Оптимизация реализаций протоколов, основанных на UDP
Авторы: Юнхонг Гу, Роберт Л.Гроссман
Источник: http://udt.sourceforge.net/doc/pfldnet2005-v8.pdf
Перевод: А.В.Сирант
Данный перевод является неполным: переведены первые 2 раздела из 5
Из-за низкой производительности стандартного TCP при передаче данных на дальние расстоянияна через высокоскоростные магистральные сети и практических трудностей при развертывании различных вариантов протоколов ядра TCP, транспортные протоколы на основе протокола UDP часто используются для массовой передачи данных. Однако, написание транспортного протоколп с нуля - нелегкая работа. Одна из сложностей-достижение эффективности в реализации на уровне приложения. В статье анализируются характеристики производительности протокола UDP и описаны некоторые приемы оптимизации, которые могут быть полезны в большинстве реализаций протоколов, основанных на UDP, включая обработку памяти, способы подтверждения доставки пакетов, обработка потерь, синхронизация и самосинхронизация, и ввод-вывод данных в UDP. Основываясь на этих принципах оптимизации, мы создали открытый фреймворк протокола (Composable UDT), который использует обратные вызовы для обработки пользовательских обработчиков событий. Этот фреймворк может сэкономить значительное время для сетевых исследователей и разработчиков.
1 Введение
Transmission Control Protocol (TCP) успешно используется в течение многих десятилетий. Но, как бы то ни было, недавно было показано, что TCP имеет некоторые недостатки в производительности при передаче по широкополосным высокоскоростным сетям. Алгоритм контроля перегрузки сети на основе алгоритма AIMD (additive increase/multiplicative decrease), который используется в протоколе TCP, довольно плох в обнаружении доступной пропускной способности и восстановлении данных при потере пакетов в сетях с высоким произведением пропускной способности на задержку [1].
Исследователи компьютерных сетей работали над новыми транспортными протоколами и алгоритмами управления перегрузками для поддержки высокоскоростных сетей следующего поколения. Многие работы, включая варианты TCP протокола (FAST [2], BiC [3], Scalable [4], и HighSpeed [5]) и XCP [6], показали более высокую производительность при моделировании и в нескольких ограниченных сетевых экспериментах. Однако, практическое применение этих протоколов в реальных условиях по-прежнему весьма ограничено из-за трудностей с реализацией и установкой. Люди, которым требуется передача больших объемов данных (например, в распределенных вычислениях), как правило, обращаются к применению решений на уровне приложений, среди которых очень популярны протоколы на основе UDP, например, SABUL [7], UDT [8], Tsunami [9], RBUDP [10], FOBS [11], и GTP [12].
Протоколы на основе UDP обеспечивают гораздо лучшую переносимость и просты в установке. Однако, хотя реализация протоколов уровня пользователя требует меньше времени для тестирования и отладки, чем реализация в ядре, трудно сделать их такими же эффективными. Поскольку реализации на уровне пользователя не могут изменять код ядра, могут существовать дополнительные операции переключения контекста и копирования памяти. При высокой скорости передачи данных эти операции очень чувствительны к использованию ЦП и производительности протокола.
В данной работе мы представляем нашу работу по оптимизации эффективности реализации протоколов на основе UDP и показываем, что с помощью этих идей возможно реализовать эффективные и практические компонуемые структуры для построения протоколов на основе UDP. Например, наш фреймворк Composable UDT, который базируется на реализации UDT(UDP-based Data Transfer library) [8], способен поддерживать различные алгоритмы управления заторами в сети, которые содержатся в высокоскоростных вариантах протокола TCP [2, 3, 4, 5], или агрессивное проталкивание
(blasting) пакетов как в RBUDP [5].
Преимущества Composable UDT включают в себя: 1) новые протоколы на основе UDP можно быстро прототипировать и тестировать; 2) различные подходы к управлению перегрузками сети могут быть легко сопоставлены экспериментально; и 3) могут быть сравнительно легко разработаны специальные протоколы на основе UDP, ориентированные на любое приложение. Например, с помощью этого фреймворка могут быть разработаны специальные протоколы для распределенных вычислений с интенсивным использованием данных или приложений потоковой передачи мультимедиа.
Основной недостаток заключается в дополнительных накладных расходах самого фреймворка, который добавляет дополнительные накладные расходы протокола прикладного уровня по сравнению с протоколом уровня ядра. Для достижения высокой производительности, мы руководствовались двумя принципами:
Не должно быть прерываний в использовании ЦП, особенно на стороне приема данных. Прерывания в использовании ЦП можут привести к тому, что входящие данные не будут обрабатываться вовремя и, таким образом, будут удалены конечной системой. Это может причинить серьезный ущерб от алгоритмов управления перегрузкой на основе потери пакетов, таких как алгоритм AIMD в TCP, в котором обычно требуется очень длительное время, чтобы восстановить пакет после потери при передачи через сети на дальние расстояния.
Общая загрузка ЦП должна быть как можно меньше. Плохая реализация может помешать приложениям использовать максимальную доступную пропускную способность (поскольку сначала используется ЦП). Кроме того, другие операции по обработке данных, которые также требуют значительного времени центрального процессора, часто сосуществуют с передачей данных.
Статья организована следующим образом. Сначала мы проанализируем производительность UDP в разных системах в разделе 2. В разделе 3 мы опишем, как оптимизировать реализацию двух принципов, описанных выше. В разделе 4 представлен составной фреймворк, который предоставляет оптимизированные компоненты протокола, которые можно настроить непосредственно для новых протоколов. Статья заключена в разделе 5.
2 Характеристики производительности UDP
Хорошее экспериментальное понимание эффективности UDP имеет решающее значение для реализации двух вышеперечисленных принципов. В этом разделе мы проводим несколько экспериментов по проверке использования ЦП протоколом UDP, задержки конечных систем и влияния размера пакетов и буфера на скорость передачи. Это формирует основу некоторых наших схем оптимизации в следующем разделе.
Эксперименты проводились на пяти различных системах (табл. 1). Все они были подключены по крайней мере к одной машине с той же конфигурацией через сеть с пропускной способностью не меньше скорости сетевого адаптера. Значения MTU на экспериментальных стендах составляет 1500 байт.
| Имя | ЦП | Память | Сетевой адаптер | ОС |
|---|---|---|---|---|
| onno | Dual Itanium2 1.5GHz | 8 GB | 10 GbE | Linux 2.6.0 |
| sara77 | Dual Xeon 2.4GHz | 2 GB | 1 GbE | Linux 2.4.18 |
| ncdm171 | Dual PowerPC G4 1GHz | 2 GB | 1 GbE | Mac OS X |
| win91 | Dual Xeon 2.4GHz | 2 GB | 1 GbE | Windows XP Professional |
| ncdm87 | Dual Opteron 2.4GHz | 4 GB | 1 GbE | Linux 2.6.8 |
Мы зафиксировали размер пакета UDP на уровне 1500 байт (измерялся на уровне IP) и буфер сокета UDP на уровне 1 МБ, и записали загрузку ЦП и задержку конечной системы. Для сравнения, для TCP также перечислены те же измерения. Результаты приведены в таблице 2. Использование ЦП измеряется в МГц/Мбит/с, что является произведением частоты ЦП и процентов использования ЦП на единицу скорости передачи данных по сети. Эксперимент проводился в локальных сетях. (Здесь частота процессора-это совокупная частота всех процессоров, используемых тестируемым приложением. Количество процессоров может быть 0.5 в некоторых системах, где используется технология Hyper-Threading).
| Имя | UDP | TCP | ||||
|---|---|---|---|---|---|---|
| Исп. ЦП (МГц/Mbps) | Задержка (мс) | Исп. ЦП (МГц/Mbps) | Задержка (мс) | |||
| Отправка | Получение | Отправка | Получение | |||
| onno | 0.22 | 0.35 | 0.062 | 0.23 | 0.50 | 0.068 |
| sara77 | 0.40 | 0.45 | 0.070 | 0.51 | 0.51 | 0.068 |
| ncdm171 | 1.22 | 1.45 | 0.202 | 2.22 | 2.73 | 0.245 |
| win91 | 1.03 | 1.09 | 0.203 | 1.14 | 1.28 | 0.302 |
| ncdm87 | 0.26 | 0.40 | 0.065 | 0.25 | 0.56 | 0.087 |
Чтобы исключить влияние ошибки RTT на результат, мы используем локальные сетевые подключения с очень маленькими значениями RTT; в противном случае большие значения RTT могут ухудшить точность относительно небольших задержек конечных систем. Значения задержки, перечисленные в таблице 2, являются только задержкой, вызванной конечной системой, без задержек сети.
Результаты эксперимента представляют собой средние значения 100 запусков.
В таблице 2 показано, что UDP имеет меньшую загрузку ЦП и конечную задержку системы, чем TCP, главным образом из-за меньших затрат на обработку. Это значит, что при эффективной оптимизации, реализации протоколов на основе UDP могут иметь такую же производительность как и реализация протокола TCP на уровне ядра.
Мы провели дополнительные эксперименты, изменив два параметра: 1) буфер сокета UDP и 2) размер пакета, чтобы выяснить их влияние на производительность. Результат между sara77 и другой локальной машиной можно найти на рисунках 1 и 2. В эксперименте мы увеличили скорость передачи по UDP, ограничив уровень потерь пакетов ниже 0,1%.
На рисунке 1 показано, что размер буфера сокета с принимающей стороны является решающим фактором, связанным с пропускной способностью. Он должен быть достаточно большим, чтобы достичь оптимальной пропускной способности, но после оптимального значения большие размеры буфера не помогают. Между тем, буфер стороны отправителя должен быть значительно меньше буфера стороны получателя.
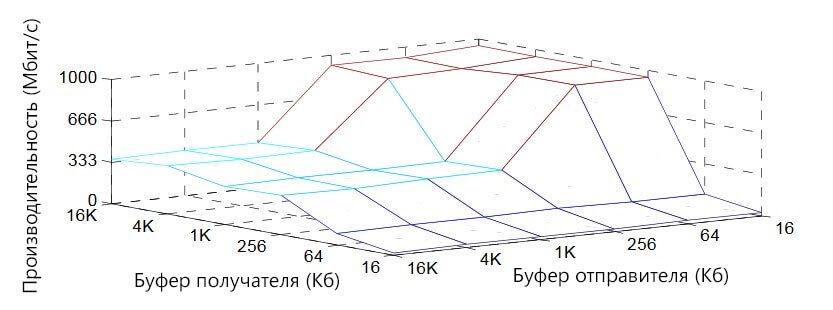
Рисунок 1. Зависимость производительности UDP от размеров буфера сокета
Небольшой буфер сокета стороны отправителя требуется, потому что: 1) больший буфер увеличивает RTT сети; и 2) больший буфер увеличивает возможность перенаполнения сети. Первая ситуация вызывает более серьезные проблемы при потере пакетов, в то время как вторая ситуация вызывает больше потерь пакетов. Между тем размер отправляющего буфера должен быть достаточно большим, чтобы он не ограничивал скорость отправки пакетов. Это минимальное значение связано с показателем RTT.
На рисунке 2 показано, что размер пакета должен быть равен размеру MTU. Хотя видно, что больший размер пакета приводит к меньшему использованию ЦП (так как происходит меньше затрат на их обработку), вероятность возникновения сегментации делает больший размер опасным [13].
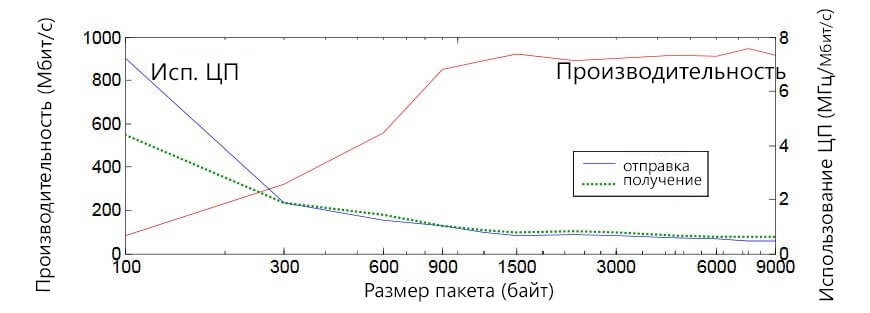
Рисунок 2. Зависимость производительности UDP от размеров сетевого пакета
Значительное улучшение производительности обеспечивается разбрасыванием /собиранием пакетов. Этот метод можно использовать, чтобы избежать одной копии памяти, избегая использования временного буфера для упаковки и распаковки заголовков пакетов и пользовательских данных.
Литература
- W. Feng and P. Tinnakornsrisuphap. The Failure of TCP in High- Performance Computational Grids. SC '00, Dallas, TX, Nov. 4 - 10, 2000.
- C. Jin, D. X. Wei, and S. H. Low. FAST TCP: motivation, architecture, algorithms, performance. IEEE Infocom '04, Hongkong, China, Mar. 2004.
- S. Floyd. HighSpeed TCP for Large Congestion Windows. RFC 3649, Experimental Standard, Dec. 2003.
- T. Kelly. Scalable TCP: Improving Performance in Highspeed Wide Area Networks. ACM Computer Communication Review, Apr. 2003.
- L. Xu, K. Harfoush, and I. Rhee. Binary Increase Congestion Control for Fast Long-Distance Networks. IEEE Infocom '04, Hongkong, China, Mar. 2004.
- D. Katabi, M. Hardley, and C. Rohrs. Internet Congestion Control for Future High Bandwidth-Delay Product Environments, ACM SIGCOMM '02, Pittsburgh, PA, Aug. 19 - 23, 2002.
- Yunhong Gu and Robert Grossman, SABUL: A Transport Protocol for Grid Computing, Journal of Grid Computing, 2003, Volume 1, Issue 4, pp. 377-386.
- Yunhong Gu, Xinwei Hong, and Robert L. Grossman, Experiences in the Design and Implementation of a High Performance Transport Protocol, SC ’04, Pittsburgh, PA.
- Mark, R. Meiss, Tsunami: A High-Speed Rate-Controlled Protocol for File Transfer, http://steinbeck.ucs.indiana.edu/~mmeiss/papers/tsunami.pdf, retrieved on Sep. 28, 2004.
- He, E., Leigh, J., Yu, O., DeFanti, T. A., Reliable Blast UDP: Predictable High Performance Bulk Data Transfer, Proc. IEEE Cluster Computing, Sept, Chicago, Illinois, 2002.
- Phillip M. Dickens, FOBS: A Lightweight Communication Protocol for Grid Computing, Europar 2003.
- Ryan X. Wu, and Andrew Chien, Evaluation of Rate Based Transport Protocols for Lambda-Grids, to appear in Proceedings of the 13th IEEE HPDC, Honolulu, Hawaii, June 2004.
- S. Floyd and K. Fall. Promoting the use of end-to-end congestion control in the Internet. IEEE/AC M Trans. on Networking, 7(4): 458- 472, 1999.