Прогнозирование фондового рынка используя алгоритма машинного обучения
Автор: Shunrong Shen, Haomiao Jiang, Tongda Zhang
Перевод: Google translate и Пожидаев Святослав Игоревич
Источник: Shunrong Shen. Stock Market Forecasting Using Machine Learning Algorithms / Haomiao Jiang, Tongda Zhang // CS 229 Machine Learning Final Projects, Autumn 2012. — Stanford, 2012. Источник оригинала
Аннотация
Прогнозирование фондового рынка давно привлекательным тема для исследователей из различных областей. В частности, многочисленные исследования были проведены, чтобы предсказать движение фондового рынка, используя алгоритмы машинного обучения, такие как поддержка векторных машины (SVM) и обучения с подкреплением. В этом проекте, мы предлагаем новый алгоритм предсказания, который использует временную корреляцию между мировых фондовых рынках и различных финансовых продуктов, чтобы предсказать на следующий день акции тенденцию с помощью SVM. Численные результаты указывают на точность предсказания 74,4% в NASDAQ, 76% в S & P500 и 77,6% в DJIA.Тот же алгоритм применяется также с различными алгоритмами регрессии проследить реальное приращение на рынках. Наконец, просто торговая модель укреплены, чтобы изучить эффективность предложенного алгоритма предсказания в отношении других показателей.
Введение
Прогнозирование фондового тенденции уже давно интригует тема и широко изучается исследователями из разных областей. Машинное обучение, хорошо создана алгоритм в широком диапазоне применений, была тщательно изучена для ее потенциалов в прогнозировании финансовых рынков. Популярные алгоритмы, в том числе опорных векторов (SVM) и обучения с подкреплением, были зарегистрированы, чтобы быть достаточно эффективным в отслеживании фондовый рынок и помочь максимизации прибыли опционной покупки в то время как держать риск низкий [1-2]. Тем не менее, во многих из этих литератур, особенности выбран для входов в машине алгоритмы обучения, в основном, происходит от данных в рамках одного рынка под беспокойства. Такая изоляция пропускает важную информацию, которую несет другими субъектами и сделать предсказание привести более уязвимыми для локальных возмущений. Усилия были сделать, чтобы разрушить границы путем включения внешней информации через свежие финансовые новости или личные интернет должностей, таких как Twitter. Эти подходы, известные как анализ настроений, отвечает на отношения несколько ключевых фигур или успешных аналитиков на рынках интерполировать умы общих инвесторов. Несмотря на успех в некоторых случаях, анализ настроений может произойти сбой при некоторых людей пристрастны, или положительные отзывы следовать мимо хорошей производительности, а не предполагая, перспективные рынки сбыта на будущее.
В этом проекте, мы предлагаем использование глобальных данных о запасах в ассоциированной с данными других финансовых продуктов, как вход в особенности алгоритмов машинного обучения, такие как SVM. В частности, мы заинтересованы в корреляции между ценами закрытия рынков, которые останавливаются торговлю, прямо перед или в начале американских рынках. Как не связи между экономикой во всем мире затянуты глобализации внешние возмущения в финансовых рынках больше не внутренний. Это для нашей веры, что данные зарубежных акций и других финансовых рынках, особенно тех, кто имеет сильное временной корреляции с предстоящим США торговый день, должны быть полезными для машинного обучения предсказателя, основанной, и наша спекуляция проверяется численных результатов.
Остальная часть отчета организована следующим образом. Раздел II представляет наш алгоритм подробно, в том числе фундаментального принципа нашего алгоритма, сбор данных и выбор функций. Численные результаты приведены в разделе III с последующим анализом и обсуждения. В разделе IV, мы создали простую торговую модель, чтобы продемонстрировать возможности предлагаемого алгоритма в увеличении прибыли в NASDAQ. Раздел V суммирует весь отчет.
Алгоритмы
Основные принципы. Глобализация углубляет взаимодействие между финансовыми рынками во всем мире. Ударная волна США финансовый кризис ударил экономику почти в каждой стране и долговой кризис в Греции возникла сбил все основные фондовые индексы. В настоящее время, нет финансового рынка не выделяют. Экономические данные, политическая возмущение и любые другие вопросы зарубежные может привести резкое колебание на внутренних рынках. Таким образом, в этом проекте, мы предлагаем использовать основные мировые фондовые индексы в качестве входных имеет для нашего машинного обучения предсказателя, основанной. В частности, зарубежные рынки, что закрывает перед или в начале торгов на рынке США должны предоставить ценную информацию о тенденции вступления США торговый день, а их движения уже зарегистрированы, для возможного настроения рынка на последнем экономическом новости или ответ на прогресс в основные мировые дела.
Рисунок 1 – Мировые финансовые рынки
В дополнение к фондовых рынках, цены на сырьевые товары и в иностранной валюте данных также перечислены в качестве потенциальных возможностей, как различные финансовые рынки взаимосвязаны. Например, замедление экономики США, безусловно, вызовет падение американского фондового рынка. Но в то же время, США и японская иена вырастет по отношению к аналогам как люди ищут убежища активов. Такое взаимодействие предполагает основную связь между этими финансовыми продуктами и возможностью использования одного или некоторых из них, чтобы предсказать ход из других.
Cбор данных. Набор данных, используемый в этом проекте собраны из [3]. Он содержит 16 источников, перечисленных в таблице I и охватывает ежедневные цены от 04-Jan-2000 25-Октябрь -2012: Поскольку рынки закрыты на праздники, которые варьируются от страны к стране, мы используем NASDAQ в качестве основы для выравнивания и данных недостающие данные в других источниках данных заменяется линейной интерполяции.
Таблица 1 - Источник данных

Выбор функций. В этом проекте, мы ориентируемся на прогнозировании тенденции фондового рынка (увеличения или уменьшения). Таким образом, изменение признака с течением времени более важен, чем абсолютное значение из каждой функции. Мы определяем XI (т), где я ? {1,2, ..., 16}, чтобы быть особенность, которую я в момент Т. Функция матрица задается

где

Новая функция, которая является разница между двух ежедневных цен можно рассчитать по

Из-за разницы в рыночной стоимости и основе каждого рынка, дифференциальные значения, вычисленные выше, может варьировать в широких пределах. Чтобы сделать их сопоставимыми, особенности нормированы следующим образом:

и нормализации может быть реализован в виде:

Как уже говорилось выше, производительность фондового рынка предсказателя в значительной степени зависит от соотношения между данными, используемыми для обучения и текущего входа на предсказания. Интуитивно, если тенденция котировок акций всегда расширение вчера, точность прогнозирования должны быть достаточно высоким. Чтобы выбрать входные функции с высокой временной корреляции, мы рассчитали автокорреляции и взаимной корреляции различных направлений рынка (увеличение или уменьшение). Результаты показано на рисунке 2 использования NASDAQ в качестве базового рынка.
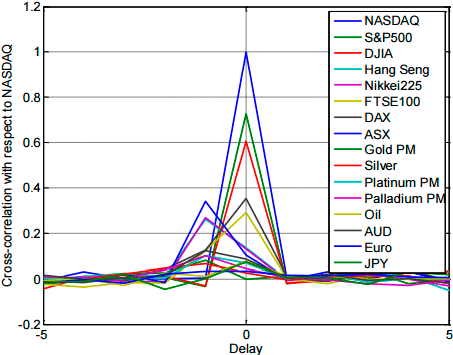
Рисунок 2 – Автокорреляционная и кросс-корреляция рыночных тенденций, используя NASDAQ в качестве базы.
Это может быть видно из графика, что автокорреляционная NASDAQ дневного тренда является только ненулевой в начале на основе которых мы можем заключить, что тенденция NASDAQ ежедневно индекса примерно марковский процесс. Следовательно, последние данные NASDAQ не будет предоставлять намного больше информации для ее будущего движения. Тот же вывод можно сделать на многих других источников данных, чьи кросс-корреляции с NASDAQ близка к нулю. Хотя тенденция DJIA и S & P500 есть сильная корреляция с NASDAQ учитывая данные на тот же день, они не доступны на момент они необходимы для прогнозирования. Тем не менее, источники данных, такие как DAX AUD и некоторых других рынках перспективные возможности для нашей предсказателя, построенные по алгоритму машинного обучения, поскольку они имеют относительную высокую корреляцию с NASDAQ в начале координат, и их данные доступны до или в начале времени рынок торговой США , Это наблюдение фактически подтверждает наш принцип прогноз, как описано в предыдущих разделах, о том-связи между глобальными рынками и, как информация отражается их движений может быть полезным для предсказания американских фондовых рынках.
В дополнение к корреляции ежедневных движений рынка, это также стоит исследовать корреляцию рыночных тенденций в долгосрочной перспективе, что также может оказать ценную информацию для прогнозирования будущей цены [4-5]. Для изучения этого ? в формуле. (3) изменяется от 1 дня до 50 дней, и часть результатов приведены на рисунке 3. Как видно из графика, временные корреляции между рынками увеличивается с временного окна ? над которой тенденции фондовых индексов рассчитывается. Одно из объяснений этого явления является то, что расчет в уравнении. (3) делает время пролеты выходов перекрываются друг с другом, и, следовательно, увеличивает временные корреляции. Кроме того, операция также неявно провести усреднение по данным в интервале, который эффективно удаляет шум и основной корреляция между рынками становятся яснее.
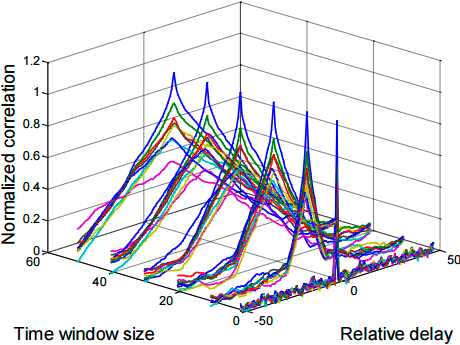
Рисунок 3 – Автокорреляционная и кросс-корреляция рыночных тенденций с различными промежутки времени..
Учитывая все возможные особенности, мы реализовали вперед алгоритм выбора функция используется для выбора функций, которые вносят наибольший вклад в точность прогнозов с использованием различных алгоритмов машинного обучения. Подробности Результаты представлены в следующем разделе. Как и ожидалось, сочетание повседневной тенденции рынка и долгосрочной перспективе ovement обеспечить наилучший результат.
Экспериментальные результаты и их обсуждение
Прогнозиорование тренда
1) Одноместный Прогноз Особенность.
В разделе 2 мы использовали кросс-корреляции оценить важность каждой функции. Чтобы проверить информацию, предоставленную корреляционного анализа, мы используем индивидуальный функцию, чтобы предсказать ежедневное индекс NASDAQ тенденцию.Точность предсказания по каждой отдельной функции показан на рисунке 4.
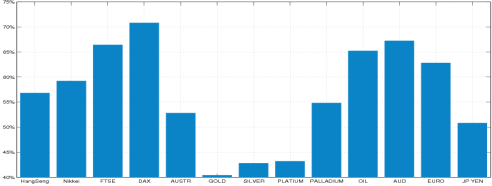
Рисунок 4 – Точность прогноза по одной функции.
Из рисунка видно, что индекс DAX дает лучшие результаты, 70,8% точность прогноза. Прогноз точности австралийского доллара, FTSE и цены на нефть также относительно высока, достигая 67,2%, 66,4% и 65,2% соответственно.
Результатом этого эксперимента поддерживает анализ кросскорреляционной. Таким образом, мы убеждены, что значение индекса других фондовых рынков и цен на сырьевые товары может предоставить полезную информацию в процессе прогнозирования.
2) Долгосрочная Прогноз.
Кроме ежедневного движения, иногда мы также заботимся о результатах прогнозирования на более длительные сроки. Здесь мы определяем нашу задачу прогнозирования знак различия между значением индекса завтрашнего по отношению к тому из несколько дней назад. Мы используем SVM в качестве учебного модели и предсказания Погрешности при различных промежутков времени приведены на рисунке 5.
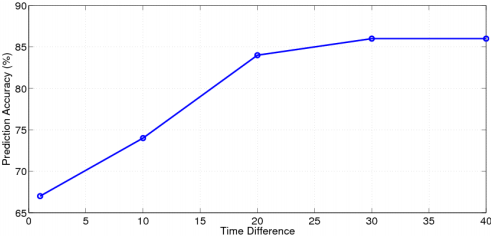
Рисунок 5 – Точность долговременное предсказание.
Из рисунка видно, что повышает точность прогнозирования, когда промежуток времени становится больше. Это происходит потому, что чем дольше период, тем больше у нас информации, и тем выше сопротивление нашей прогнозирования шума. Наконец, мы можем достичь 85% точности, когда время спам становится больше, чем 30 дней.
На самом деле, мы можем повторно Перефразируя эту проблему как оценки Pr{Vt+1-Vt>Ct}, где Ct = -(Vt-ts - Vt). Это соответствует после упомянутого регрессии проблемы повседневной движения фондового рынка.
3) Много-Особенность Прогноз.
Использование функции, описанные в разделе 2, мы сравним прогнозирования точности алгоритма SVM и MART (на основе дерева решений повышения алгоритма). Результаты прогнозирования представлены в таблице 2.
Таблица 2 - Точность однодневного прогноза

Из таблицы 1, мы видим, что точность из SVM и MART ученика может достигать 74%. Эта ежедневная точность предсказания тенденция выше, чем большинство моделей и значений, указанных на веб-сайтах финансового анализа.
Кроме того, отметим, что алгоритм SVM очень чувствительна к размеру обучающих данных. Когда размер обучающего множества не является достаточно большим, гипер-самолет найден алгоритм SVM не могли бы разделить данные должным образом. Таким образом, выбор функция имеет важное значение при использовании SVM. В отличие от множественного регрессионного Добавка деревья (МАРТ) алгоритм требует меньше подготовки данных и предпочитает высокой размерной набор функций.
Чтобы проверить общность нашей модели, мы использовали тот же самый алгоритм, чтобы предсказать два других американских фондовых рынков. Результаты показаны в таблице 3 ниже.
Таблица 3 - Точность прогноза на всех американских рынках

Как можно видеть, все записи в таблице являются высокими. Это показывает, что наша модель может быть применена для всех фондовых рынков США. На самом деле, идея использования задержку между различными фондовых рынках также может быть использована для прогнозирования другие индексы.
Регрессия
По сравнению с фондового тенденции, точнее прирост фондового индекса может предоставить больше информации для инвестиционной стратегии. Это означает, что задача классификации Теперь развивается в задаче регрессии. Для оценки производительности нашей модели, мы используем квадратный корень из среднего квадрата ошибки (СКО) в качестве критериев, который определяется как

Мы используем линейную регрессию, обобщенная линейная модель (GLM) и метод опорных векторов, чтобы предсказать точное значение ежедневного движения NASDAQ. Значения СКО для разных алгоритмов, приведены в таблице 4 ниже
Таблица 4 - Точность регрессии фондовых индексов

Базовый предсказателем в таблице формируется удержания фильтра нулевого порядка. Из таблицы видно, что СВМ дает наиболее точный прогноз.СКО задается SVM 21,6, только половина средней флуктуации, 47.66.
Многокласовая Классификация
В предыдущей части мы исследовали различные методы, чтобы улучшить точность предсказания и свести к минимуму корень квадратный среднеквадратичной ошибки. Эти усилия могут быть непосредственно использованы для максимального торговую прибыль. Однако, помимо максимизации прибыли, еще один аспект нашей задачей является минимизация риска торговли. В этой части, мы будем использовать SVM регрессионной модели и начать с основного алгоритма интуиции в SVM
В SVM, далее расстояние между точкой и гиперплоскости, более уверенно мы для прогнозирования мы сделали, в то время как наш прогноз не может быть очень точным, когда точка находится близко к гипер-плоскости. Чтобы свести к минимуму торговый риск, мы можем забрать эти рискованные моменты и игнорировать их метки прогнозирования. Таким образом, мы должны классифицировать исходные данные, по меньшей мере трех классов, негативный, нейтральный и положительных. Это интуиция, что приводит к прототипу нашей мультиклассируют модели классификации.
Для наращивать мультиклассируют классификатор, мы, во-первых необходимо определить ширину центральной области. Чтобы оценить, насколько хорошо наш классификатор, мы ввели понятия точности и отзыве, которые определяются как

В уравнениях выше, тп, ФП и п стоять истинного положительного, ложноположительных и отрицательных соответственно. Точные и вспомнить значения против различных центральных шириной области представлены на рис. 6. На этой фигуре вызова для положительного класса отражает долю прогнозируемых растущих среди всех дней роста дней, а точность указывает на скорость роста успех среди предсказаний. Таким образом, напомним, непосредственно влияет на частоту торговых и точность ударов прибыль / убыток в каждый момент времени. Принимая продукт из двух, мы вычисляем счет F1, которая определяется как

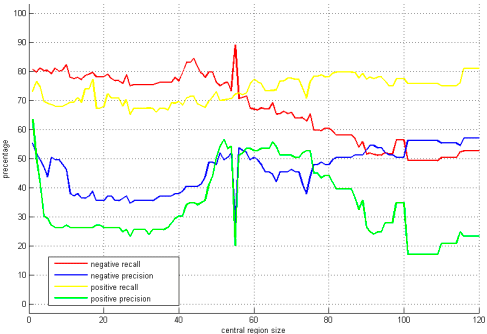
Рисунок 6 – Точность и отзыв против центральных шириной окна для положительной и negtive класса.
Значение баллов F1 для положительных и отрицательных классов показаны на рис. 7. Как можно видеть из графика, множество F1 как для класса являются относительно высокими примерно 0 до 50. Таким образом, мы должны выбрать размер окна около 0 при торговле сборов / налоговых достаточно малы, чтобы быть проигнорированы. В противном случае, следует выбирать 50 в качестве оптимального размера окна.
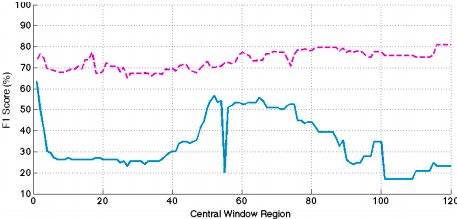
Рисунок 7 – F1 оценка против центральной размера окна для положительной и отрицательной класса.
Торговая модель
В этом разделе, мы будем строить торговый модель, основанную на предсказателя мы находим в разделе 2 и разделе 3 мы сравним результаты моделирования нашей модели в отношении двух отдельных тестах.
Основные настройки
Мы случайным образом выбрать 5 различных временных интервалов для моделирования, 50 дней внутри каждого временных интервалов.Первоначальный капитал в начале слота каждый раз составляет 10000 долларов. В конце торгового периода, все обладали запасы вынуждены быть обналичены. Кроме того, для простоты будем считать, что нет Гербовый сбор или любой вид налога или гонорары во время процесса и короткие продажи не допускается в нашей модели.
Модель Спецификация
В нашей модели мы используем две эталонные модели и одну модель, используя нашу предсказатель. Здесь мы опишем три модели в деталях.
1) Тест модель 1 В этой простой модели, мы предположим, что мы используем все деньги, чтобы купить акции в первый день и продавать акции в конце. Таким образом, прибыль зависит от тенденции в течение этого периода тестирования, то есть

2) Тест модель 2В этой модели, мы предполагаем, что закрытие фондового индекса завтра выше, чем сегодня, если сегодня показатель выше, чем вчера. Всякий раз, когда предсказание растет, мы покупаем в большинстве S акций акций. В противном случае, мы продаем все акции у нас есть.
Эта модель хорошо работает, когда фондовые рынки идти гладко. Но это потери много, когда рынки колеблются или потрясения часто.
3) Предлагаемый Торговая модель Мы используем результаты прогнозирования нашего SVM ученика.Торговая доверитель же, как Benchmark модели 2. То есть, мы покупаем акции, когда предсказание является положительной, и все запасы денежных мы имеем, когда предсказание является отрицательным.
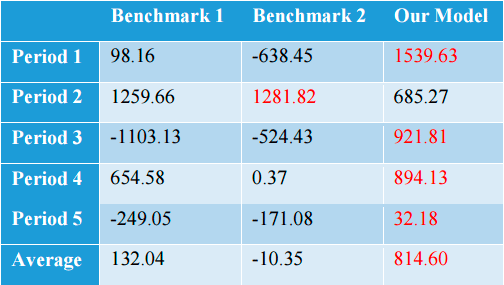
Результаты моделирования Прибыль из трех моделей в течение пяти период показано в таблице 5 ниже. Из таблицы видно, что в течение большей части периода, наша предложенная модель выигрывает большинство прибыли. В среднем, наша модель получает 814,6 долларов в качестве прибыли на каждые 50 дней. Это 8% дозы выводится в течение 50 дней. Таким образом, мы можем достичь годовой интересы около 30%.
Кроме того, высокая прибыль, наша модель также имеет преимущество низкого риска. Наша модель редко проигрывает в торговый период, а тестовая модель 1 и модель 2 тест теряет в период 3 и 5. На самом деле, в большинстве случаев, наша модель может получить по крайней мере 5% прибыли в 50 день торгового периода.
Хотя мы можем достичь высокую прибыль и низкий риск в нашей модели, мы будем до сих пор помню, что мы не брали налог и сборы во внимание. Мы также предполагаем, что наша работа не будет иметь прямого влияния на значение индекса.
Таблица 5 - Торговые результаты различных торговых стратегий
Заключение
В проекте, мы предложили использовать данные, собранные из разных мировых финансовых рынках с алгоритмами машинного обучения для прогнозирования движения фондовых индексов. Наши результаты могут быть сведены в трех аспектах:
1. Корреляционный анализ указывает на сильное взаимосвязь между индексом фондовой США и мировых рынках, которые закрывают непосредственно перед или в самом начале американской торговой времени.
2. Различные модели, основанные обучения машина предлагается для прогнозирования дневной тренд американских акций. Численные результаты предполагает высокую точность
3. Практическая торговая модель построена на наш хорошо обученный предсказателя.Модель генерирует высокую прибыль по сравнению с выбранными критериями.
Есть ряд других направлений можно исследовать, начиная с этого проекта.Первый заключается в изучении других творческих и эффективных методов, которые могут принести еще более высокую производительность по прогнозированию фондового рынка. Во-вторых, модели могут быть изменены, чтобы заботиться о налоговой и сборов в процессе торговли. Наконец, мы можем исследовать механизм короткие продажи и увеличить прибыль наш, даже если рынок бычий
Список использованной литературы
1. W. Huang et al., “Forecasting stock market movement direction with
support vector machine,” Computers & Operations Research, 32, pp.
2513–2522005, 2005
2. J. Moody, et al., “Learning to trade via direct reinforcement,” IEEE
Transactions on Neural Networks, vol. 12, no. 4, Jul. 2001.
3. www.wikiposit.org
4. S. Zemke, “On developing a financial prediction system: Pitfall and
possibilities,” Proceedings of DMLL-2002 Workshop, ICML, Sydney,
Australia, 2002.
5. Vatsal H. Shah, “Machine learning techniques for stock prediction,”
www.vatsals.com.