
Summary of the final work
Content
- Introduction
- 1. Relevance of the topic
- 2. The purpose and objectives of the study, the planned results
- 3. Distributed systems
- 3.1 Distributed Systems Architecture
- 3.2 Requirements for distributed systems
- 3.3 Intermediate environment
- 4.ROR(Ruby on Rails)
5. Review of research and development
- 5.1 International sources
- 5.2 National sources sources
- 5.3 Local sources
- Findings
- List of sources
Introduction
According to the well-known computer scientist E. Tanenbaum, there is no generally accepted and at the same time strict definition of a distributed system. Some wits claim that a computing system is distributed, in which a computer malfunction, the existence of which users had never even suspected before, causes all their work to stop. A significant part of distributed computing systems, unfortunately, satisfy this definition, but formally it refers only to systems with a unique point of vulnerability (single point of failure).[1]
Often when defining a distributed system, the division of its functions among several computers is of paramount importance. With this approach, any computing system is distributed, where data processing is divided between two or more computers. Based on the definition of E. Tanenbaum, a somewhat more narrowly distributed system can be defined as a set of independent computers connected by communication channels, which from the user's point of view of some software look like a single whole..[2]
This approach to defining a distributed system has its drawbacks. For example, all software used in such a distributed system could work on a single computer, but from the point of view of the above definition, such a system would no longer be distributed. Therefore, the concept of a distributed system should probably be based on an analysis of the software that forms such a system.[3]
1. Relevance of the topic
At the moment there are many approaches to the development of various types of systems and complexes. Recently, however, the notions of the distribution of the system, both on the physical and software levels, are becoming increasingly popular. Distribution allows you to interact with the hardware, and in some cases with the software at a distance, which is incredibly convenient. Also, the concept of a distributed system includes a client-server architecture that is currently used everywhere.
2. The purpose and objectives of the study, the planned results
The purpose of the master's work is the research and development of a distributed system
The main objectives of the study:
- Overview of existing distributed systems
- Overview of the possibilities of implementing such systems in the Ruby language
- Analysis of distributed system architectures
- Development of a distributed system in the Ruby language
3. Distributed systems
A distributed system is a system for which the relations of the locations of elements (or groups of elements) play a significant role from the point of view of the functioning of the system, and, consequently, from the point of view of the analysis and synthesis of the system.[4]
3.1 Distributed Systems Architecture
As a basis for describing the interaction of two entities, we consider a common client-server interaction model in which one of the parties (the client) initiates data exchange by sending a request to the other side of the client (Fig. 1.1).
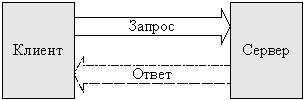
Рис. 1.1. Модель взаимодействия клиент сервер
Interaction within the client-server model can be either synchronous when the client waits for the server to process its request, or asynchronous, in which the client sends a request to the server and continues its execution without waiting for a server response. The client and server model can be used as the basis for describing various interactions. For this course, the interaction of the components of the software that makes up the distributed system is important.[5]
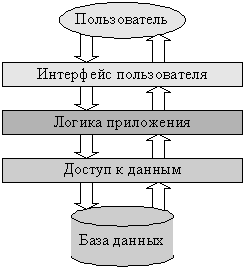
Рис. 1.2. Логические уровни приложения
Consider a typical application that, in accordance with modern concepts, can be divided into the following logical levels (Fig. 1.2): user interface (PI), application logic (LP) and data access (DD), working with a database (DB) . The system user interacts with it through the user interface, the database stores data describing the application domain, and the application logic level implements all the algorithms related to the subject area.[6]
Since, in practice, different users of the system are usually interested in accessing the same data, the simplest separation of the functions of such a system between several computers will be the separation of the logical levels of the application between one server part of the application responsible for accessing data and client parts located on several computers. implementing the user interface. The application logic can be assigned to the server, clients, or divided between them (Fig. 1.3).[6]
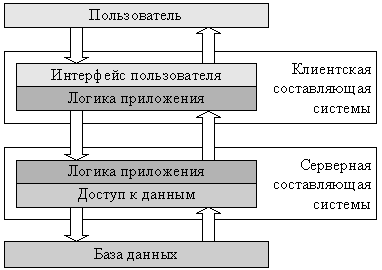
Рис. 1.3. Двухзвенная архитектура
The architecture of applications built on this principle is called a client server or two-link. In practice, such systems are often not classified as distributed, but formally they can be considered the simplest representatives of distributed systems. The development of client-server architecture is a three-tier architecture in which the user interface, application logic and data access are separated into independent components of the system that can work on independent computers (Fig. 1.4).[1]
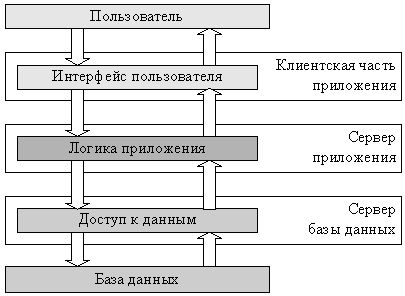
Рис. 1.4. Трехзвенная архитектура
User requests in such systems are sequentially processed by the client part of the system, the application logic server and the database server. However, usually a distributed system is understood as a system with a more complex architecture than the three-tier system.
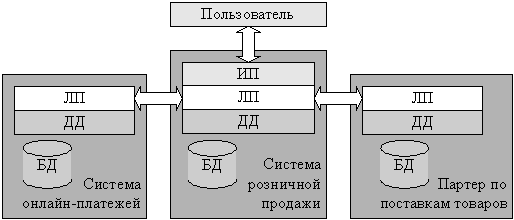
Рис. 1.5. Распределенная система розничных продаж
As applied to enterprise automation applications, typically referred to as systems with application logic, distributed among several components of the system, each of which can run on a separate computer. For example, the implementation of retail sales application logic should use requests to third-party application logic, such as suppliers of goods, electronic payment systems, or banks that provide consumer loans (Fig. 1.5).[7]
Thus, in use, a distributed system often implies the growth of a multilink architecture "wide", when user requests do not pass sequentially from the user interface to a single database server. As another example of a distributed system, one can cite peer-to-peer networks. If the previous example had a tree-like architecture, then the direct exchange networks are organized in a more complicated way, fig. 1.6. Such systems are currently, probably, one of the largest existing distributed systems, uniting millions of computers.[8]
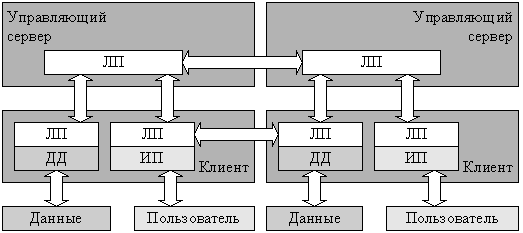
Рис. 1.6. Система прямого обмена данными между клиентами
3.2 Requirements for distributed systems
To achieve the goal of its existence - to improve the performance of user requests - a distributed system must meet some necessary requirements. We can formulate the following set of requirements that, in the best case, a distributed computing system should satisfy.[6]
Openness All component interaction protocols within a distributed system should ideally be based on publicly available standards. This allows the use of various development tools and operating systems to create components. Each component must have an accurate and complete specification of its services. In this case, the components of a distributed system can be created by independent developers. If this requirement is violated, the possibility of creating a distributed system covering several independent organizations may disappear.[9]
Scalable. The scalability of computing systems has several aspects. The most important of these for this course is the possibility of adding new computers to a distributed system to increase system performance, which is related to the concept of load balancing on the servers of the system. Scaling also includes issues of efficient allocation of server resources serving client requests.[10]
Maintain logical data integrity. A user request in a distributed system must either correctly execute entirely or not at all. The situation when a part of the system components correctly processed the incoming request, and a part not, is the worst.[11]
Sustainability. Stability refers to the possibility of duplication of the same functions by several computers, or the possibility of automatic distribution of functions within the system in the event of the failure of one of the computers. In the ideal case, this means the complete absence of a unique point of failure, that is, the failure of any one computer does not make it impossible to serve the user's request.[12]
Security. Each component that forms a distributed system must be sure that its functions are used by the components or users authorized to do so. Data transmitted between components must be protected from both distortion and viewing by third parties.
Efficiency. In the narrow sense as applied to distributed systems, the efficiency will be understood as minimizing the overhead costs associated with the distributed nature of the system. Since efficiency in this narrow sense may conflict with the security, openness and reliability of the system, it should be noted that the requirement for efficiency in this context is the least priority. For example, considerable time and memory resources may be wasted to maintain the logical integrity of data in a distributed system, but a system with inaccurate data is hardly needed by users. A desirable feature of the intermediate environment is the ability to organize effective data exchange, if the interacting software components are on the same computer. An effective middleware should be able to organize their interaction without affecting the TCP / IP stack. To do this, you can use system sockets (unix sockets) on POSIX systems or named pipes (named pipes).[13]
The stability of a distributed system is associated with the concept of scalability, but is not equivalent to it. Suppose the system uses a set of request processing servers and one request manager, which distributes user requests between servers. Such a system can be considered quite well scalable, but the dispatcher is a vulnerable point of such a system. On the other hand, a system with a single server can be stable if there is a mechanism for its automatic replacement in case of its failure, but it is unlikely to belong to the class of well-scalable systems. In practice, quite often there are distributed systems that do not meet these requirements: for example, any system with a unique database server, implemented as a single computer, has a unique point of failure. Meeting the requirements of stability and scalability is usually associated with some additional costs, which in practice may not always be advisable. However, the technologies used in building distributed systems must admit the fundamental possibility of creating stable and highly scalable systems.[14]
A classic example of a system that largely meets all the requirements presented above is the system for translating symbolic names into network IP addresses (DNS). The name system is an organized hierarchically distributed system, with duplication of all functions between two or more servers (Fig. 1.7).
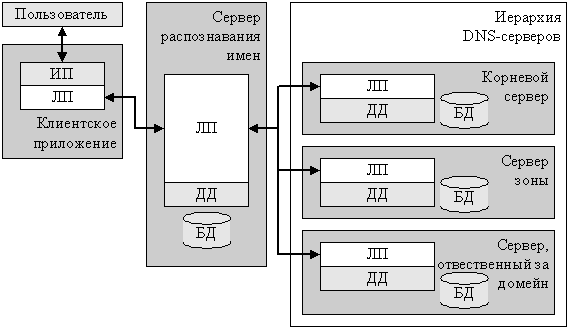
Рис. 1.7. Система DNS
The user's request to resolve the name (for example, w3c.org) to a network address is transmitted to the name server of the ISP. The name recognition server polls the servers from the hierarchy of the name service in turn. Interrogated from root servers, which returns the addresses of servers responsible for the domain zone. It then polls the server responsible for the zone (in this case, .org), which returns the addresses of the servers responsible for the second-level domain, and so on. Name servers cache name and address mapping information to reduce system load. Software on the user's computer usually has the ability to connect to at least two different name recognition servers.
However, in the name recognition system, not all requirements for distributed systems are met. In particular, it does not contain any explicit security mechanisms. This leads to regular attacks on name servers in the hope of disabling them, for example, with a large number of queries.
3.3 Intermediate environment
From the point of view of one of the computers of a distributed system, all other machines included in it are remote computing systems. The theoretical basis for network interaction of remote systems is the well-known OSI / ISO open systems interaction model, which divides the interaction process of the two sides into seven levels: physical, channel, network, transport, session, application, representative.[15]
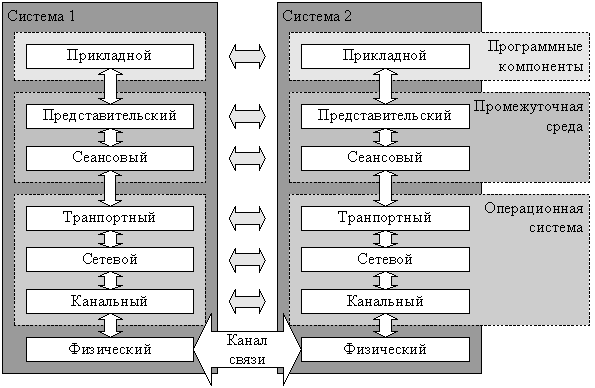
Рис. 1.8. Модель взаимодействия вычислительных систем
In networks of the most common TCP / IP protocol stack, TCP is the transport protocol and IP is the network layer protocol. The provision of an interface to the transport layer is currently assumed by the network component of the operating system, usually providing a socket-based interface for the upper layers. Sockets provide low-level primitives for directly exchanging a stream of bytes between two processes. There is no standard representative or session layer in the TCP / IP protocol stack; sometimes they include secure SSL / TLS protocols.[16]
Using TCP / IP through sockets provides a standard, cross-platform, but low-level service for exchanging data between components. In order to fulfill the requirements set forth above for distributed systems, the functions of the session and representative levels should be taken over by some intermediate environment (middleware), also called middleware (Fig. 1.9). Such an environment should help developers create open, scalable and sustainable distributed systems. To achieve this goal, the intermediate environment must provide services for the interaction of the components of the distributed system. These services include:
- providing a unified and operating system independent mechanism by some software components of the services of other components;
- ensuring the security of a distributed system: authentication and authorization of all service users of the components and protection of information transmitted between the components against distortion and reading by third parties;
- data integrity: managing transactions distributed between remote components of systems;
- load balancing on servers with software components;
- detection of remote components.[17]
Within one distributed system, several types of intermediate media can be used (Fig. 1.9). With a good approach to the design of the system, each of its distributed components provides its services through a single intermediate environment, and uses the services of other components through a single intermediate environment, however these environments may be different.
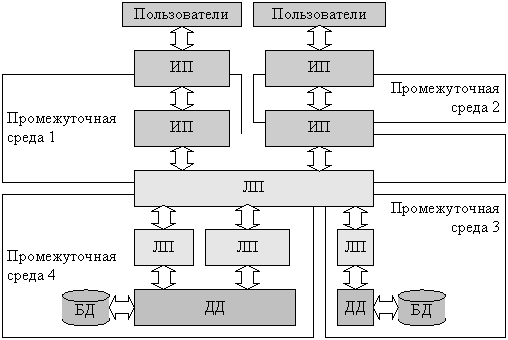
Рис. 1.9. Гетерогенная распределенная система
A distributed system whose components use several intermediate media can be called heterogeneous, as opposed to homogeneous, using a single intermediate medium. Since the same intermediate environment can be implemented on different hardware platforms and operating systems, both classes of distributed systems can include computers running both the same and different operating systems.
There is currently no universally applicable intermediate environment, although, as will be shown in the course, there is a certain movement in this direction. The main reason for the absence of such an environment is partly contradictory requirements for distributed systems, as well as the different nature of network connections between system components: for example, the interaction of components within one enterprise can probably be built differently than the interaction of components of two different enterprises that do not fully trust each other.[18]
The interaction of software components within the same computer also occurs through the intermediate environment, which, when using some intermediate environments, can be both inconvenient and inefficient. Ideally, the distributed component should be implemented in such a way that the transition from one intermediate medium to another takes place by changing the configuration of the software component, and not by changing the source code. In practice, this requirement, unfortunately, can be difficult to implement, however, it is necessary to at least minimize the possible corrections of the program code with a possible change of the intermediate environment.[7]
4. ROR(Ruby on Rails)
RoR is a free framework required for developing applications that are based on the MVC (Model-View-Controller) architecture and are based on Ruby. The main goal is to simplify the development of web applications and create them in a small amount of code, rather than in other frameworks, with minimal configuration. Metaprogramming Ruby just allows you to achieve all of this.
The core principles of Ruby on Rails are configuration exclusion, entering, wherever possible, generally accepted conventions, and eliminating duplicate code that has the same meaning. The components of Ruby on Rails are integrated in such a way that now the programmer does not need to write descriptors that are necessary for communication with each other or repeat the definitions found in the program code in the relational database.
The Ruby on Rails framework and its additional extensions are distributed through a system such as Ruby Gems, which standardizes distribution channels and package formats. Model Classes of Ruby on Rails models are based on Active Record libraries that implement the object-relational type of data stored in the database. Active Record has:
- Reflection of associations, columns, aggregations
- Hereditary hierarchy
- Auto-reflection between tables and classes, columns and attributes
- Transactional support at the database level and at the object presentation level
- Object Field Validation Rules
- Ability to present entries as trees or lists
- Aggregation of objects
- The ability to specify actions that are performed at different stages of the life of an object, both in a separate class and in the model itself
- By abstraction from a specific DBMS. PostgreSQL, MySQL, DB2, SQL Server, Oracle support
- Inheriting a class from the class ActiveRecord :: Base, which automatically displays a table with a name that matches the name of the class you created
- The relation of objects supported by the macros has_one, has_many, belongs_to
View To display the user interface in Ruby on Rails, there is a class called Action View that implements an advanced pattern system, much like JavaScript, where Ruby language instructions are located inside tags such as <% =%> or <%%>. There is also a render function (display of the template), which is used both inside the template and serves to show the sub-template and inside the controller. Controller
The interacting classes with the user in Ruby on Rails are built on the principle of the ActionController classes. This defines the methods that are accessible via a URL via the web. The default view template is associated with each method. This class defines various helper methods that are needed to manage aspects that interact with the user and generate the code that is often used. For example, when working with a database for CRUD operations (Create-Remove-Update-Delete). [19]
5. Review of research and development
Because the distributed systems are a promising though not new research and development topic and are widely researched by both our and foreign scientists in relation to completely different areas.
5.1 International Sources
Among foreign companies, Microsoft and Alibaba should be highlighted. Probably you either heard or used the AliExpress service, but you probably didn’t think that the whole concept of the service’s operation is based on distributed systems. Despite this, unfortunately, it was not possible to find a worthy mention of the literature for the authorship of this company or its employees. In the field of literature on this topic, Microsoft has achieved great success. Let's stop on a pair of interesting books.
Designing Distributed Systems
Techniques and patterns in this free e-book will help you quickly develop reliable distributed systems, at least so the developers say. Distributed systems allow you to create specialized applications to meet the needs of different areas of business. They can also be used to realize analytical opportunities and innovations. New standards give new impetus to business, but at the same time they create the danger of inefficient development, when the same systems are introduced several times. This free e-book provides reproducible patterns and versatile components that will facilitate the development of reliable distributed systems and help make it more efficient. As a result, you can devote more time directly to application development.
The book consists of 160 pages and contains:
- • Introduction to the basics of distributed systems.
- • Templates and techniques to help create distributed systems.
- • A description of the platform for integrating applications, data sources, business partners, customers, mobile applications, social networks and devices for the Internet of Things.
- • A description of the event-based architecture for handling and responding to events.
- • Additional resources for exploring containers and container management systems.
“Now the need for building distributed systems is high, and there are not so many people who can create them. Templates for building distributed systems (especially for container management systems such as Kubernetes) will be useful for both beginners and experienced developers to quickly build and deploy reliable distributed systems. ”- Brendan Burns
Brendan Burns is one of the leading Microsoft developers, working on the Azure project and co-founder of the Kubernetes project.
The second source of interest is a course lecture from Microsoft Academy called Support for the Development of Distributed Applications in the Microsoft .NET Framework:
The course describes in detail the methods of creating distributed applications, recommendations on the architecture of complex applications, standards for the exchange of information between remote systems, as well as ensuring network security. Consideration is given to the creation of distributed systems on the Microsoft platform (COM +, MSMQ, IIS) using Microsoft. NET Framework. And despite the sort of narrow focus on the development through the Microsoft .NET Framework. The course perfectly reveals not only the development, but also the principles of distributed software systems. [ 19 ]
5.2 National Sources
Also, the topic of distributed systems was not spared, and from our side, unfortunately, and perhaps, fortunately, unlike foreign authors, we pay more attention to the implementation of distributed systems on the hardware. One of the good examples with which it will be interesting to get acquainted is the textbook "INTRODUCTION TO DISTRIBUTED CALCULATIONS" the author of this manual is M. Kosyakov.
The manual outlines the basic concepts and concepts from the field of distributed computing, for the model of asynchronous distributed systems are methods and algorithms for solving the most important tasks. Particular attention is paid to the mechanism of logical clocks, which allows to significantly simplify the development of algorithms for distributed systems. The main distributed mutual exclusion algorithms are carefully considered. The study of these algorithms allows to reveal such important issues as ensuring the security properties and survivability of distributed algorithms. The material of the manual is accompanied by numerous examples demonstrating the application of the studied methods and algorithms for solving real problems. [13]
5.3 Local Sources
In the Donetsk National Technical University, the topic of distributed systems has been widely developed and is being developed, on the Masters portal you can find many interesting works on this topic, I will mention only a few of them.
- Filenko MS Development of a mechanism for distributed storage and protection of information
- S.Stryukov Development of models and software for building computer information systems with distributed architecture
- Latortsev A.A. Development of the distributed computer information systems modeling subsystem
- Afonov I.V. Exploring the properties of distributed storage systems
- MV Varich Development of a parallel computing system model for calculating the parameters of a moving object
- ...
The list could go on and on, but I hope that for the initial acquaintance with the topic there will be enough of these works
Remarks
At the time of writing this essay the master's work is not yet completed. Estimated completion date: May 2019. Full text of the work, as well as materials on the topic can be obtained from the author or his manager after the specified date.
Findings
Based on the above, it can be concluded that the topic of distributed systems is very deep and interesting. Also, this topic reveals a wide scope for research and development.
List of sources
- Елена Чернопрудова, Сергей Щелоков. Проектирование распределенных информационных систем: Курс лекций[Электронный ресурс] Режим доступа: Ссылка.
- Митряев. Понятие распределенной информационной системы: Курс лекций[Электронный ресурс] Режим доступа: Ссылка.
- Приходько Семён Артурович. Обзор распределенных систем.[Электронный ресурс] Режим доступа: Ссылка.
- Распределённая система.Материал из Википедии – свободной энциклопедии [Электронный ресурс] Режим доступа:Ссылка.
- Митряев. Модель Клиент-сервер: Курс лекций [Электронный ресурс] Режим доступа: Ссылка.
- Сергей Горин, Всеволод Крищенко. Поддержка разработки распределенных приложений в Microsoft .NET Framework: Лекции[Электронный ресурс] Режим доступа: Ссылка.
- Сергей Горин, Всеволод Крищенко. Поддержка разработки распределенных приложений: Учебный курс Москва, 2006. - 5c
- Распределенные информационные системы: Конспект.[Электронный ресурс] Режим доступа: Ссылка.
- Задачи и проблемы распределенной обработки данных[Электронный ресурс] Режим доступа: Ссылка.
- Масштабируемость параллельных и распределенных систем[Электронный ресурс] Режим доступа: Ссылка.
- М. Тамер Оззу, Патрик Валдуриз. Распределенные и параллельные системы баз данных: Журнал Системы Управления Базами Данных # 4/1996, издательский дом «Открытые системы» [Электронный ресурс] Режим доступа: Ссылка.
- В.З. Шнитман, С.Д. Кузнецов. Аппаратно-программные платформы корпоративных информационных систем: Информационно-аналитические материалы Центра Информационных Технологий [Электронный ресурс] Режим доступа: Ссылка.
- Косяков М.С. Введение в распределенные вычисления. – СПб: НИУ ИТМО, 2014. - 8c
- Уфимский Государственный Авиационный Технический Университет. Общие сведения о tcp/ip: Лекции[Электронный ресурс] Режим доступа: Ссылка.
- Митряев. Соответствие модели osi и других моделей сетевого взаимодействия:Лекции[Электронный ресурс] Режим доступа: Ссылка.
- Г. Ладыженский. Jet Infosystems системы[Электронный ресурс] Режим доступа: Ссылка.
- ASP.NET Core MVC[Электронный ресурс] Режим доступа: Ссылка.
- Ruby on Rails - Introduction[Электронный ресурс] Режим доступа: Ссылка.
- Брендан Бернс. Проектирование распределенных систем[Электронный ресурс] Режим доступа: Ссылка.