Из-за задержки апдейтов в Яндексе у seo-оптимизаторов появилась задача автоматизировать процесс определения наличия изменений, а также ввести такой термин, как сила апдейта (или шторм), под которым подразумевается расхождение между предыдущей и текущей картиной в ТОПе. Это возлагает на поисковую систему дополнительную нагрузку, но позволяет получить уведомление об апдейте раньше официального, а также найти другие изменения, связанные с обновлениями алгоритмов.
В данной статье мы уделяем большое внимание поиску силы апдейта Яндекса, однако, апдейты выдачи не есть самоцель, подобная задача может решаться более красивым способом, чем сравнение ТОПов. Из-за восстребованности анализаторов апдейта (тема близка почти каждому оптимизатору), ниже будут приведены примеры именно для решения этой задачи. Однако, степень изменения поисковой выдачи может говорить нам не только о наличии апдейта в поиске, но также апдейта тИЦ, PageRank сайтов, обновления рубрик Яндекс.Каталога, помочь определить геозависимость запроса или сравнить расхождения выдачи разных поисковых систем и так далее.
Итак, на данный момент существует множество сервисов, анализирующих апдейты, каждый из них использует свой алгоритм поиска расхождений в ТОПе. На первый взгляд задача кажется простой, но при её решении возникает ряд нюансов и желание найти оптимальное решение.
Какие возникают проблемы при поиске силы апдейта?
Давайте рассмотрим, какие ещё можно использовать методы сравнения массивов и определения степени их расхождения, а также проверим работу каждого из них на тестовой выборке.
Суть данного метода заключается в измерении абсолютных изменений параметров массивов, их суммировании и дальнейшей нормализации.
Fn = Norm( Σ|p1(i) — p2(i)| )
Где p(i) — значение i-ого элемента массива (сравниваются массивы p1 и p2 одинаковой длины).
В сумме используются лишь те элементы массива p1, которые присутствуют в p2, для нормализации значение делится на максимально возможную разницу позиций (max = [len(p)/2]^2).
В данном методе производится поиск количества общих символов в сравниваемых строках. Агоритм Оливера в PHP реализован в стандартной функции similar_text(). Чтобы преобразовать массив значений в текст, необходимо каждому значению присвоить уникальный символ (в таблице UTF8 их можно подобрать нужное количество).
Алгоритм Левенштейна ищет минимальное количество вставок, удаления и замены одного символа на другой, необходимых для превращения одной строки в другую. Метод широко используется для исправления ошибок в словах (грамматика поисковых систем), сравнения текстовых файлов или даже генов и хромосом. Вполне подходит этот метод и для наших целей.
Метод, предложенный Евгением Трофименко, где производится поиск количества парных изменений в массивах.
Для проверки каждого из методов были созданы тестовые выборки и разработан скрипт на php, который можно скачать и проверить на своей выборке (test_top.zip, 3 Кб).
Описание тестовых массивов:
top1 — Начальный массив с последовательной нумерацией сайтов.
top2 — Отличается от начального заменой одного элемента без смещения остальных. Имитация смены сайта на его афиллиат.
top3 — Отличается от начального выпадением двух элементов и смещением остальных. Имитация выпадения сайтов из ТОПа.
top4 — Отличается от начального сменой мест у четырех пар элементов. Имитация небольших смещений позиций единичных сайтов.
top5 — Небольшие разнообразные изменения по сравнению с начальным массивом. Имитация слабого апдейта.
top6 — Случайная сортировка и смещение массива. Имитация сильной встряски поисковой выдачи.
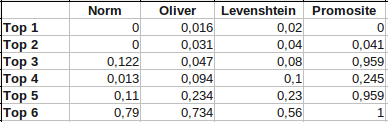
Результаты работы алгоритмов приведены ниже в таблице (нормированные значения).
Как видно из таблицы, недостаток первого метода заключается в большой чувствительности к малым изменениям. Выпадение пары сайтов может дать коэффициент разнообразия массивов больше, чем небольшой апдейт. Что касается алгоритма попарного сравнения, наблюдается такая же картина — для выборки top3 мы имеем значение, схожее с серьезным апдейтом. Намного лучше дают результаты алгоритмов Оливера и Левенштейна, причем, максимальное значение для выборки top6 (где элементы были максимально перемешаны) дает именно алгоритм Оливера.
Посмотрим также результаты работы алгоритмов на примере реальной выборки по ключевому запросу «купить машину» в Яндекс.Москва до и после апдейтов — 20 августа(после длительной задержки, когда ожидались глобальные изменения), 22 августа (второй апдейт), и 23 августа (когда апдейта не было).

Между первым и вторым апдейтом сила разнилась, судя по разным методам, на 4%, 9%, 6% и 0%. Метод Оливера здесь дает также наилучшие результаты, делая шкалу более линейной. Конечно же, чтобы получить более достоверные данные об изменениях в ТОПе, если мы говорим не об одном ключевом слове (или регионе), а сразу нескольких, то необходимо сравнивать массивы для разных ключевых слов и брать средний результат. Однако, целью данной статьи было именно описать возможные варианты решения задачи сравнения и мы надеемся, какой-то из методов вам пригодится для проведения аналитики!
Если у вас есть в арсенале свои методы сравнения двух массивов (в поиске коэффициента расхождения), или есть какие-либо замечания по описанным выше алгоритмам, будем рады прочитать ваши комментарии.