Определение
Мета-поиск предназначен для выполнения запроса поиска в нескольких поисковых системах. Для выполнения базового метапоиска пользовательский запрос отправляется нескольким существующим поисковым системам с помощью метапоиска; когда результаты поиска, полученные из поисковых систем, принимаются метапоискателем, они объединяются в один ранжированный список, а объединенный список предоставляется пользователю. Ключевыми проблемами являются передача пользовательских запросов другим поисковым системам, правильно идентификация результатов, возвращенных из поисковых систем, и объединение результатов из разных источников поиска. Более сложные метапоиска позволяют выполнить выбор поисковой системы, то есть идентифицировать поисковые системы, наиболее подходящие для запроса, и отправить запрос только в эти поисковые системы. Чтобы определить подходящие поисковые системы для использования для запроса, необходимо оценить полезность каждой поисковой системы в отношении запроса на основе некоторой меры полезности.
Очерки истории
Самый ранний веб-механизм метапоиска — это, вероятно, система MetaCrawler [1], которая начала функционировать с июня 1995 года. Мотивациями для использования метапоиска являются: расширенный охват поиска, потому что метапоиск эффективно сочетает в себе охват всех поисковых систем, улучшенное удобство для пользователей, поскольку механизм метапоиска позволяет пользователям получать информацию из нескольких источников с одной отправкой запроса и лучшая эффективность поиска с более релевантными результатами. За последние двенадцать лет в Интернете были разработаны многие метапоисковые системы. Большинство из них построены на основе небольшого числа популярных общедоступных поисковых систем, но есть также метапоисковые системы, которые подключены к более специализированным поисковым системам, а некоторые из них подключены к более чем тысячам поисковых систем
Даже самые ранние мета-поисковые системы решали проблемы извлечения результатов поиска и слияния результатов. Слияние результатов является одним из наиболее фундаментальных компонентов метапоиска, и в результате он получил большое внимание в сообществах метапоиска и распространения информации, и был предложен широкий спектр решений для достижения эффективного слияния результатов. Поскольку различные поисковые системы могут индексировать другой набор веб-страниц, а некоторые поисковые системы лучше других для запросов в разных предметных областях, важно определить соответствующие поисковые системы для каждого пользовательского запроса. Важность выбора поисковой системы была реализована в начале мета-поисковых исследований, и для решения этой проблемы было предложено множество подходов. Обзор некоторых методов слияния результатов и поисковых систем можно найти в [2].
Большинство метапоисковых систем построены поверх других поисковых систем без явного сотрудничества с этими поисковыми системами. В результате для создания этих метапоисковых систем требуется программа соединения и программа извлечения для каждой поисковой системы компонента. Первый необходим для передачи запроса из механизма метапоиска в поисковую систему и получения результатов поиска, возвращаемых из поисковой системы, а последний используется для извлечения записей результатов поиска из результирующих страниц, возвращенных из поисковой системы. В то время как программы не могут быть трудными для производства опытным программистом, сохранение их достоверности может быть серьезной проблемой, поскольку они могут устареть, когда используемые поисковые системы изменят свои параметры подключения и/или формат отображения результатов. Кроме того, для приложений, которым необходимо подключаться к сотням или тысячам поисковых систем, для производства и поддержки этих программ может потребоваться много времени. В результате в последние годы технологии автоматической обертки получили много внимания. На рисунке 1 показана базовая архитектура типичной метапоисковой системы.
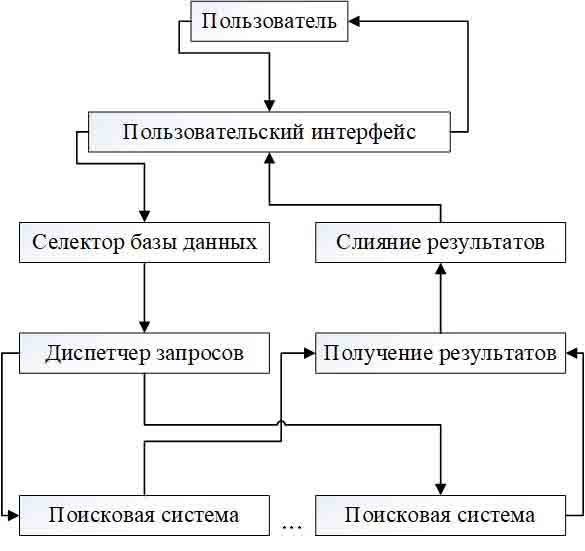
Рисунок 1 — Базовая архитектура типичной метапоисковой системы
Слияние результатов
Слияние результатов заключается в объединении результатов поиска, возвращенных из нескольких поисковых систем, в единый ранжированный список. Ранние поисковые системы часто связывали числовое соответствие с каждым полученным результатом поиска, а алгоритмы слияния результатов в то время были предназначены для нормализации
оценок, полученных из разных поисковых систем, в значения в пределах общего диапазона с целью сделать их более сопоставимыми. Нормализованные баллы будут использованы для повторного ранжирования всех результатов поиска. Когда совпадающие баллы недоступны, ряды результатов поиска от поисковых систем компонента могут быть агрегированы с использованием методов голосования. Нормализация нормализации и агрегирование рангов также могут принимать во внимание оценочную полезность каждой выбранной поисковой системы относительно запроса, которая получается на этапе выбора поисковой машины. Например, нормированный балл результата может быть взвешен с помощью оценки полезности поисковой системы, которая вернула результат. Это увеличивает вероятность того, что результаты из более полезных поисковых систем будут ранжированы выше.
Другим методом слияния результатов является загрузка всех возвращенных документов со своих локальных серверов и вычисление их совпадающих оценок с использованием общей функции сходства, используемой механизмом метапоиска. Затем результаты будут оцениваться на основе этих оценок. Например, метапоиска Inquirus использует этот подход [4]. Преимущество этого подхода состоит в том, что он обеспечивает единый способ вычисления ранжирования, поэтому приведенный ранжинг имеет больше смысла. Его основным недостатком является более длительное время отклика из-за задержки, вызванной загрузкой документов и их анализом на лету
. Большинство современных поисковых систем отображают заголовок каждого полученного результата вместе с кратким резюме, называемым фрагментом. Заголовок и фрагмент результата часто дают хорошие подсказки относительно того, относится ли результат к запросу. В результате в последнее время были предложены алгоритмы слияния результатов, основанные на заголовках и фрагментах. Когда заголовки и фрагменты используются для выполнения слияния, соответствующий результат каждого результата с запросом может быть вычислен на основе нескольких факторов, таких как количество уникальных терминов запроса, которые появляются в заголовке/фрагменте, а также близость условий запроса в заголовок/фрагмент.
Возможно, что один и тот же результат извлекается из нескольких поисковых систем. Такие результаты, скорее всего, будут иметь отношение к запросу, основанному на наблюдении, что различные алгоритмы ранжирования стремятся получить один и тот же набор релевантных результатов, но разные наборы нерелевантных результатов [6]. Чтобы помочь ранжировать эти результаты выше в объединенном списке, рейтинг баллов этих результатов из разных поисковых систем может быть добавлен для получения окончательного результата. Результаты поиска затем оцениваются в порядке убывания конечных результатов.
Выбор поисковой системы
Чтобы включить выбор поисковой системы, сначала необходимо собрать некоторую информацию, которая может представлять содержимое документов каждой поисковой системы. Такая информация для поисковой системы называется представителем поисковой системы. Представители всех поисковых систем, используемой метапоисковой системы, собираются заранее и хранятся с помощью метапоиска. При выборе поисковой системы для данного запроса поисковые системы ранжируются на основе того, насколько хорошо их представители соответствуют запросу. Были предложены различные методы выбора поисковой системы, и они часто используют представителей разных типов. Простой представитель поисковой системы может содержать только несколько выбранных ключевых слов или краткое описание. Этот тип представителя обычно создается вручную кем-то, знакомым с содержимым поисковой системы, но также может быть автоматически сгенерирован. Поскольку этот тип представителей предоставляет только общее описание содержимого поисковых систем, точность использования таких представителей для выбора поисковой системы обычно низкая. Более сложные представители состоят из подробной статистической информации для каждого термина в каждой поисковой системе. В [7] частота документа каждого термина в каждой поисковой системе используется для вычисления вариации валидности каждого из них, которая измеряет отклонение распределения термина запроса во всех поисковых системах компонентов, чтобы помочь ранжировать поисковые системы для каждого запроса. В [8] частота и частота приема каждого термина используются для представления каждой поисковой системы. В [9] скорректированный максимальный нормализованный вес каждого термина по всем документам в поисковой системе используется для представления поисковой системы.
Существуют также методы, которые создают представителей поисковой системы, изучая результаты поиска прошлых запросов. По существу, такой тип представителей - это знание, указывающее на прошлую работу поисковой системы по отношению к различным запросам. В поисковом алгоритме Savvy Search [12] для каждой поисковой системы S каждого компонента поддерживается вес каждого термина, который появился в предыдущих запросах. После оценки каждого запроса Q вес каждого члена в представителе, который появляется в Q, увеличивается или уменьшается в зависимости от того, возвращает ли S полезные результаты. Со временем, если термин для S имеет большой положительный (отрицательный) вес, тогда S считается хорошо отреагированным (слабо) на термин в прошлом. Для нового запроса, полученного с помощью механизма метапоиска, веса терминов запроса в представителях разных поисковых систем агрегируются для ранжирования поисковых систем. В метаданных ProFusion [13] учебные запросы используются, чтобы выяснить, насколько хорошо каждая поисковая система отвечает на запросы в разных категориях. Знания, полученные из каждой поисковой системы из обучающих запросов, используются для выбора поисковых систем для каждого пользовательского запроса, и знания постоянно обновляются на основе реакции пользователя на результат поиска, то есть, независимо от того, выбрал ли пользователь нужный ему результат.
Автоматическое подключение поисковой системы
Интерфейсы большинства поисковых систем реализованы с использованием тега формы HTML с текстовым полем запроса. В большинстве случаев тег формы поисковой системы содержит всю информацию, необходимую для соединения с поисковой системой, то есть отправки запросов и получения результатов поиска через программу. Такая информация включает имя и расположение программы, которая оценивает пользовательские запросы, метод сетевого подключения, и имя, связанное с текстовым полем запроса который используется для сохранения строки запроса. Тег формы каждого интерфейса поисковой системы обычно предварительно обрабатывается для извлечения информации, необходимой для подключения к программе, и извлеченная информация сохраняется в метапоиска. Существование Javascript в теге формы обычно затрудняет извлечение информации о соединении. После того, как метаисследователь получает запрос и определенную поисковую систему, среди возможных других поисковых систем, выбирается для оценки этого запроса, запрос присваивается имени текстового поля запроса поисковой системы и отправляется на сервер поисковой системы используя метод HTTP-запроса, поддерживаемый поисковой системой. После того как запрос оценивается поисковой системой, одна или несколько страниц результатов, содержащих результаты поиска, возвращаются в метапоиска для дальнейшей обработки.
Автоматическое извлечение результатов поиска
Страница результатов, возвращаемая поисковой системой, представляет собой динамически создаваемую HTML-страницу. В дополнение к записям результатов поиска для запроса страница результатов обычно также содержит некоторую нежелательную информацию/ссылки, такие как рекламные объявления и спонсируемые ссылки. Важно правильно извлекать записи результатов поиска на каждой странице результатов. Типичная запись результатов поиска соответствует извлеченному документу и обычно содержит URL-адрес и заголовок страницы, а также фрагмент документа. Поскольку различные поисковые системы создают страницы результатов в другом формате, для каждой поисковой системы необходимо создать отдельную программу извлечения результатов. В последние годы большое внимание уделяется созданию обертки для поисковых систем, и были предложены различные методы , Большинство из них анализируют исходные HTML-файлы на страницах результатов как текстовые строки или деревья тегов, чтобы найти повторяющиеся шаблоны записей записей поиска. Обзор, содержащий некоторые из ранних методов извлечения, можно найти в [14]. Некоторые более поздние работы также используют определенную визуальную информацию на страницах результатов, чтобы помочь идентифицировать шаблоны результатов (например, [15]).
Области примеение мета-поиска
Основное применение мета-поиска — поддержка поиска. Это может быть эффективный механизм поиска как поверхностных, так и глубоких веб-источников данных. Предоставляя общий интерфейс поиска по нескольким поисковым системам, метапоисковая система устраняет нагрузку пользователей на поиск нескольких источников по отдельности. Когда в метаисследовательском механизме используются определенные поисковые системы специальных компонентов, он может поддерживать интересные специальные приложения. Например, для большой организации со множеством филиалов, если каждая ветвь имеет свою собственную поисковую систему, то система метапоиска, соединяющая все поисковые системы отрасли, становится поисковой системой всей организации.
Будущие направления
Механизмы поиска компонентов, используемые механизмом метапоиска, могут в любое время изменять параметры соединения и формат отображения результатов. Эти изменения могут привести к тому, что уязвимые поисковые системы будут недоступны в метапоисковой системе, если соответствующие программы подключения и обертки для извлечения результата не будут изменены соответствующим образом. Как отслеживать изменения в поисковых системах и автоматически и своевременно производить соответствующие изменения в метапоискаторе — это область, которая требует неотложного внимания со стороны исследователей и разработчиков метапоиска.
Большинство современных метапоисковых систем используют лишь небольшое количество поисковых систем общего назначения. Создание крупномасштабных метопоисковых систем с использованием многочисленных специализированных поисковых систем — еще одна область, заслуживающая большего внимания. Нынешняя крупнейшая система метапоиска - новостная система под названием AllInOneNews. Эта система в настоящее время подключается к примерно 1800 поисковым системам новостей. Вызовы, возникающие в результате создания очень крупных метапоисковых двигателей, включают автоматическое создание и обслуживание поисковой системы высокого качества представителей, необходимых для эффективного и эффективного выбора поисковой системы, а также высокоавтоматизированных методов для добавления поисковых систем в метапоиска и адаптации к изменениям поисковых систем.
Список использованной литературы
- Selberg E. and Etzioni O. The MetaCrawler architecture for resource aggregation on the web. IEEE Expert, 12 (1):11–14, 1997.
- Meng W., Yu C., and Liu K. Building efficient and effective metasearch engines. ACM Comput. Surv., 34(1):48–89, 2002.
- Aslam J. and Montague M. Models for metasearch. In Proceedings of the ACM SIGIR Conference, New Orleans, LA, 2001, pp. 276–284.
- Lawrence S. and Lee Giles C. Inquirus, the NECi meta search engine. In Seventh International World Wide Web conference, Brisbane, Australia, 1998, pp. 95–105.
- Lu Y., Meng W., Shu L., Yu C., and Liu K. Evaluation of result merging strategies for metasearch engines. WISE Conference, New York, NY, 2005, pp. 53–66.
- Lee J-H. Combining multiple evidence from different properties of weighting schemes. In Proceedings of the ACM SIGIR Conference, Seattle, WA, 1995, pp. 180–188.
- Yuwono B. and Lee D. Server ranking for distributed text resource systems on the internet. DASFAA Conference, Melbourne, Australia, 1997, pp. 391–400.
- Callan J., Lu Z., and Croft W.B. Searching distributed collections with inference networks. In Proceedings of the ACM SIGIR Conference, Seattle, WA, 1995, pp. 21–28.
- Meng W., Wu Z., Yu C., and Li Z. A highly scalable and effective method for metasearch. ACM TOIS, 19(3):310–335, 2001.
- Yu C., Liu K., Meng W., Wu Z., and Rishe N. A methodology to retrieve text documents from multiple databases. IEEE TKDE, 14(6):1347–1361, 2002.
- Callan J., Connell M., and Du A. Automatic discovery of language models for text databases. In Proceedings of the ACM SIGMOD Conference, Philadelphia, PA, 1999, pp. 479–490.
- Dreilinger D. and Howe A. Experiences with selecting search engines using metasearch. ACM Trans. Inf. Syst., 15 (3):195–222, 1997.
- Fan Y. and Gauch S. Adaptive agents for information gathering from multiple, distributed information sources. AAAI Symposium on Intelligent Agents in Cyberspace, Stanford University, 1999, pp. 40–46.
- Laender A.A., Ribeiro-Neto B., da Silva A., and Teixeira J. A brief survey of web data extraction tools. ACM SIGMOD Rec., 31 (2):84–93, 2002.
- Zhao H., Meng W., Wu Z., Raghavan V., and Yu C. Fully automatic wrapper generation for search engines. World Wide Web Conference, Chiba, Japan, 2005, pp. 66–75.
