Аннотация
Серёженко О.А., Коломойцева И.А. Применение мета-поиска к решению задач поиска цитат. В данной статье описаны проблема поиска текста в сети Интернет, в частности цитат, инструментарий мета-поисковых систем на основе примеров Exactus и Dogpile. Также рассмотрены и описаны общая схема обработки естественно-языковых текстов, реляционно-ситуационный и латентно-семантический методы анализа текста. Как результат анализа представлена структура мета-поисковой системы цитат.
Введение
На сегодняшний день насущной проблемой для миллионов людей каждый день является проблема поиска информации в Интернете. Последние годы прослеживается явная тенденция к появлению узкоспециализированных сервисов поиска: например, yandex-блоги, yandex-картинки, yandex-новости, google-maps, google-video и т. д. Разделение задачи поиска информации на подзадачи позволяет внедрять новые методы поиска и значительно повышать его эффективность. Но, несмотря на это, на сегодняшний день существует крайне мало решений, обеспечивающих поиск в Интернете именно текстов.
Если текст не такой распространенный, и/или в известных пользователю сетевых библиотеках его найти не удалось, то он вынужден воспользоваться услугами поисковых систем. Пользователь вводит мета-текст в интерфейс поисковой системы (далее ИПС), и получает в ответ несколько сотен или тысяч ссылок, часть из которых ведет на сайты магазинов, в которых можно купить соответствующую книгу, часть этих ссылок введет в библиографию и/или упоминание, часть этих ссылок просто информационный шум, и, наконец, часть ссылок может ввести к самому тексту. Даже с таким довольно приблизительным разбиением результатов, очевидно, что задача обработки полученного результата возлагается на пользователя. Специализированные же ИПС отсекают значительную часть заведомо нерелевантных результатов, поэтому создание специализированных ИПС под конкретную задачу является более эффективным решением.
Целью данной работы является анализ существующих мета-поисковых систем, методов синтаксического и семантического разборов естественно-языковых текстов. Также на основе этого анализа необходимо определить структурную модель мета-поисковой системы цитат.
Мета-поисковая система
Мета-поисковая система – это поисковый инструмент, посылающий запрос пользователя одновременно на несколько поисковых систем, каталогов [1].
Принцип работы мета-поисковика заключается в следующем: запрос пользователя преобразуется в запросы, отформатированные синтаксически и логически в конструкции, оптимальные для каждого отдельного, традиционного
поисковика, т. е. из одного запроса мета-поисковый механизм делает ряд запросов, которые адресуются нескольким обычным
поискам [2]. Собрав результаты, мета-поисковая система удаляет дублированные ссылки и, в соответствии со своим алгоритмом, объединяет результаты в общем списке.
В рамках одной мета-поисковой системы можно осуществлять поиск информации различного типа. Мета-поисковые системы не предназначены для индексирования и накопления данных, их назначение – чистый поиск и обработка результатов поиска.
Мета-поисковые системы позволяют взглянуть на результаты поиска по ключевым словам, подобрать новые ключевые слова с помощью облаков связанных понятий. Можно однозначно рекомендовать мета-поисковые системы для обзорного поиска. Обзорный поиск полезен при первом подходе к изучению материалов по новой для пользователя теме или же необходим для включения в поле зрения как можно большего числа интернет-источников. Даже одно ключевое слово может в некоторых случаях дать полезный, наводящий результат [3].
Примерами мета-поиска могут служить такие системы, как http://exactus.ru, http://dogpile.com, http://info.com и т. д.
Интеллектуальная поисковая система Exactus
Интеллектуальная поисковая система Exactus позволяет искать документы в сети Интернет. Система Exactus функционирует на высокопроизводительной кластерной установке под управлением операционной системы Unix. Архитектура Exactus построена по модульному расширяемому принципу с возможностью наращивания мощности кластерной установки. Exactus является кросс-платформенной системой, реализованной на языке C++, что позволяет запускать ее на широком спектре Unix-подобных операционных систем [4].
Отличительные особенности системы Exactus:
- полный лингвистический анализ текстов;
- сравнение текстов по семантике;
- нечувствительность к перефразированию – перестановке слов и предложений местами, замене слов и словосочетаний синонимами.
Ознакомиться с интеллектуальной системой Exactus можно по адресу http://exactus.ru. На рисунке 1 показан пример работы с вышеуказанной интеллектуальной системой.
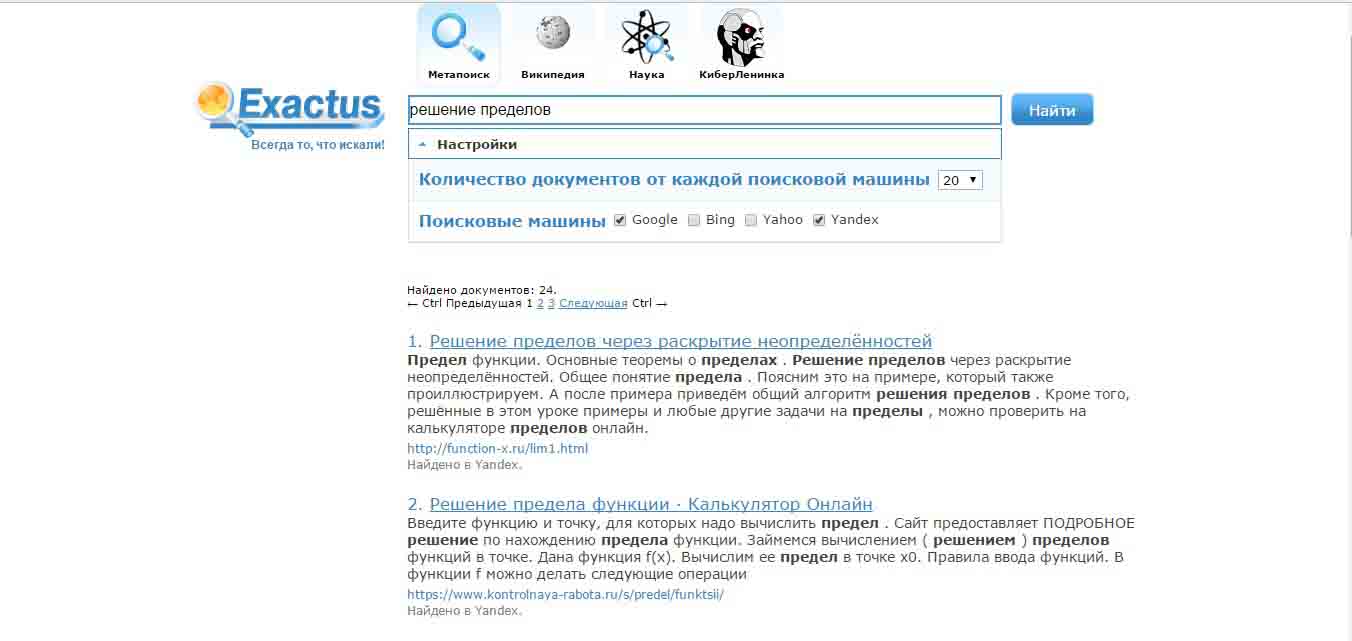
Рисунок 1 – Пример работы с интеллектуальной системой Exatcus
Интеллектуальная поисковая система Dogpile
Мета-поисковая система Dogpile использует для поиска несколько средств, среди которых: поисковые машины, веб-каталоги, расширенные средства поиска. Система позволяет искать сайты, изображения, аудио– и видеофайлы, а также проводить поиск в новостях. Есть специальные вкладки yellow page
(жёлтые страницы
) и white pages
(белые страницы
). В разделе yellow pages
проводится поиск компаний по их названию, в запросе можно задать отрасль или вид бизнеса, а также город и штат. Раздел white pages
предназначен для поиска людей по указанным имени, фамилии, городу и штату. Дополнительные возможности, предоставляемые Dogpile: поиск пути между двумя указанными городами, поиск электронного адреса и просмотр карты.
Доступна сортировка полученных результатов по релевантности или поисковому средству. В левой части окна отображается список предыдущих запросов. В Dogpile не предусмотрена кластеризация результатов, вместо этого система формирует список скорректированных запросов, содержащих данное поисковое слово.
Отличительные особенности системы Dogpile:
чистый
интерфейс, приятный дизайн;- наличие функции контроля содержимого;
- наличие 3 варианта фильтрации: отсутствие фильтрации, отбрасывание наиболее нескромных страниц и, наконец, максимальная фильтрация, после которой, по идее, должны остаться только безупречно благопристойные ссылки;
- возможность настройки способа сортировки результатов поиска изображений, новостей и медиа-файлов;
- организация реальных акций в помощь животным.
Ознакомиться с интеллектуальной системой Dogpile можно по адресу http://dogpile.com. На рисунках 2-3 показаны главная страница вышеуказанной интеллектуальной системой и результат её работы соответственно.

Рисунок 2 – Главная страница интеллектуальной системы Dogpile
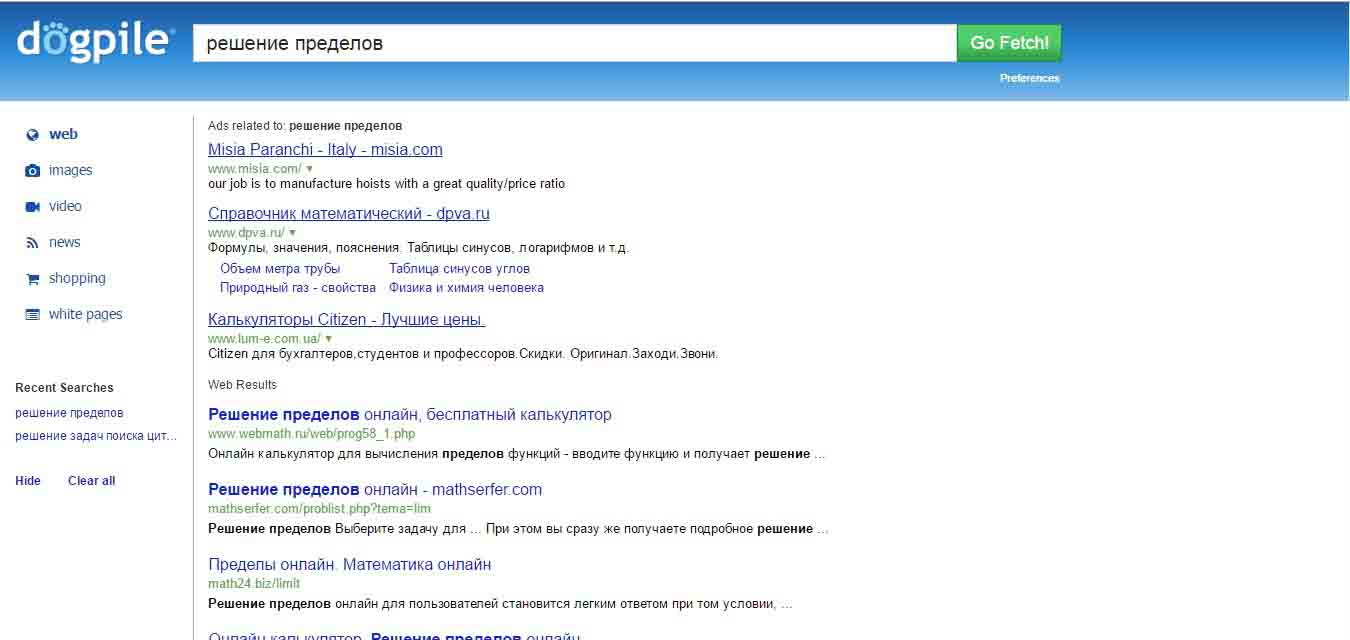
Рисунок 3 – Результат работы интеллектуальной системы Dogpile
Общая схема обработки естественно-языковых текстов
Общая схема обработки текстов инвариантна по отношению к выбору естественного языка. Независимо от того, на каком языке написан исходный текст, его анализ проходит одни и те же стадии. Первые две стадии (разбиение текста на отдельные предложения и на слова) практически одинаковы для большинства естественных языков. Единственное, где могут проявиться специфичные для выбранного языка черты, — это обработка сокращений слов и обработка знаков препинания.
Последующие две стадии (определение характеристик отдельных слов и синтаксический анализ), напротив, сильно зависят от выбранного естественного языка. Последняя стадия (семантический анализ) также мало зависит от выбранного языка, но это проявляется только в общих подходах к проведению анализа.
Семантический анализ основывается на результатах работы предыдущих фаз обработки текста, которые всегда специфичны для конкретного языка. Следовательно, способы представления их результатов тоже могут сильно варьироваться, оказывая большое влияние на реализацию методов семантического анализа. Результаты анализа, произведенного на ранних стадиях, могут быть многозначны: для выходных параметров указывается не одно, а сразу несколько возможных значений. В таких случаях последующие стадии должны выбирать наиболее вероятные значения результатов ранних стадий анализа и уже на их основе проводить дальнейший анализ текста [5].
На рисунке 4 показана общая схема обработки текстов.
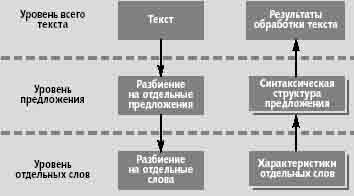
Рисунок 4 — Схема обработки текстов
Реляционно-ситуационный метод анализа текста
Коммуникативная грамматика русского языка отвергает традиционное противопоставление синтаксиса семантике, которое предполагает разделение знаний о законах формирования связной речи на два уровня: знания о форме (синтаксис) и знания о значении (семантика). Главная идея коммуникативной грамматики заключается в том, что синтаксис должен изучать осмысленную речь, а синтаксические правила должны учитывать категориальные значения слов, чтобы иметь возможность определять обобщенный смысл любой синтаксической конструкции — от слова до словосочетания и простого предложения [6, 7].
Формируя и изучая связную речь, синтаксис имеет дело, прежде всего, с осмысленными единицами, несущими свой не индивидуально лексический, а обобщенный, категориальный смысл в конструкциях разной степени сложности. В основе коммуникативной грамматики лежит понятие синтаксемы, как минимальной единицы смысла высказывания. Синтаксемой называется минимальная синтактико-семантическая единица языка, несущая обобщенный категориальный смысл и характеризующаяся взаимодействием морфологических, семантических и функциональных признаков.
Синтаксемой называется минимальная синтактико-семантическая единица языка, несущая обобщенный категориальный смысл и характеризующаяся взаимодействием морфологических, семантических и функциональных признаков.
Несмотря на сложность описания, синтаксема является интуитивно понятной конструкцией для любого носителя языка и используется им повсеместно для построения различного рода высказываний. Примеры значений синтаксем:
- аблатив — исходная точка движения (выйти из комнаты);
- агенс — производитель действия (закон подписан президентом);
- адресат — лицо или реже предмет, к которому обращено информативное, донативное или эмотивное действие (обратиться к президенту);
- дестинатив — назначение действия или предмета (выступать в защиту животных; поехать на лечение);
- транзитив — компонент со значением пути движения (Корейский лидер проехал почти по всей России на поезде);
- инструментив — орудие действия (Что написано пером, того не вырубишь топором);
- каузат — объект каузирующего воздействия (способствовать вступлению России в ВТО);
- каузатор — воздействующий фактор (от ученья нравам лишь вред).
Основной задачей реляционно-ситуационного анализа является выявление значений синтаксем и семантических связей между ними. Главную роль здесь играют глаголы, имеющие, как правило, центральное положение в семантической структуре предложения и оказывающие решающее влияние на именные словосочетания и предложения. Сведения о синтаксической сочетаемости каждого глагола с синтаксемами заносятся лингвистами в словарь предикатных слов. Кроме того, в словаре имеются указания на то, как могут быть связаны между собой именные синтаксемы. Набор заносимых в словарь бинарных связей на множестве ролей также является специфичным для каждого типа предикатных слов и определяется априорно [8].
Приведем пример правил для синтаксем родительного падежа: если встречается синтаксема в падеже <родительный> с предлогом <для>, имеющая категориальный класс <личное>, а до неё встречается синтаксема в падеже <именительный>, имеющая категориальный класс <предметное>, то полагается, что первая синтаксема имеет значение <дестинатив - назначение предмета или действия>.
Латентно-семантический метод анализа текста
Латентно-семантический анализ (далее ЛСА) используется для выявления латентных (скрытых) ассоциативно-семантических связей между термами путем сокращения факторного пространства термы-на-документы. Термами могут выступать как слова, так и их комбинации – в идеале: наборы тематически однородных текстов, либо просто любой желательно объемный текст (несколько млн. словоформ), произвольно разбитый на куски, например, абзацы.
Основная идея латентно-семантического анализа состоит в следующем: если в исходном вероятностном пространстве, состоящим из векторов слов (вектором могут выступать предложение, абзац, документ и т.п.), между двумя любыми словами из двух разных векторов может не наблюдаться никакой зависимости, то после некоторого алгебраического преобразования данного векторного пространства эта зависимость может появиться, причем величина этой зависимости будет определять силу ассоциативно-семантической связи между этими двумя словами.
Например, рассмотрим два простых сообщения из разных источников:
1-ый источник реклама: Этот замечательный ноутбук XXX имеет мощный аккумулятор!
2-ой источник блоги: Кстати, у устройства XXX неплохая батарейка
.
Поскольку лексика блогов и рекламы не сильно пересекается, то слова аккумулятор
и батарейка
получат разный вес, скажем, первое маленький, а второе, наоборот, большой. Тогда эти сообщения можно объединить только на основе названия XXX
(сильный критерий), но подробности про батарею (назовем его слабым критерием) пропадет.
Однако, если мы проведем ЛСА, то веса у аккумулятора
и батарейки
выровняются, и эти сообщения можно будет объединить на основе хотя и слабого критерия, но наиболее важного для товара критерия.
Таким образом, ЛСА стягивает
вместе слова разные по написанию, но близкие по смыслу.
Очевидным недостатком ЛСА является ненормальность вероятностного распределения слов в любом естественном языке. Но эту проблему можно решить сглаживанием выборки (например, применив фонетические слова: распределение становится более нормальным
).
Другим, менее очевидным недостаткам ЛСА (и ему подобных методов) применительно к обработке неструктурированной информации можно отнести туманность
самого метода и интерпретации результата, не говоря уже о проблеме сбалансированности обучающего текста.
Интерпретируемость результатов ЛСА также затруднительна: человек еще может понять, что за тематику будет содержать текст, полученный в результате анализа, а вот машине не понять тематику без привлечения большого числа хороших и разных тезаурусов.
Таким образом, несмотря на трудоемкость и непрозрачность ЛСА, он может успешно применяться для разного рада задач, где важно поймать семантику сообщения, обобщить или расширить смыслы
поискового запроса [9].
Применение мета-поисковой системы в решении задачи поиска цитат
Поиск цитат — это поиск текста по заданному фрагменту.
Пользователь, задавший такой запрос, вероятнее всего, хочет найти происхождение цитаты — то есть либо увидеть произведение, из которого она взята (в таком случае на найденной странице будет представлен достаточно широкий оригинальный контекст цитаты, что и проверяется анализатором), либо хотя бы узнать автора и название этого произведения.
Рассмотрим эту проблему подробнее, а также введем некоторые ограничения и определения.
- Под поиском текстов в Интернете понимается ситуация, когда пользователю известно название произведения и/или его автор (имя-фамилия), а в качестве результата пользователь хочет получить полный текст этого произведения в электронном виде.
Текстом
будем считать законченное языковое произведение, характеризующееся наличием автора и названия.Мета-текстом
будем считать любую непустую комбинацию имени-фамилии автора и названия текста.Адресом
текста будет считаться веб-адрес, по которому это текст доступен в Интернете. Если такого адреса не существует, то будем считать адрес этого текста "нулевым".- Для примеров будем использовать литературные произведения на русском языке, хотя методы поиска применимы к текстам любого жанра и тематики (технические, публицистические и др.).
Стандартным решением проблемы поиска текстов в Интернете является создание систем, индексирующих найденные в Интернете тексты. По сути дела, данные системы являются базами данных, в которых содержатся ссылки на тексты в Интернете. В таких системах пользователь вводит мета-текст в стандартный поисковый интерфейс и, если данный текст проиндексирован, то пользователь получает адрес текста, по которому данный текст был найден в процессе индексирования. Данные системы обладают, как минимум, одним серьезным недостатком: при таком построении текст привязывается к определенному адресу в Интернете. Но Интернет-ресурсы имеет свойство закрываться, переезжать с одного домена на другой, а расположенные на них документы часто меняют название, удаляются, реорганизуются. Следовательно, проиндексированные адреса в любой момент могут перестать быть актуальными. Второй недостаток подобного метода состоит в охвате представленных адресов. Ручное пополнение баз данных не гарантирует попадание всех адресов текста, автоматическое же индексирование по адресу
серьезно повышает уровень информационного шума.
Существует иной способ поиска текстов в Интернете, назовем его поиском по цитате или цитатным поиском. Основная идея заключается в том, что ИПС общего назначения предоставляют возможность в качестве запроса указывать целую фразу, и результатом такого запроса будут только те документы, в которых присутствует эта фраза целиком с сохранением порядка слов. Таким образом, если пользователю вместо мета-текста известна цитата из текста, то дальнейший процесс поиска текста сокращается до ввода этой цитаты в кавычках в Google или Yandex, и поисковик либо выдает ссылки непосредственно на текст, либо однозначно сигнализирует о том, что такого текста в Интернете нет. Очевидным образом, мы сталкиваемся с двумя проблемами: предварительное извлечение цитат из текстов и релевантность выдаваемых ссылок. Первая проблема решается построением базы данных цитат, которые будут выдаваться в обмен на мета-текст. Вторая же проблема связана с понятием целостности текста
(мы можем попасть
не в целый текст, а в часть текста, например, в случае цитирования текста или ознакомительной страницы) и минимальной релевантной цитаты
(есть вероятность, что цитата может встретиться в нескольких различных текстах). Обе эти проблемы активно изучаются и решаются авторами. Процесс поиска текстов в Интернете можно разбить на два этапа: пользователь должен по мета-тексту получить цитату, затем по полученной цитате отыскивается полный текст. Таким образом, для эффективного разрешения проблемы поиска текстов в Интернете необходимо создать специализированную ИПС, ядром которой будет база цитат, предварительно извлеченных из текстов. Эта система должна работать в качестве посредника между пользователем и ИПС общего назначения.
Мета-поисковая система поиска цитат будет включать несколько этапов.
- Пользователь делает запрос с цитатой.
- Система проводит синтаксический анализ запроса.
- Результаты синтаксического анализа попадают в блок семантического анализа.
- На основе результатов синтаксического и семантического анализа, используя словари ассоциаций, синонимов, система генерирует несколько запросов, являющихся вариациями исходного.
- Система посылает полученные запросы стандартным поисковым системам, например, google, yandex.
- Система анализирует результат работы поисковиков, выбирая самые подходящие источники цитат, и выводит их на экран пользователю.
На рисунке 5 показана структурная схема алгоритма поиска цитат.
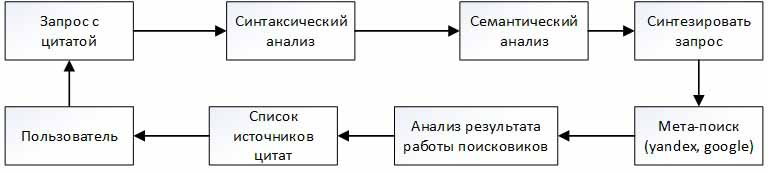
Рисунок 5 — Структурная схема алгоритма поиска цитат
Выводы
В ходе написании статьи были проанализированы:
- проблемы поиска цитат в сети Интернет;
- инструментарии существующих мета-поисковых систем, приведены их характеристики;
- существующие методы обработки естественно-языковых текстов.
Также была составлена схема собственного алгоритма поиска цитат по его фрагментарному заданию.
Список использованной литературы
- Мета-поисковые системы — [Электронный ресурс]. — Режим доступа: http://catalysis.ru/link/index.php?ID=12&SECTION_ID=54
- Мета-поисковые системы — [Электронный ресурс]. — Режим доступа: http://www.vsepoisk.ru/2009/07/blog-post_23.html
- Метапоисковые системы: принципы работы, опыты кластеризации поисковых результатов — [Электронный ресурс]. — Режим доступа: http://life-prog.ru/2_10898_metapoiskovie-sistemi-printsipi-raboti-opiti-klasterizatsii-poiskovih-rezultatov.html
- Поисковая система Exactus — [Электронный ресурс]. — Режим доступа: http://www.isa.ru/index.php?option=com_content&view=article&id=55%3Aexactus&catid=68%3Aon-line-&lang=ru
- Обработка текстов на естественном языке — [Электронный ресурс]. — Режим доступа: http://www.osp.ru/os/2003/12/183694/
- Золотова Г.А., Онипенко Н.К., Сидорова М.Ю. Коммуникативная грамматика русского языка. Институт русского языка РАН им. В. В. Виноградова, М. 2004 544 с.
- Золотова Г.А. Синтаксический словарь: Репертуар элементарных единиц русского синтаксиса. – М.: Наука, 1988 – 440 с.
- Г.С. Осипов, И.В. Смирнов, И.А. Тихомиров. Реляционно-ситуационный метод поиска и анализа текстов и его приложения. Отделения нанотехнологий и информационных технологий Российской академии наук, 2008, № 2, с. 4-6.
- Латентно-семантический анализ и искусственный интеллект (ЛСА и ИИ) — [Электронный ресурс]. — Режим доступа: https://geektimes.ru/post/230075/
