
Зміст
- Введення
- 1. Актуальність теми
- 2. Мета і завдання дослідження, плановані результати
- 3. Огляд досліджень і розробок
- 3.1 Огляд міжнародних джерел
- 4. Оптимізація роєм частинок
- 5. Автоматична кластеризація з використанням оптимізації рою частинок
- 5.1 Основна ідея
- 5.2 Оптимізація роєм частинок ідея
- 6. Багатоагентна кластеризация PSO
- 6.1 Кластеризация PSO
- 6.2 Автоматична кластеризация PSO
- Висновки
- Список джерел
Введення
Однією з найбільш складних проблем обробки зображень є виділення контуру об'єктів для їх подальшого розпізнавання. Ключове завдання виділення ліній, що проходять на кордонах однорідних областей.Одной з найбільш складних проблем обробки зображень є виділення контуру об'єктів для їх подальшого розпізнавання. Ключове завдання виділення ліній, що проходять на кордонах однорідних областей.
Виділення кордонів грунтується на алгоритмах, які визначають різку зміну яскравості на зображенні. Результатом виконання алгоритмів виділення кордонів повинна бути деяка кількість пов'язаних кривих, які відображають межі об'єкта. У більшості випадків кордону на зображеннях виражені не настільки контрастно, тому що існують на даний момент алгоритми і оператори не забезпечують ефективність одержуваного результату. Часто результат обробки варіюється від розривів контурів і ліній (фрагментованість) до повної відсутності кордону.
Однією з найбільш складних прикладних задач в даній області є виділення ліній на долоні. Виділення контуру долоні зазвичай не є складним завданням, а виділення ліній на ній - досить нетривіальна операція, тому що через низьку контрастності ліній по відношенню до їх оточенню і велика кількість перешкод (шуму) виникають розриви, помилкові лінії або повна їх відсутність.
1. Актуальність теми
Розпізнавання візуальних образів є один з найважливіших компонентів систем управління і обробки інформації, автоматизованих систем та систем прийняття рішень. Завдання, пов'язані з класифікацією і ідентифікацією предметів, явищ і сигналів, що характеризуються кінцевим набором деяких властивостей і ознак, виникають в таких галузях як робототехніка, інформаційний пошук, моніторинг і аналіз візуальних даних, дослідження штучного інтелекту. На даний момент в виробництві широко використовуються системи розпізнавання рукописного тексту, автомобільних номерів, відбитків пальців або людських осіб, що знаходять застосування в інтерфейсах програмних продуктів, системах безпеки та ідентифікації особистості, а також в інших прикладних цілях.
Однак, актуальною проблемою, визнаною науковим співтовариством, залишається розпізнавання зображених об'єктів на зашумлений зображеннях, що ускладнює визначення меж об'єкта і подальшої обробки соотвественно.
Актуальність даної проблеми особливо висока в галузях, де розпізнавання образів застосовується в природному середовищі (відеоспостереження, аналіз даних камер моніторингу, робототехнічні зорові системи), де зоровий сенсор може мати довільний обмежений кут огляду по відношенню до шуканого об'єкту.
2. Мета і завдання дослідження, плановані результати
Метою дослідження є розробка алгоритму ройовий оптимізації для задач розпізнавання на зашумленних зображеннях
Придушення цифрового стохастичного шуму при постобробці проводиться усереднення яскравості пікселя по певної групи пікселів, який алгоритм вважає "схожими". Зазвичай при цьому погіршується детальність зображення, воно стає більш "мильним". Крім цього, можуть проявиться помилкові деталі, яких не було на вихідній сцені. Наприклад, якщо алгоритм буде шукати "схожі" пікселі недостатньо далеко, то мелкозернсітий і середньозернистий шум може бути пригнічений, а слабкий, але все одно досить помітний неприродний "великий" шум залишиться видимим.
Основні завдання дослідження:
- Розробка алгоритмічної бази для представленої моделі, що включає в себе алгоритм розпізнавання зображень.
- Реалізація алгоритмічного комплексу у вигляді програми для ЕОМ.
- Оцінка продуктивності розробленого методу і критеріїв досягнення поставленої мети.
- Оцінка ефективності розробленого методу в порівнянні з сучасними альтернативними методами розпізнавання
3. Огляд досліджень і розробок
Оскільки розпізнавання об'єктів на зображеннях є дуже актуальною темою, то проблеми розпізнавання широко досліджені як нашими, так і іноземними вченими.
3.1 Огляд міжнародних джерел
Роботі Гонсалеса і Вудса [1] присвячена сегментації зображень, їх поданням та опису. Подробиця викладу всіх питань досить висока. Дана книга найкращим чином підходить для додаткового вивчення даної теми в цілому.
Робота Лакшмі і Санкаканяанана присвячена текстуам [2]. логіка викладу відповідає нашим курсом, але обсяг істотно більше і виклад докладніше і глибше. оскільки тема текстурного аналізу описана нами надзвичайно коротко, дана глава з також може бути рекомендована цілком в якості матеріалу для додаткового самостійного вивчення.
В роботі Зуєва О.О. [3] розглядається задача сегментації зображення (в широкому сенсі) відповідно в контексті кластеризації (розбиття вибірки на класи) та ймовірнісної оптимізації (максимуму апостеріорної ймовірності і байєсівського підходу).
4. Оптимізація роєм частинок
В основу алгоритму оптимізації роєм часток (Particle Swarm Optimization, PSO) покладена соціально-психологічна поведінкова модель натовпу. Розвиток алгоритму інспірували такі завдання, як моделювання поведінки птахів у зграї і риб в косяку. Метою було виявити базові принципи, завдяки яким, наприклад, птиці в зграї поводяться дивно синхронно, змінюючи як по команді напрямки свого руху, так що зграя рухається як єдине ціле. До сучасного часу концепція алгоритму рою частинок розвинулася в високоефективний алгоритм оптимізації, часто становить конкуренцію кращим модифікаціям генетичного алгоритму. Існує дуже багато алгоритмів рою частинок. В канонічному алгоритмі, запропонованому в 1995 р Кеннеді (J. Kennedy) і Еберхарт (R. Eberhart), при визначенні наступного положення частинки враховується інформація про найкращу частці з числа її «Сусідів», а також інформація про дану частці на тій ітерації алгоритму, на якій цій частинці відповідало оптимальне значення фітнес-функції. Відомо велика кількість модифікацій даного алгоритму. Наприклад, модифікація FIPS при визначенні наступного положення частинки враховує значення фітнес функції, які відповідають усім частинкам популяції.
Нижче представлені канонічний алгоритм PSO, найбільш відомі модифікації канонічного алгоритму, визначено поняття топології сусідства частинок. Крім того, розглянуті основні топології, використовувані в обчислювальній практиці, дано огляд алгоритмів PSO з динамічної топологією сусідства частинок, представлений гібридний алгоритм на основі рою частинок і імітації відпалу. На завершення параграфа наведено приклад використання алгоритму PSO.
5. Автоматична кластеризація з використанням оптимізації рою частинок
5.1 Основна ідея
Основна ідея алгоритмів рій-інтелекту полягає в тому, що набір індивідуумів можуть співпрацювати децентралізованим чином, підвищуючи свою продуктивність. Таким чином, мета знайти механізми, які можуть моделювати складні системи, і представляти їх в формальному шляху
5.2 Оптимізація роєм частинок
Оптимізація роялів частинок є формою стохастичною оптимізації, заснованої на роях спрощених, соціальних агентів [4]. Первинні алгоритми оптимізації рій частинок пошук по m-мірному простору U за допомогою набору агентів. У цій решітці агент (частки) i займають положення xi (t) = {xi, j (t) | j = 1, ..., m} і має швидкість vi (t) = {vi, j (t) | j = 1, ..., m} в момент часу t, із співвідношенням 1: 1 (обидва xi (t) і vi (t) містять набір компонент {j = 1, ..., m}, що відображаються в координати в U). Простий алгоритм PSO [5] працює наступним чином: на етапі ініціалізації кожен агент приймає позиції навколо x (0) = xmin + r (xmax -xmin), а швидкості встановлюються на 0 (xmin і xmax - мінімальна і максимальна величини в U, а r - дійсне число між 0 і 1). По-друге, алгоритм входить в фазу пошуку. Фаза пошуку складається з наступних кроків: Краще оновлення когнітивної / глобальної позиції і швидкість / положення оновлення.
На етапі когнітивного поновлення кожен агент встановлює значення для поточного (локального) найкращого положення yi (t), яке воно безпосередньо спостерігало. Оновлений локальний оптимізатор агента yi (t +1) відповідно до рівняння:
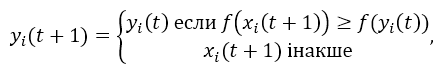
тоді як f (xi (t)) є функцією придатності, яка оцінює доброту заснованого на рішенні на позиції xi (t).
Навпаки, глобальний крок поновлення задає на кожній ітерації найкраще можливе положення Yi спостерігається у будь-якого агента. Наступне рівняння відображає вибір найкращого глобального положення:
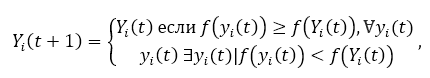
Крок поновлення швидкості або положення вибирає нові значення для позиції xi (t +1) і швидкість vi (t +1), використовуючи рівняння:
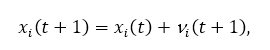
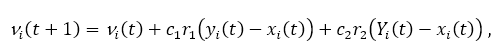
де параметри c1 і c2 використовуються для направлення пошуку між локальними (когнітивними компонент) і соціальні (глобальні компоненти) спостереження. r1, r2 ∈ [0,1] є випадковими параметрами які вводять стохастический вага в пошуку. Нарешті, алгоритм зупиняється поки не буде досягнута точка збіжності.
Пропонований критерій збіжності пропонується в [6]; він полягає в (f (Yi (t)) - f (Yi (t-1))) / f (Yi (t)) менше малої константи ε для заданого числа ітерацій. Важливо відзначити, що кожна частка в цієї багатоагентній системі ділиться його знання (глобальне краще становище) з усіма іншими частинками з допомогою околиці топологія.
Було запропоновано кілька топологій [7] (т. Е Зірка, кільце, кластери, фон Нейман, і т.д.). різниця між районами полягає в тому, як швидко чи повільно (в залежності від зв'язність) знання поширюються через рій.
Подальші удосконалення були запропоновані для базового алгоритму PSO [8, 9]: Velocity затиск, інерційний вага і коефіцієнт звуження. Всі алгоритми на основі PSO в це дослідження було виконано з використанням коефіцієнта звуження (найбільш надійного механізму).
Швидкісний коефіцієнт. Слабкістю алгоритмів оптимізації основних ролей частинок є що швидкість швидко зростає до невідповідних значень. Висока швидкість призводить до великих (в цьому випадку частинки можуть навіть вийти за межі пошуку простір). Це особливо справедливо для частинок, що займають вищі позиції. Затиск швидкості є простим обмеженням, що накладає максимальну швидкість. на рівнянні зображено це правило.
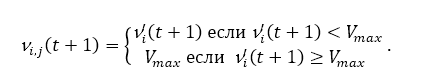
Очевидно, що великі значення Vmax полегшують розвідку (маленькі воліють експлуатацію). Vmax часто є дробом δ доменного простору для кожного вимірювання j в пошуку простір U. наступне рівняння представляє цю коригування.
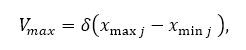
тоді як xmaxj і xminj представляють собою максимальну і мінімальну величини відповідно.
Вага інерції. Інерційний вага є обмеженням, яке націлене на контроль компромісу між розвідкою і експлуатацією більш прямим чином. Рівняння вводить інерційний вага w, який впливає на оновлення швидкості.
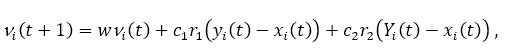
w ≥ 1 призводить до збільшення швидкості з плином часу (дослідження), w < 1 зменшує швидкості зі часом (на користь експлуатації). Згідно [10] значення w = 0,7298, c1 = c2 = 1.49618 довели хороші результати емпірично, хоча в багатьох випадках вони є проблемою залежний.
Коефіцієнт звуження. Аналогічний метод інерційного ваги був запропонований в [11], деномінований коефіцієнт звуження. Рівняння визначає нове оновлення швидкості механізм.
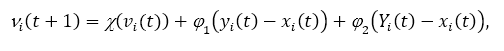
де φ = φ1 + φ2, φ1 = c1r1, φ2 = c2r і
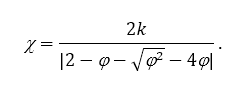
Важливо зауважити, що φ ≥ 4 и k ∈ [0,1 є необхідними обмеженнями для установки χ у діапазоні [0,1].
6. Багатоагентна кластеризация PSO
Раніше були представили теоретичні основи, необхідні, в яких новий AutoCPB годиться. В цьому розділі докладно розглянемо нашу багатоагентного систему для кластеризації. Однією з основних проблем, пов'язаних з алгоритмами PSO, є те, що вони мають тенденцію потрапити в субоптимальних рішення через відсутність різноманітності в рої. Один з наші амбіції - знайти механізм для поліпшення різноманітності. Поліпшення вихідного алгоритму PSO [12] полягає в використанні або memetic підходу або гібридизації з іншим методом розвідки рою [13]. За умови AutoCPB - гібридний евристичний алгоритм, ми вирішили розробити попередні прототипні алгоритми. Ми починаємо вводити спрощений метод кластеризації на основі рій, а потім ми поступово представляємо більш продумані розробки
6.1 Кластеризация PSO
Ми реалізували простий алгоритм кластеризації, позначений ClusterP, який був запропонований в [14]. Такий метод об'єднує PSO і K-засоби для угруповання даних.
Набір даних D = {d1, m, d2, m, ..., dn, m} визначає число компонентів m і примірників n в просторі пошуку U. Таким чином, кожне dumum di, j ∈ D можна розглядати як точку в U. Оскільки мета полягає в тому, щоб знайти безліч k бажаних кластерів C, що містять кожен елемент з D; легко зрозуміти, що основна проблема полягає в тому, щоб знайти безліч O = {o1, o2, ..., ok} Центроїд, які мінімізують функцію придатності (евклідова відстань) по відношенню до кожного точка в D. У clusterP кожен агент pl ∈ P являє собою рішення з набором позицій Ol = {ol, j | j = 1, ..., k}. Алгоритм представлений на малюнку 1 показує метод ClusterP.

Малюнок 1 - Алгоритм ClouserP
ClusterP працює наступним чином: він отримує дані D і ціле число k. По-перше, він поєднується кожен агент p в середовищі, кожен з яких містить набір Центроїд O (рядок 1). Потім, о н привласнює кожного запису di кластеру Ch, якщо відстань з його центром ваги (di, oh) одно мінімальний (рядки 3-8). Потім він отримує когнітивну і глобальну позицію (рядки 9-12), і оновлює кожну зі своїх швидкостей і положень Центроїд (рядки 13-16). Алгоритм зупиняється після фіксованого числа ітерацій або якщо немає значних прогрес здійснюється відповідно до функцією фітнесу.
6.2 Автоматична кластеризация PSO
ClusterP було розширено в [15], щоб автоматично знайти оптимальну кількість кластерів.
Новий метод називається AutoCP. Він починається з числа k кластерів (k ≤ n), і він видаляє непослідовні кластери.
Форма для виявлення неузгоджених кластерів описується наступним чином: по-перше, для кожного кластера Cj обчислюємо його вага Wj = ∑| Cj |q = 1 dist (oj, dq) у вигляді суми відстаней від центр oj до його точкам qj, де qj = oj. Відразу ж все ваги W з кластерів упорядковано. Потім нормуємо все ваги Wj щодо кластера з найменшим значення Ws, так що безліч локальних порогів стає th = {thj | j = 1, ..., k, thj = Ws / Wj, Ws = argminw ∈ W (w)}. Нарешті, кластер Cj оголошується неузгодженим, якщо його поріг tj нижче глобального порога T, тоді як T знаходиться в діапазоні [0,1]. алгоритм представлений на малюнку 2.

Малюнок 2 - Покращений алгоритм ClouserP
Як уже згадувалося раніше, AutoCP просто додає механізм для ClusterP для автоматичного виявлення кластерів без подальшої модифікації (рядки 6-15). В кінці кожного ітерації, ми вибираємо і відкидаємо неузгоджені кластери.
Висновки
Однією з найбільш складних проблем обробки зображень є виділення контуру об'єктів для їх подальшого розпізнавання. Ключове завдання виділення ліній, що проходять на кордонах однорідних областей.
Так як в більшості випадків межі на зображеннях виражені не настільки контрастно, тому існуючі на даний момент алгоритми і оператори не забезпечують ефективність одержуваного результату. Часто результат обробки варіюється від розривів контурів і ліній (фрагментованість) до повної відсутності кордону. Одним з найбільш перспективних, на мій погляд, є підхід, заснований на виділенні контурів на малоконтрастних і розмитих зображеннях на основі фрактальної фільтрації. Фрактали більш наочно виділяють контури, ніж інші оператори, але вони орієнтовані на обробку малоконтрастних зображень в цілому, а не на виділення окремих ліній і меж.
В цій роботі була описана техніки розвідки рою, а саме: рій частинок оптимізації. Були детально описаний алгоритм, заснований на цій парадигмі. Нові алгоритми покращують базовий кластерний метод, який на самому справі засноване на K-значенні.
Список джерел
- Gonzalez D., Woods D., Hildreth E. Theory of edge detection/Dslash Proc. R. Soc. (London). 2009. B207. 187 – 217c.
- Lakshmi S, Sankaranarayanan V. (2010) A Study of edge detection techniques for segmentation computing approaches, Computer Aided Soft Computing Techniques for Imaging and Biomedical Applications. - P. 35–41.
- Зуєв А.А. Методи виділення контурів на зображеннях / А.А. Зуєв, Г.Є. Нечепоренко // Міжнародна наукова конференція MicroCAD: Секцiя № 8 - Мікропроцесорна техніка в автоматіці та пріладобудуванні - НТУ ХПІ, 2012. - С. 108.
- Kennedy, J., Ebenhart, R.: Particle Swarm Optimization. In: Proceedings of the 1995 IEEE Int. Conf. on Neural Networks, pp. 1942–1948 (1995)
- Passino, K.: Biomimicry of bacterial foraging for distributed optimization and control. Control Systems Magazine, 52–67 (2002)
- Engelbrecht, A.: Fundamentals of Computational Swarm Intelligence. Wiley, Chichester (2005)
- Heylighen, F., Joslyn, C.: Cybernetics and second-order cybernetics. Encyclopedia of Physical Science and Technology. Academic Press, New York (2001)
- Bergh, F.: An analysis of particle swarm optimizers. PhD Thesis, University of Pretoria, South Africa (2002)
- Van der Merwe, D., Engelbrecht, A.: Data Clustering using particle swarm optimization. In: The 2003 congress on Evolutionary Computation, vol. 1, pp. 215–220 (2003)
- Biswas, A., Dasgupta, S.: Synergy of PSO and bacterial foraging optimization: A comprehensive study on. Advances in Soft Computing Series, pp. 255–263. Springer, Heidelberg (2007)
- Holdsworth B. Digital logic design / B. Holdsworth, C. Woods. – Prentice Hall, 2002. – 519 pp.
- Abraham, A., Roy, S.: Swarm intelligence algorithms for data clustering. Chp. 12, 279–313 (2008)
- Asuncion, A., Newman, D.: UCI Machine Learning Repository. University of California, Irvine, School of Information and Computer Sciences (2007)
- Clerc, M., Kennedy, J.: The particle swarm: Explosion, stability and convergence. IEEE Transactions on Evolutionary Computation 6, 58–73 (2002)
- Zhan, Z-H.; Zhang, J. Adaptive Particle Swarm Optimization. IEEE Transactions on Systems, Man, and Cybernetics. 39 (6): 1362–1381