1. Введение
Эта статья объединяет новые алгоритмы и идеи для создания основы для надежной и чрезвычайно быстрого обнаружения объекта. Этот Фреймворк демонстрируется и частично мотивирован, задачей распознавания лица. С этой целью мы построили фронтальную систему распознавания лиц, которая достигает обнаружения и ложных срабатываний, которые эквивалентны лучшим опубликованным результатам [16, 12, 15, 11, 1]. Эта система распознавания лица наиболее четко отличается от предыдущих подходов в своей способности распознавать лица чрезвычайно быстро. Работая с 384х288 пиксельными изображениями, со скоростью 15 кадров в секунду на обычном 700 МГц Intel Pentium III обнаружены лица. В других системах распознавания лиц, вспомогательной информации, например, различия изображения в видеопоследовательности или цвет пикселя в цветных изображениях, которые были использованы для достижения высоких скоростей кадров. Наша система обеспечивает высокую частоту кадров, работающих только с серой цветовой шкалой. Эти альтернативные источники информации также могут быть интегрированы с нашей системой, чтобы достичь еще более высокую частоту кадров. Есть три основных вклада нашей системы обнаружения объекта. Мы представим каждую из этих идей кратко ниже, а затем опишем их подробно в последующих разделах.
Первый вклад этой статьи является новое представление изображения называется интегральным изображение, которое позволяет достичь очень быстрой оценки примитив. Частично мотивировано работой Papageorgiou и др. наша система обнаружения не работает напрямую с яркостью изображения [10]. Как и эти авторы мы используем набор признаков, которые напоминают функции базиса Хаара (хотя мы также будем использовать родственные фильтры, которые являются более сложными, чем фильтры Хаара). Для того, чтобы вычислить эти признаки очень быстро во многих масштабах мы вводим интегральное представление для изображений. Интегральное изображение может быть вычислено из изображения с помощью нескольких операций на пиксель. После вычисления, любой из этих Harr-подобных признаков может быть вычислен в любом масштабе или месте с одинаковой скоростью.
Второй вклад данной работы является метод построения классификатор, выбрав небольшое количество важных функций с помощью AdaBoost [6]. В пределах любого подмножества изображения общее количество Harr-подобных признаков очень велико, гораздо больше, чем количество пикселей. Для того, чтобы обеспечить быструю классификацию, процесс обучения должен исключить значительное большинство имеющихся функций, и сосредоточиться на небольшом наборе важнейших примитв. Мотивируясь работой Tieu и Viola, отбор признаков достигается за счет простой модификации процедуры AdaBoost: слабая обучаемость ограничена тем чтобы каждый слабый классификаторское возвращение могло зависеть только от одной признака [2]. В результате каждый этап процесса ускорения, который выбирает новый слабый классификатор, можно рассматривать как процесс выбора признаков. AdaBoost обеспечивает эффективный алгоритм обучения и сильные границы обобщения в исполнении [13, 9, 10].
Третий основной вклад этой статьи представляет собой способ объединения последовательно более сложные классификаторы в каскадные структуры, что резко увеличивает скорость детектора, сосредоточив внимание на перспективных областях изображения. Идея подхода позади фокуса внимания является то, что часто можно быстро определить, где в изображении объект может находится [17, 8, 1]. Более сложная обработка зарезервирована только для этих перспективных регионов. Ключевой мерой такого подхода является "ложный отрицательный результат" скорость процесса сосредоточения внимания. Должно быть так, что все, или почти все, экземпляры объектов выбираются фильтром сосредоточения внимания.
Мы опишем процесс обучения чрезвычайно простого и эффективного классификатора, который может быть использован в качестве "контролируемого" оператора фокус внимания. Термин под контролируемого относится к тому факту, что оператор сосредоточения внимания натренирован на обнаружение примеров конкретного класса. В области обнаружения лица возможно достижение менее 1% ложноотрицательных и 40% ложных срабатываний, используя классификатор, созданный из двух Harr-подобных признаков. Эффект этого фильтра заключается в снижении более чем на половину числа тех местах, где должны быть оценен конечный детектор.
Эти подмножества, которые не отторгаются исходным классификатором обрабатываются последовательностью классификаторов, каждый немного более сложным, чем в прошлом. Если какой-либо классификатора отвергает подмножество, дальнейшая обработка не выполняется. Структура процесса каскадного обнаружения заключается в, дегенерирующем дереве решений, и как таковой связан с работой Geman и его коллегами [1, 4].
Чрезвычайно быстрый детектор лицо будет иметь широкое практическое применение. Они включают в себя пользовательские интерфейсы, базы данных изображений и телеконференций. В приложениях, где быстрые каркасные ставки не нужны, наша система позволит значительно дополнить последующей обработки и анализа. Кроме того наша система может быть реализована в широком диапазоне малых маломощных приборов, в том числе портативные устройства и embedded processors. В нашей лаборатории мы внедрили этот детектор лица на КПК Compaq Ipaq и достигли обнаружения на двух кадров в секунду (это устройство имеет низкую мощность 200 MIPS Сильный процессор Arm, который испытывает недостаток аппаратных средств с плавающей точкой).
2. Признаки
Наша процедура обнаружения объекта классифицирует изображения на основе значения простых признаков. Есть много причин для использования признаков, а не пикселей напрямую. Наиболее распространенной причиной является то, что признаки могут служить для кодирования одноранговой информации, которую трудно узнать с помощью конечного значения обучающих данных. В этой системе также существует вторая критическая причина для признаков: система, основанная на признаках, работает гораздо быстрее, чем системы на основе пикселей.
Простые используемые признаки, напоминают базисные функций Хаара, которые были использованы Papageorgiou и др. [10]. Более конкретно, мы используем три вида признаков. Значение признака из двух прямоугольников это разница между суммой пикселей в пределах двух прямоугольных областей. Области имеют одинаковые размеры и форму и примыкают по горизонтали или вертикали (рис. 1). При трех прямоугольниках вычитаем сумму в пределах двух внешних прямоугольников из суммы центрального прямоугольника. Наконец признак из четырех прямоугольников вычисляется как разность между диагональными парами прямоугольников.
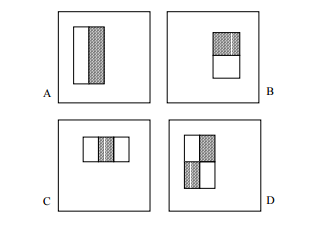
Рисунок 1 – Пример прямоугольных признаков показаны относительно окна обнаружения вшита. Сумма пикселей, которых лежат в пределах белых прямоугольников, вычитаются из суммы пикселей в серых прямоугольниках. Два прямоугольника показаны в (А) и (В). На рисунке (C) признак с тремя прямоугольниками и (D) признак с четырьмя прямоугольниками.
Учитывая что базовое разрешение детектора 24x24, исчерпывающий набор прямоугольных признаков достаточно велик, более 180 000. Замете что вопреки базису Haar, набор признаков сверхполный.
2.1 Интегральное изображение
Прямоугольные примитивы можно вычислить очень быстро с использованием промежуточного представления для изображения, которое мы называем интегральное изображение. Интегральное изображение в x, y хранит сумму пикселей выше и левее стоящих x, y, включительно:
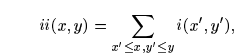
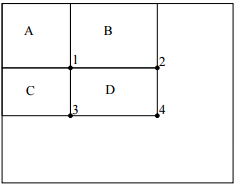
Рисунок 1 – сумма пикселей внутри прямоугольника может быть вычислена с помощью 4 значений массива. Значение интегрального изображения в позиции 1 это сумма пикселей прямоугольника D. Значение 2 = A+B, позиция 3 = A+C, и позиция 4 = A+B+C+D. Сумма внутри D может быть вычислена как 4+1-(2+3)
, где ii(x, y) – интегральное изображение и i(x, y) – исходное изображение. Используя следующую пару рекуррентностей:

, (где s(x, y) – кумулятивная сумма ряда, s(x, -1)=0, и ii(-1, y)=0) интегральное изображение может быть вычислено в один проход оригинального изображения.
Используя интегральное изображение любую прямоугольную сумму можно вычислить с помощью 4 позиций массива (рис. 2). Очевидно, что разница между двумя прямоугольными суммами может быть вычислено с использованием восьми позиций. Так как два прямоугольника, определенные выше, включают смежные прямоугольные суммы они могут быть вычислен с использованием шести позиций массива, восемь в случае трёх прямоугольников, и девять для признаков с четырьмя прямоугольниками.
2.2 Выводы по признакам
Прямоугольные признаки являются несколько примитивными по сравнению с альтернативой, управляемыми фильтрами [5, 7]. Управляемые фильтры, и их родственники, отлично подходят для детального анализа границ, сжатия изображений и анализа текстуры. С другой стороны, в то время как признаки чувствительны к наличию ребер, решеток и других простых структур, они являются довольно стойкими. В отличие от фильтров у прямоугольных признаков единственное направление может быть вертикальным, горизонтальным и диагональным. Множество функций прямоугольника, тем не менее обеспечивают богатое представление изображения, которое поддерживает эффективное обучение. В сочетании с интегральным изображением, эффективность набора признаков обеспечивает достаточную компенсацию за их ограниченную гибкость.
3. Изучение функции классификации
Задав ряд признаков и ряд для обучения с положительными и отрицательными изображениями и отрицательными, любой подход машинного обучения может быть использован для обучения классификации. В нашей системе вариант AdaBoost используется для выбора малого набора признаков и обучения классификатора [6]. В оригинале, алгоритм обучения AdaBoost используется для ускорения классификации простого (или же слабого) алгоритма обучения. Есть целый ряд формальных гарантий, предусмотренных процедурой обучения AdaBoost. Freund и Schapire доказали, что ошибка обучения сильного классификатора приближается к нулю экспоненциально с повышением количества итераций. Что еще более важно ряд результатов доказал позже о выполнении обобщения [14]. Ключевое понимание в том, что производительность обобщение связано с краем примеров, и что AdaBoost достигает больших полей быстрее.
Напомним, что существует более 180 000 прямоугольных признаков, связанных с каждым подмножеством изображения, число гораздо больше, чем количество пикселей. Даже если каждый признак может быть вычислена очень эффективно, вычисление полного набора непомерно дорого. Наша гипотеза, которая подтверждается экспериментально, заключается в том, что очень небольшое число этих признаков могут быть объединены, чтобы сформировать эффективный классификатор. Основная задача состоит в том, чтобы найти эти признаки.
В поддержку этой цели, слабый алгоритм обучения предназначен для выбора одного признака, который наилучшим образом разделяет положительные и отрицательные примеры (это похоже на подходе [2] в области поиска базы данных изображений). Для каждого признака, слабая обучение определяет оптимальную функцию порога классификации, таким образом минимальное количество примеров ошибочно классифицируется. Слабый классификатор h_j (x) состоит из признаков f_j, a порог ?_j и паритет p_j указывающая направление знака неравенства:

Тут x - 24x24 пиксельное подмножество изображение. Таблица 1 демонстрирует процесс.
Таблица 1 - Алгоритм AdaBoost для обучения классификатора. Каждая итерация выбирает один признак из 180 000 потенциальных признаков.

На практике ни один признак не может выполнить задачу классификации с без ошибок. Признаки, которые выбраны в ранних итерация процесса обучения имеют частоту ошибок в диапазоне от 0,1 до 0,3. Признаки, выбранные в поздних итерация, поскольку задача становится более труднее, процент ошибок находится между 0,4 и 0,5.
3.1 Выводы по обучению
Было предложено много процедур отбора общей чертой (смотрите главу 8 [18] для обзора). Наше окончательное приложение требовало очень агрессивный подход, который отбросит подавляющее большинство признаков. Для подобной проблемы распознавания Papageorgiou и др. была предложена схема отбора признаков на основе признак дисперсии [10]. Они показали хорошие результаты, выбрав 37 признаков из общего числа 1734 признаков.
Roth и др. предлагают способ отбора признаков на основе Отсеивающего экспоненциального перцептроного правила обучения [11]. Процесс обучения Отсеивания сходится к решению, где многие из этих весов равны нулю. Тем не менее, очень большое количество признаков сохраняются (возможно, несколько сотен или тысяч).
3.2 Результаты обучения
Хотя детали обучения и производительности окончательной системы представлены в разделе 5, несколько простых результатов заслуживают обсуждения. Первоначальные эксперименты показали, что классификатор фронтального лица построен из 200 признаков дает высокий уровень обнаружения 95% с ложных срабатываний 1 в 14084. Эти результаты являются убедительными, но не достаточными для многих реальных задач. С точки зрения вычислений, этот классификатор, вероятно, быстрее, чем в любой другой опубликованной системе, требующей 0,7 секунды для сканирования 384 288 пикселей изображения. К сожалению, самый простой метод для повышения эффективности обнаружения, добавляя новые возможности для классификатора, непосредственно увеличивает время вычислений.
Для задачи обнаружения лица, начальные признаки прямоугольники, отобранные AdaBoost являются осмысленными и легкими для интерпретации. Первый выбранный признак, фокусируется на собственности, что область глаз часто темнее, чем область носа и щек (рис. 3). Этот признак является относительно большим по сравнению с рабочим подмножеством, и должен быть несколько нечувствительным к размеру и местоположению лица. Второй признак выбран из-за того, что глаза темнее, чем переносица.

Рисунок 3 - Первый и второй признак, выбранные AdaBoost. Два признака показаны в верхней строке, а затем наслаивали на типичном лицом обучения в нижнем ряду. Первый признак измеряет разницу в интенсивности между областью глаз и областью верхней щеки. Признак основан на наблюдении, что область глаз часто темнее, чем щеки. Второй признак сравнивает интенсивности в глазных регионах к интенсивности переносицы.
4. Каскад сосредоточения внимания
В данном разделе описывается алгоритм построения каскада классификаторов, которая достигает повышенную производительность обнаружения в то время как радикально сокращаяется время вычислений. Ключевой момент в том, что усиленные классификаторы могут быть построены меньше, и, следовательно, более эффективными, если они отвергают многие негативные подмножества при обнаружении почти всех положительных случаев (то есть порог форсированного классификатора может быть отрегулирована таким образом, чтобы ложноотрицательный ставка была близка к нулю). Упрощенные классификаторы используются, чтобы отклонить большинство подмножеств прежде, чем более сложные классификаторы призваны обеспечить низкое количества ложных срабатываний.
Общий вид процесса обнаружения заключается в дегенерирующем дереве решений, что мы называем «каскад» (рис. 4). Положительный результат от первого классификатора запускает оценку второго классификатора, который также были скорректированы для достижения очень высокого уровня обнаружения. Положительный результат от второго классификатора запускает третий классификатор, и так далее. Отрицательный результат в любой точке приводит к немедленному отказу от подмножества.
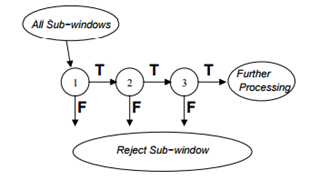
Рисунок 4 - Схематичное изображение каскада обнаружения
Этапы в каскаде строятся путем обучения классификаторов с использованием AdaBoost, а затем регулируют порог, чтобы свести к минимуму ложные отрицательные результаты. Обратите внимание, что порог AdaBoost по умолчанию предназначен для получения низкой частоты ошибок на обучающих данных. В целом более низкий порог дает более высокий уровень обнаружения и более высокие количества ложных срабатываний.
Например, отличный первый классификатор может быть построен из сильного классификатора с двумя признаками путем снижения порога, чтобы свести к минимуму ложные результаты. Измеряется от проверенного обученного набора, порог может быть отрегулирована для обнаружения 100% лиц с ложноположительным в размере 40%. Рис.3 показывает описания двух признаков, используемых в данном классификаторе.
Вычисление двух признаков классификатора составляет около 60 инструкций микропроцессора. Кажется, трудно себе представить, что любой простой фильтр может достичь более высоких скоростей отторжения. Для сравнения, сканирования простой шаблон изображения или одного слоя персептрона, потребуется по меньшей мере, в 20 раз больше операций в подмножестве.
Структура каскада отражает тот факт, что в каком-либо одном изображении подавляющее большинство подмножеств этого изображения отрицательны. Таким образом, каскад пытается отвергнуть как можно больше отрицательных на самой ранней стадии. В то время как положительный экземпляр инициирует переоценку каждого классификатора в каскаде, это является чрезвычайно редким событием.
Во многом как дерево решений, последующие классификаторы обучаются с использованием примеров, которые прошли через все предыдущие стадии. В результате, второй классификатор сталкивается с более трудной задачей, чем первый. Примеры, которые делают это через первый этап являются более "тяжелыми", чем типичные примеры. Более сложные примеры, вталкиваемые с более глубокими классификаторами, толкает весь приемник операционных характеристик (receiver operating characteristic ROC) по кривой вниз. При заданной скорости обнаружения, более глубокие классификаторы имеют соответственно больше ложно положительных показателей.
4.1 Обучение каскад классификаторов
Каскадный процесс обучения включает в себя два компромисса. Во многих случаях классификаторы с более широкими возможностями сможет достичь более высокого уровня обнаружения и меньше ложных срабатываний. В то же время классификаторов с большим количеством примитив требует большего времени вычислений. В принципе можно было бы определить рамки оптимизации, в которой: 1) количество ступеней классификатора, 2) количество признаков на каждом этапе, и 3) порог каждой ступени, жертвуется, чтобы минимизировать ожидаемое число оцениваемых признаков. К сожалению, найти оптимальный вариант чрезвычайно трудно.
На практике используется очень простая структура для получения эффективного классификатор, который имеет высокую эффективность. Каждая стадия в каскаде снижает процент ложных срабатываний и снижает уровень обнаружения. Цель выбирается за минимальное снижение ложных срабатываний и максимального обнаружения. Каждый этап обучается путем добавления признака, пока обнаружение цели и ложные срабатывания не будут уравновешены (эти показатели определяются путем тестирования детектора на множестве проверок). Этапы добавляют до тех пор, пока общий целевой показатель для ложных срабатываний и обнаружения не встретятся.
Список использованной литературы
[1] Y. Amit, D. Geman, and K. Wilder. Joint induction of shape features and tree classifiers, 1997.
[2] Anonymous. Anonymous. In Anonymous, 2000.
[3] F. Crow. Summed-area tables for texture mapping. In Proceedings of SIGGRAPH, volume 18(3), pages 207–212, 1984.
[4] F. Fleuret and D. Geman. Coarse-to-fine face detection. Int. J. Computer Vision, 2001.
[5] William T. Freeman and Edward H. Adelson. The design and use of steerable filters. IEEE Transactions on Pattern Analysis and Machine Intelligence, 13(9):891–906, 1991.
[6] Yoav Freund and Robert E. Schapire. A decision-theoretic generalization of on-line learning and an application to boosting. In Computational Learning Theory: Eurocolt ’95, pages 23–37. Springer-Verlag, 1995.
[7] H. Greenspan, S. Belongie, R. Gooodman, P. Perona, S. Rakshit, and C. Anderson. Overcomplete steerable pyramid filters and rotation invariance. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1994.
[8] L. Itti, C. Koch, and E. Niebur. A model of saliency-based visual attention for rapid scene analysis. IEEE Patt. Anal. Mach. Intell., 20(11):1254–1259, November 1998.
[9] Edgar Osuna, Robert Freund, and Federico Girosi. Training support vector machines: an application to face detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1997.
[10] C. Papageorgiou, M. Oren, and T. Poggio. A general framework for object detection. In International Conference on Computer Vision, 1998.
[11] D. Roth, M. Yang, and N. Ahuja. A snowbased face detector. In Neural Information Processing 12, 2000.
[12] H. Rowley, S. Baluja, and T. Kanade. Neural network-based face detection. In IEEE Patt. Anal. Mach. Intell., volume 20, pages 22–38, 1998.
[13] R. E. Schapire, Y. Freund, P. Bartlett, and W. S. Lee. Boosting the margin: a new explanation for the effectiveness of voting methods. Ann. Stat., 26(5):1651–1686, 1998.
[14] Robert E. Schapire, Yoav Freund, Peter Bartlett, and Wee Sun Lee. Boosting the margin: A new explanation for the effectiveness of voting methods. In Proceedings of the Fourteenth International Conference on Machine Learning, 1997.
[15] H. Schneiderman and T. Kanade. A statistical method for 3D object detection applied to faces and cars. In International Conference on Computer Vision, 2000.
[16] K. Sung and T. Poggio. Example-based learning for viewbased face detection. In IEEE Patt. Anal. Mach. Intell., volume 20, pages 39–51, 1998.
[17] J.K. Tsotsos, S.M. Culhane, W.Y.K. Wai, Y.H. Lai, N. Davis, and F. Nuflo. Modeling visual-attention via selective tuning. Artificial Intelligence Journal, 78(1-2):507–545, October 1995.
[18] Andrew Webb. Statistical Pattern Recognition. Oxford University Press, New York, 1999.