностью должно быть включено в реферат документа. Значение этой функции вычисляется как отношение числа имен собственных, которые встречаются в предложении к длине предложения:
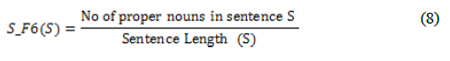
3.2.7. Тематическое слово
Тематическое слово подразумевает слово, которое часто встречается в документе и, вероятно, связано с темой. Тематическое слово – это слово с максимальной возможной относительностью. Мы вычислили частоту встречаемости каждого слова в документе и использовали 5 самых встречаемых слов контента для рассмотрения их, как тематических. Значение этой функции вычисляется как отношение числа тематических слов в предложении к максимальному количеству тематических слов в предложении:
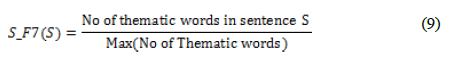
3.2.8. Числовые данные
Эта функция представляет собой количество числовых данных в предложении. Предложение, которое содержит числовые данные, является важным и вероятно должно быть включено в реферат. Значение этой функции вычисляется как отношение количества числовых данных, которые встречаются в предложении к длине предложения:

3.3 Реферирование текста, основанное на нечеткой логике
Целью реферирования текста, основанного на экстракции, является выбор предложений. Наша система состоит из следующих основных шагов:
а) считывание исходного документа в систему;
б) на шаге предварительной обработки система извлекает отдельные предложения из оригинального документа, а затем разделяет входной документ на отдельные слова. Далее удаляются стоп слова. Последним шагом предварительной обработки является стемминг;
в) каждое предложение связывается с вектором восьми функций, которые описаны в разделе 3.2, значения которых получаются из контента предложения;
г) значение для каждого предложения, полученное из его функций, основанное на методе нечеткой логики;
д) множество предложений с высокой оценкой, извлекаются в реферат документа в зависимости от степени сжатия.
Чтобы извлечь важные предложения, мы использовали метод нечеткой логики. Нечеткая логика обычно включает нечеткий выбор правила и функции принадлежности. Выбор нечетких правил и функций принадлежности непосредственно влияет на производительность системы нечеткой логики.
Система нечеткой логики состоит из четырех компонентов: фазификация, механизм логического вывода, дефазификация и нечеткая база знаний. На этапе фазификации четкие входные данные преобразуются в лингвистические значения при использовании функции принадлежности. После фазификации механизм логического вывода обращается к базе правил, содержащей нечеткие «если-то» правила для получения лингвистических значений. На последнем шаге выходные лингвистические переменные после механизма логического вывода преобразуются в заключительные четкие значения дефазификацией, используя функции принадлежности для того, чтобы получить окончательную оценку. На рисунке 1 показано реферирование текста, основанное на архитектуре системы нечеткой логики.
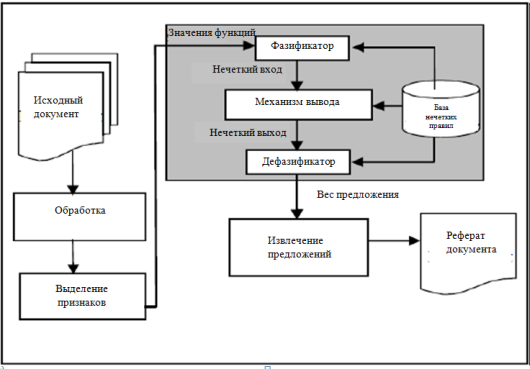
Рисунок 1 - Реферирование текста, основанное на системе нечеткой логики
Для реализации реферирования текста на основе нечеткой логики, во-первых, восемь функции, извлеченных в предыдущем разделе, используются в качестве входа на этапе фазификации. Мы использовали треугольные функции принадлежности и нечеткую логику, чтобы получить реферат документа. Треугольная функция принадлежности на входе для каждой функции разделена на пять нечетких множеств, которые составлены из незначительных значений (низкий (L) и очень низкий (VL), средние значения (средний (M)) и важные значения (высокий (H) и очень высокий (VH)). Обобщенная треугольная функция принадлежности зависит от трех параметров a, b, и c, где, «a» и «c» являются левым и правым нижними углами треугольника, а «b», - вершина треугольника, как показано рисунке 2. Мы использовали нечеткий центроидный метод, чтобы вычислить значение для каждого предложения документа. Значение от нуля до единицы получается для каждого предложения на выходе, в зависимости от значения функций и базы знаний. Полученное значение на выходе определяет степень важности предложения в заключительной сводке. Упрощенное нечеткое центроидное вычисление (11) производится по следующей формуле:
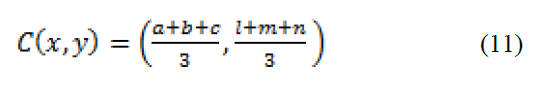
где a, b, c являются стандартными значениями низких, средних и высоких соответственно, и l, m, n является вычисленными значениями низких, средних и высоких соответственно.
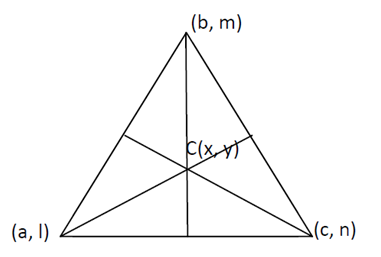
Рисунок 2 - Нечеткое центроидное вычисление
В механизме логического вывода самой важной частью является определение нечетких «если-то» правил. Важное предложения извлекаются по правилам согласно нашим критериям функций.
Аналогично последним шагом в системе нечеткой логики является дефазификация. Мы использовали выходную функцию принадлежности, которая разделена на три функции принадлежности: вывод {Незначительный, Средний, Важный}, чтобы преобразовать нечеткие следствия механизма логического вывода в четкий вывод для окончательной оценки каждого предложения.
3.4. Извлечение предложений
В методе нечеткой логики, описанном выше, каждое предложение документа представлено весом предложения. Затем все предложения документа оцениваются в порядке по убыванию, основанном на их весе. Ряд предложений с самым высоким весом, извлекаются как реферат документа, основанный на 20%-ом уровне сжатия. В конце, предложения реферата располааются в первоначальном порядке.
4. Оценка и результаты
Оценка рефератов сделана на основе двух факторов, упомянутых на рисунке 5. Мы использовали 30 документов URL-новостей как входные данные для системы. Здесь сгенерированные человеком рефераты используются для оценки наших результатов. Человек сгенерировал рефераты по золотому стандарту, так как люди могут получить и связать глубокие значения текста в отличие от машин. Мы получили сгенерированные рефераты человека для наших входных документов от пяти различных экспертов. Здесь мы вызываем рефераты Fuzzy summarizer, Copernic summarizer и MS Word summarizer, как рефераты кандидата, и человек генерировал сводки как ссылочные сводки.
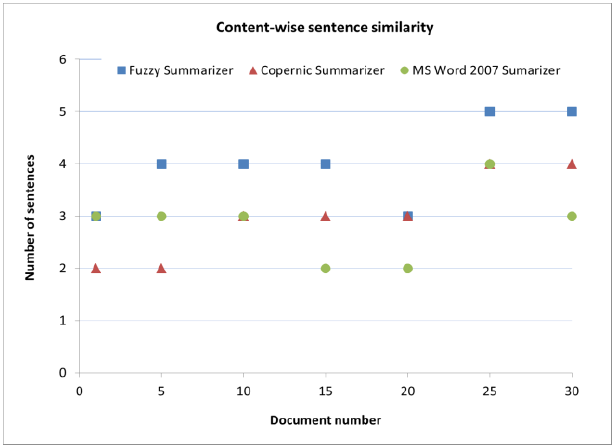
Рисунок 3 - Смысловое cоотношение рефератов
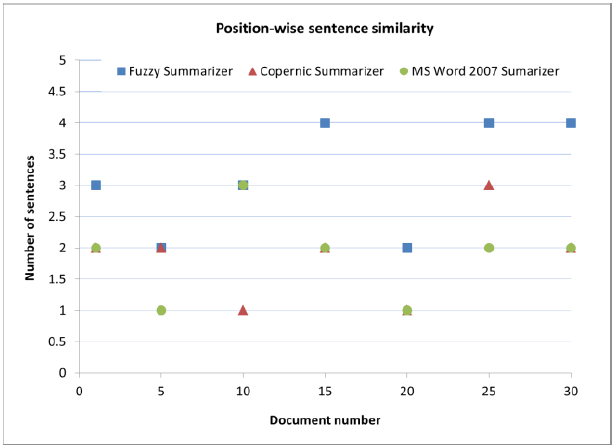
Рисунок 4 - Соотношение положения предложений рефератов
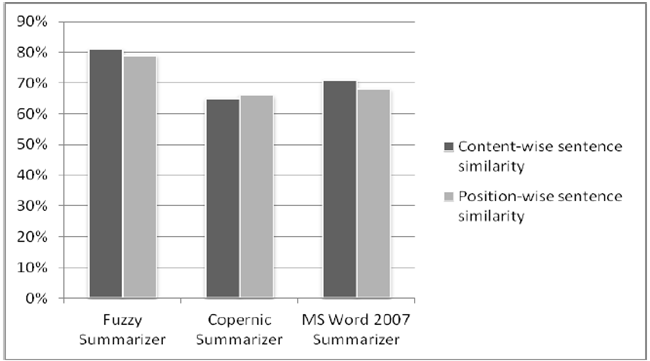
Рисунок 5 - Среднее подобие между рефератами
Первым фактором в оценке, как упомянуто на рисунке 3, является число подобных предложений рефератов. Для этого факторного нечеткого аннотатора показано самое высокое среднее 81 %-ое подобие реферату, как показано на рисунке 5. Вторым фактором в оценке как упомянуто на рисунке 4 является подобие между позициями предложений в рефератах. Поскольку у этого факторного нечеткого аннотатора есть среднее 79 %-ое подобие реферату, которое является самым высоким среди других, как показано на рисунке 5. Результаты ясно показывают, что нечеткий аннотатор работает лучше чем Copernic summarizer и MS Word 2007 summarizer.
5. Заключение и будущая работа
В этой статье мы реализуем автоматическое реферирование текста, которое базируется на извлечении важных предложений, используя метод нечеткой логики. Система протестирована на 30 документах новостей и по сравнению с Copernic summarizer и MS Word 2007 summarizer. Результаты показывают, что использование нечеткой логики в текстовом реферировании улучшает качество реферата. Мы применяли наш метод для реферирования одного документа, которое могло быть расширено для реферирования нескольких документов. Как исходные данные мы использовали 30 документов новостей. Новости имеют такие категории, как спортивные состязания, политика, погода и т.д. Необходимо включить автоматический выбор нечетких правил вывода, основанных на типе входных новостей, чтобы генерировать рефераты лучшего качества. Наш метод может быть расширен для автоматического выбора нечетких правил вывода.
Ссылки:
- H.P. Luhn, “The Automatic Creation of Literature Abstracts” IBM Journal of Research and Development, vol. 2, pp. 159–165. 1958.
- G.J. Rath, A. Resnick, and T.R. Savage, “The formation of abstracts by the selection of sentences” American Documentation, vol. 12, pp. 139–143. 1961.
- Inderjeet Mani and Mark T. Maybury, editors, Advances in automatictext summarization (MIT Press. 1999).
- H.P. Edmundson., “New methods in automatic extracting” Journal of the Association for Computing Machinery 16 (2). pp. 264–285. 1969.
- A. D. Kulkarni and D.C. Cavanaugh, “Fuzzy Neural Network Models for Classification” Applied Intelligence 12, pp. 207–215. 2000.
- L. Zadeh, “Fuzzy sets. Information Control” vol. 8, pp. 338–353. 1965.
- R. Witte and S. Bergler, “Fuzzy coreference resolution for summarization” In Proceedings of 2003 International Symposium on Reference Resolution and Its Applications to Question Answering and Summarization (ARQAS). Venice, Italy: Universita Ca'Foscari. pp. 43–50. 2003.
- Arman Kiani and M.R. Akbarzadeh, “Automatic Text Summarization Using: Hybrid Fuzzy GA-GP” In Proceedings of 2006 IEEE International Conference on Fuzzy Systems, Sheraton Vancouver Wall Center Hotel, Vancouver, BC, Canada. pp. 977–983. 2006.
- J. Kupiec, J. Pedersen, and F. Chen, “A Trainable Document Summarizer” In Proceedings of the Eighteenth Annual International ACM Conference on Research and Development in Information Retrieval (SIGIR), Seattle, WA, pp. 68–73. 1995.
- G. Salton, C. Buckley, “Term-weighting approaches in automatic text retrieval” Information Processing and Management 24, 1988. 513-523. Reprinted in: Sparck-Jones, K.; Willet, P. (eds.) Readings in I.Retrieval. Morgan Kaufmann. pp. 323–328. 1997.
