Аннотация
X. Wu, V. Kumar, J. Ross Quinlan, J. Ghosh, Q. Yang, H. Motoda Топ 10 алгоритмом интеллектуального анализа данных. CART В данной статье представлено описание и результаты алгоритма, а также анализ текущего и дальнейшего исследования по алгоритму.
CART
Монография 1984 "CART: классификация и деревья регрессии ," в соавторстве Лео Бреймана, Джерома Фридмана, Ричарда Олсена и Чарльза Стоуна, представляет собой важный этап в эволюции искусственного интеллекта, машинного обучения, непараметрической статистики и исследовании данных.Работа важна для полноты ее изучения деревьев решений, технических нововведений, своим опытным обсуждения древоструктурного анализа данных, и своим авторитетным подходом к большому количество примером деревьев. В то время как CART цитаты можно найти практически в любой области, намного более появляются в таких областях, как электротехника, биологии, медицинских исследованиях и финансовым вопросам, чем, например, в маркетинговых исследованиях или социологии, где другие методы дерева более популярным. Этот раздел предназначен для выделения ключевых тем обработанные в CART монографии с тем чтобы стимулировать читателей, чтобы вернуться к первоисточнику более подробно.
Обзор
Дерево решений CART представляет собой двоично рекурсивную процедуру разделения, способную обрабатывать непрерывные и номинальные атрибуты и в качестве мишеней и предсказателей. Данные обрабатываются в сыром виде; хранение не требуется и не рекомендуется. Деревья выращивают до максимального размера без использования правила остановки и затем обрезаются (по существу разделена за разделением) в корневом каталоге с помощью затратной и сложной обрезки. Следующее разделение сокращено в один воздействуя как минимум на общую производительность дерева на обучающих данных (более чем одно разбиение может быть удалено). Процедура производит деревья, которые не зависят ни при каких целях, сохраняя преобразование атрибутов предикторов. Механизм CART предназначен для производства не одного, а последовательности вложенных обрезанных деревьев, все из которых являются кандидатами на оптимальное дерево. "Правильного размера" или "честное" дерево определены путем оценки интеллектуального производительность каждого дерева в последовательности обрезки. CART предлагает не внутренние меры производительности для выбора дерева, основанные на данных обучения, как некоторые меры признания подозреваемого. Вместо этого, производительность дерево всегда измеряется на независимых тестовых данных (или с помощью перекрестной проверки) и выбор дерева происходит только после испытаний, основанных на данных оценки. Если не существует тестов и перекрёстная проверка данных не была выполнена, CART останется агностиком в отношении какое дерево в последовательности лучшее. Это находится в резком контрасте с такими методами, как C4.5, которые генерируют предпочтительные модели на основе учебных мероприятий данных. Механизм CART включает автоматический (опционально) класс балансировки, автоматическую обработку пропавшего значение, и разрешает учесть экономически чувствительное обучение, динамические особенности конструкции и оценки дерева вероятностей. Окончательные отчеты включают новый атрибут важность рейтинга. Авторы CART также сделали прорыв, показав, как перекрёстные проверки могут быть использованы для оценки производительности для каждого дерева в выборке, учитывая, что деревья в разные ветви могут не совпадать по количеству конечных узлов.
Правила разбиения
Правила CART разбиения всегда сформулированы в виде
Экземпляр уходит влево, если УСЛОВИЕ, и идет прямо в противном случае
где условие выражается как "атрибут Xi <= C" для непрерывных атрибутов. Для номинальных атрибутов условие выражается как членство в явном списке значений. Авторы утверждают, что CART двоичные разбиения должны быть предпочтительным, поскольку (1) они фрагментируют данные медленнее, чем многопутевые разбиения, и (2) повторные разбиения на одном атрибуте разрешено и, если выбран, в конечном счете, будет сгенерировано столько разделов для атрибута, сколько требуется. Любая потеря простоты в чтении дерева, как ожидается, будут компенсирована за счет улучшения производительности. Третьей неявной причиной является то, что большой пример теории, разработанный авторами, был ограничен в двоичной разметке. Монография CART фокусирует основную часть обсуждения на правило Джини, которое похоже на более известную энтропию или критерий усиления информации. Для бинарных (0/1) целевое "измерения примеси Джини" из узла t равно
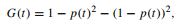
где р (t) это (возможно взвешенная) относительная частота 1 класса в узле, и улучшение (усиление), сгенерированная разбиением родительского узла P в левый и правый дочерний L и R является
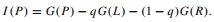
Здесь q это (возможно, взвешенная) доля случаев движения налево. Авторы CART предпочитают критерий Джини информационному усилению, потому что Джини может быть легко расширен, чтобы включить симметризованные расходы (см ниже) и вычисляется быстрее, чем информационное усиление. (Поздние версии CART добавили информационное усиление в качестве дополнительного правило разбиения.) Они представляют модифицированное правила раздваивания, которое основано на прямом сравнении разбиения целевого атрибута на два дочерних узла
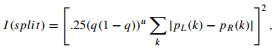
где k индексы целевых классов, PL () и PR () - распределения вероятностей цели в левой и правой дочерних узлах соответственно, и степенной терм u представляет собой погрешность разбиения генерирующихся дочерних узлов не равного размера. (Это сплиттер модифицированная версия Мессенджера и Манделл [5].) Они также внедрили вариант раздвоения сплит критерия, который рассматривает классы по упорядоченным целям; очередное раздвоение пытается обеспечить целевые классы, представленные слева от разбиения, ранжируются ниже тех, которые представлены справа. Основываясь на нашем опыте, критерий раздвоения по производительности, на целях мульти-класса, так же хорош, как и для сложных задач прогнозирования (например, работа с шумом) двоичных объектов. Для регрессии (непрерывные цели), CART предлагает на выбор метод наименьших квадратов (LS) и наименее абсолютное отклонение (LAD) критериев в качестве основы для измерения улучшения разбиения.
Наблюдаемые вероятности и баланс классов
В своей классификации по умолчанию CART всегда рассчитывает частоты класса в любом узле по отношению к частотам класса в корне. Это эквивалентно автоматически перевзвешиванию данных, чтобы сбалансировать классы, что гарантирует, что дерево выбирается в качестве оптимального сбалансированного и минимизирует ошибку класса. Под перевзвешиванием подразумевается расчете всех вероятностей и улучшений и запросов без вмешательства пользователя; отчет считается в каждом узле, таким образом, отражаются невзвешенные данные. Для бинарных (0/1) цель любой узел, классифицируется как класс 1, если, и только если,
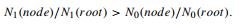
Этот режим по умолчанию, называется «равенство наблюдений» в монографии. Это позволило пользователям CART легко работать с любыми несимметричными данных, не требуя никаких специальных мер относительно балансирования класса или введения построенных вручную весов. Для эффективной работы с несимметричными данных достаточно, чтобы запустить CART, используя свои параметры по умолчанию. Неявное перевзвешивание может быть выключено с помощью опции "наблюдаемые данные", и разработчик может также указать произвольный набор априорных данных чтобы отразить расходы или потенциальные различия между обучающимися данными и будущим целевым распределением классов.
Правила остановки, обрезки, последовательности дерева, и выбор дерева
Ранее работы над деревьями решений не позволяли выполнять обрезку. Вместо этого, деревья увеличивали, пока они не столкнулись с некоторым состоянием остановки и в результате дерево считается окончательным. В монографии CART авторы утверждают, что ни одно правило, предназначено для остановки роста деревьев, не может гарантировать, то, что не будет упущена важная структура данных (например, рассмотреть двумерную задачу XOR). Поэтому они избрали рост деревьев, без остановок. В результате чрезмерно большое дерево обеспечивает сырой материал, из которого извлекается окончательная оптимальная модель. Механизм обрезки производится строго на данных обучения и начинается со стоимости меры сложности определенной в
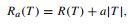
где R (T) это стоимость обучения образца дерева, |Т| это число конечных узлов в дереве и является погрешностью на каждом узле. Если а = 0, то минимальная стоимость сложности дерева явно крупнейшая вероятная. Если допускается постепенно увеличивать а, минимальная стоимость сложности дерева станет меньше с разбиением в нижней части дерева, которое снижает R(T). Параметр а постепенно увеличивается от 0 до величины, достаточной, чтобы сократить расстояние всех разбиений. BFOS доказывает, что любое дерево размера Q извлечено таким образом, что будет проявлять затрат R (Q), что является минимальным в классе всех деревьев с терминальными узлами Q. Оптимальное дерево определяется как дерево в обрезанной последовательности, которое достигает минимальной стоимости на тестовых данных. Потому что измерение стоимости неправильной классификации является ключом к определению ошибки выборки, неопределенность всегда остается, в отношении которой дерево в последовательности обрезки является оптимальным. BFOS рекомендовано выбрать "1 SE" дерево, что является самым маленьким с оценочной стоимостью в 1 стандартной ошибки минимальной стоимости (или "0 SE") дерева.
Выводы
Интеллектуальный анализ данных является широкой областью, которая объединяет методы из нескольких областей, включая машинное обучение, статистику, распознавание образов, искусственный интеллект, и системы баз данных, для анализа больших объемов данных.
Список использованной литературы
- Chen JR (2007) Making clustering in delay-vector space meaningful. Knowl Inf Syst 11(3):369–385
- Gondek D, Hofmann T (2007) Non-redundant data clustering. Knowl Inf Syst 12(1):1–24
- Hu T, Sung SY (2006) Finding centroid clusterings with entropy-based criteria. Knowl Inf Syst 10(4):505–514
- Kobayashi M, Aono M (2006) Exploring overlapping clusters using dynamic re-scaling and sampling. Knowl Inf Syst 10(3):295–313
- Messenger RC, Mandell ML (1972) A model search technique for predictive nominal scale multivariate analysis. J Am Stat Assoc 67:768–772
- Inokuchi A, Washio T, Motoda H (2005) General framework for mining frequent subgraphs from labeled graphs. Fundament Inform 66(1-2):53–82
- Jain AK, Dubes RC (1988) Algorithms for clustering data. Prentice-Hall, Englewood Cliffs
- Jin R, Goswami A, Agrawal G (2006) Fast and exact out-of-core and distributed k-means clustering. Knowl Inf Syst 10(1):17–40