
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи системы
- 3. Обзор существующих моделей и методов
- 4. Математическая постановка задачи
4.1 Алгоритм генетического програмирования
4.2 Применение генетического програмирования для решения задачи
4.3 Генерация начальной популяции
4.4 Применение генетического програмирования для получения правил
- Выводы
- Список источников
Введение
Эффективность работы практически любой отрасли в значительной степени определяется уровнем информационных технологий и широтой их применения. Этот фактор становится решающим в развитии практически любой области.
При разработке ЭС как правило используется продукционные модели.
Продукционные модели – это наиболее распространенные на текущий день модели представления знаний, где знания описываются с помощью правил «если–то» (явление > реакция) и представляются в виде: ЕСЛИ условие (антецедент) ТО действие (консеквент). Система поддержки принятия решений предназначена для поддержки многокритериальных решений в сложной информационной среде. При этом под многокритериальностью понимается тот факт, что результаты принимаемых решений оцениваются не по одному, а по совокупности многих показателей (критериев) рассматриваемых одновременно. Информационная сложность определяется необходимостью учета большого объема данных, обработка которых без помощи современной вычислительной техники практически невыполнима. В этих условиях число возможных решений, как правило, весьма велико, и выбор наилучшего из них "на глаз", без всестороннего анализа может приводить к грубым ошибкам.
Под условием понимается некоторое предложение–образец, по которому осуществляется поиск в базе знаний, а под действием – набор действий, выполняемых при успешном исходе поиска. Внутри консеквента могут также генерироваться и добавляться в базу новые факты, которые были получены в результате вычислений или взаимодействия с пользователем.
При использовании таких моделей у систем, основанных на знаниях, имеется возможность:
- применение простого и точного механизма использования знаний;
- представления знаний с высокой однородностью, описываемых по единому синтаксису.
Эти две отличительные черты и определили широкое распространение методов представления знаний правилами. Но вот получение таких правил является одной из наиболее трудоемких задач.
1. Актуальность темы
На данный момент процесс получения продукционных правил является обязательным фактором для ЭС в области представления знаний. Это связано с тем, что методы машинного обучения на основе использования обучающих данных имеют преимущества по сравнению с другими математическими методами.
Благодаря развитию компьютерных технологий, все данные и методы искусственного интеллекта на базе машинного обучения, методы интелектуального анализа позволят быстро и эффективно получать продукционные правила для извлечения знаний и получать новые и более обновленные знания используя обучающие примеры.
Учитывая вышеуказанное, разработка данного программного приложения является актуальным, эффективным и рациональным решением для будущих потребителей системы.
2. Цель и задачи системы
Целью данной работы является разработать математический аппарат для получения продукционных правил для ЭС.
Для этого необходимо решить задачи:
- разработать структуру ЭС;
- разработать продукционные правила.
Для решения перечисленных задач выбраны следующие направления исследований:
- методы интеллектуального анализа данных с целью получения продукционных правил;
- принципы построения экспертных систем.
3. Обзор существующих моделей и методов
В настоящее время существует достаточно много методов извлечения закономерностей. Наиболее широко для обработки результатов используются методы математической статистики и регрессионного анализа. Но такие методы могут быть недоступны неподготовленному пользователю, так как требуют специальной математической подготовки. Этим обусловлена необходимость представления результатов обработки информации в форме, доступной для специалистов любой области. Рассмотрим некоторые методы извлечения знаний, многие из которых способны предоставить результат в понятном для человека виде.
В последние годы успешно внедряются приложения, реализованные на основе машинного обучения (МО). Область МО рассматривает вопросы разработки компьютерных программ, которые способны автоматически получать новые или обновлять накопленные знания, используя обучающие примеры. Общий подход МО состоит в разработке и использовании программ, способных обучатся под руководством учителя. Так, учитель предъявляет программе примеры реализации некоторого концепта, а задача программы заключается в том, чтобы извлечь из этих примеров набор атрибутов и значений, которые определяют этот концепт.
Все идет к тому, что МО будет играть центральную роль в информатике и компьютерных технологиях. МО использует понятия и происходит от многих областей таких дисциплин, как теория вероятности и статистика, ИИ, философия, теория информации, нейробиология, вычислительная теория сложности, элементы теории управления и другие.
Применение МО к извлечению знаний может использоваться:
- для извлечения множества правил из обучающего множества входных данных;
- анализа важности отдельных правил;
- оптимизации производительности набора правил.
Методы ИИ используют машинное обучение как подход к проблеме поиска решения, на основе применения накопленных знаний, которые содержатся в обучающих данных. Рассмотрим некоторые из них.
Извлечение знаний с помощью НС. Как правило, НС используются как инструмент предсказания, а не понимания. Классический нейросетевой подход – метод черного ящика – предполагает создание имитационной модели, без явной формулировки правил принятия решений.
Метод нейросетевого предсказания реализуется НС, способной осуществлять манипуляции в пространстве признаков большой размерности. Решения задачи с помощью НС можно описать следующим алгоритмом:
- Формализация обучающей выборки. Отбор пациентов и информации, которая будет включена в обучающую выборку. Выбор важных факторов, характеризующих (влияющих на) определенное заболевание. При необходимости – кодирование и нормировка обучающих данных.
- Формирование архитектуры НС. Выбирается тип НС, функции активации и алгоритм обучения.
- Начальная активация нейронов. Задание начальных весовых коэффициентов.
- Итерационное обучение НС выбранным алгоритмом.
- Получение и интерпретация результата.
Эволюционные вычисления включают четыре относительно независимых направления: генетические алгоритмы (ГА), эволюционное программирование, ГП и эволюционные стратегии. Все четыре парадигмы начали исследоваться в 60–х и 70–х годах, но только в конце 80–х годов они начали широко применятся на практике и получили признание.
В настоящее время ГА рассматриваются как один из наиболее успешных методов МО. По существу, они являются процедурами оптимизации, имитирующими при проектировании модели такие процессы, как генетическая рекомбинация, мутация и отбор, аналогичные тем, что обусловливают естественную эволюцию. Первые генетические алгоритмы были предложены в начале 70–х годов Джоном Холландом (John Holland) с целью имитации эволюционных процессов в живой природе.
Реализовать более мощные возможности можно с помощью ГП. ГП является одной из парадигм эволюционных вычислений, которые тоже основаны на формализации принципов естественной эволюции. В настоящее время ГП успешно применяется при решении различных задач. В качестве особи (потенциального решения) в ГП используется компьютерная программа, которая решает определенную задачу. В отличие от других эволюционных методов в ГП особи имеют изменяющиеся размер и форму. Особь строится на основе множества проблемно–ориентированных элементарных функций (функционального множества) и констант (терминального множества), выбор которых существенно влияет на размерность пространства поиска и качество получаемого решения. В процессе эволюции производится автоматическая разработка, в определенном смысле, лучшей программы.
Решение задачи на основе ГП можно представить следующей последовательностью действий:
- Создание исходной популяции.
- Оценка особей по фитнесс–функции.
- Выбор родителей (работает оператор отбора – репродукции).
- Создание потомков из отобранных пар родителей (работает оператор скрещивания – кроссинговер).
- Мутация новых особей (работает оператор мутации).
- Расширение популяции новыми порожденными особями.
- Сокращение расширенной популяции до исходного размера (работает оператор редукции).
- Если критерий останова алгоритма выполнен, то выбор лучшей особи в конечной популяции является результатом работы алгоритма. Иначе переход на шаг 2.
Таким образом, для решения задачи на основе ГП необходимо определить множества элементарных функций и констант, форму представления потенциального решения особи, операции скрещивания и мутации, задать фитнесс–функцию. Очевидно, что эффективность решения задачи зависит от целого ряда параметров: размера популяции, стратегии выбора особей, операторов скрещивания и мутации, стратегии сокращения популяции, а также вида фитнесс–функции. Применяются различные варианты данных параметров в зависимости от конкретной задачи.
4. Математическая постановка задачи
Пусть для вектора входных переменных см. рис.1,для каждого i–ой переменной определен некоторый вектор допустимых значений см. рис.2, где s – количество допустимых значений, разное для каждого входа Xi.
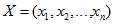
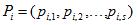
Тогда, например, при решении задачи классификации на два класса с бинарными входными аргументами, правило может быть представлено следующим образом:
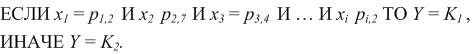
Часто имеется несколько таких правил, например:
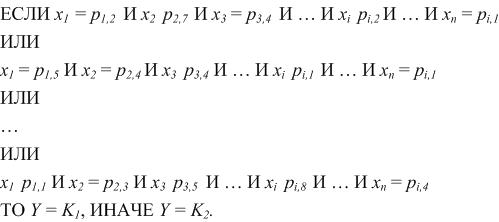
В этом случае систему правил теперь можно описать так:
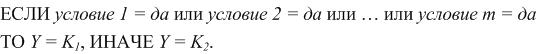
Где i–му условию может соответствовать, например, такое условие:
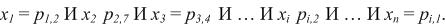
Перечисленные правила можно формально описать следующим образом:
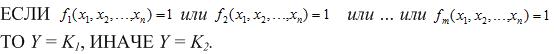
При такой интерпретации для построения правил необходимо найти булевы функции вида (3)
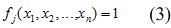
И тогда вся система правил будет представлена так:
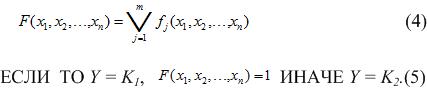
Тогда функция определена в (4), а:
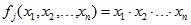
при этом присутствие каждого фактора не обязательно и каждый присутствующий фактор может быть в прямом или инверсном состоянии (операция НЕ). Базис логических функций тоже можно изменять. Разработка правил сводится к нахождению определенной функции или системы функций F и заключается в построении булевых функций рис.3 .
Критерием оценки качества найденного решения может быть оценка точности. Пусть критерием оценивания является ошибка Е(F), тогда задача поиска решения сводится к нахождению функций F, так чтобы выполнялось условие:
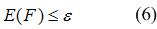
где e – допустимая погрешность классификации.
В качестве ошибки классификации может использоваться:
доля правильной классификации (7);
среднеквадратичная ошибка (8);
средняя абсолютная ошибка (9);
критерий суммы квадратов ошибки (10).
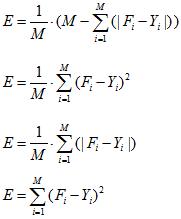
где М – количество обучающих примеров, F – полученный результат, Y – желаемый результат.
4.1Алгоритм генетического програмирования
Для решения задачи с помощью генетического программирования необходимо выполнить следующие предварительные этапы:
определить терминальное множество;
определить функциональное множество;
определить фитнесс–функцию;
определить значения параметров ГП: мощность популяции, максимальный размер особи, вероятности кроссинговера и мутации, способ отбора родителей, критерий окончания эволюции и другие.
После этого разрабатывается эволюционный алгоритм, который реализует ГП для решения конкретной задачи. Возможны различные подходы. Будем использовать для решения нашей задачи классический подход ГП, обобщенный алгоритм работы которого представлен на рис.3 Приведенный алгоритм относится к классу синхронных эволюционных алгоритмов, где мощность популяции на каждой итерации всегда поддерживается постоянной и переход к следующей итерации (поколению) «синхронизирован». Сначала обрабатываются все потомки предыдущего поколения, а затем происходит переход на следующую итерацию.
4.2Применение генетического програмирования для решения задачи
Аппарат ГП позволяет построить с помощью эволюционного алгоритма на основе обучающей выборки программу, которая будет строить продукционные правила, для классификации на два класса. В соответствии с постановкой задачи необходимо построить булеву функцию вида (11):
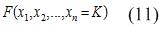
Значение K, равное единице, означает принадлежность к одному классу, а нулю – соответственно к другому.

(анимация: 10 кадров, 10 циклов повторения, размер 572x706, 145 КБ, 1 к/с)
Данные должны быть предварительно обработаны, основное назначение предобработки – преобразовать входное обучающее множество в булевозначный вектор. Далее в соответствии с приведенным выше алгоритмом определяются терминальное и функциональное множества, фитнесс–функция, значения параметров эволюционного алгоритма. Решением задачи будет булева функция (11), представленная в виде дерева.
Терминальное множество в данном случае состоит из входных переменных, которые после предобработки представляют собой булевозначный вектор.
Функциональное множество. Основными логическими операциями являются: ИЛИ, И, НЕ. Все эти операции всегда имеют один выход, но могут иметь разное количество входов. Так как первые две функции могут иметь два и более входа, а последняя только один, то для более удобной программной реализации выполним замену операции НЕ на следующие две: ИЛИ–НЕ и И–НЕ. Такая замена позволит унифицировать количество входов для всех операций (их будет всегда 2). Таким образом, функциональное множество составляют 4 логические функции ИЛИ, И, ИЛИ–НЕ и И–НЕ. Такой логический базис позволяет избавиться и от так называемых интронов (бесполезных участков кода), в данном случае ? от двойного отрицания (НЕ(НЕ(X))).
В качестве фитнесс–функции используется доля с правильно определенным классом (7).
Итак, в контексте нашей задачи ГП используется для получения классификационного дерева (пример структуры показан рис.4. Дереву на рис. 4 соответствует булева функция (12):
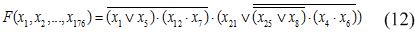
Обобщенный алгоритм получения таких деревьев и правил с помощью генетического программирования представлен на рис.(3).
Для получения классификационного дерева необходимо выполнить следующие этапы:
1. Установить параметры ГП.
2. Сгенерировать начальную популяцию. Популяция состоит из некоторого количества хромосом (особей). Каждая особь соответствует определенному дереву, которое представляет собой решение, например, как на рис.4. Особь (дерево) на начальном этапе генерируется случайным образом и состоит из функциональных и терминальных узлов.
3. По значению фитнесс–функции (7) оценить все особи, входящие в популяцию.
4. Выполнить генетические операторы.
5. Проверить условие останова. Если критерий останова выполнен, то перейти на шаг 6, иначе на шаг 3.
6. Выбрать лучшую особь (с максимальным значением фитнесс–функции), которая будет результатом работы ГП, а соответствующее ей дерево – решением поставленной задачи (классификационным деревом, выполняющим классификацию на два класса).
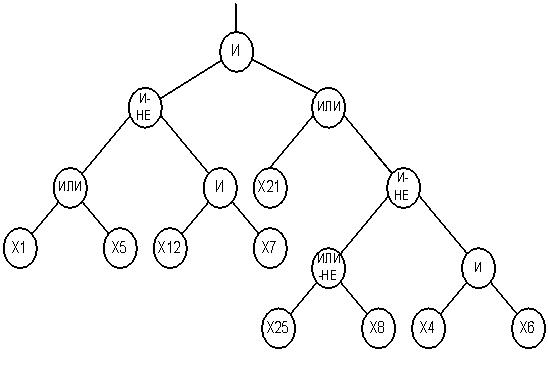
4.3 Генерация начальной популяции
На данном этапе происходит генерация начальной популяции в соответствии с заданными параметрами. Популяция состоит из набора деревьев, сгенерированных случайным образом.
Генерация каждого дерева происходит рекурсивно, начиная с генерации функционального узла и его аргументов. Для каждого дочернего узла (аргумента) случайным образом определяется, будет данный узел функциональным или терминальным, далее в соответствии с типом узла выбирается его значение из соответствующего терминального или функционального множества. Процесс выполняется по левой ветви до тех пор, пока не будет выбран дочерним терминальный узел. Затем генерируются правые ветви.
Предусмотрены следующие методы создания деревьев:
1. Полный. При генерации случайного дерева каждая ветвь имеет одинаковую (максимальную) глубину.
2. Растущий. При генерации случайного дерева каждая ветвь может иметь различную глубину, но не более чем заданная максимальная.
3. Комбинированный. Половина деревьев всей популяции генерируется полным методом, вторая половина – растущим.
1.Отбор родителей. Важнейшим фактором, который влияет на эффективность ГП, является оператор отбора. Слепое следование принципу «выживает сильнейший» может привести к сужению пространства области поиска решения и попаданию найденного решения в область локального экстремума фитнесс–функции. С другой стороны, достаточно слабый оператор отбора может привести к медленному росту качества популяции, что приведет к замедлению поиска решения. Кроме того, популяция при таком подходе может не только не улучшаться, но и ухудшаться.
Наиболее распространенные варианты отбора родителей:
– случайный равновероятностный;
– рангово–пропорциональный;
– отбор пропорционально значению фитнесс–функции;
– элитный отбор;
– отбор с вытеснением.
Из них использован отбор пропорционально значению фитнесс–функции, реализованный методом рулетки и турнира.
2.Кроссинговер. Для древообразной формы представления используются следующие три основных типа оператора кроссинговера (ОК):
– узловой кроссинговер;
– кроссинговер поддеревьев;
– смешанный;
Узловой оператор кроссинговера выполняется следующим образом:
– выбираются два дерева и узлы в этих деревьях. Так как узлы в деревьях могут быть разного типа, сначала необходимо убедиться, что выбранные узлы у родителей являются взаимозаменяемыми. Если тип узла во втором родителе отличен от типа узла первого родителя, то во втором родителе случайным образом выбирается другой узел, после чего опять выполняется проверка на предмет совместимости;
– производится обмен выбранных узлов.
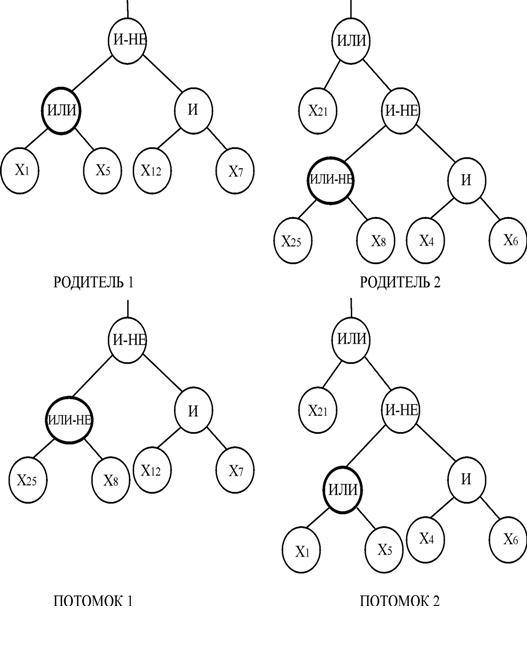
Пример узлового ОК показан на рис.5.
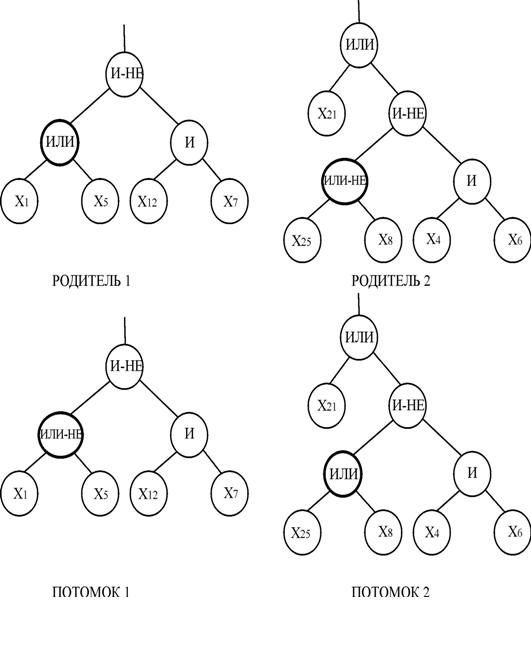
В кроссинговере поддеревьев родители обмениваются не самими узлами, а соответствующими им поддеревьями. Такой ОК выполняется следующим образом:
– выбираются родители и узлы в них. Далее необходимо убедиться, что выбранные узлы принадлежат одному типу (функциональному или терминальному). Если это условие не выполняется, то, как и в предыдущем случае, во втором дереве выбирается другой узел с последующей проверкой на взаимозаменяемость;
– производится обмен поддеревьев, которые соответствуют этим выбранным узлам. Вычисляется глубина дерева для каждого потомка. Если ожидаемый размер не превышает заданный порог, то потомки запоминаются.
Обмен поддеревьями возможен и в одном родителе. Пример ОК поддеревьев показан на рис. 6.
При смешанном операторе кроссинговера для одних особей выполняется узловой оператор кроссинговера, а для других – кроссинговер поддеревьев.
3.Мутация. Для деревьев применимы следующие операторы мутации (ОМ):
– узловая мутация;
– усекающая мутация;
– растущая мутация.
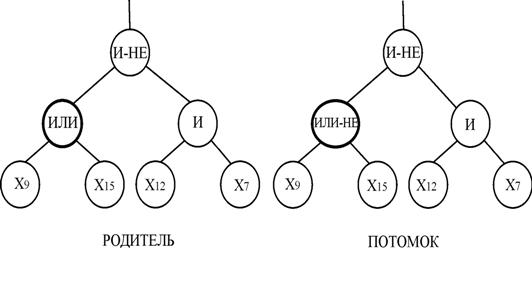
Узловой оператор мутации выполняется следующим образом:
– выбирается случайным образом узел, подлежащий мутации;
– определяется тип выбранного узла (функциональный или терминальный);
– случайно выбирается из множества, соответствующего типу выбранного узла, значение узла, отличное от рассматриваемого;
– заменяется исходное значение узла на выбранное.
Пример узлового оператора мутации показан на рис.7.
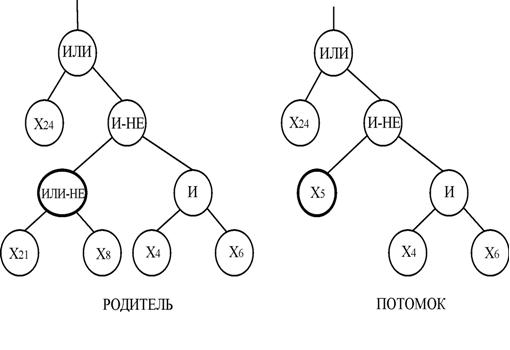
Усекающий оператор мутации производится так:
– случайным образом выбирается узел;
– случайным образом выбирается символ из заданного терминального множества;
– обрезается ветвь выбранного узла мутации;
– вместо обрезанной ветви ставится терминальный символ.
Пример усекающего оператора мутации показан на рис. 8.
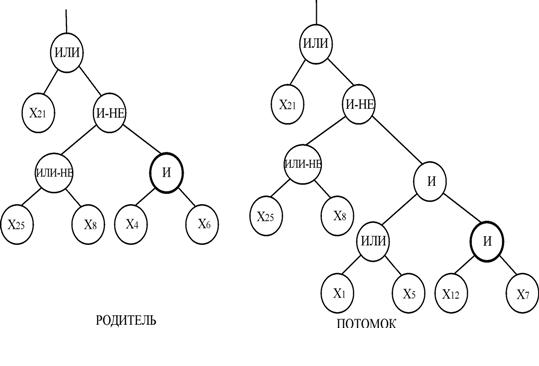
Растущий оператор мутации выполняется следующим образом:
– случайным образом определяется узел мутации;
– если узел не является терминальным, то необходимо отсечь ветви, которые исходят из него, иначе выбрать другой узел;
– вычислить глубину остатка дерева;
– вместо отсеченной ветви дерева вырастить случайным образом новую ветвь так, чтобы размер нового построенного дерева не превышал заданный порог.
Пример растущего оператора мутации показан на рис. 9. Это очень мощный оператор, обладающий большими возможностями.
4.Редукция. Оператор редукции выполняется с целью сохранения размера популяции. Типы оператора практически совпадают с типами оператора отбора родителей. Но процедуры редукции и отбора родителей разнесены по действию во времени и имеют разный смысл. Возможно выполнение следующих вариантов редукции:
– элитная стратегия;
– чистая замена;
– равномерная случайная замена (с указанием количества заменяемых особей в процентах).
В качестве критерия останова можно использовать указание определенного числа итераций или указание определенного числа повторения лучшего результата.
4.4 Применение генетического програмирования для получения правил
Не менее важно построить систему правил, которые облегчат интерпретацию результата. Для решения такой задачи предложен метод, основная идея которого заключается в способе кодирования особей для ГП. Как и ранее, особь представляет собой дерево, только теперь оно соответствует синтаксическому выражению, представляющему булеву функцию в дизъюнктивной нормальной форме (ДНФ), что полностью соответствует постановке задачи.
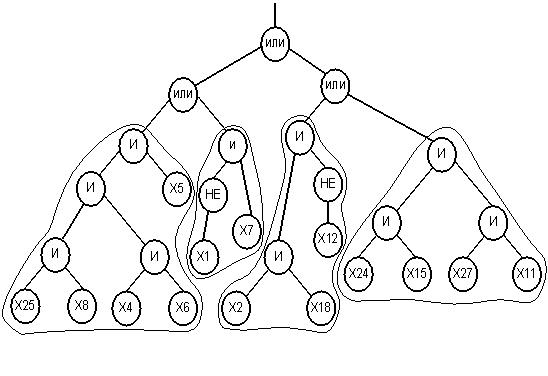
На рис. 10 представлен пример дерева, которому соответствует функция в дизъюнктивной нормальной форме. Такое кодирование особи для ГП значительно упрощает интерпретацию результата. Рассмотренное дерево состоит из 4 правил, и расшифровка для данного примера будет следующей:
ЕСЛИ выполняется правило 1 ИЛИ выполняется правило 2 ИЛИ выполняется правило 3 ИЛИ выполняется правило 4, ТО результат 1, ИНАЧЕ результат 2.
Выводы
Проведен анализ современных методов извлечения знаний. Показано, что методы машинного обучения на основе использования обучающих данных имеют преимущества по сравнению с другими математическими методами. Рассмотрены методы искусственного интеллекта на базе машинного обучения. Отмечено, что ГП имеет мощные возможности поиска закономерностей, рассмотрены параметры, влияющие на его эффективность, значения которых зависят от конкретной задачи.
Поставлена цель работы – автоматизировать процесс разработки продукционных правил для ЭС.
Для этого необходимо решить задачи:
1. Pазработать структуру ЭС.
2. Pазработать продукционные правила.
Для решения перечисленных задач выбраны следующие направления исследований:
1. Методы интеллектуального анализа данных с целью получения продукционных правил.
2. Принципы построения экспертных систем.
Выполнена математическая постановка задачи применительно к задаче классификации на два класса.
Список источников
-
Системы поддержки принятия решений / Интернет-ресурс. — Режим доступа: http://bourabai.kz/tpoi/dss.htm
-
Генетические алгоритмы / Интернет-ресурс. — Режим доступа: https://ru.wikipedia.org/wiki/
-
Генетические алгоритмы Т.В. Панченко / Интернет-ресурс. — Режим доступа: http://mathmod.aspu.ru/images/File/ebooks/GAfinal.pdf
-
Goldberg D.E. Genetic Algorithms in Search, Optimization and Machine Learning.-Addison-Wesley, reading,MA.-1989.
-
Koza J.R. Genetic Programming.Cambridge:MA:MIT Press,1992.
-
Рутковская Д., Пилинский М., Рутковский Л. Нейронные сети, генетические алгоритмы и нечеткие системы: Пер. с польск. И.Д. Рудинского. - М.: Горячая линия – Телеком, 2006. – 452 с. : ил.
-
Гомзин А., Коршунов А. Системы рекомендаций: обзор современных подходов // Препринт. Москва: Труды Института системного программирования РАН. 2012. 20 c.