
Реферат за темою випускної роботи
Зміст
- Введення
- 1. Актуальність теми
- 2. Мета і задачі дослідження, заплановані результати
- 3. Огляд існуючих методів виділення контурів зображення
- 4. Огляд міжнародних джерел
- 5. Виділення і опис елементів зображення
- 6. Огляд деяких існуючих методів
- 6.1 Детектор кордонів Canny
- 6.2 Алгоритми відстежування
- 6.3 Способи опису контурів
- Висновки
- Перелiк посилань
Вступ
Виділення меж зображень є ключовим елементів сучасних систем комп'ютерного зору при вирішенні ряду прикладних задач, пов'язаних з розпізнаванням образів. Кордони є підмножина точок вихідного зображення, пов'язані з межами предметів або іншими істотними елементами зображення.
Алгоритми виділення кордонів і прив'язка їх до суттєвих елементів зображення називають детекторами країв (edge ??detection). Точки зображення, в яких яскравість змінюється особливо сильно, називають крайовими точками, а їх сукупність формує краю областей зображення. Детектори країв використовують для аналізу приналежності даної точки вихідного зображення локальний фрагмент зображення, на підставі аналізу якого робиться висновок про наявність крайової точки.
1. Актуальність теми
Виділення меж зображень є ключовим елементів сучасних систем комп'ютерного зору при вирішенні ряду прикладних задач, пов'язаних з розпізнаванням образів. Науковою новизною даної роботи є розробка алгоритму виділення контурів на слабоконтрастних напівтонових зображеннях. Існуючі на сьогоднішній день алгоритми виділення контурів погано справляються з низькою контрастністю об'єктів і фону, а також вкрай чутливі до шуму на зображенні. Розроблюваний алгоритм буде спрямований на максимальне виділення всіх кордонів об'єктів і на придушення виявлених помилкових контурів, які найчастіше виникають від присутності імпульсного шуму.
При аналізі зображень і розпізнаванні об'єктів, присутніх на ньому, вагому частку приймають на себе методи і алгоритми виділення контурів, так як вони значно спрощують роботу з зображенням і / або цифровим рядом. Але більшість існуючих на сьогоднішній день алгоритмів не може надати досить високу точність виділення контуру об'єктів, так як завжди присутні розриви і помилкові кордону. Це в значній мірі ускладнює подальшу роботу над зображенням. Дана робота націлена на розробку алгоритму, що дозволяє максимально поліпшити виділення кордонів зображення шляхом комбінації і модифікації існуючих алгоритмів знаходження контурів об'кта на зображенні із застосуванням всіляких методів розпізнавання.
2. Мета і задачі дослідження та заплановані результати
Як правило, детектори країв дають великий вихід при наявності різких локальних змін яскравості. Широкий клас систем технічного зору експлуатується в умовах наявності шумів і перешкод. Шуми істотно спотворюють інформацію про становище крайових точок, що призводить до появи двох типів можливих помилок. Перший тип пов'язаний з пропуском реально існуючої крайової точки, а другий, з появою помилковою. Детектор країв CANNY вважається одним з кращих, він не працездатний при наявності шумів.
Основні завдання дослідження:
Поліпшення якості детекторів країв вимагає збільшення площі фрагмента зображення, використовуваного для прийняття рішення про наявність крайової точки, а також складних алгоритмів обробки. З точки зору реалізації це означає необхідність виконання великого обсягу обчислень. Природно, що для відеосистем складність реалізації завадостійких фільтрів кордонів істотно складніше через необхідність обробляти 25 - 30 кадрів в секунду.
Можна констатувати, що проблема розробки завадостійких детекторів країв є актуальною, а способи її вирішення багато в чому визначають параметри підсистем технічного зору. Як показує аналіз, рішення задачі обробки відеоінформації неможливо без застосування паралельних обчислень. Одним з можливих варіантів реалізації завадостійких детекторів країв є використання методології нейронних мереж.
3. Огляд досліджень та розробок
Виділення контурів зображень - визначення в теорії обробки зображення і комп'ютерного зору, частково з області пошуку об'єктів і виділення об'єктів, ґрунтується на алгоритмах, які виділяють точки цифрового зображення, в яких різко змінюється яскравість або є інші види неоднорідностей.
В ідеальному випадку, результатом виділення контурів є набір пов'язаних кривих, що позначають межі об'єктів, граней і відбитків на поверхні, а також криві відображають зміни положення поверхонь. Таким чином, застосування фільтра виділення кордонів до зображення може істотно зменшити кількість оброблюваних даних, через те, що відфільтрована частина зображення вважається менш значущим, а найбільш важливі структурні властивості зображення зберігаються.
Однак не завжди можливо виділити контур в картинах реального світу середньої складності. Межі виділені з таких зображень часто мають такі недоліки як фрагментованість (криві контурів не з'єднані між собою), відсутність кордонів або наявність хибних, які не відповідають об'єкту, що вивчається.
Існує безліч підходів до виділення контурів зображень, але майже все можна розділити на дві категорії: методи, засновані на пошуку максимумів, і методи, засновані на пошуку нулів.
Методи, засновані на пошуку максимумів, виділяють контури за допомогою обчислення «сили краю», зазвичай вираження першої похідної, такого як величина градієнта, і потім пошуку локальних максимумів сили краю, використовуючи передбачуване напрямок контуру, зазвичай перпендикуляр до вектору градієнта.
Методи, засновані на пошуку нулів, шукають перетину осі абсцис вираження другої похідної, зазвичай нулі Лапласіан або нулі нелінійного диференціального виразу. В якості кроку попередньої обробки до виділення кордонів практично завжди застосовується згладжування зображення, зазвичай фільтром Гаусса. Методи виділення контурів відрізняються застосовуваними фільтрами згладжування. Хоча багато методів виділення кордонів ґрунтуються на обчисленні градієнта зображення, вони відрізняються типами фільтрів, що застосовуються для обчислення градієнтів в x- і y-напрямках.
4 Огляд міжнародних джерел
В роботі (Гонсалес, Вудс) глава 10 [1] присвячена сегментації зображень, а глава 11 - їх поданням та опису. Подробиця викладу всіх питань досить висока. Дана книга найкращим чином підходить для додаткового вивчення даної теми в цілому.
В роботі (Заріт) глава 9 [2] присвячена аналізу і синтезу текстуртекстур на основі частотних підходів і різних розкладів [3]. Оскільки це питання зовсім не зачіпається в нашому короткому курсі, дана глава може бути рекомендована цілком в якості матеріалу для додаткового самостійного вивчення.
В роботі (Лаксмі, Санкаканяанан) роботі з текстурами присвячена глава 7 [3]. Логіка викладу відповідає нашим курсом, але обсяг істотно більше і виклад докладніше і глибше. Оскільки тема текстурного аналізу описана нами надзвичайно коротко, дана глава з також може бути рекомендована цілком в якості матеріалу для додаткового самостійного вивчення.
В главах 14 і 16 роботи (Зуєв) [4] завдання сегментації зображення (в широкому сенсі) розглядається відповідно в контексті кластеризації (розбиття вибірки на класи) та ймовірнісної оптимізації (максимуму апостеріорної ймовірності і байєсівського підходу). Ці підходи до сегментації зображень на області практично не розкриваються в нашому курсі, тому рекомендується ознайомитися з 14 і 16 главами книги в рамках поглибленого самостійного вивчення даного курсу.
5. Виділення і опис елементів зображення
У міру зростання вимог до точності і надійності алгоритмів виявлення все більш складних об'єктів у все більш складної реальній обстановці недоліки даної групи методів стали проявлятися все більш явно. Це, перш за все, висока ймовірність аномальних помилок, необхоодімость мати велике число еталонів для опису разноракурсних образів тривимірних об'єктів, нестійкість по відношенню до яркостное-геометричної мінливості зображень, що має місце в реальних умовах реєстрації. Таким чином, намітився перехід від кореляційних детекторів заданих образів до методів і алгоритмів структурного аналізу зображень.
В даний час послідовність процедур обробки зображень прийнято розглядати відповідно до так званої парадигмою Марра. Ця парадигма, запропонована Д.Марром на основі тривалого вивчення механізмів зорового сприйняття людини, стверджує, що обробка зображень спирається на кілька послідовних рівнів висхідній інформаційної лінії "іконічна уявлення об'єктів (растрове зображення, неструктурована інформація) - символічне уявлення (векторні і атрибутивні дані в структурованої формі, реляційні структури) "і повинна здійснюватися за модульним принципом за допомогою наступних етапів обробки:
- Передобробка зображення;
- Первинна сегментація зображення;
- Виділення геометричній структури видимого поля;
- Визначення відносної структури і семантики видимої сцени.
Пов'язані з цими етапами рівні обробки зазвичай називаються обробки нижнього, середнього і високого рівнів, відповідно. У той час як алгоритми обробки нижнього рівня (фільтрація простих шумів, гістограмного обробка) можуть розглядатися як добре опрацьовані і детально вивчені, алгоритми середнього рівня (сегментація) продовжують сьогодні залишатися центральним полем докладання дослідницьких зусиль. За останні роки значний прогрес був досягнутий стосовно проблем зіставлення точок і фрагментів зображень (matching) виділення ознак всередині малих фрагментів високої точності 3D-позиціонування точок що має на увазі відповідне моделювання та калібрування датчиків і їх комбінацій, виділення простих яркостное-геометричних структур типу "точка "," край "," пляма "," пряма лінія "," кут ". Ці "первинні" особливості зображення, також звані характерними рисами (ХЧ), грають базову роль при складанні яркостное-геометричних моделей об'єктів і розробці робастних алгоритмів їх виділення.
На рисунку 5.1 наведено класифікацію характерних рис (ХЧ), які можуть бути присутніми на зображеннях.
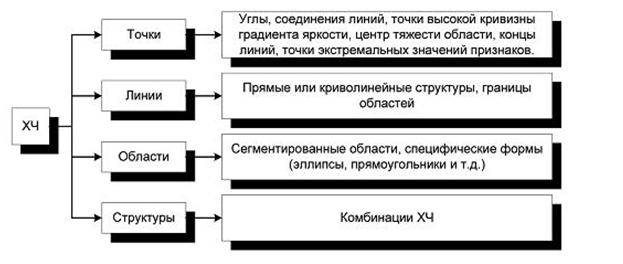
Рисунок 5.1 - класифікація характерних рис (ХЧ)
При роботі з реальними зображеннями перераховані критерії є суперечливими. Тому конкретний вибір ХЧ і їх атрибутів залежить від доступної обчислювальної потужності і від мінімальної необхідної робастності опису моделі об'єкта в термінах ХЧ. Дана таблиця демонструє суперечливість різних типів ХЧ в сенсі різних критеріїв. Якщо говорити про методи і алгоритми виявлення складних об'єктів, то одна з центральних проблем, що відрізняють методи обробки зображень від добре вивченої теорії обробки сигналів, полягає в розробці методів виявлення об'єктів, слабо чутливих до різноманітних видів мінливості, характерним лише для зображень. Такими специфічними видами мінливості є ракурсів і радіометричні спотворення, а також різні види спотворень, що не зводяться до імовірнісних моделей (шуми форми). На шляху боротьби з ними були запропоновані як безліч евристичних алгоритмів виявлення конкретних типів об'єктів, так і ряд підходів, що володіють більшою спільністю: методи кореляційного виявлення перетворення Хафа морфологічні підходи Питьева і Серра. Значний внесок у розробку методів і алгоритмів обробки зображень і машинного зору стосовно обговорюваних завданням виявлення внесли роботи Л.П.Ярославского, В.К.Злобіна, В.Л.Лёвшіна, Р.Хараліка, Е.Девіса, Р.Неватіа, Е .Дікманнса, В.Фёрстнера і багатьох інших. Однак, незважаючи на досягнуті результати, загальний стан проблеми виділення та ідентифікації складнострукурованих об'єктів на моноскопіческіх зображеннях можна охарактеризувати як незадовільний. Ще складніше виглядає завдання виявлення тривимірних структур на стереоскопічних зображеннях. Тут тільки намічаються підходи до більш загальним постановок.
6. Огляд досліджень і розробок
6.1 Детектор кордонів Canny
John Canny описав алгоритми виявлення кордонів, які з тих пір стали одними з найбільш широко використовуваних. Можна сказати, що вони стали класикою в області виявлення кордонів. Canny виходив з трьох критеріїв, яким повинен задовольняти детектор кордонів:
- Гарне виявлення (Canny трактував це властивість як підвищення відносини сигнал / шум);
- Хороша локалізація (правильне визначення положення кордону);
- Єдиний відгук на одну кордон.
З цих критеріїв потім будувалася цільова функція вартості помилок, мінімізацією якої знаходиться "оптимальний" лінійний оператор для згортки із зображенням. Алгоритм детектора кордонів Canny не обмежується обчисленням градієнта згладженого зображення. У контурі кордону залишаються тільки точки максимуму градієнта зображення, а не максимальні точки, що лежать поруч з кордоном, видаляються. Тут також використовується інформація про направлення кордону для того, щоб видаляти точки саме поруч з кордоном і не розривати саму кордон поблизу локальних максимумів градієнта. Потім за допомогою двох порогів видаляються слабкі кордону. Фрагмент кордону при цьому обробляється як ціле. Якщо значення градієнта де-небудь на простежується фрагменті перевищить верхній поріг, то цей фрагмент залишається також "допустимої" кордоном і в тих місцях, де значення градієнта падає нижче цього порога, до тих пір поки вона не стане нижче нижнього порога. Якщо ж на всім фрагменті немає жодної точки із значенням більшим верхнього порогу, то він видаляється. Такий гистерезис дозволяє знизити число розривів в вихідних межах. Включення в алгоритм Canny шумозаглушення з одного боку підвищує стійкість результатів, а з іншого - збільшує обчислювальні витрати і призводить до спотворення і навіть втрати подробиць кордонів. Так, наприклад, таким алгоритмом скругляются кути об'єктів і руйнуються кордону в точках з'єднань [5][6].
6.2 Алгоритми відстежування
Відстежують методи засновані на тому, що на зображенні відшукується об'єкт (перша зустрілася точка об'єкта) і контур об'єкта відстежується і векторизуется. Перевагою даних алгоритмів є їх простота, до недоліків можна віднести їх послідовну реалізацію і деяку складність при пошуку і обробці внутрішніх контурів, а так само необхідність застосування сканування, для виявлення дуже маленьких контурів.
Приклад відслідковує методу - метод жука - наведено на малюнку 3. Жук починає рух з білою області у напрямку до чорної, Як тільки він потрапляє на чорний елемент, він повертає ліворуч і переходить до наступного елементу. Якщо цей елемент білий, то жук повертається направо, інакше - наліво. Процедура повторюється до тих пір, поки жук не повернеться у вихідну точку. Координати точок переходу з чорного на біле і з білого на чорне і описують кордон об'єкта.
На малюнку 3 показана схема роботи такого алгоритму.
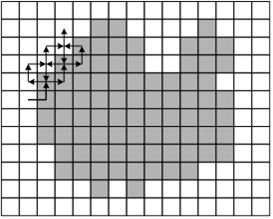
Рисунок 6.1 - Метод Жука
Метод, заснований на послідовному скануванні зображення (малюнок 4), полягає в пошуку таких пар точок, для яких різниця інтенсивностей з сусідніми точками (вздовж напрямку сканування) більше деякого порога ? / 2, а різниця інтенсивностей з усіма точками між бажаного не перевищує цей поріг [7]. До переваг даного методу можна віднести незалежність часу обробки від кількості контурів на карті і більшою ефективністю в порівнянні з відстежують алгоритмами.
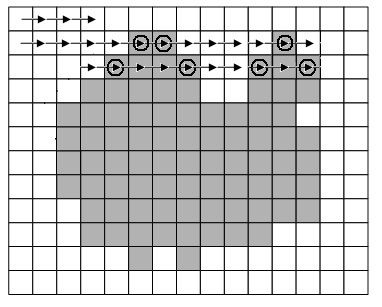
Рисунок 6.2 - Метод послідовного сканування
6.3 Способи опису контурів
Дискретне уявлення кривої у вигляді послідовності точок з координатами (x, y) вкрай неефективно. Більш ефективним є уявлення за допомогою ланцюгових кодів (chain code) при використанні яких вектор, що з'єднує дві сусідні точки, кодується одним символом, що належить кінцевому множину[7]. Зазвичай при користуванні ланцюговим кодом розглядається околиця точки розміром 3 ? 3 і 4 або 8 можливих напрямків кодування (рисунок 5.1).
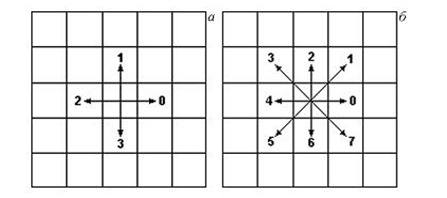
Рисунок 6.3 - Напрямки кодування в ланцюгових кодах:
а-4 напрямки, б - 8 напрямківПочинаючи з першої точки, проводиться обхід контуру за годинниковою стрілкою, при цьому кожна наступна точка кодується числом 1 - 8, в залежності від свого розташування відносно центральної точки околиці. Результатом кодування є послідовність, що складається з цифр 1 - 8. Приклад кодування кривої (рис. 10) за допомогою ланцюгового коду: +77121076667110076771122334. Даний спосіб представлення кривої має такі недоліки.
- Залежність від початкової точки кодування.
- Не володіє властивістю інваріантності до обертання.
- Нестійкість до зашумлення.
- Розглянуто можливості комплексної автоматизації розробленого підходу до уніфікації синтезу автоматів Мура, оцінені вимоги до програмного забезпечення, виконаний пошук функціонально подібних програмних продуктів синтезу послідовних логічних схем.

Рисунок 6.4 - Процес виділення контурів зображення
(Анімація: 7 кадрів, 7 циклів повторення, 36 кілобайт)Локальні зміни контуру можуть привести до різних результатів кодування. Іншим способом представлення кривої є кусочно-поліноміальна апроксимація. Завдання апроксимації полягає в знаходженні кривої, що проходить поблизу заданої множини точок контуру. Крива розбивається окремими вузлами на відрізки, при цьому апроксимуюча функція на кожному з них має вигляд:

де an - коефіцієнти полінома, що підлягають визначенню на кожному відрізку.
В якості характерних ознак можна використовувати число і положення особливих точок контуру (точки максимального перегину, локальні екстремуми функції кривизни, кінцеві точки, точки розгалуження). В першу чергу, на контурі намагаються виділити так звані кутові (контрольні) точки, тобто точки, що мають максимальну кривизну в певній околиці, тому що кінцеві точки і точки розгалуження є недостатньо надійними ознаками і в значній мірі схильні до впливів шумів. Перехід назад до точкових характеристикам дозволяє використовувати методи ототожнення, описані в попередньому розділі[8].
Істотною відмінністю методу виділення характерних точок на контурах є те, що в якості опорної інформації використовуються не яскравості, а геометричні особливості об'єкта.
В даній роботі були розглянуті різні варіанти виділення особливих точок на отриманих контурах. Найбільш простим і швидким способом є описаний вище пошук точок максимального перегину за допомогою ітеративного алгоритму підбору кінцевих точок. Однак використання даного алгоритму не принесло позитивних результатів. Нестійкість його роботи визначається досить сильною залежністю результатів пошуку точок від початкових умов (кінцевих точок контура). Недостатня перешкодозахищеність не дозволяє використовувати даний метод для виділення особливих точок на контурах.
7. Проблеми та невирішені питання в області контурного аналізу зображення
Досліджуючи дану проблему, стають очевидним, що з одного боку це питання висвітлюється досить широко, хоча безпосередньо в Україні він торкнуться досить поверхово, більше уваги його вивчення приділяється за кордоном[9]. Згодом дослідження в області методів контурного аналізу стають все глибше і глибше, проте у міру того, як вивчається область ширшає, з'являється все більше і більше питань для подальшого розгляду.
Все ще не вирішена проблема отримання ідеального замкнутого контуру, хоча сучасні методи дуже наближають вирішення цієї проблеми. Також залишається відкритим питання про те, як відкинути помилкові контури, не торкнувшись при цьому інші, які є істинними. Крім того, часто при отриманні зображення для подальшої обробки виникає проблема накладення контуру. Таким чином, поділ контурів також є все ще не до кінця невирішеною проблемою.
Дослідження в цій галузі будуть актуальними до тих пір, поки не вирішаться хоча б ці питання [ 10 ]. Обробка зображень досить сучасна проблема і багато вчених, що працюють в даному напрямку пропонують свої методи вирішення. Наприклад, Фомін Я. А. В своїх роботах «Розпізнавання образів: теорія і застосування» предлагатет наступну ідею: на його думку, точність виділення країв можна підвищити шляхом їх простеження на послідовності зображень, отриманих в різні моменти часу.
Висновки
В даній роботі були розглянуті різні варіанти виділення особливих точок на отриманих контурах. Найбільш простим способом є описаний вище простеження контурів за допомогою ітеративного алгоритму підбору кінцевих точок. Однак використання даного алгоритму не принесло позитивних результатів. Нестійкість його роботи визначається досить сильною залежністю результатів пошуку точок від початкових умов (кінцевих точок контура і зашумленности зображення). Недостатня перешкодозахищеність не дозволяє використовувати даний метод для виділення особливих точок на контурах.
В подальшому буде зроблена спроба заглибитися в дослідження з метою впровадження нових розроблених технологій в різні сфери діяльності. За кордоном використання даних алгоритмів знаходження контуру об'єктів на зашумлених зображеннях зустрічається практично повсюдно, т. К. Виділення контурів окремих об'єктів вельми полегшує подальший пошук цих об'єктів. Будемо сподіватися, що розвиток передових технологій в цій галузі в нашій час незабаром також буде мати місце.
Примітка
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2018 року. Повний текст роботи і матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.
Список джерел
- Gonzalez D., Woods D., Hildreth E. Theory of edge detection / Dslash Proc. R. Soc. (London). 2009. B207. 187 - 217c.
- B.D. Zarit, International Journal of Computer Science & Information Technology (IJCSIT), 3 (6). - С. 259-267.
- Lakshmi S, Sankaranarayanan V. (2010) A Study of edge detection techniques for segmentation computing approaches, Computer Aided Soft Computing Techniques for Imaging and Biomedical Applications. - P. 35-41.
- Ramadevi Y. (2010) Segmentation and object recognition using edge detection techniques, International Journal of Computer Science and Information Technology, Vol 2, No.6. - P. 153-161.
- Зуєв А.А. Методи виділення контурів на зображеннях / А.А. Зуєв, Г.Є. Нечепоренко // Міжнародна наукова конференція MicroCAD: Секцiя № 8 - Мікропроцесорна техніка в автоматіці та пріладобудуванні - НТУ ХПІ, 2012. - С. 108.
- Самаль Д.І. Вибір ознак для розпізнавання на основі статистичних даних / Д.І. Сама, В.В. Головенко - Мінськ: ІТК, 1999. - 218 c.
- Самаль Д.І. Методика автоматизованого розпізнавання людей по фотопортрет / Д.І. Сама., В.В. Головенко - Мінськ: ІТК, 1999. -187 с.
- Вапник В. Н. Теорія розпізнавання образів. / В. Н. Вапник, А. Я. Червоненкис - М .: Наука, 1974. - 416 с.
- Фомін Я. А. Розпізнавання образів: теорія і застосування / Фомін, Я.А. - 2-е вид. - М .: фазисами, 2012. - 429 с.
- Чен Ш.К. Принципи проектування систем візуальної інформації / Чен, Ш.К. - М .: Світ, 1994. - 408 с.
- Аркадьєв А. Г. Навчання машини розпізнаванню образів / А.Г. Аркадьєв, Е. М. Браверман - М .: Наука, 1964. - 478 с.