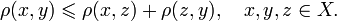
Алгоритмы нечеткого поиска (также известного как поиск по сходству или fuzzy string search) являются основой систем проверки орфографии и полноценных поисковых систем вроде Google или Yandex. Например, такие алгоритмы используются для функций наподобие «Возможно вы имели в виду …» в тех же поисковых системах.
В этой обзорной статье я рассмотрю следующие понятия, методы и алгоритмы:
А также проведу сравнительное тестирование качества и производительности алгоритмов.
Нечеткий поиск является крайне полезной функцией любой поисковой системы. Вместе с тем, его эффективная реализация намного сложнее, чем реализация простого поиска по точному совпадению.
Задачу нечеткого поиска можно сформулировать так:
«По заданному слову найти в тексте или словаре размера n все слова, совпадающие с этим словом (или начинающиеся с этого слова) с учетом kвозможных различий».
Например, при запросе «Машина» с учетом двух возможных ошибок, найти слова «Машинка», «Махина», «Малина», «Калина» и так далее.
Алгоритмы нечеткого поиска характеризуются метрикой — функцией расстояния между двумя словами, позволяющей оценить степень их сходства в данном контексте. Строгое математическое определение метрики включает в себя необходимость соответствия условию неравенства треугольника (X — множество слов, p — метрика):
Между тем, в большинстве случаев под метрикой подразумевается более общее понятие, не требующее выполнения такого условия, это понятие можно также назвать расстоянием.
В числе наиболее известных метрик — расстояния Хемминга, Левенштейна и Дамерау-Левенштейна. При этом расстояние Хемминга является метрикой только на множестве слов одинаковой длины, что сильно ограничивает область его применения.
Впрочем, на практике расстояние Хемминга оказывается практически бесполезным, уступая более естественным с точки зрения человека метрикам, о которых и пойдет речь ниже.
Наиболее часто применяемой метрикой является расстояние Левенштейна, или расстояние редактирования, алгоритмы вычисления которого можно найти на каждом шагу.
Тем не менее, стоит сделать несколько замечаний относительно наиболее популярного алгоритма расчета — метода Вагнера-Фишера.
Исходный вариант этого алгоритма имеет временную сложность O(mn) и потребляет O(mn) памяти, где m и n — длины сравниваемых строк. Весь процесс можно представить следующей матрицей:
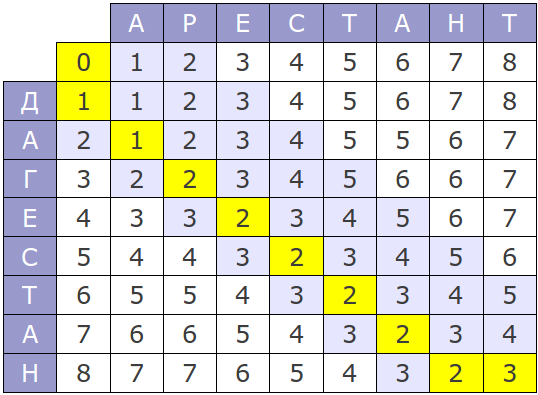
Если посмотреть на процесс работы алгоритма, несложно заметить, что на каждом шаге используются только две последние строки матрицы, следовательно, потребление памяти можно уменьшить до O(min(m, n)).
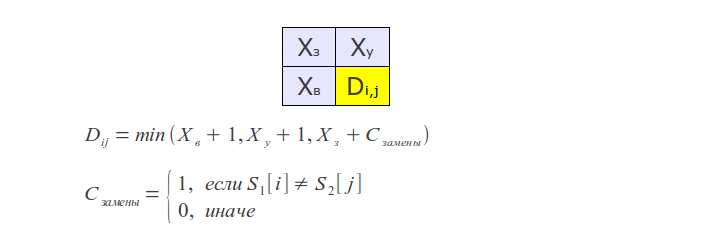
Но это еще не всё — можно дальше оптимизировать алгоритм, если стоит задача нахождения не более k различий. В этом случае нужно вычислять в матрице лишь диагональную полосу шириной 2k+1 (отсечение Укконена), что сводит временную сложность к O(k min(m, n)).
Также бывает необходимо вычислять расстояние между префиксом-образцом и строкой — т. е. найти расстояние между заданным префиксом и ближайшим префиксом строки. В этом случае необходимо взять наименьшее из расстояний от префикса-образца до всех префиксов строки. Очевидно, что префиксное расстояние не может считаться метрикой в строгом математическом смысле, что ограничивает его применение.
Зачастую при нечетком поиске важно не столько само значение расстояния, сколько факт того, превышает оно или нет определенную величину.
Эта вариация вносит в определение расстояния Левенштейна еще одно правило — транспозиция (перестановка) двух соседних букв также учитывается как одна операция, наряду со вставками, удалениями и заменами.
Еще пару лет назад Фредерик Дамерау мог бы гарантировать, что большинство ошибок при наборе текста — как раз и есть транспозиции. Поэтому именно данная метрика дает наилучшие результаты на практике.

Чтобы вычислять такое расстояние, достаточно немного модифицировать алгоритм нахождения обычного расстояния Левенштейна следующим образом: хранить не две, а три последних строки матрицы, а также добавить соответствующее дополнительное условие — в случае обнаружения транспозиции при расчете расстояния также учитывать и её стоимость.
Кроме рассмотренных выше, существует еще множество других, иногда применяющихся на практике расстояний, таких как метрика Джаро-Винклера, многие из которых доступны в библиотеках SimMetrics и SecondString.
English version: Fuzzy string search